







爬取目的与任务
- 本项目的需求之一是为用户提供个性化的文物介绍,为了丰富deepseek的知识库,提高deepseek回答的准确性,我们计划爬取山东省博物馆的文物介绍作为数据集之一。所以本周我的任务是从山东省博物馆的小程序上爬取各个展馆的文物介绍内容。
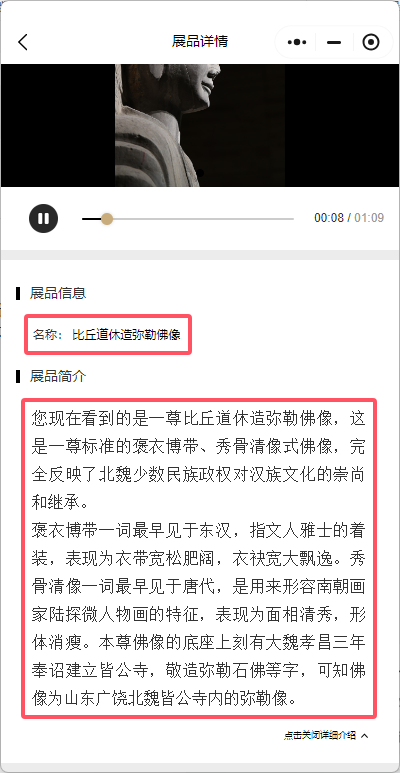
- 需要爬取的内容示例如下:包括文物的名称及其简介
爬取的工具和具体步骤
爬取工具
使用reqable作为抓包工具进行api解析,然后使用python进行具体的爬取操作
reqable解析api
- 参考教程:Python爬虫实战:使用抓包工具爬取微信小程序数据_哔哩哔哩_bilibili
- 主要原理:微信小程序实际上是内嵌在微信的应用程序,所以没有具体的网页,需要借助抓包工具捕获网络请求,分析在客户端和服务端之间的网络请求,再根据分析的内容进行内容爬取
- 具体步骤:
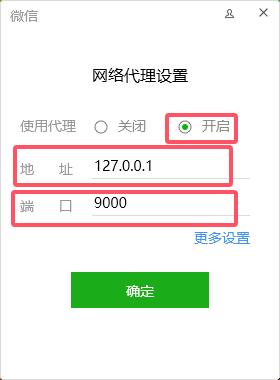
- 在进入微信之前点击右上角的设置,设置代理,端口号与reqable一致,便于后续抓包
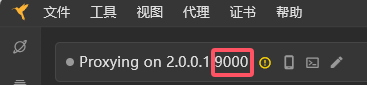
- 启动抓包后,点击小程序中想要访问的文物介绍,并在reqable进行搜索,即可得到相关的api
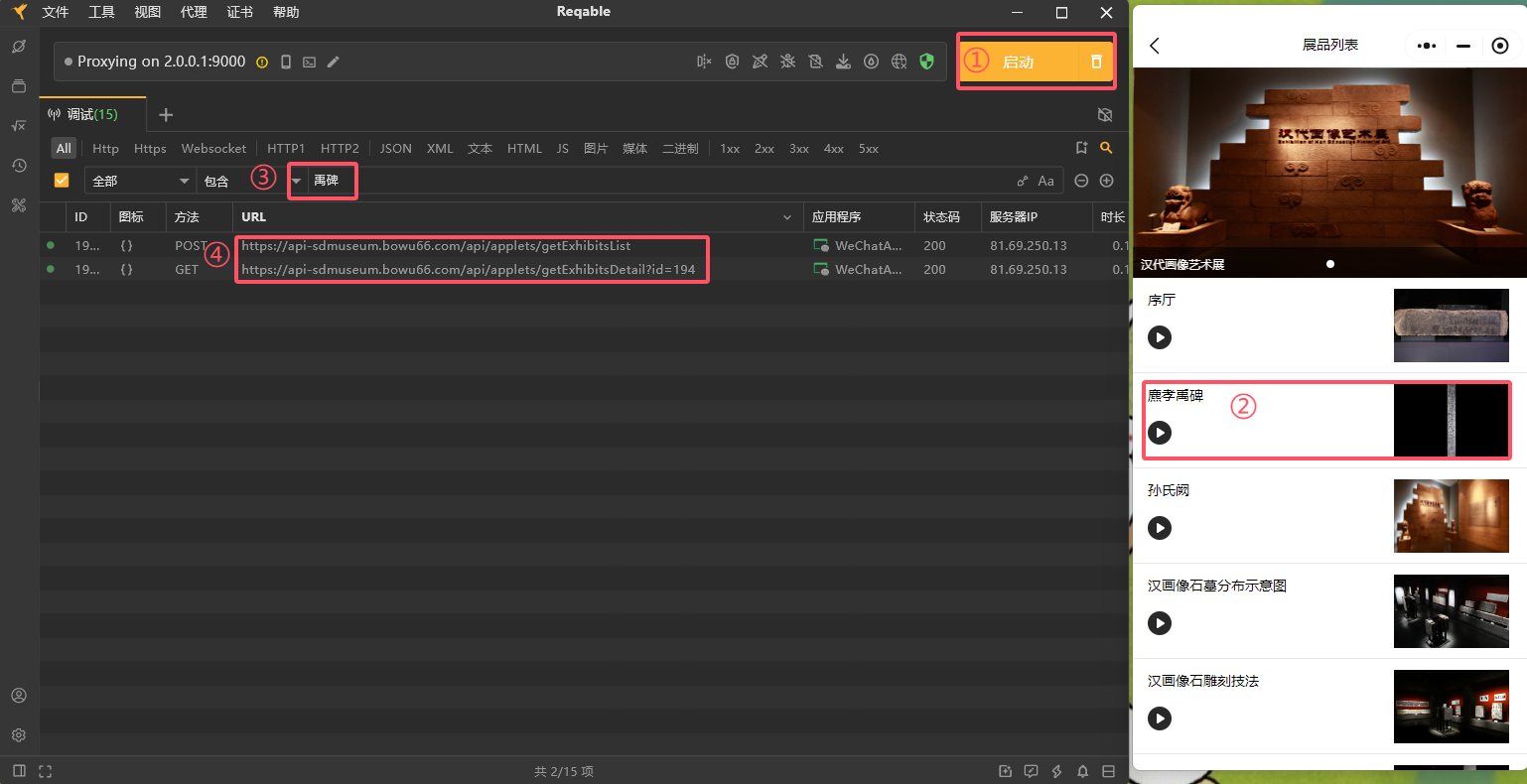
- 分析api可知获取文物介绍的api是由baseURL和id构成的,下面即可根据这一规律进行内容爬取
python爬取内容
- 查看抓包内容,即获取文物列表的api,可以获取文物的id
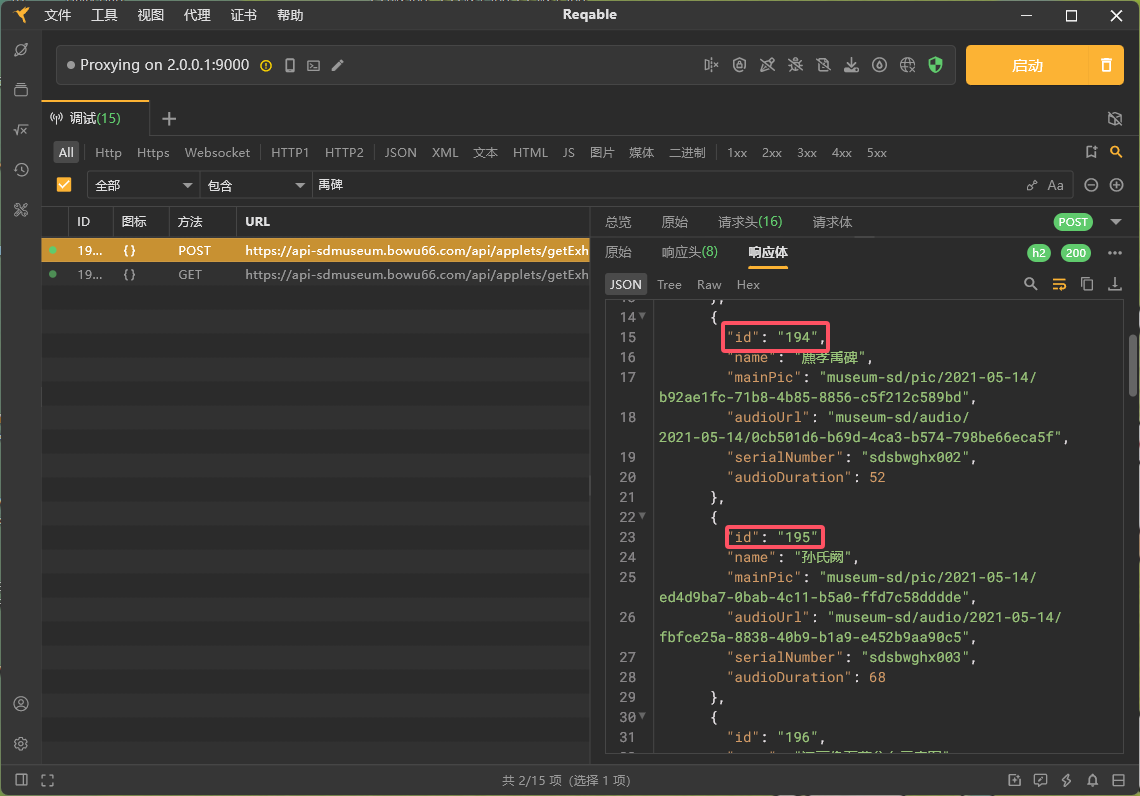
- 编写代码,爬取相关内容,并且进行内容解析,最终将爬取内容存储到json文件中(实际操作中,每个展馆的文物介绍的页面的页面布局各不相同,可能同时包含p标签和span标签,但是都可以通过解析p标签得到结果)
- 对于这个api来说,每个文物介绍对应着不同的id,所以选择按照场馆的不同,分批遍历id,使用beautiful soup解析html页面内容,爬取所需数据
-
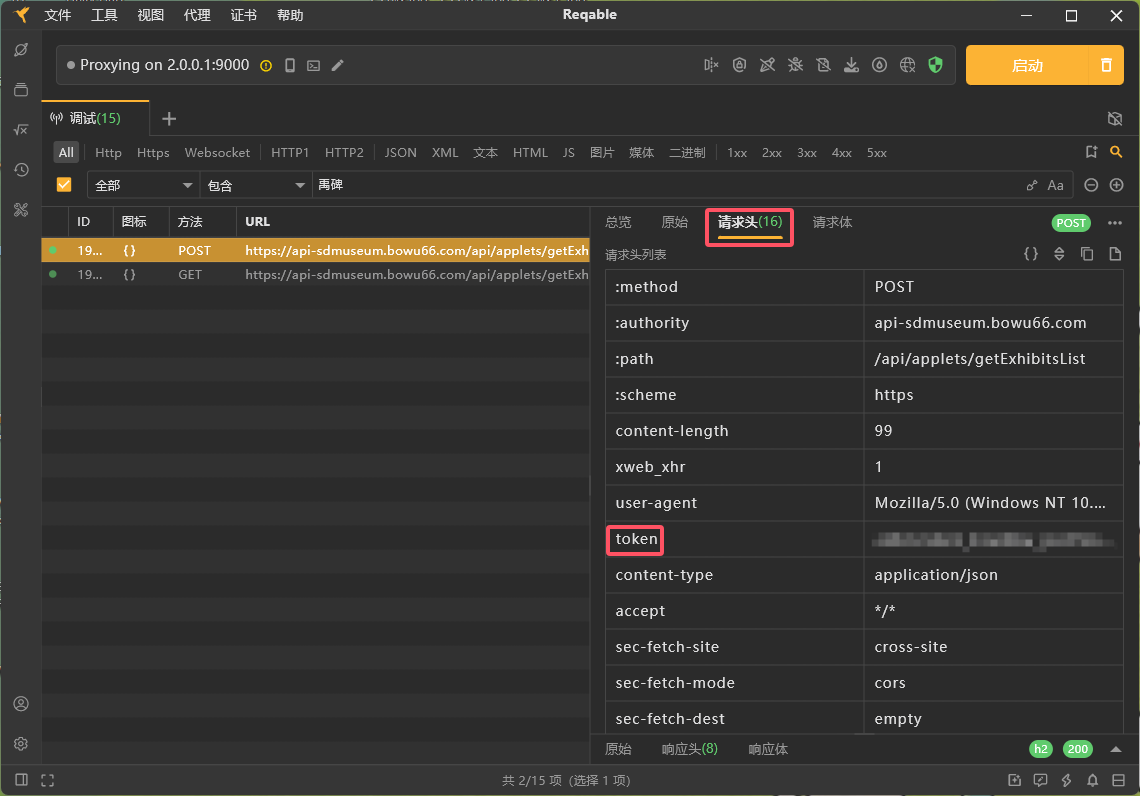
import requests import re import time import random import json from bs4 import BeautifulSoup # 使用BeautifulSoup来解析HTML # 定义基础URL base_url = "https://api-sdmuseum.bowu66.com/api/applets/getExhibitsDetail?id=" headers = { "token": "YourToken" } # 定义存储爬取结果的列表 exhibits_data = [] # 遍历id从37到53 for exhibit_id in range(37, 54): # 54是因为range是左闭右开的 url = base_url + str(exhibit_id) print(url) try: # 发送GET请求 response = requests.get(url=url, headers=headers, verify=False) response.raise_for_status() # 检查请求是否成功 data = response.json() # 提取name字段 name = data["data"]["name"] # 提取about字段中的<p>标签内容 about_html = data["data"]["about"] soup = BeautifulSoup(about_html, "html.parser") # 使用BeautifulSoup解析HTML about_text = "" # 找到所有的<p>标签并提取其内容 for p in soup.find_all("p"): about_text += p.get_text(strip=True) + " " # 将每个<p>标签的内容拼接起来,中间用空格分隔 # 去掉多余的空白 about_text = about_text.strip() # 将提取的数据存储为字典 exhibit_info = { "Name": name, "About": about_text.strip() # 去掉多余的空白 } # 将字典添加到列表中 exhibits_data.append(exhibit_info) # 打印结果 print(f"Exhibit ID: {exhibit_id}") print("Name:", name) print("About:", about_text.strip()) print("-" * 80) # 分隔线 except requests.exceptions.RequestException as e: print(f"Request failed for ID {exhibit_id}: {e}") print("请检查网页链接的合法性或稍后重试。") except KeyError as e: print(f"Data format error for ID {exhibit_id}: {e}") except Exception as e: print(f"Unexpected error for ID {exhibit_id}: {e}") # 设置随机爬取时间间隔 sleep_time = random.randint(5, 10) # 随机生成5到10秒的间隔 print(f"Waiting for {sleep_time} seconds before next request...") time.sleep(sleep_time) # 等待随机时间 # 将爬取到的数据存储为JSON文件 output_file = "exhibits_data2.json" with open(output_file, "w", encoding="utf-8") as json_file: json.dump(exhibits_data, json_file, ensure_ascii=False, indent=4) print(f"All data has been saved to {output_file}") - 身份验证所需的token字段可以在reqable捕获的请求字段中获取
python爬取的最终内容文件
exhibits_data1.json
[
{
"Name": "比丘道休造弥勒佛像",
"About": "您现在看到的是一尊比丘道休造弥勒佛像,这是一尊标准的褒衣博带、秀骨清像式佛像,完全反映了北魏少数民族政权对汉族文化的崇尚和继承。 褒衣博带一词最早见于东汉,指文人雅士的着装,表现为衣带宽松肥阔,衣袂宽大飘逸。秀骨清像一词最早见于唐代,是用来形容南朝画家陆探微人物画的特征,表现为面相清秀,形体消瘦。本尊佛像的底座上刻有大魏孝昌三年奉诏建立皆公寺,敬造弥勒石佛等字,可知佛像为山东广饶北魏皆公寺内的弥勒像。"
},
{
"Name": "山东样式",
"About": "山东样式是指能代表山东北朝佛教造像艺术成就的佛像特征,既包括造像薄衣贴体、倒龙衔莲等造型上的美感,也包括雕刻技术上的精妙。 佛教于东汉时期,经丝绸之路传入中原,到南北朝时期,佛教也迎来了自传入中国后的第一次信仰高潮。佛教造像极为盛行,由于传播路径和地域文化差异等多方因素,不同地区的佛教造像风格不一,石刻佛像在山东地区经历了模仿、融合后,最终形成了自己独特的风格,研究者称之为山东样式。"
},
{
"Name": "道玉造背屏三尊像",
"About": "这是一尊背屏三尊像,石屏上雕刻有一佛二菩萨,主尊佛像着褒衣博带式袈裟,双手施与愿、无畏印立于莲台之上。两旁胁侍菩萨挽高髻,上身裸露,披天衣,着长裙,立于莲台之上。背屏上部正中雕刻有一条倒悬的龙,两侧各三尊飞天。三尊像的莲花座之间浅浮雕龙衔莲花图像,这是山东北朝时期独具特色的造像特征。"
},
{
"Name": "蝉冠菩萨像",
"About": "这尊蝉冠菩萨像是单体圆雕像,戴高冠,披天衣,着长裙,戴项链,佩璎珞,雕像身躯修长,衣着轻薄贴体,衣褶密而不厚,体现了北魏到北齐过渡的山东造像特点。 菩萨像不仅装饰华美,而且雕工精细,是北朝雕塑艺术精品。菩萨像佩戴蝉冠是山东佛教造像艺术的创新,既是佛教本土化、世俗化的体现,也象征了佛教神像高贵和超凡的特质。1976年这批佛像出土后随即留在民间,经多年征集才收回73件。蝉冠菩萨像发现之时就已断为三截,从三位村民家中分别找到,最终拼接成一尊断臂的菩萨像。2008年1月蝉冠菩萨像入藏山东博物馆。"
},
{
"Name": "贴金彩绘菩萨像",
"About": "山东北朝菩萨像最显著的特征是从头到脚满身佩饰,十分繁缛和精细。本尊菩萨像虽头、手臂等部位缺失,但仍不掩其华丽的身姿。 菩萨两肩各垂三缕发辫,肩前各垂一条僧带。上身内着袒右衣,外披帛衣。下着长裙,腰间系带,在裙带的前、后、左、右4个方向各下垂一条宽带。脖子下戴项圈,项圈之下缀华饰,两肩往下披长串的璎珞,璎珞由各种不同形状的宝石串成,于腹前交叉处装饰璧形器。"
}
]
















 1783
1783

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









