







1,Probabilistic language model (概率语言模型)
目标:计算句子或单词序列的概率:
P(W)=P(w1,w2,w3,...,wn)
下一个单词出现的概率:
P(W)=P(wn|w1,w2,w3,...,wn-1)
2,Application
- Machine translation
P(Students from my class are the best|我班上的学⽣是最棒的) > P(Students from Stanford are the best|我班上的学⽣是最棒的)
- Natural language generation
P(best|Students from my class are the) > P(average|Students from my class are the)
- Speech recognition
P(Three students) > P(Tree students)
3,language models in daily life
- (search engine)搜索引擎
- (search engine Grammar check)语法检查
4,Probability of next word
1) P(best|Students from my class are the) = C(Students from my class are the best)/ C(Students from my class are the)(条件概率)
C(......)->the count of the phrase of "......"
2)A more easier way to calculate the probability:
P(Students from my class are the best) = P(best|the)P(the|are)P(are|class)P(class|my)P(my|from)P(from|Students)P(Students)
chain rule:P(w1:n) = P(w1)P(w2 |w1)P(w3 |w1:2) . . . P(wn |w1:n−1)
5,N-gram
- Bigram model:approximates the probability of a word given all the previous words by using only the conditional probability of the preceding word.
eg:P(best|Students from my class are the) ≈ P(best|the)
- Markov assumption:the probability of a word depends only on the previous word (P(wn |w1:n−1) ≈ P(wn |wn−1))
- Markov model:assume we can predict the probability of some future unit without looking too far into the past
- Generalizing bigram to n-gram:
From bigram to n-gram:P(wn |w1:n−1) ≈ P(wn |wn−N+1:n−1)
‣ N = 2: bigram ‣ N = 3: trigram ‣ N = 4: 4-gram ‣ N = 5: 5-gram
cases:
1) unigram:P(w1:n) = P(w1)P(w2)P(w3) . . . P(wn)
2)biogram:Condition on the previous word P(wi|w1:i−1) ≈ P(wi|wi−1)
6,Perplexity
- Definition: the inverse probability of the test set, normalized by the number of words
- Formula:
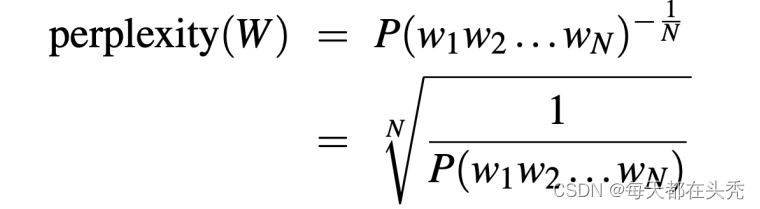
Apply chain rule:
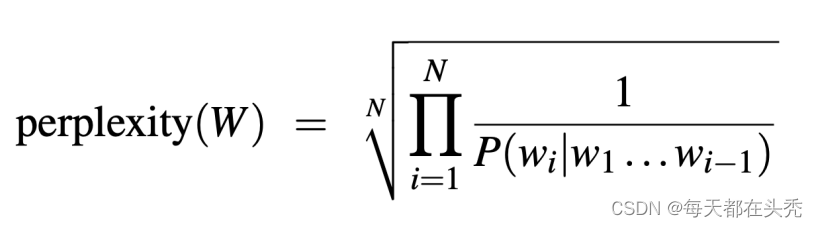
- Intuition of perplexity
Definition: Intuitively, perplexity can be understood as a measure of uncertainty
Understanding:What’s the level of uncertainty to predict the next word? eg:
- ChatGPT is built on top of OpenAI's GPT-3 family of large language _____ ?
Uncertainty level
- Unigram: highest
- Bigram: high
- 5-gram: low
Note:Lower perplexity = better model
7, The perils of overfitting
- N-gram models only work well for word prediction if the test corpus looks like the training corpus
- In real world, the inference corpus often doesn’t look like the training
- Robust models that generalize are all we need
- One kind of generalization: Zeros
- Things that doesn’t ever occur in the training set but not in the test set
7,Zeros
- Training set - … denied the allegations - … denied the reports - … denied the claims - … denied the request
- Test set - … denied the offer - … denied the loan
- For biogram:
zero probability:
![]()
Perplexity: can't find because of 1 over 0
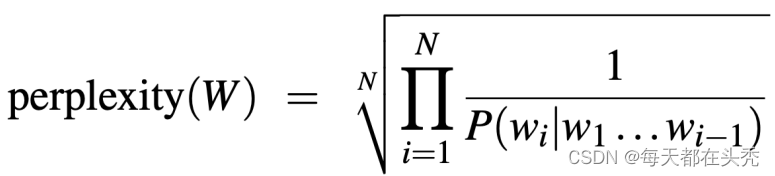
- Create an unknown word token
- Training of probabilities
Training of <UNK>probabilities
- Create a fixed lexicon L of size V
- At text normalization phase, any training word not in L changed to<UNK>
- During inference - Use UNK probabilities for any word not in training
8,Smoothing
- To improve the accuracy of our model
- To handle data sparsity, out of vocabulary words, words that are absent in the training set.
- Smoothing techniques
- Laplace smoothing: Also known as add-1 smoothing
- Additive smoothing - Good-turing smoothing
- Kneser-Ney smoothing
- Katz smoothing
- Church and Gale Smoothing
- Laplace Smoothing:Assuming every (seen or unseen) event occurred once more than it did in the training data.
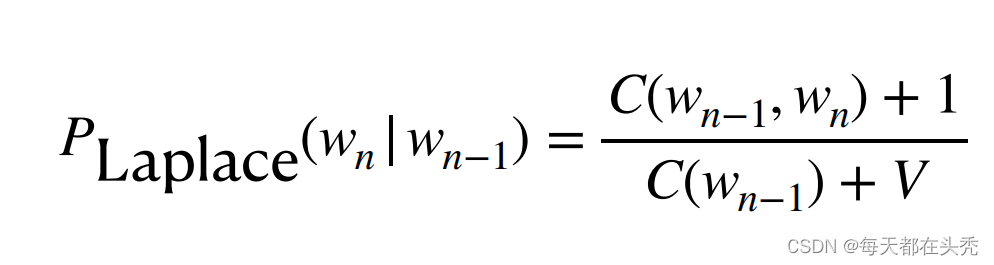
- Intuition of smoothing
‣ When we have sparse statistics:
- P(w | denied the)
• 3 allegations
• 2 reports
• 1 claims
• 1 request
‣ Steal probability mass to generalize better - P(w | denied the)
• 2.5 allegations • 1.5
• reports
• 0.5 claims
• 0.5 request
• 2 other
9,Backoff and interpolation
‣ Use less context
- Backoff(退避)
• use trigram if you have good evidence,
• otherwise bigram, otherwise unigram
- Interpolation(差值)
• Mix unigram, bigram, trigram















 774
774

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









