







mysql时间函数
select now(); --当前时间
select current_date() --当前日期
select current_timestamp --同now()
select date('2025-04-14 12:34:56) --提取日期部分:2025-04-14
select datediff('2025-4-14','2025-04-10') 日期相差四天
select date_sub('2024-04-14',interval 7 day); --输出:2025-04-07
select date_add('2024-04-14',interval 1 month); --输出:2024-05-10
select year('2025-04-10') --2025
select month(2025-04-10') --04
select day(2025-04-20')
select week('2025-04-10') --第几周
select str_to_date('14-04-2025', '%d-%m-%Y') --输出:2024-04-14
date_format(date,format) select date_format('2025-04-20',"%Y%m%d);
窗口函数,排序类:
公共表达式CTE :with t as , 类似给子查询起一个临时名叫 t
case-when:
判断三角形:
SELECT
x,
y,
z,
CASE
WHEN x + y > z AND x + z > y AND y + z > x THEN 'Yes'
ELSE 'No'
END AS 'triangle'
FROM
triangle
;group by 和partition by 的区别:
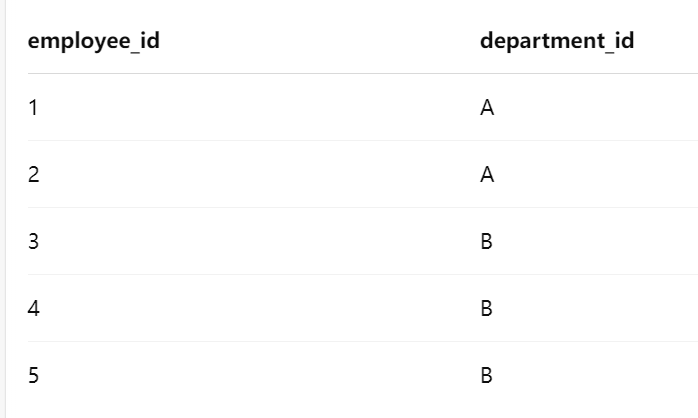
- SELECT department_id, COUNT(*) AS cnt
FROM Employee
GROUP BY department_id;
输出:
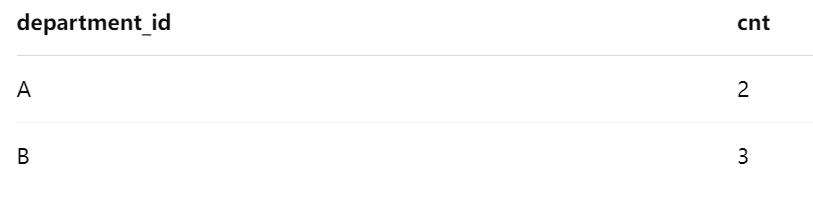
- SELECT employee_id, department_id, COUNT(*) OVER(PARTITION BY department_id) AS cnt
FROM Employee;

组内编号
row_number():
select * ,row_number() over (partition by department order by salary desc) as rn from Employee;每个部分按照工资从高到低排序,并编号
rank(): 有并列跳号
select * ,rank() over (partition by department order by salary desc) as rank from Employee;dense_rank() :无并列跳号
select * ,dense_rank() over(partition by department order by employee_id desc) as rank from Employee;lag()取前一行的工资: 每位员工,显示其部门内工资比他高的那一位的工资。
lead():后一位的工资, 每位员工,显示其部门内工资比他低的那一位的工资。
first_calue():组内第一个值, 每人都显示本部门工资最高的人工资是多少。
last_calue():组内最后一个值, 每人都显示本部门工资最低的人工资是多少。
NTH_VALUE() :
select * ,lag(salary,1,0) over (partition by department order by salary desc) as lag_salary from Employee;
SELECT *,
LEAD(salary, 1, 0) OVER (PARTITION BY department ORDER BY salary DESC) AS next_salary
FROM Employee;
SELECT *,
FIRST_VALUE(salary) OVER (PARTITION BY department ORDER BY salary DESC) AS highest
FROM Employee;
SELECT *,
NTH_VALUE(salary, 2) OVER (PARTITION BY department ORDER BY salary DESC) AS second_highest
FROM Employee;
percent_rank():百分比分位排名:(0~1)之间
SELECT *,
PERCENT_RANK() OVER (PARTITION BY department ORDER BY salary) AS pr
FROM Employee;
全函数对比表
| 函数名 | 作用描述 | 是否允许并列 | 是否跳号 | 常用用途 | 示例代码片段 |
|
| 每组按顺序编号,从 1 开始,不重复 | ❌ 否 | ❌ 否 | 排名、Top N 取唯一 |
|
|
| 排名,有并列,名次会跳号 | ✅ 是 | ✅ 是 | 比赛成绩、奖项排名 |
|
|
| 紧凑排名,有并列但无跳号 | ✅ 是 | ❌ 否 | 分层统计、等级划分 |
|
|
| 取当前行前 n 行的某列值 | 不适用 | 不适用 | 环比计算、对比前值 |
|
|
| 取当前行后 n 行的某列值 | 不适用 | 不适用 | 环比预测、趋势延伸 |
|
|
| 每组中第一个值 | 不适用 | 不适用 | 每组最大/最小/最早/最新值 |
|
|
| 每组中最后一个值(注意窗口范围设定) | 不适用 | 不适用 | 每组最后一个记录 |
|
|
| 每组中第 n 个值 | 不适用 | 不适用 | 业务规则:第2名、第3高、等 |
|
|
| 将排序结果等分成 n 组(桶),返回组编号 | 不适用 | 不适用 | 分档评级、高中低档、层级划分 |
|
|
| 每组中当前行的百分比分位(0 ~ 1 之间) | ✅ 是 | ✅ 是 | 百分位数、分布分析 |
|
|
| 累计分布值(含当前行,占总数的比例,结果也是 0 ~ 1) | ✅ 是 | ❌ 否 | “多少人不高于我”、分布百分比 |
|
with numbered as(select * row_number() over (order byid )
字符按拼接SQL
substring(column_name,start,length):
将从列的值中提取一个子字符串,从指定的起始位置开始,直到指定的长度。
upper():大写
lower():小写
concat(string1,string2):拼接字符
字符的分组和聚合
GROUP_CONCAT(
DISTINCT expression1
ORDER BY expression2
SEPARATOR sep
);leetcode原题:
1484. 按日期分组销售产品 - 力扣(LeetCode)
select sell_date,count(distinct (product)) as num_sold,
group_concat(distinct product order by product separator ',') as products
from Activities group by sell_date order by sell_date asc;
















 650
650

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









