






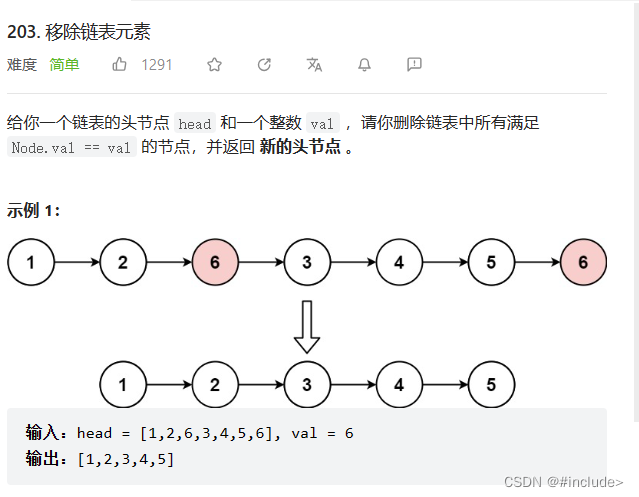
删除链表中等于定值的结点
题目链接
思路一:
定义一个结点指针,将值不等于val的结点尾插到该指针所指向的链表中,最后得到新的链表就是我们要找的链表
代码实现
struct ListNode* removeElements(struct ListNode* head, int val)
{
struct ListNode*newNode=NULL;
struct ListNode*tail=NULL;
struct ListNode*cur=head;
while(cur)
{
if(cur->val!=val)//结点的值不等于val
{
if(newNode==NULL)//当新链表中没有元素时尾插
{
newNode=cur;
tail=cur;
}
else//链表有元素时尾插
{
tail->next=cur;
tail=tail->next;
}
}
else//将值等于val的结点删除
{
struct ListNode*tmp=cur;
cur=cur->next;
free(tmp);
continue;
}
cur=cur->next;
if(tail)
tail->next=NULL;//及时将新链表的尾节点置空避免出现Bug
}
return newNode;
}
思路二
定义两个指针(分别是prev和cur),遍历整个链表,在遍历过程中发现值为val的结点就进行删除
代码实现
struct ListNode* removeElements(struct ListNode* head, int val){
struct ListNode*prev=NULL;
struct ListNode*cur=head;
while(cur)
{
if(cur->val==val)//要删除的情况
{
if(head==cur)//当要进行头删操作时
{
head=head->next;
free(cur);
cur=head;
}
else
{
prev->next=cur->next;
free(cur);
cur=prev->next;
}
}
else//不需要删除就继续向后走
{
prev=cur;
cur=cur->next;
}
}
return head;
}
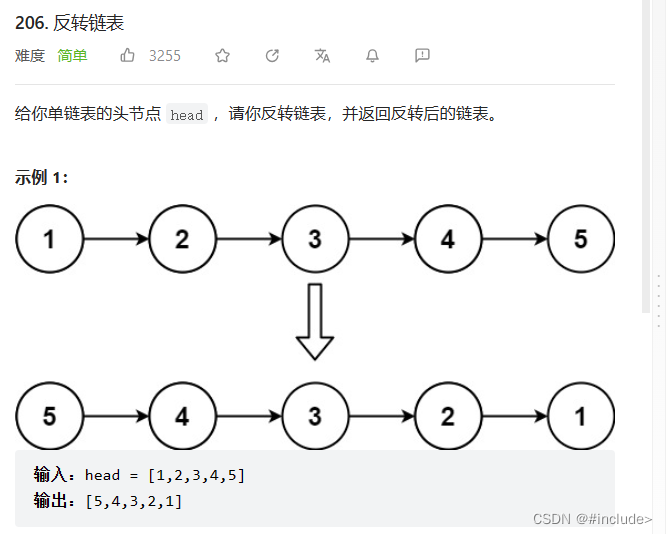
反转链表
思路一
利用三个指针(prev、next、cur)来实现每个结点指向的改变同时遍历整个链表
代码实现
struct ListNode* reverseList(struct ListNode* head){
struct ListNode*prev=NULL;
struct ListNode*cur=head;
struct ListNode*next=NULL;
if(cur)
{
next=cur->next;//next用来指向cur的下一个结点,以防在
} //改变反转后找不到下一个结点的位置
while(cur)
{
cur->next=prev;
prev=cur;
cur=next;
if(next)
{
next=next->next;
}
}
return prev;
}
思路二
想象一下,若分别将值为1,2,3,4,5的结点分别头插,那么就得到的链表的顺序为5,4,3,2,1
已知上述规律,我们也可以利用头插的思想来做这道题
struct ListNode* reverseList(struct ListNode* head)
{
if(head==NULL)//链表为空就不需要反转了
{
return head;
}
struct ListNode*newhead=NULL;//定义newhead假设指向一个新链表
struct ListNode*cur=head;
struct ListNode*next=cur->next;
while(cur)
{//在循环内进行头插操作
cur->next=newhead;
newhead=cur;
cur=next;
if(next)
{
next=next->next;
}
}
return newhead;
}
找链表的中间结点

题目链接
思路一:
先遍历整个链表得出链表的长度,再遍历链表长度的一半
时间复杂度O(N),空间复杂度O(1)
struct ListNode* middleNode(struct ListNode* head){
int count=0;
struct ListNode*tmp=head;
while(tmp!=NULL){
count++;
tmp=tmp->next;
}//计算一共有多少个节点
int mid=0;
if(count%2!=0){
mid=(count+1)/2;
}else{
mid=count/2+1;//找到第二个中间结点
}
count=1;
tmp=head;
while(count<mid){
tmp=tmp->next;
count++;
}
return tmp;
}
思路二:
快慢指针:定义两个指针分别为fast和slow,fast一次遍历两个结点,slow一次遍历一个结点,当fast走到最后一个结点或者为空时,slow就已经走到了中间结点
时间复杂度O(N),空间复杂度O(1)
struct ListNode* middleNode(struct ListNode* head){
struct ListNode*fast=head;
struct ListNode*slow=head;
while(fast&&fast->next)
{
fast=fast->next->next;
slow=slow->next;
}
return slow;
}
链表的倒数第k个结点

题目链接
思路一
遍历整个链表,得到链表的长度,就可推得倒数第k个结点得位置,再次遍历得到倒数第k个结点
struct ListNode* getKthFromEnd(struct ListNode* head, int k){
struct ListNode*cur=head;
int length=1;
while(cur->next)//得到整个链表得长度
{
cur=cur->next;
length++;
}
cur=head;
int count=length+1-k;
while((--count)!=0)//再次遍历得到倒数第k个结点
{
cur=cur->next;
}
return cur;
}
思路二
快慢指针:定义两个指针fast和slow,fast先走k-1步,然后fast和slow一起走,当fast走到最后一个结点时(fast->next==NULL),slow就是倒数第k个结点
struct ListNode* getKthFromEnd(struct ListNode* head, int k)
{
struct ListNode*fast=head,*slow=head;
while(--k)
{
fast=fast->next;
}
while(fast->next)
{
fast=fast->next;
slow=slow->next;
}
return slow;
}
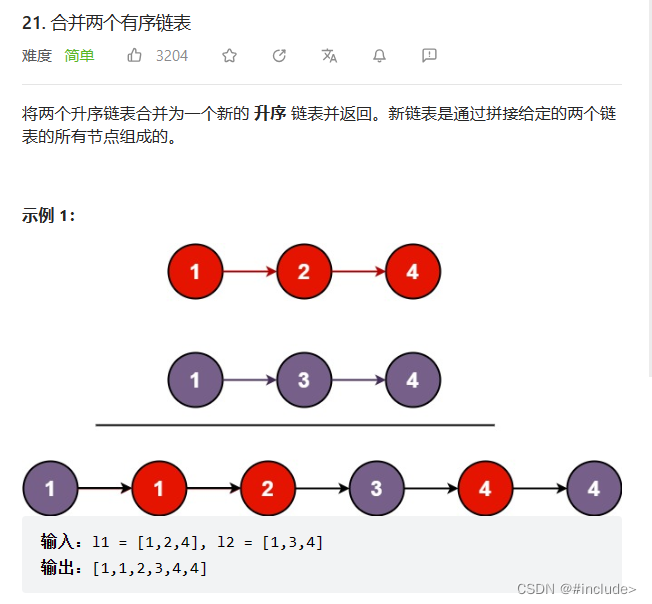
合并两个有序链表
思路一
定义一个head和一个tail,两个链表的结点小就将那个结点尾插到head指向的结点后面
struct ListNode* mergeTwoLists(struct ListNode* list1, struct ListNode* list2){
if(list1==NULL)
{
return list2;
}
if(list2==NULL)
{
return list1;
}//如果其中一个链表为空,就返回另外一个
struct ListNode*head=NULL,*tail=NULL;
while(list1&&list2)
{
if(list1->val<=list2->val)
{
if(head==NULL)
{
head=tail=list1;
}
else
{
tail->next=list1;
tail=list1;
}
list1=list1->next;
}
else
{
if(head==NULL)
{
head=tail=list2;
}
else
{
tail->next=list2;
tail=list2;
}
list2=list2->next;
}
}
if(list1==NULL&&list2!=NULL)
{
tail->next=list2;
}
if(list2==NULL&&list1!=NULL)
{
tail->next=list1;
}
return head;
}
思路二
和思路一相似,思路二就是定义一个哨兵位,将小的结点尾插到哨兵位的后面,与思路一相比,尾插更加方便,不需要考虑链表中是否有元素
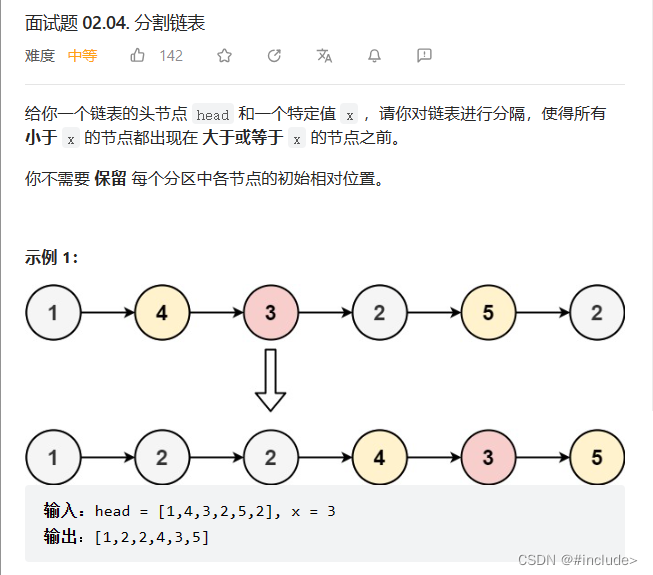
分割链表
思路
定义两个结点指针,小于x的结点尾插到其中一条,大于等于x的尾插到另一条,最后根据题目需要再将两条链表连接起来
struct ListNode* partition(struct ListNode* head, int x){
struct ListNode*smallHead=NULL;
struct ListNode*samllTail=NULL;
struct ListNode*greatHead=NULL;
struct ListNode*greatTail=NULL;
struct ListNode*cur=head;
while(cur)
{
if(cur->val<x)小于x的结点尾插到slowHead指向的链表后面
{
if(smallHead==NULL)
{
smallHead=cur;
samllTail=cur;
}
else
{
samllTail->next=cur;
samllTail=cur;
}
cur=cur->next;
samllTail->next=NULL;
}
else//大于x的结点尾插到greatHead指向的链表后面
{
if(greatHead==NULL)
{
greatHead=cur;
greatTail=cur;
}
else
{
greatTail->next=cur;
greatTail=cur;
}
cur=cur->next;
greatTail->next=NULL;
}
}
if(smallHead)//如果尾插小于x的链表不为空时,就将两条链表连在一起
{
samllTail->next=greatHead;
return smallHead;
}
return greatHead;
}
回文链表

题目链接
思路
先找到链表的中间结点,然后再逆置前半部分或者后半部分,再将前半部分和后半部分进行比对
bool isPalindrome(struct ListNode* head){
//先用快慢指针找到中点
struct ListNode*fast=head,*slow=head;
while(fast&&fast->next)
{
fast=fast->next->next;
slow=slow->next;
}
//再逆置前半部分
struct ListNode*prev=NULL,*cur=head,*next=head->next;
while(cur!=slow)
{
cur->next=prev;
prev=cur;
cur=next;
next=next->next;
}
//开始比对
if(fast)//当链表长度是奇数个时,链表的值关于中间那个对称
{
slow=slow->next;
}
while(prev&&slow)//此时prev和slow所指向的结点在链表中的位置是对称的
{
if(prev->val!=slow->val)//
{
return false;
}
prev=prev->next;
slow=slow->next;
}
return true;
}
相交链表
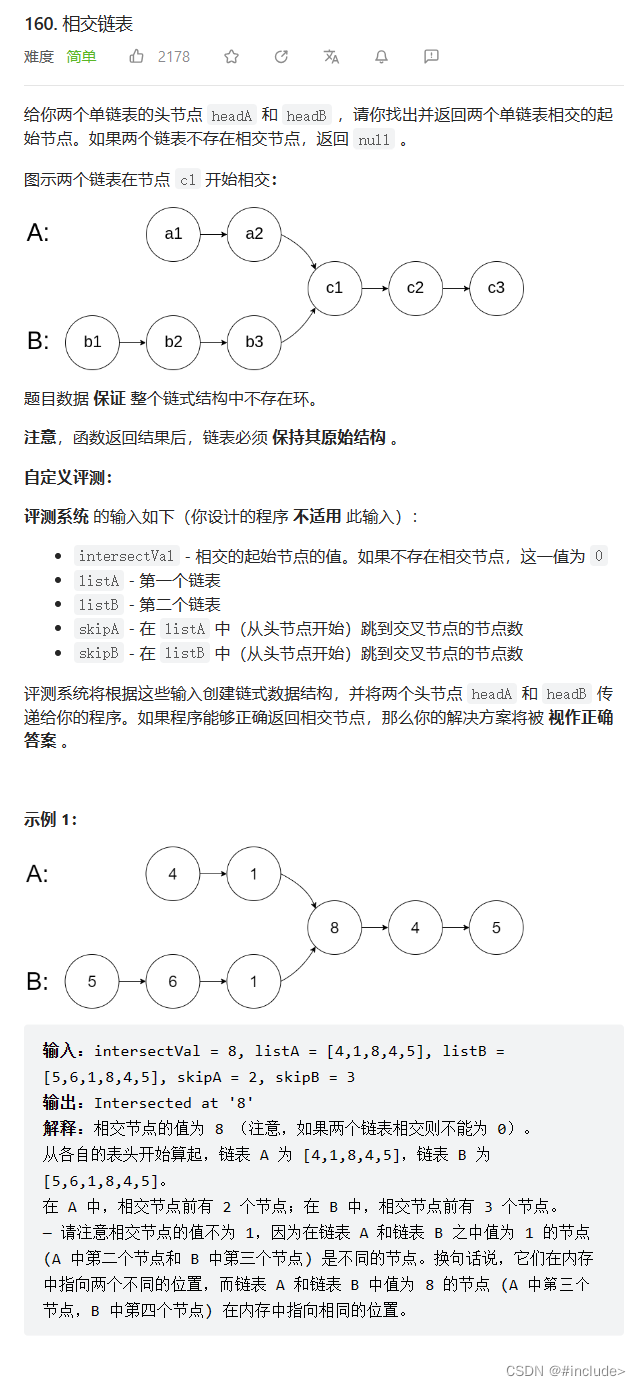
思路
计算出链表A和链表B的长度分别用lenA和lenB表示,同时也可以通过两个链表的最后一个结点是否相同来判断两个链表是否相交
让长的链表先走差距步(lenA-lenB or lenB-lenA),然后在同时走并依次对比来找到公共结点
struct ListNode *getIntersectionNode(struct ListNode *headA, struct ListNode *headB) {
struct ListNode *curA=headA;
int countA=1;
while(curA->next!=NULL){//求出A链表的长度以及找到最后一个结点
curA=curA->next;
countA++;
}
struct ListNode *curB=headB;
int countB=1;
while(curB->next!=NULL){//求出B链表的长度以及找到最后一个结点
curB=curB->next;
countB++;
}
if(curA!=curB){//没有相交的
return NULL;
}else{
curA=headA;
curB=headB;
if(countA>countB){
for(int i=0;i<countA-countB;i++){//求出长度的差,长的那个指针先走差距步
curA=curA->next;
}
}else if(countA<countB){
for(int i=0;i<countB-countA;i++){
curB=curB->next;
}
}
while(curA!=curB){//当curA和curB指向的结点不同时,就继续往后面走
curA=curA->next;
curB=curB->next;
}
return curA;
}
return NULL;
}
环形链表 I
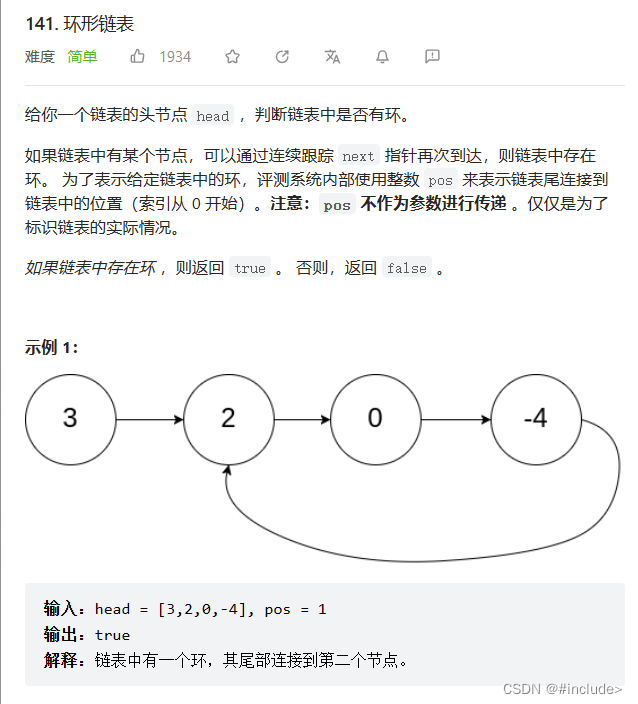
思路
快慢指针:快慢指针,即慢指针一次走一步,快指针一次走两步,两个指针从链表起始位置开始往后走,如果链表带环则一定会在环中相遇,否则快指针率先走到链表的末尾。
bool hasCycle(struct ListNode *head) {//快慢指针
struct ListNode *fast=head,*slow=head;
while(fast&&fast->next)
{
fast=fast->next->next;
slow=slow->next;
if(fast==slow)
{
return true;
}
}
return false;
}
拓展问题
- 为什么快指针每次走两步,慢指针走一步可以?
假设链表带环,那么这两个指针最后是一定都会进环的,快指针先进环,慢指针后进环
当慢指针刚进环时,此时最好的情况就是快指针和满指针在入环点相遇,最差的情况是两个指针之间的距离接近环的长度,当两个指针每同时移动一次后,快指针和慢指针之间的距离就会减1,假设最开始两指针的距离为N,那么之后的距离就是N-1、N-2、N-3…3、2、1、0,当它们的距离为0时,快慢两指针就相遇了
- 快指针一次走3步,走4步,…n步可行吗?
这里以快指针一次走3步的情况为例

综上所述,当快指针一次走大于2步时,是不一定和慢指针相遇的
只有快指针走2步,慢指针走一步才可以,因为环的长度最小是1,即使是套圈了两个也在相同的位置
环形链表 II
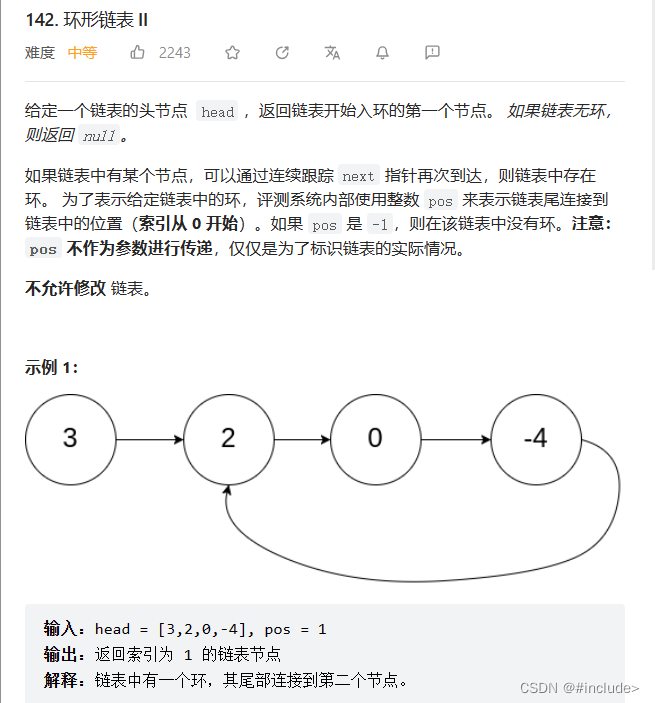
题目链接
思路一
先沿用上一题的思路找到相遇点,让指针从链表的起始位置开始遍历链表,同时让一个指针从环中相遇点的位置开始绕环运行,两个指针每次走一步,最后会在入口时相遇
证明

说明:
H为链表的初始点,E为环入口点,M为环内的相遇点
设:
环的长度为R,H到E的距离为L,E到M的距离为X
则M到E的距离就是R-X
在判环时,快慢指针走的路径长度:
fast:L+X+nR(slow进环时,fast以及走了n圈,n>=1且n向上取 整,在追的过程中,会把第n圈补完整)
slow:L+X (slow进环后一圈以内,fast一定追上slow)
注意
- 当慢指针进环时,快指针可能已经在环中绕了n圈了,n至少为1 因为:快指针先进环走到M位置,最后又在环中的M位置与慢指针相遇
- 慢指针进环之后,快指针一定会在慢指针走完一圈之前追上慢指针,因为慢指针进环之后,快慢指针的距离最多就是环的长度,而两个指针在移动时,每次它们之间的距离就会减少一步,因此在慢指针移动一圈之前快指针是一定会追上慢指针的
不难得出,由于快指针的速度是慢指针速度的两倍,相同运动次数的情况下,所以快指针走过的路程就是慢指针走过路程的两倍,由此可推出以下关系
2*(L+X)=L+X+nR
L+X=nR
L=nR-X(也可以表示成(n-1)R+R-X,即从相遇点开始在圈内走n-1圈,最后一圈只走R-X的距离)
(n为1,2,3…,n的大小取决于环的大小,环越小,n越大)
极端情况下,假设n=1,此时 L=R-X
struct ListNode *detectCycle(struct ListNode *head){
struct ListNode *slow=head,*fast=head;
struct ListNode *meet=NULL;
while(fast&&fast->next)//找到相遇点
{
slow=slow->next;
fast=fast->next->next;
if(slow==fast)
{
meet=slow;
break;
}
}
if(fast==NULL||fast->next==NULL)
{
return NULL;
}
//一个从起点开始走,一个从相遇点开始走
struct ListNode *cur1=head;
struct ListNode *cur2=meet;
while(cur1!=cur2)
{
cur1=cur1->next;
cur2=cur2->next;
}
return cur1;
}
思路二
找到相遇点后,定义一个指针meet指向该节点,同时定义一个结点newhead为meet的下一个结点,再将meet->next置空,那么这道题就变成了相交链表的问题了
复制带随机指针的链表
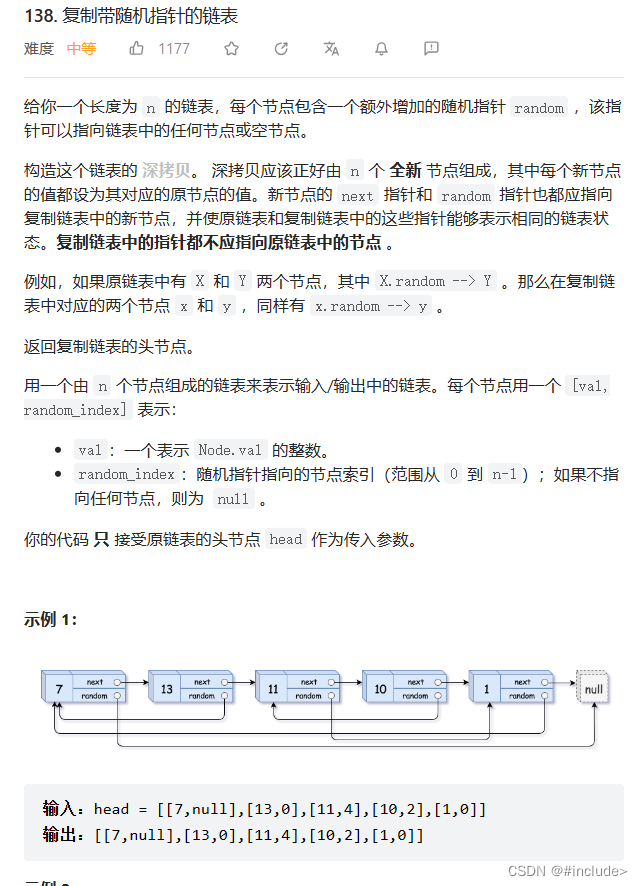
题目链接
思路一
- 先不管random指针,将整个链表都复制下来(时间复杂度O(N))
- 计算每个原结点的random指向的结点在链表中的相对位置,再在复制的链表中对random进行处理(时间复杂度O(N^2))
思路二
- 拷贝结点插在原结点的后面
- 控制每个拷贝结点的random(因为拷贝结点都在其原结点的后面,所以拷贝结点中random所指向的结点也在其原结点中random所指向的结点的后面)
- 将拷贝结点解下来放到一起组成的链表就是要拷贝的链表并恢复原链表
struct Node* copyRandomList(struct Node* head) {
if(head==NULL){
return NULL;
}
struct Node*tmp=head;
while(tmp!=NULL){
struct Node*copy=(struct Node*)malloc(sizeof(struct Node));
copy->val=tmp->val;
struct Node*nextNode=tmp->next;
tmp->next=copy;
copy->next=nextNode;
tmp=copy->next;
}
tmp=head;
while(tmp!=NULL){
if(tmp->random==NULL){//tmp->next就是经tmp拷贝后的结点
tmp->next->random=NULL;
}else{
tmp->next->random=tmp->random->next;
}
tmp=tmp->next->next;
}
struct Node*newhead=head->next;
tmp=newhead;
while(tmp->next!=NULL){
tmp->next=tmp->next->next;
tmp=tmp->next;
}
return newhead;
}















 823
823











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









