









前言:我们已经认识并实现了哈希底层的逻辑,创建出了其开散列。现在我们要进行封装,类比STL中的unordered_set 与 unordered_map。
目录
1.2 unordered_set 与 unordered_map的封装
1. 模拟实现
1.1 哈希表的改造
1. 模板参数列表的改造
unordered_set 与 unordered_map的泛型与map与set的泛型有些类似,unordered_set 与 unordered_map比map与set多一个仿函数,他们都取key值,并且需要一个hash值作为映射点。所以需要两个仿函数。
K:关键码类型
V: 不同容器V的类型不同,如果是unordered_map,V代表一个键值对,如果是
unordered_set,V 为 K
KeyOfValue: 因为V的类型不同,通过value取key的方式就不同,我们必须使用一个仿函数进行才能实现unordered_map/set。
Hash: 哈希函数仿函数对象类型,哈希函数使用除留余数法,需要将Key转换为整形数字才能
取模
template<class K, class V, class KeyOfValue, class Hash = DefHashF<T> >
class HashBucket;只有我们调用unordered_set 与 unordered_map时,编译器会识别关键字进行操作,所以我们定义的仿函数可以使用类部类中:
//unodered_set
template<class K, class Hash = HashFunc<K>>
class unordered_set
{
struct SetKeyOfT
{
const K& operator()(const K& key)
{
return key;
}
};
public:
typedef typename hash_bucket::HashTable<K, const K, SetKeyOfT, Hash>::iterator iterator;
};
//unorder_map
template<class K, class V, class Hash = HashFunc<K>>
class unordered_map
{
struct MapKeyOfT
{
const K& operator()(const pair<K, V>& kv)
{
return kv.first;
}
};
public:
typedef typename hash_bucket::HashTable<K, pair<const K, V>, MapKeyOfT, Hash>::iterator iterator;
};
所以我们HashNode中的泛型应该修改:
template<class T>
struct HashNode
{
HashNode<T>* _next;
T _data;
HashNode(const T& data)
:_next(nullptr)
, _data(data)
{}
};2. 增加迭代器操作
我们要实现迭代器的++、*、!=等等,因为HashNode中为单链表,所以我们不需要实现--操作。
那我们应该如何实现呢?
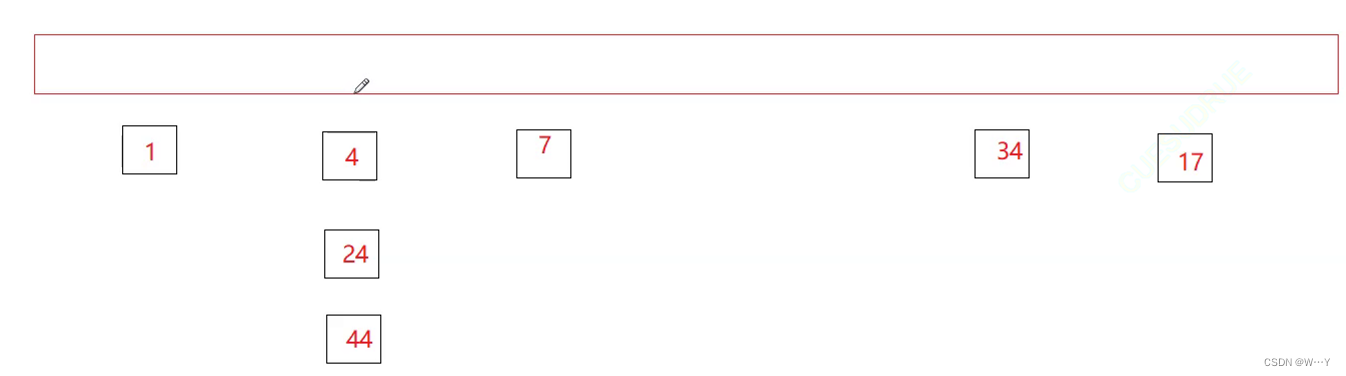 上图是散列表结构,迭代器的底层就是指针,所以我们就要使用指针指向桶中的元素。所以我们就要HashNode的指针与HashTable的指针作为迭代器成员。
上图是散列表结构,迭代器的底层就是指针,所以我们就要使用指针指向桶中的元素。所以我们就要HashNode的指针与HashTable的指针作为迭代器成员。
struct __HTIterator
{
typedef HashNode<T> Node;
typedef HashTable<K, T, KeyOfT, Hash> HT;
typedef __HTIterator<K, T, KeyOfT, Hash> Self;
Node* _node;
HT* _ht;
__HTIterator(Node* node, HT* ht)
:_node(node)
, _ht(ht)
{}
};begin()与end()函数非常简单,begin就找vector中第一个不为空的指针,返回其值即可。
iterator begin()
{
for (size_t i = 0; i < _tables.size(); i++)
{
// 找到第一个桶的第一个节点
if (_tables[i])
{
return iterator(_tables[i], this);
}
}
return end();
}end就是返回空即可:
iterator end()
{
return iterator(nullptr, this);
}++其实是最难实现的,因为当给予一个指针时,我们要桶的下一个节点,如果这个桶的所以节点全部走完就要寻找下一个不为空的桶即可。
Self& operator++()
{
if (_node->_next)
{
// 当前桶还是节点
_node = _node->_next;
}
else
{
// 当前桶走完了,找下一个桶
KeyOfT kot;
Hash hs;
size_t hashi = hs(kot(_node->_data)) % _ht->_tables.size();
// 找下一个桶
hashi++;
while (hashi < _ht->_tables.size())
{
if (_ht->_tables[hashi])
{
_node = _ht->_tables[hashi];
break;
}
hashi++;
}
// 后面没有桶了
if (hashi == _ht->_tables.size())
{
_node = nullptr;
}
}
return *this;
}迭代器中剩余函数:
bool operator!=(const Self& s)
{
return _node != s._node;
}
T& operator*()
{
return _node->_data;
}1.2 unordered_set 与 unordered_map的封装
//unordered_set
namespace why
{
template<class K, class Hash = HashFunc<K>>
class unordered_set
{
struct SetKeyOfT
{
const K& operator()(const K& key)
{
return key;
}
};
public:
typedef typename hash_bucket::HashTable<K, const K, SetKeyOfT, Hash>::iterator iterator;
iterator begin()
{
return _ht.begin();
}
iterator end()
{
return _ht.end();
}
bool insert(const K& key)
{
return _ht.Insert(key);
}
private:
hash_bucket::HashTable<K, const K, SetKeyOfT, Hash> _ht;
};
//unordered_map
namespace why
{
template<class K, class V, class Hash = HashFunc<K>>
class unordered_map
{
struct MapKeyOfT
{
const K& operator()(const pair<K, V>& kv)
{
return kv.first;
}
};
public:
typedef typename hash_bucket::HashTable<K, pair<const K, V>, MapKeyOfT, Hash>::iterator iterator;
iterator begin()
{
return _ht.begin();
}
iterator end()
{
return _ht.end();
}
bool insert(const pair<K, V>& kv)
{
return _ht.Insert(kv);
}
private:
hash_bucket::HashTable<K, pair<const K, V>, MapKeyOfT, Hash> _ht;
};以上就是unordered_set 与 unordered_map的封装的全部内容,具体代码在我的gitee代码库中,想要的可以自行去取!!!















 157
157











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











