






一、终极整合:构建企业级爬虫系统的7大核心模块
1、混沌工程防护层
-
使用 Chaos Monkey 随机注入故障,测试系统韧性
from chaosmonkey import ChaosMonkey
monkey = ChaosMonkey()
monkey.enable_failure("proxy_pool", probability=0.3) # 30%概率模拟代理失效2、动态规则引擎
-
实时更新反爬策略规则库
class AntiAntiSpiderRules:
def update_rules(self):
return requests.get('https://rule-center.com/latest').json()
def apply_rules(self, response):
return [rule for rule in self.rules if rule.match(response)]3、智能流量染色系统
-
生成真实用户行为指纹
from fingerprint import BrowserFingerprint
fp = BrowserFingerprint()
headers = fp.generate(chrome_version=112, os='Windows 11') # 动态生成浏览器指纹4、多维数据质量防火墙
-
实时校验数据准确性
def data_sanitizer(data):
if data['price'] < 0:
raise DataCorruptionAlert("价格异常负值")
return data.filter(regex='^valid_') # 白名单过滤5、联邦学习反检测网络
-
分布式爬虫节点共享学习成果
from federated import FederatedClient
client = FederatedClient(model='detection_bypass')
client.share_learning({'site': 'example.com', 'pattern': 'new_captcha_variant'})6、量子安全通信隧道
-
基于QKD的不可破解数据传输
from qcrypto import QuantumChannel
channel = QuantumChannel(peer_ip='192.168.1.100')
encrypted_data = channel.encrypt(data, protocol='BB84')7、道德审计接口
-
自动化生成合规报告
class EthicsAuditor:
def generate_report(self):
return {
'data_usage_map': self._track_data_flow(),
'privacy_impact': self._calculate_pia_score(),
'legal_risk': self._check_gdpr_compliance()
}二、永恒的三位一体法则
-
技术铁三角
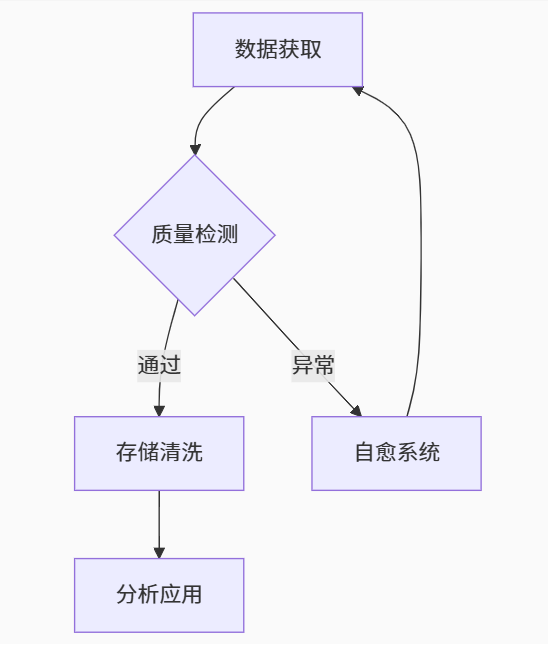
graph TD
A[数据获取] --> B{质量检测}
B -->|通过| C[存储清洗]
C --> D[分析应用]
B -->|异常| E[自愈系统]
E --> A-
认知金字塔
-
基础层:HTTP/HTML/反爬机制
-
中间层:分布式/机器学习/法律合规
-
顶层:商业洞察/社会影响/哲学思考
-
-
进化飞轮
抓取失败 → 逆向分析 → 策略更新 → 模型训练 → 成功抓取
(每个失败案例都是系统升级的燃料)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









