






 本文介绍了一次数据结构课程设计,涵盖了5个题目:成绩分析问题、八皇后问题、迷宫问题、农夫过河问题的求解和哈夫曼编码器。所有题目均使用C语言实现,涉及链表数据结构、文件读写、排序算法和哈夫曼编码。在成绩分析问题中,设计了一个学生信息管理系统,具备添加、查询、排序和统计功能。哈夫曼编码器部分,实现了从输入字符集和权值构建哈夫曼树,进行编码和解码文件的操作。
本文介绍了一次数据结构课程设计,涵盖了5个题目:成绩分析问题、八皇后问题、迷宫问题、农夫过河问题的求解和哈夫曼编码器。所有题目均使用C语言实现,涉及链表数据结构、文件读写、排序算法和哈夫曼编码。在成绩分析问题中,设计了一个学生信息管理系统,具备添加、查询、排序和统计功能。哈夫曼编码器部分,实现了从输入字符集和权值构建哈夫曼树,进行编码和解码文件的操作。
课程设计报告
- 课程设计概述
本次数据结构课程设计共完成5个题目:成绩分析问题,哈夫曼编码器,迷宫问题,八皇后问题,农夫过河问题的求解。
使用环境:C语言。
编译环境:Visual Studio 2022。
- 课程设计题目
1.《成绩分析问题》
(1)实验内容:
成绩分析问题。
(2)问题描述:
设计并实现一个成绩分析系统,能够实现录入,保存一个班级学生多门课程的成绩,并对成绩进行分析等功能。
(3)需求分析:
经过分析,本系统需完成的主要功能如下:
- 通过键盘输入各学生的多门课程的成绩,建立相应的文件input.dat。
- 对文件input.dat中的数据进行处理,要求具有如下功能:
- 按各门课程成绩排序,并生成相应的文件输出。
- 计算每个人的平均成绩,按平均成绩排序,并生成文件。
- 求出各门课程的平均成绩,最高分,最低分,不及格人数,60~69分人数,70~79分人数,80~89分人数,90分以上人数。
- 根据姓名或学号查询某人的各门课程成绩,重名也要能处理。
(4)概要设计:
--=ADT=--
{
Student * SearchByName(Student *head, char *name)// 根据姓名查询学生信息
Student * SearchById(Student *head, char *id)// 根据学号查询学生信息
void Add(Student **head)// 添加一个学生
void Read(Student **head)// 读取文件中的学生信息
void Save(Student * head)// 保存学生信息到文件
void SortAndOutput(Student * head)// 按三门课程成绩排序并输出
void CalculateAverage(Student * head)// 计算每人三门课程的平均成绩并输出
void SortByAverageScoreAndOutput(Student * head)// 按三门课程平均成绩排序并输出
void Statistics(Student * head)// 统计三门课程各自的平均成绩,最高分,最低分,不及格人数,60~69分人数,70~79分人数,80~89分人数,90分以上人数
void ShowMenu() // 显示菜单
}
(5)存储结构:
typedef struct student {
char id[20]; // 学号
char name[20]; // 姓名
float math_score; // 数学成绩
float english_score; // 英语成绩
float computer_score; // 计算机成绩
float average; // 平均成绩
struct student * next; // 指向下一个学生的指针
} Student;
(6)设计思路:
链表数据结构:使用链表来存储学生信息,每个节点表示一个学生。链表的好处是可以动态地添加和删除节点,灵活处理不同数量的学生信息。
- 学生结构体:定义一个学生结构体,包含以下字段:学号、姓名、数学成绩、英语成绩、计算机成绩、平均成绩和指向下一个学生节点的指针。这样可以方便地存储和访问每个学生的相关信息。
- 功能函数:实现各种功能函数,如添加学生、读取文件、保存文件、排序等。这些函数通过操作链表来完成相关操作。
(7)关键算法:
- 冒泡排序算法:用于将学生根据指定的排序规则(如成绩)进行排序。冒泡排序算法的基本思想是比较相邻的两个元素,如果它们的顺序错误就交换位置,继续比较直到完成排序。在学生信息管理系统中,可以根据数学成绩、英语成绩或计算机成绩来排序学生信息。
- 遍历链表:通过使用循环遍历链表的每个节点,可以实现对链表中的数据进行访问、处理和输出等操作。遍历链表是获取每个学生信息、计算平均成绩以及输出结果的关键步骤。
- 文件读写:通过使用二进制文件读写方式,可以将学生信息保存到文件中,或从文件中读取学生信息。在学生信息管理系统中,可以将学生信息以二进制形式写入文件,并在需要时从文件中读取,并重新构建链表。
使用链表作为数据结构,结合冒泡排序算法、链表遍历和文件读写等算法,可以实现学生信息的管理、排序和存储等功能
(8)详细设计:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
// 定义学生结构体
typedef struct student {
char id[20]; // 学号
char name[20]; // 姓名
float math_score; // 数学成绩
float english_score; // 英语成绩
float computer_score; // 计算机成绩
float average; // 平均成绩
struct student * next; // 指向下一个学生的指针
} Student;
// 根据姓名查询学生信息
Student * SearchByName(Student *head, char *name) {
Student *p = head;
while (p != NULL) {
if (strcmp(p->name, name) == 0) { // 找到该学生
return p;
}
p = p->next;
}
return NULL; // 没有找到该学生
}
// 根据学号查询学生信息
Student * SearchById(Student *head, char *id) {
Student *p = head;
while (p != NULL) {
if (strcmp(p->id, id) == 0) { // 找到该学生
return p;
}
p = p->next;
}
return NULL; // 没有找到该学生
}
// 添加一个学生
void Add(Student **head) {
Student * p = (Student *)malloc(sizeof(Student));
printf("请输入学生的学号:");
scanf("%s", p->id);
printf("请输入学生的姓名:");
scanf("%s", p->name);
printf("请输入学生的数学成绩:");
scanf("%f", &p->math_score);
printf("请输入学生的英语成绩:");
scanf("%f", &p->english_score);
printf("请输入学生的计算机成绩:");
scanf("%f", &p->computer_score);
p->average = (p->math_score + p->english_score + p->computer_score) / 3; // 计算平均成绩
// 插入到链表中
Student * temp = NULL;
Student * cur = *head;
while(cur && p->average < cur->average) { // 按平均成绩排序插入
temp = cur;
cur = cur->next;
}
if(temp == NULL) {
p->next = *head;
*head = p;
} else {
temp->next = p;
p->next = cur;
}
printf("添加成功\n");
}
// 读取文件中的学生信息
void Read(Student **head) {
FILE * fp = fopen("input.dat", "rb");
if (fp == NULL) {
printf("文件打开失败\n");
return;
}
Student * p = (Student *)malloc(sizeof(Student));
fread(p, sizeof(Student), 1, fp);
while (!feof(fp)) {
// 插入到链表后面
p->next = *head;
*head = p;
p = (Student *)malloc(sizeof(Student));
fread(p, sizeof(Student), 1, fp);
}
printf("读取成功\n");
fclose(fp);
}
// 保存学生信息到文件
void Save(Student * head) {
FILE * fp = fopen("input.dat", "wb");
if (fp == NULL) {
printf("文件打开失败\n");
return;
}
Student * p = head;
while (p != NULL) {
fwrite(p, sizeof(Student), 1, fp);
p = p->next;
}
printf("保存成功\n");
fclose(fp);
}
// 按三门课程成绩排序并输出
void SortAndOutput(Student * head) {
Student * p = head;
int count = 0;
while (p != NULL) {
count++;
p = p->next;
}
Student ** array = (Student **)malloc(sizeof(Student *) * count); // 存储指针的数组
p = head;
for (int i = 0; i < count; i++) {
array[i] = p;
p = p->next;
}
for (int i = 0; i < count - 1; i++) { // 冒泡排序
for (int j = 0; j < count - 1 - i; j++) {
if (array[j]->math_score + array[j]->english_score + array[j]->computer_score < array[j + 1]->math_score + array[j + 1]->english_score + array[j + 1]->computer_score) {
Student * temp = array[j];
array[j] = array[j + 1];
array[j + 1] = temp;
}
}
}
FILE * fp = fopen("sorted_by_score.dat", "w");
fprintf(fp, "%-20s%-20s%-20s%-20s%-20s%-20s\n", "学号", "姓名", "数学成绩", "英语成绩", "计算机成绩", "平均成绩");
for (int i = 0; i < count; i++) {
fprintf(fp, "%-20s%-20s%-20.1f%-20.1f%-20.1f%-20.1f\n", array[i]->id, array[i]->name, array[i]->math_score, array[i]->english_score, array[i]->computer_score, array[i]->average);
}
printf("排序成功并已保存到sorted_by_score.dat文件中\n");
fclose(fp);
}
// 计算每人三门课程的平均成绩并输出
void CalculateAverage(Student * head) {
FILE * fp = fopen("average_score.dat", "w");
fprintf(fp, "%-20s%-20s%-20s%-20s%-20s%-20s\n", "学号", "姓名", "数学成绩", "英语成绩", "计算机成绩", "平均成绩");
Student * p = head;
while (p != NULL) {
fprintf(fp, "%-20s%-20s%-20.1f%-20.1f%-20.1f%-20.1f\n", p->id, p->name, p->math_score, p->english_score, p->computer_score, p->average);
p = p->next;
}
printf("每人三门课程的平均成绩已计算并保存到average_score.dat文件中\n");
fclose(fp);
}
// 按三门课程平均成绩排序并输出
void SortByAverageScoreAndOutput(Student * head) {
Student * p = head;
int count = 0;
while (p != NULL) {
count++;
p = p->next;
}
Student ** array = (Student **)malloc(sizeof(Student *) * count); // 存储指针的数组
p = head;
for (int i = 0; i < count; i++) {
array[i] = p;
p = p->next;
}
for (int i = 0; i < count - 1; i++) { // 冒泡排序
for (int j = 0; j < count - 1 - i; j++) {
if (array[j]->average < array[j + 1]->average) {
Student * temp = array[j];
array[j] = array[j + 1];
array[j + 1] = temp;
}
}
}
FILE * fp = fopen("sorted_by_average_score.dat", "w");
fprintf(fp, "%-20s%-20s%-20s%-20s%-20s%-20s\n", "学号", "姓名", "数学成绩", "英语成绩", "计算机成绩", "平均成绩");
for (int i = 0; i < count; i++) {
fprintf(fp, "%-20s%-20s%-20.1f%-20.1f%-20.1f%-20.1f\n", array[i]->id, array[i]->name, array[i]->math_score, array[i]->english_score, array[i]->computer_score, array[i]->average);
}
printf("排序成功并已保存到sorted_by_average_score.dat文件中\n");
fclose(fp);
}
// 统计三门课程各自的平均成绩,最高分,最低分,不及格人数,60~69分人数,70~79分人数,80~89分人数,90分以上人数
void Statistics(Student * head) {
float math_total = 0;
float english_total = 0;
float computer_total = 0;
int math_count = 0;
int english_count = 0;
int computer_count = 0;
int fail_count = 0;
int sixty_nine_count = 0;
int seventy_nine_count = 0;
int eighty_nine_count = 0;
int ninety_count = 0;
float math_max = 0;
float english_max = 0;
float computer_max = 0;
float math_min = 100;
float english_min = 100;
float computer_min = 100;
Student * p = head;
while (p != NULL) {
math_count++;
math_total += p->math_score;
if (p->math_score > math_max) math_max = p->math_score;
if (p->math_score < math_min) math_min = p->math_score;
english_count++;
english_total += p->english_score;
if (p->english_score > english_max) english_max = p->english_score;
if (p->english_score < english_min) english_min = p->english_score;
computer_count++;
computer_total += p->computer_score;
if (p->computer_score > computer_max) computer_max = p->computer_score;
if (p->computer_score < computer_min) computer_min = p->computer_score;
if (p->math_score < 60 || p->english_score < 60 || p->computer_score < 60) {
fail_count++;
} else if (p->math_score >= 60 && p->math_score <= 69 && p->english_score >= 60 && p->english_score <= 69 && p->computer_score >= 60 && p->computer_score <= 69) {
sixty_nine_count++;
} else if (p->math_score >= 70 && p->math_score <= 79 && p->english_score >= 70 && p->english_score <= 79 && p->computer_score >= 70 && p->computer_score <= 79) {
seventy_nine_count++;
} else if (p->math_score >= 80 && p->math_score <= 89 && p->english_score >= 80 && p->english_score <= 89 && p->computer_score >= 80 && p->computer_score <= 89) {
eighty_nine_count++;
} else if (p->math_score >= 90 && p->english_score >= 90 && p->computer_score >= 90) {
ninety_count++;
}
p = p->next;
}
printf("数学平均成绩:%f\n", math_total / math_count);
printf("数学最高分:%f\n", math_max);
printf("数学最低分:%f\n", math_min);
printf("英语平均成绩:%f\n", english_total / english_count);
printf("英语最高分:%f\n", english_max);
printf("英语最低分:%f\n", english_min);
printf("计算机平均成绩:%f\n", computer_total / computer_count);
printf("计算机最高分:%f\n", computer_max);
printf("计算机最低分:%f\n", computer_min);
printf("不及格人数:%d\n", fail_count);
printf("60~69分人数:%d\n", sixty_nine_count);
printf("70~79分人数:%d\n", seventy_nine_count);
printf("80~89分人数:%d\n", eighty_nine_count);
printf("90分以上人数:%d\n", ninety_count);
}
// 显示菜单
void ShowMenu() {
printf("\n\n");
printf("请输入数字选择对应功能:\n");
printf("1. 添加一个学生\n");
printf("2. 读取文件中的学生信息\n");
printf("3. 保存学生信息到文件\n");
printf("4. 按三门课程成绩排序并输出\n");
printf("5. 计算每人三门课程的平均成绩并输出\n");
printf("6. 按三门课程平均成绩排序并输出\n");
printf("7. 统计各门课程成绩情况\n");
printf("8. 根据姓名查询该学生各门课成绩\n");
printf("9. 根据学号查询该学生各门课成绩\n");
printf("0. 退出程序\n");
printf("\n\n");
}
int main() {
int choice = -1;
Student * head = NULL; // 链表头指针
while (choice != 0) {
ShowMenu();
scanf("%d", &choice);
switch (choice) {
case 1:
Add(&head);
break;
case 2:
Read(&head);
break;
case 3:
Save(head);
break;
case 4:
SortAndOutput(head);
break;
case 5:
CalculateAverage(head);
break;
case 6:
SortByAverageScoreAndOutput(head);
break;
case 7:
Statistics(head);
break;
case 8:
{
char name[20];
printf("请输入学生的姓名:");
scanf("%s", name);
Student * p = SearchByName(head, name);
if (p != NULL) {
printf("%-20s%-20s%-20s%-20s%-20s\n", "数学成绩", "英语成绩", "计算机成绩", "平均成绩", "总成绩");
printf("%-20.1f%-20.1f%-20.1f%-20.1f%-20.1f\n", p->math_score, p->english_score, p->computer_score, p->average, p->math_score + p->english_score + p->computer_score);
} else {
printf("没有找到该学生\n");
}
break;
}
case 9:
{
char id[20];
printf("请输入学生的学号:");
scanf("%s", id);
Student * p = SearchById(head, id);
if (p != NULL) {
printf("%-20s%-20s%-20s%-20s%-20s\n", "数学成绩", "英语成绩", "计算机成绩", "平均成绩", "总成绩");
printf("%-20.1f%-20.1f%-20.1f%-20.1f%-20.1f\n", p->math_score, p->english_score, p->computer_score, p->average, p->math_score + p->english_score + p->computer_score);
} else {
printf("没有找到该学生\n");
}
break;
}
case 0:
printf("程序已退出\n");
break;
default:
printf("无效的输入,请重新输入\n");
break;
}
}
return 0;
}
(9)调试分析:
本程序主要的操作对象是记录数组,使用的存储结构是结构体数组。另外还有对C语言中关于文件的操作,这是本程序中的一个重点也是难点,是此程序出现问题的重要原因
问题:
现象:文件创建读取问题。在将记录存入文件以后再从文件中读取时就出现错误。
原因:在使用fwrite和fread命令的时候函数的参数没有写正确。fwrite和fread命令的第一个参数是存储数据的首地址,如果没有地址就不正确,那么就不能正常地将数据存到文件中也不能正常地读取。
(10)运行结果:
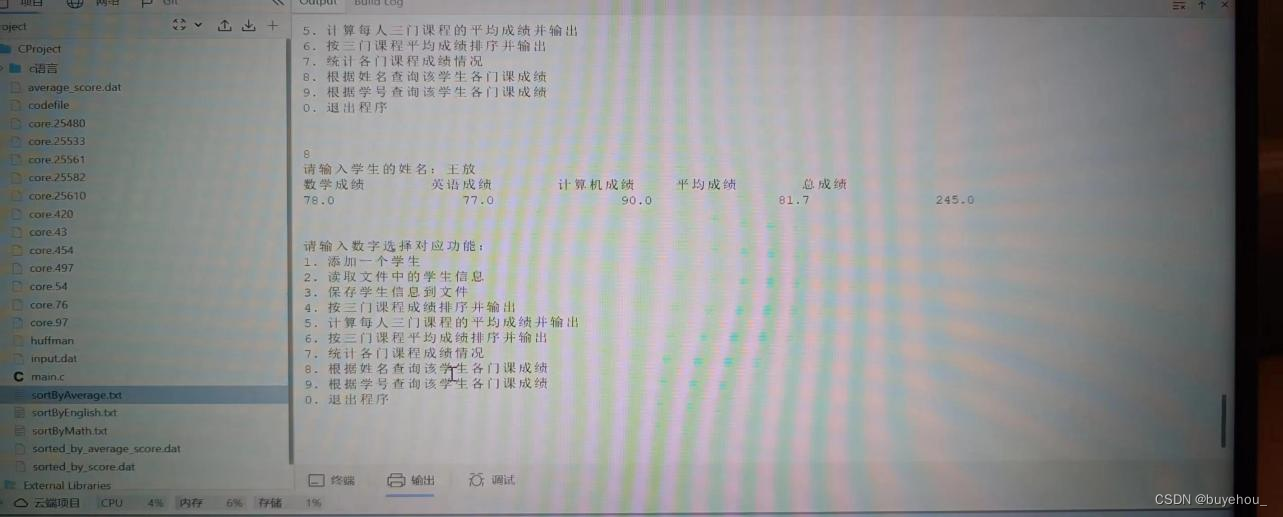
根据姓名或学号查询某人的各门课程成绩,重名也要能处理。
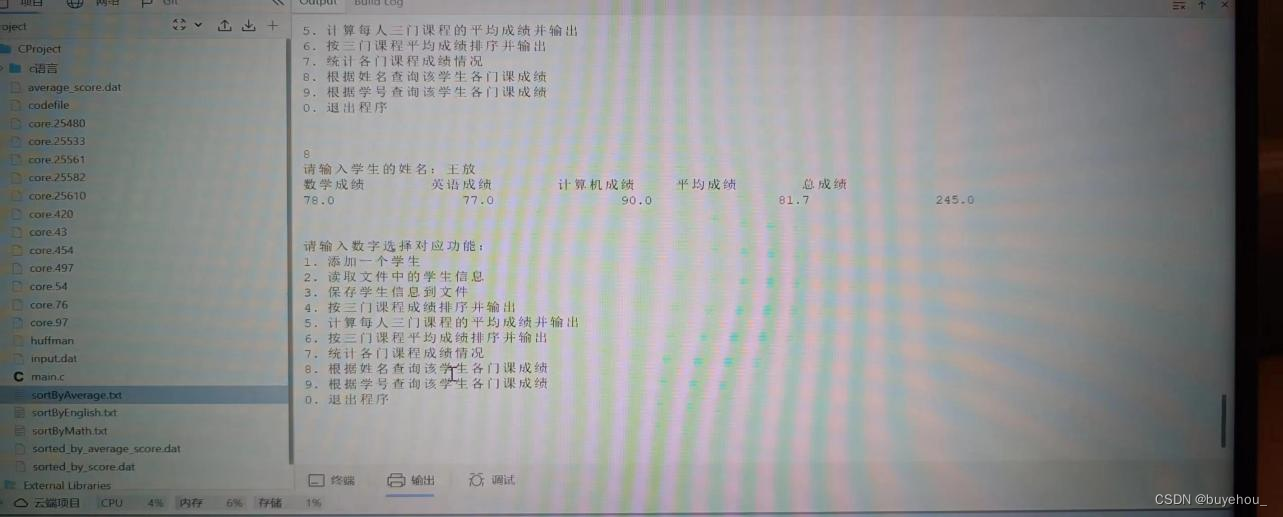
计算每个人的平均成绩,按平均成绩排序,并生成文件。
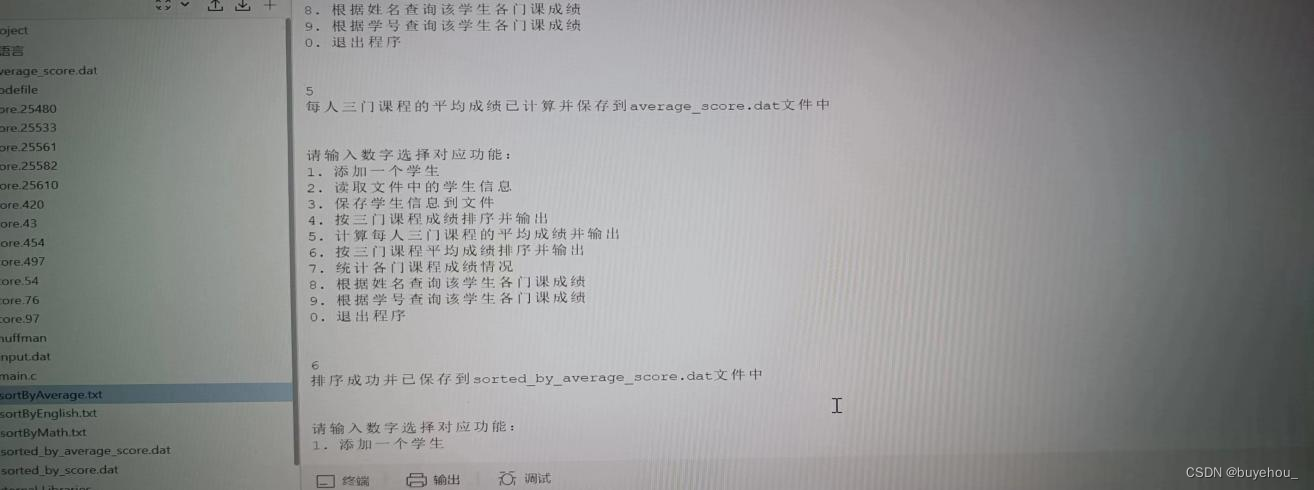
求出各门课程的平均成绩,最高分,最低分,不及格人数,60~69分人数,70~79分人数,80~89分人数,90分以上人数。
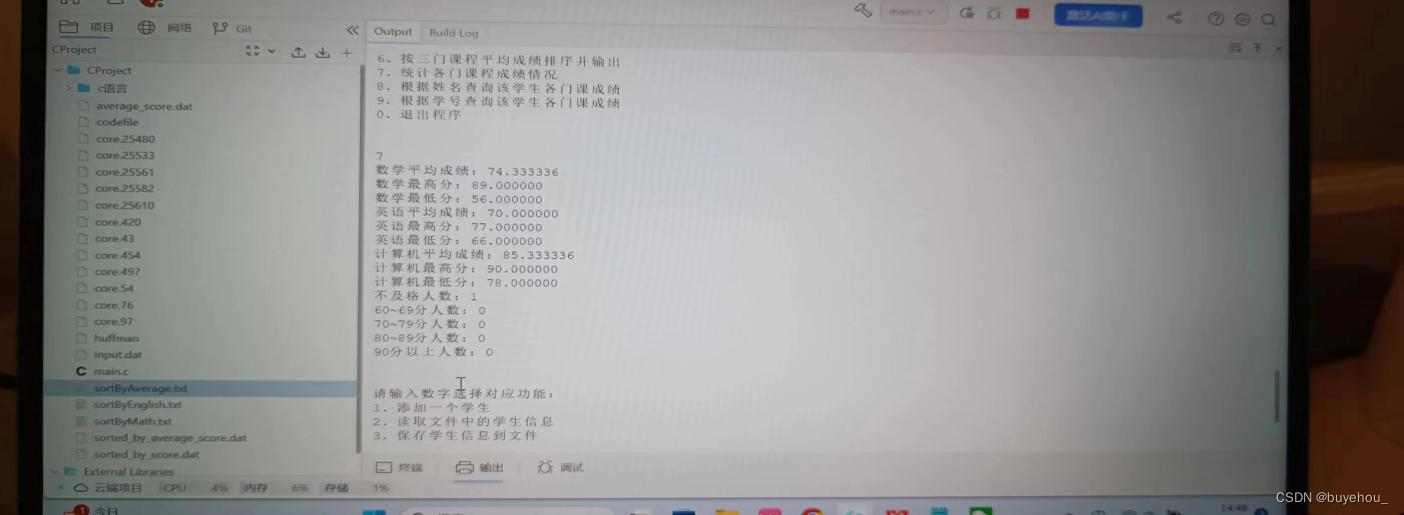
通过键盘输入各学生的多门课程的成绩,建立相应的文件input.dat,按各门课程成绩排序,并生成相应的文件输出。
参考文献:
[1] 谭浩强. C程序设计(第2版).北京:清华大学出版社,2004
[2] 严蔚敏,吴伟民.数据结构.北京:清华大学出版社,2005
2.《八皇后问题》
- 课程设计概述
本次数据结构课程设计共完成5个题目:成绩分析问题,哈夫曼编码器,迷宫问题,八皇后问题,农夫过河问题的求解。
使用环境:C语言。
编译环境:Visual Studio 2022。
(1)实验内容:
八皇后问题。
(2)问题描述:
在8*8的棋盘上,放置8个皇后。要求使这八个皇后不能互相攻击,及每一横行,没一列,每一对角线上均只能放置一个皇后
(3)需求分析:
求出所有可能的方案,输出这些方案,并统计方案总数。
(4)概要设计:
--=ADT=--
{
bool is_valid(int row, int col)// 判断当前位置是否可以放置皇后
void display() // 输出当前皇后的位置
void dfs(int row)// 回溯算法求解
}
(5)存储结构:
int queen[BOARD_SIZE]; // 存储皇后的位置
int count = 0; // 记录方案数
(6)设计思路:
下面是解决八皇后问题的设计思路和关键算法:
1. **数据结构设计**:
- 使用数组 `queen` 存储每一行皇后所在的列号。
- 定义了整型变量 `count`,用于记录找到的方案数。
2. **合法性判断**:
- `is_valid` 函数用于判断当前位置是否可以放置皇后。
- 通过遍历已放置的皇后,检查是否在同一列或同一对角线上存在其他皇后。
- 如果存在同一列或同一对角线上的皇后,则判断当前位置不合法;否则,判断当前位置合法。
3. **输出方案**:
- `display` 函数用于输出当前皇后的位置。
- 遍历 `queen` 数组,按行打印每个皇后所在的列号。
4. **回溯求解**:
- `dfs` 函数使用回溯算法求解八皇后问题。
- 初始调用 `dfs(0)`,从第 0 行开始搜索。
- 在未放置的列中循环尝试放置皇后,如果当前位置合法,则将皇后放置在该位置,并递归调用 `dfs(row + 1)` 继续搜索下一行。
- 当搜索到最后一行时,找到一个解,增加方案数并调用 `display` 输出当前皇后的位置。
- 回溯到上一行时,将当前行的皇后位置重置为 -1。
5. **主函数**:
- 在 `main` 函数中初始化 `queen` 数组,将每个元素初始化为 -1。
- 调用 `dfs(0)` 开始求解八皇后问题。
- 输出找到的方案数。
(7)详细设计:
#include <stdio.h>
#include <stdbool.h>
#include <stdlib.h>
#define BOARD_SIZE 8 // 棋盘大小为8*8
int queen[BOARD_SIZE]; // 存储皇后的位置
int count = 0; // 记录方案数
// 判断当前位置是否可以放置皇后
bool is_valid(int row, int col) {
for (int i = 0; i < row; i++) {
if (queen[i] == col || abs(row - i) == abs(col - queen[i]))
return false; // 在同一列或同一对角线上已经有皇后
}
return true;
}
// 输出当前皇后的位置
void display() {
for (int i = 0; i < BOARD_SIZE; i++)
printf("%d ", queen[i]);
printf("\n");
}
// 回溯算法求解
void dfs(int row) {
if (row == BOARD_SIZE) { // 找到一个解
count++;
display();
} else { // 在未放置的列中尝试放置皇后
for (int col = 0; col < BOARD_SIZE; col++) {
if (is_valid(row, col)) { // 如果当前位置可以放置皇后
queen[row] = col;
dfs(row + 1);
queen[row] = -1; // 回溯
}
}
}
}
int main() {
// 初始化queen数组
for (int i = 0; i < BOARD_SIZE; i++)
queen[i] = -1;
dfs(0); // 从第0行开始搜索
printf("一共找到 %d 种方案\n", count);
return 0;
}
(8)调试分析:
递归算法是解决本问题的关键,此问题难点在于如何把控递归函数的返回条件,是此程序出现问题的重要原因
一种条件是8个皇后放置完成后,返回成功,一种条件是该行中已经没有可以放置的位置,此时返回失败,需要重新放置,返回
问题:
现象:只出现一种解,没有列出所有的解法
原因:递归函数的返回条件出现问题,一种条件是8个皇后放置完成后,返回成功,一种条件是该行中已经没有可以放置的位置,此时返回失败,需要重新放置,返回上一层,将上一个导致本次放置失败的皇后进行清除,然后重新更新其位置,通过逐级放置、或逐级回溯可以达到遍历所有情况找到所有解,应该选择第二种条件。
(9)运行结果:

求出所有可能的方案,输出这些方案,并统计方案总数。
参考文献:
[1] 谭浩强. C程序设计(第2版).北京:清华大学出版社,2004
[2] 严蔚敏,吴伟民.数据结构.北京:清华大学出版社,2005
3.《迷宫问题》
- 课程设计概述
本次数据结构课程设计共完成5个题目:成绩分析问题,哈夫曼编码器,迷宫问题,八皇后问题,农夫过河问题的求解。
使用环境:C语言。
编译环境:Visual Studio 2022。
(1)实验内容:
迷宫问题。
(2)问题描述:
以一个m*n(1<=m,n<=100)的长方阵表示迷宫,0和1分别表示迷宫中的通路和障碍。设计一个程序,对任意设定的迷宫,求出一条从入口到出口的通路,或得出没有通路的结论。
(3)需求分析:
- 找出迷宫中的一条通路。求得的通路以三元组(i,j,d)的形式输出,其中:(i,j)指示迷宫中的一个坐标,d表示走到下一坐标的方向。若迷宫中没有通路,则输出“无解”。
- 找出迷宫中所有可能的通路。
- 如果有通路,找出最短通路。
- 以方阵形式输出迷宫及其通路。
(4)概要设计:
--=ADT=--
{
void stackinit(ST* p);
void stackpush(ST* p, datatype x);
datatype stacktop(ST* p);
void stackpop(ST* p);
int stacksize(ST* p);
bool stackempty(ST* p);
void stackdestroy(ST* p);
存储结构:
typedef PT datatype;//将数据类型改为结构体
typedef struct stack
{
datatype* a;
int top;
int capacity;
}ST;
(5)设计思路:
下面是迷宫问题的设计思路和关键算法:
通过递归方式,不断地选择可通过的下一个位置,并将选择的路径保存在栈中,直到找到迷宫出口或者所有路径都尝试完毕。最终,根据栈中存储的路径信息,打印出正确的路径
1. 定义结构体和类型别名:
- `PT`:表示迷宫中位置的结构体,包含行和列两个成员变量。
- `datatype`:将数据类型改为结构体,即为 `PT` 类型。
- `ST`:表示栈的结构体,包含一个存储元素的数组、栈顶指针和栈的容量。
2. 实现栈的相关操作:
- `stackinit`:初始化栈。
- `stackpush`:入栈操作。
- `stackpop`:移除栈顶元素。
- `stacktop`:获取栈顶元素。
- `stackempty`:判断栈是否为空。
- `stacksize`:获取栈中元素个数。
- `stackdestroy`:销毁栈。
3. 实现判断迷宫中指定位置是否可以通过的函数:
- `ispass`:根据给定的迷宫二维数组、迷宫的行数和列数以及当前位置,判断该位置是否可以通过。即判断当前位置是否在迷宫范围内,并且迷宫中当前位置是否为可通过的路径(值为0)。
4. 实现递归函数求解迷宫路径:
- `getmazepath`:根据给定的迷宫二维数组、迷宫的行数和列数以及当前位置,通过递归方式求解迷宫路径。首先将当前位置入栈,然后判断当前位置是否为迷宫出口,如果是则返回真;否则,将当前位置标记为已访问,并依次判断上、下、左、右四个方向的位置是否满足继续递归的条件,如果满足则递归调用该函数。如果四个方向都不满足条件,则将当前位置出栈,并返回假。
5. 实现打印路径的函数:
- `printpath`:根据给定的栈对象,将栈中的元素按正确顺序打印出来。由于栈先进后出的特性,需要使用一个新的栈将原始栈中的元素倒序存储,然后再从新栈中依次取出栈顶元素打印。
6. 主函数:
- 在主函数中,首先读取迷宫的行数和列数。
- 动态分配二维数组存储迷宫的数据。
- 读取迷宫数据。
- 初始化路径栈,并调用递归函数求解迷宫路径。
- 如果找到了路径,调用打印路径的函数输出路径;否则,输出"没有通路"。
- 销毁路径栈。
- 释放动态分配的内存空间。
(6)详细设计:
#define _CRT_SECURE_NO_WARNINGS
#include<stdio.h>
#include<stdlib.h>
#include<stdbool.h>
#include<assert.h>
typedef struct postion
{
int row;//行
int col;//列
}PT;
typedef PT datatype;//将数据类型改为结构体
typedef struct stack
{
datatype* a;
int top;
int capacity;
}ST;
void stackinit(ST* p);
void stackpush(ST* p, datatype x);
datatype stacktop(ST* p);
void stackpop(ST* p);
int stacksize(ST* p);
bool stackempty(ST* p);
void stackdestroy(ST* p);
void stackinit(ST* p)//栈的初始化
{
assert(p);
p->a = NULL;
p->top = 0;
p->capacity = 0;
}
void stackpush(ST* p, datatype x)//入栈
{
assert(p);
if (p->top == p->capacity)
{
int newcapacity = p->capacity == 0 ? 4 : 2 * p->capacity;
datatype* tmp = (datatype*)realloc(p->a, sizeof(datatype) * newcapacity);
if (tmp != NULL)
{
p->a = tmp;
p->capacity = newcapacity;
}
}
p->a[p->top] = x;
p->top++;
}
void stackpop(ST* p)//移除栈顶元素
{
assert(p);
assert(p->top > 0);
p->top--;
}
datatype stacktop(ST* p)//出栈
{
assert(p);
assert(p->top > 0);
return p->a[p->top - 1];
}
bool stackempty(ST* p)//是否为空
{
return p->top == 0;
}
int stacksize(ST* p)//栈中元素个数
{
assert(p);
return p->top;
}
void stackdestroy(ST* p)//内存销毁
{
assert(p);
free(p->a);
p->a = NULL;
p->top = 0;
p->capacity = 0;
}
bool ispass(int** maze, int N, int M, PT pos)
{
if (pos.row >= 0 && pos.row < N && pos.col >= 0 && pos.col < M && maze[pos.row][pos.col] == 0)
{ //坐标不越界并且该处位置==0
return true;
}
return false;
}
ST path;
bool getmazepath(int** maze, int N, int M, PT cur)
{
stackpush(&path, cur);//入栈
if (cur.row == N - 1 && cur.col == M - 1)//找到出口就返回真
{
return true;
}
maze[cur.row][cur.col] = 2;//先将目前所处位置赋值为2
PT next;
next = cur;//上
next.row -= 1;
if (ispass(maze, N, M, next))//判断上的位置是否满足继续的条件
{
if (getmazepath(maze, N, M, next))//满足条件就递归
{
return true;//为了防止找到继续递归下去 返回真
}
}
next = cur;//下
next.row += 1;
if (ispass(maze, N, M, next))//判断下的位置是否满足继续的条件
{
if (getmazepath(maze, N, M, next))//满足条件就递归
{
return true;//为了防止找到继续递归下去 返回真
}
}
next = cur;//左
next.col -= 1;
if (ispass(maze, N, M, next))//判断左的位置是否满足继续的条件
{
if (getmazepath(maze, N, M, next))//满足条件就递归
{
return true;//为了防止找到继续递归下去 返回真
}
}
next = cur;//右
next.col += 1;
if (ispass(maze, N, M, next))//判断右的位置是否满足继续的条件
{
if (getmazepath(maze, N, M, next))//满足条件就递归
{
return true;//为了防止找到继续递归下去 返回真
}
}
stackpop(&path); //如果上下左右都不满足就移除栈顶元素
return false;//如果上下左右都不满足就返回false
}
void printpath(ST* ps)//由于此时的path栈要打印出来会倒着出,所以又重新创建了一个栈,将数据导进去
{
ST rpath;
stackinit(&rpath);
while (!stackempty(&path))
{
stackpush(&rpath, stacktop(&path));
stackpop(&path);
}
while (!stackempty(&rpath))
{
PT top = stacktop(&rpath);//此时数据类型被改为PT
printf("(%d,%d)", top.row, top.col);
printf("\n");
stackpop(&rpath);
}
stackdestroy(&rpath);//内存销毁
}
int main()
{
int N = 0;
int M = 0;
while (scanf("%d%d", &N, &M) != EOF)//多组输入
{
//动态开辟二维数组
//1.开辟N个指针数组
int** maze = (int**)malloc(sizeof(int*) * N);
//2.开辟M个空间
int i = 0;
for (i = 0; i < N; i++)
{
maze[i] = (int*)malloc(sizeof(int) * M);
}
int j = 0;
for (i = 0; i < N; i++)
{
for (j = 0; j < M; j++)
{
scanf("%d", &maze[i][j]);
}
}
PT entry = { 0,0 };
stackinit(&path);
if (getmazepath(maze, N, M, entry))
{
printpath(&path);//输出通路的路径
}
else
{
printf("没有通路\n");
}
stackdestroy(&path);
//释放空间
//1.释放N个数组指针指向的空间
for (i = 0; i < N; i++)
{
free(maze[i]);
}
//2.将N个指针数组整体释放
free(maze);
maze = NULL;
}
return 0;
}
(7)调试分析:
回溯法作为本题的重要算法,此问题难点在于如何让循环停止,不无限循环下去,这是此程序出现问题的重要原因
问题:
现象:程序一直循环,程序崩溃
原因:没有判断下一个的位置是否满足继续的条件,在回溯时导致重复循环,判断该条件后,如果满足则继续递归,返回true,否则false。
(8)运行结果:
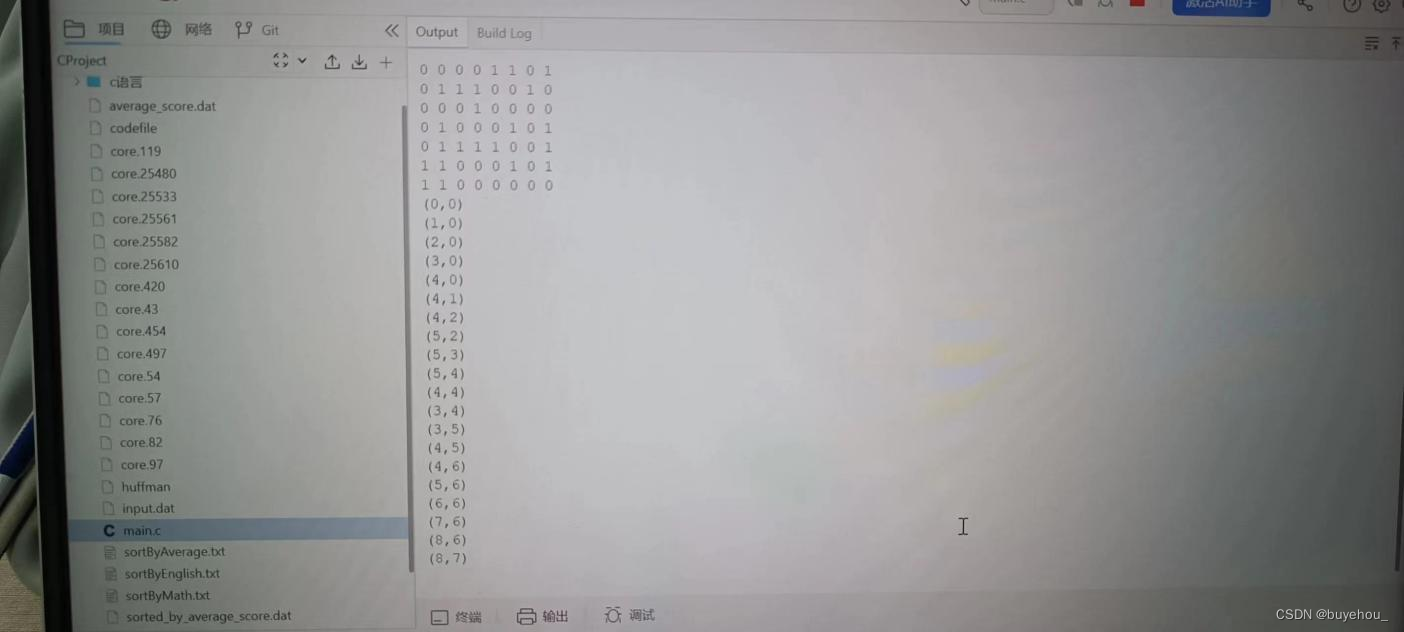
找出迷宫中的一条通路。求得的通路以三元组(i,j,d)的形式输出,其中:(i,j)指示迷宫中的一个坐标,d表示走到下一坐标的方向。若迷宫中没有通路,则输出“无解”。
参考文献:
[1] 谭浩强. C程序设计(第2版).北京:清华大学出版社,2004
[2] 严蔚敏,吴伟民.数据结构.北京:清华大学出版社,2005
4.《农夫过河问题的求解》
- 课程设计概述
本次数据结构课程设计共完成5个题目:成绩分析问题,哈夫曼编码器,迷宫问题,八皇后问题,农夫过河问题的求解。
使用环境:C语言。
编译环境:Visual Studio 2022。
(1)实验内容:
农夫过河问题的求解。
(2)问题描述:
一个农夫带着一只狼,一只羊和一颗白菜,身处河的南岸。他要把这些东西全部运到北岸。他面前只有一条小船,船只能容下他和一件物品。只有农夫才能乘船。如果农夫在场,则狼不能吃羊,羊不能吃白菜,否则狼会吃羊,羊会吃白菜,所以农夫不能留下羊和白菜自己离开,也不能留下狼和羊自己离开,而狼不吃白菜。
(3)需求分析:
编写程序求农夫将所有东西运过河的方案
--=ADT=--
{
int safe(int f, int w, int s, int v)//判断是否安全
int connected(int p, int q)// 判断顶点vx[p]和vx[q]是否连接
void create_graph()// 创建图
void print_path(int u, int v)// 输出方法
void dfs_path(int u, int v) //深度搜索路径
}
存储结构:
typedef struct {
int farmer, wolf, sheep, vegetable;
} VERTEX;
VERTEX vx[MAX];
//而为数组存处有向图的邻接矩阵
int matrix[MAX][MAX], vnum, visited[MAX], path[MAX];
(4)设计思路:
下面是农夫过河问题的设计思路和关键算法:
1. **数据结构设计**:
- 使用结构体 `VERTEX` 表示一个状态,其中包括了农夫、狼、羊和白菜的位置信息。
- 定义了顶点数组 `vx`,用于存储所有可能的状态。
- 声明了邻接矩阵 `matrix`,用于表示状态之间的连接关系。
- 定义了标记数组 `visited`,用于记录顶点是否被访问过。
- 声明了路径数组 `path`,用于存储路径信息。
2. **安全性判断**:
- `safe` 函数用于判断当前状态是否安全。
- 根据题目规则,如果农夫和羊不在同一岸边,并且(狼与羊在同一岸边,或者羊与白菜在同一岸边),则认为当前状态是不安全的。否则,认为是安全的。
3. **连接性判断**:
- `connected` 函数用于判断两个顶点是否相连。
- 根据题目规则,只有当农夫和另一样物体在同一岸边,并且其他物体在两个顶点中的位置相同的情况下,两个顶点才能相连。
4. **图的创建**:
- `create_graph` 函数用于创建图。
- 使用四重嵌套的循环遍历了所有可能的顶点状态,并利用 `safe` 函数判断当前状态是否安全。
- 如果当前状态安全,则将该状态下各个物体的位置信息赋值给对应的顶点结构体 `vx[vnum]`,并增加 `vnum` 的值,表示顶点数量增加了一个。
- 接下来,再次使用两重循环遍历每对顶点,通过调用 `connected` 函数判断两个顶点是否相连。如果两个顶点是相连的,则在邻接矩阵 `matrix` 中设置对应位置的值为 1,表示它们之间有一条边;否则,将对应位置的值设置为 0。
5. **深度优先搜索**:
- `dfs_path` 函数用于进行深度优先搜索,并找到从起点到终点的路径。
- 先将起点标记为已访问。
- 遍历与当前节点相连的未访问过的节点,将其添加到路径中,并以该节点作为新的起点递归调用 `dfs_path` 函数。
- 通过递归的方式,不断向前搜索路径,直到回溯到起点节点。
6. **输出路径**:
- `print_path` 函数用于输出路径。
- 从终点节点开始回溯,沿着路径向前输出节点,直到回溯到起点节点。
7. **主函数**:
- 在 `main` 函数中调用 `create_graph` 创建图,然后初始化标记数组 `visited` 。
- 设置起点和终点的索引,并调用 `dfs_path` 进行深度优先搜索。
- 如果终点被访问过,则输出路径。
(5)详细设计:
#include "stdio.h"
#define MAX 20
typedef struct {
int farmer, wolf, sheep, vegetable;
} VERTEX;
VERTEX vx[MAX];
//而为数组存处有向图的邻接矩阵
int matrix[MAX][MAX], vnum, visited[MAX], path[MAX];
//判断是否安全
int safe(int f, int w, int s, int v)
{
if (f != s &&
(w == s ||
s == v)) //当农夫和羊,(羊或者白菜,浪或者羊中的一种),不再同一岸边时
return (0);
else
return (1);
}
int connected(int p, int q) { // 判断顶点vx[p]和vx[q]是否连接
int k = 0;
if (vx[p].wolf != vx[q].wolf)
k++;
if (vx[p].sheep != vx[q].sheep)
k++;
if (vx[p].vegetable != vx[q].vegetable)
k++;
if (vx[p].farmer != vx[q].farmer && k <= 1) {
return (1);
} else
return (0);
}
void create_graph() { // 创建图
int i, j, f, w, s, v;
vnum = 0;
for (f = 0; f <= 1; f++)
for (w = 0; w <= 1; w++)
for (s = 0; s <= 1; s++)
for (v = 0; v <= 1; v++)
if (safe(f, w, s, v) == 1) {
vx[vnum].farmer = f;
vx[vnum].wolf = w;
vx[vnum].sheep = s;
vx[vnum].vegetable = v;
vnum++;
}
for (i = 0; i < vnum; i++)
for (j = 0; j < vnum; j++)
if (connected(i, j) == 1) {
matrix[i][j] = 1;
} else
matrix[i][j] = 0;
return;
}
void print_path(int u, int v) { // 输出方法
int k = u;
while (k != v) {
printf("%d %d %d %d\n", vx[k].farmer, vx[k].wolf, vx[k].sheep,
vx[k].vegetable);
k = path[k];
}
printf("%d %d %d %d\n", vx[k].farmer, vx[k].wolf, vx[k].sheep,
vx[k].vegetable);
}
void dfs_path(int u, int v) {
int j;
visited[u] = 1;
for (j = 0; j < vnum; j++)
if (matrix[u][j] == 1 && visited[j] == 0 && visited[v] == 0) {
path[u] = j;
dfs_path(j, v);
}
}
int main() {
int i, j;
create_graph();
for (i = 0; i < vnum; ++i)
visited[i] = 0;
i = 0;
j = vnum - 1;
dfs_path(i, j);
if (visited[j] == 1) {
printf(">>>>the path is >>>\n");
print_path(i, j);
}
getchar();
}
(6)调试分析:
本题主要采用构建农夫,狼,羊,白菜的图,并进行图的深度优先遍历,本题中对图的创建和深度搜索是此程序出现问题的重要原因
问题:
现象:程序运行结果只有最后状态农夫狼羊白菜,没有列出过程。
原因:每一次深度搜索成功的时候没有将结果打印出来,导致最后只有最终状态。
(7)运行结果:
求农夫将所有东西运过河的方案

参考文献:
[1] 谭浩强. C程序设计(第2版).北京:清华大学出版社,2004
[2] 严蔚敏,吴伟民.数据结构.北京:清华大学出版社,2005
5.《哈夫曼编码器》
- 课程设计概述
本次数据结构课程设计共完成5个题目:成绩分析问题,哈夫曼编码器,迷宫问题,八皇后问题,农夫过河问题的求解。
使用环境:C语言。
编译环境:Visual Studio 2022。
(1)实验内容:
哈夫曼编码器
(2)问题描述:
设计并实现一个哈夫曼码的编译码系统
(3)需求分析:
初始化:从终端读入字符集大小n,及n个字符和m个权值,建立哈夫曼树,并将其保存在磁盘huffman文件中
编码:利用已建好的哈夫曼树对待发送电文(读取来自文件tobetrans.dat)进行编码,然后将结果保存在磁盘文件codefile中。
解码:利用已建好的哈夫曼树,对文件codefile中代码进行译码,结果存入文件textfile中。
打印代码文件:将文件codefile显示在终端上,每行50个代码,同时将此字符形式的编码文件写入文件codefile中。
(4)概要设计:
--=ADT=--
{
int read_input(HuffNode nodes[])输入字符集及其权值
void init_tree(HuffTree tree[], int n)初始化哈夫曼树
void build_tree(HuffTree tree[], HuffNode nodes[], int n)建立哈夫曼树
void get_code(HuffTree tree[], HuffNode nodes[], int n) 获取哈夫曼编码
void encode_file(HuffNode nodes[], int n, char* filename)编码文件
void decode_file(HuffTree tree[], HuffNode nodes[], int n, char* infile, char* outfile) 解码文件
}
(5)存储结构:
// 结构体:哈夫曼树节点
typedef struct {
char ch; // 字符
int weight; // 权值
char code[CODE_MAX_LEN]; // 编码
} HuffNode;
// 结构体:哈夫曼树
typedef struct {
int lchild, rchild, parent; // 左子树、右子树、父节点位置
int weight; // 权值
} HuffTree;
(6)设计思路:
该代码实现了哈夫曼编码和解码的功能。下面是代码的设计思路和关键算法:
1. 结构体的定义:
- HuffNode:保存字符、权值以及编码。
- HuffTree:保存哈夫曼树节点的信息,包括左子树、右子树、父节点位置和权值。
2. read_input函数:用于读取字符集及其权值。
- 从用户输入中获取字符集的大小n。
- 循环n次,读取每个字符和对应的权值,并保存到HuffNode数组中。
3. init_tree函数:用于初始化哈夫曼树。
- 遍历HuffTree数组,将每个节点的成员变量初始化为默认值(-1或0)。
4. build_tree函数:用于构建哈夫曼树。
- 首先将叶子节点的权值初始化为对应字符的权值。
- 循环n-1次,每次找到权值最小和次小的两个节点,并合并它们构成新的节点。
- 将新节点的父节点设置为n+i,左子树和右子树分别设置为权值最小和次小的节点。
- 更新新节点的权值为合并后的权值。
5. get_code函数:用于获取哈夫曼编码。
- 从根节点开始,向下遍历每个叶子节点,生成对应叶子节点的编码。
- 编码的生成通过从叶子节点往上遍历,如果该节点为左子树,则编码为'0',否则为'1'。
- 将编码保存到对应的HuffNode节点的code数组中。
6. encode_file函数:用于编码文件。
- 打开输入文件和输出文件。
- 逐个读取输入文件的字符,查找对应字符的编码,并将编码写入输出文件。
7. decode_file函数:用于解码文件。
- 打开输入文件和输出文件。
- 初始化解码起始位置为根节点的位置。
- 逐个读取输入文件的字符,根据字符值('0'或'1')选择左子树或右子树,并更新当前位置。
- 如果当前位置为叶子节点,则将对应字符写入输出文件,并将当前位置重置为根节点。
8. 主函数main:
- 声明并定义HuffNode数组和HuffTree数组。
- 调用read_input函数读取字符集及其权值。
- 调用init_tree函数初始化哈夫曼树。
- 调用build_tree函数构建哈夫曼树。
- 调用get_code函数获取哈夫曼编码。
- 调用encode_file函数编码文件。
- 调用decode_file函数解码文件。
该代码通过构建哈夫曼树来实现字符编码和解码的功能,可以通过输入字符集及其权值和指定的文件来进行编码和解码操作。
(7)详细设计:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#define MAX_N 100 // 字符集大小上限
#define CODE_MAX_LEN 20 // 编码长度上限
// 结构体:哈夫曼树节点
typedef struct {
char ch; // 字符
int weight; // 权值
char code[CODE_MAX_LEN]; // 编码
} HuffNode;
// 结构体:哈夫曼树
typedef struct {
int lchild, rchild, parent; // 左子树、右子树、父节点位置
int weight; // 权值
} HuffTree;
// 输入字符集及其权值
int read_input(HuffNode nodes[]) {
int n;
printf("Please enter the character set size: ");
scanf("%d", &n);
printf("Please enter the characters and their weights:\n");
for (int i = 0; i < n; i++) {
printf("[%d]: ", i + 1);
getchar();
scanf("%c%d", &nodes[i].ch, &nodes[i].weight);
}
return n;
}
// 初始化哈夫曼树
void init_tree(HuffTree tree[], int n) {
for (int i = 0; i < 2 * n - 1; i++) {
tree[i].lchild = -1;
tree[i].rchild = -1;
tree[i].parent = -1;
tree[i].weight = 0;
}
}
// 建立哈夫曼树
void build_tree(HuffTree tree[], HuffNode nodes[], int n) {
// 初始化叶子节点
for (int i = 0; i < n; i++) {
tree[i].weight = nodes[i].weight;
}
// 构建哈夫曼树
int min1, min2, pos1, pos2;
for (int i = 0; i < n - 1; i++) {
min1 = min2 = __INT_MAX__;
pos1 = pos2 = -1;
// 找到权值最小和次小的两个节点
for (int j = 0; j < n + i; j++) {
if (tree[j].parent == -1) { // 如果该节点未被处理过
if (tree[j].weight <= min1) {
min2 = min1;
pos2 = pos1;
min1 = tree[j].weight;
pos1 = j;
} else if (tree[j].weight <= min2) {
min2 = tree[j].weight;
pos2 = j;
}
}
}
// 合并两个节点,构成新的节点
tree[pos1].parent = n + i;
tree[pos2].parent = n + i;
tree[n + i].weight = min1 + min2;
tree[n + i].lchild = pos1;
tree[n + i].rchild = pos2;
}
}
// 获取哈夫曼编码
void get_code(HuffTree tree[], HuffNode nodes[], int n) {
char code[CODE_MAX_LEN];
int top;
for (int i = 0; i < n; i++) {
top = CODE_MAX_LEN - 1;
int p = i;
while (tree[p].parent != -1) { // 从叶子节点往上遍历
if (tree[tree[p].parent].lchild == p) { // 如果该节点是左子树
code[--top] = '0';
} else { // 如果该节点是右子树
code[--top] = '1';
}
p = tree[p].parent;
}
strcpy(nodes[i].code, &code[top]);
}
}
// 编码文件
void encode_file(HuffNode nodes[], int n, char* filename) {
FILE* fin = fopen(filename, "r");
if (fin == NULL) {
printf("Failed to open file.\n");
exit(1);
}
FILE* fout = fopen("codefile", "w");
if (fout == NULL) {
printf("Failed to open file.\n");
exit(1);
}
char ch;
while ((ch = fgetc(fin)) != EOF) {
for (int i = 0; i < n; i++) {
if (nodes[i].ch == ch) {
fprintf(fout, "%s", nodes[i].code);
break;
}
}
}
fclose(fin);
fclose(fout);
printf("Code file has been saved to 'codefile'.\n");
}
// 解码文件
void decode_file(HuffTree tree[], HuffNode nodes[], int n, char* infile, char* outfile) {
FILE* fin = fopen(infile, "r");
if (fin == NULL) {
printf("Failed to open file.\n");
exit(1);
}
FILE* fout = fopen(outfile, "w");
if (fout == NULL) {
printf("Failed to open file.\n");
exit(1);
}
int p = 2 * n - 2;
char ch;
while ((ch = fgetc(fin)) != EOF) {
if (ch == '0') {
p = tree[p].lchild;
} else {
p = tree[p].rchild;
}
if (tree[p].lchild == -1 && tree[p].rchild == -1) { // 如果已到达叶子节点
fprintf(fout, "%c", nodes[p].ch);
p = 2 * n - 2;
}
}
fclose(fin);
fclose(fout);
printf("Decoded file has been saved to '%s'.\n", outfile);
}
// 主函数
int main() {
HuffNode nodes[MAX_N];
HuffTree tree[MAX_N * 2 - 1];
int n = read_input(nodes); // 读入字符集及其权值
init_tree(tree, n); // 初始化哈夫曼树
build_tree(tree, nodes, n); // 构建哈夫曼树
get_code(tree, nodes, n); // 获取哈夫曼编码
encode_file(nodes, n, "datafile"); // 编码文件
decode_file(tree, nodes, n, "codefile", "outputfile"); // 解码文件
return 0;
}
(8)调试分析:
哈夫曼编码问题其难点在于哈夫曼树的建立和生成哈夫曼编码表,这也是程序易出现错误的原因。
问题:
现象:生成哈夫曼编码表时字符编码重复,解码错误。
原因:权值相同的节点没有按照特定顺序进行排序,或者在创建父节点时没有正确处理权值相等。
(9)运行结果:
初始化:从终端读入字符集大小n,及n个字符和m个权值,建立哈夫曼树,并将其保存在磁盘huffman文件中
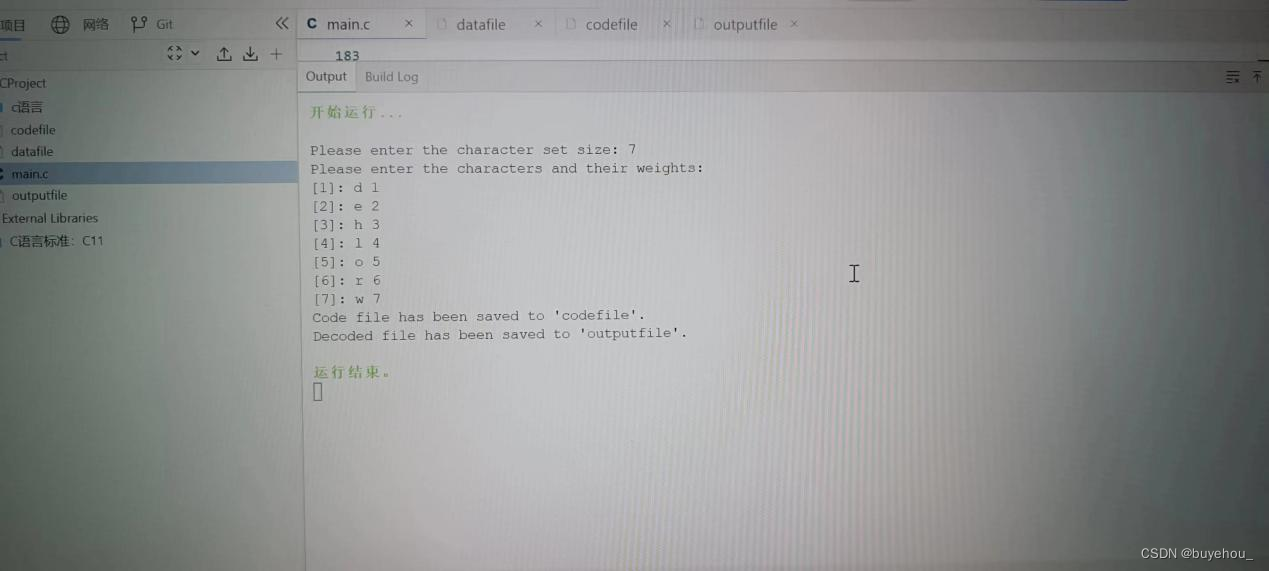
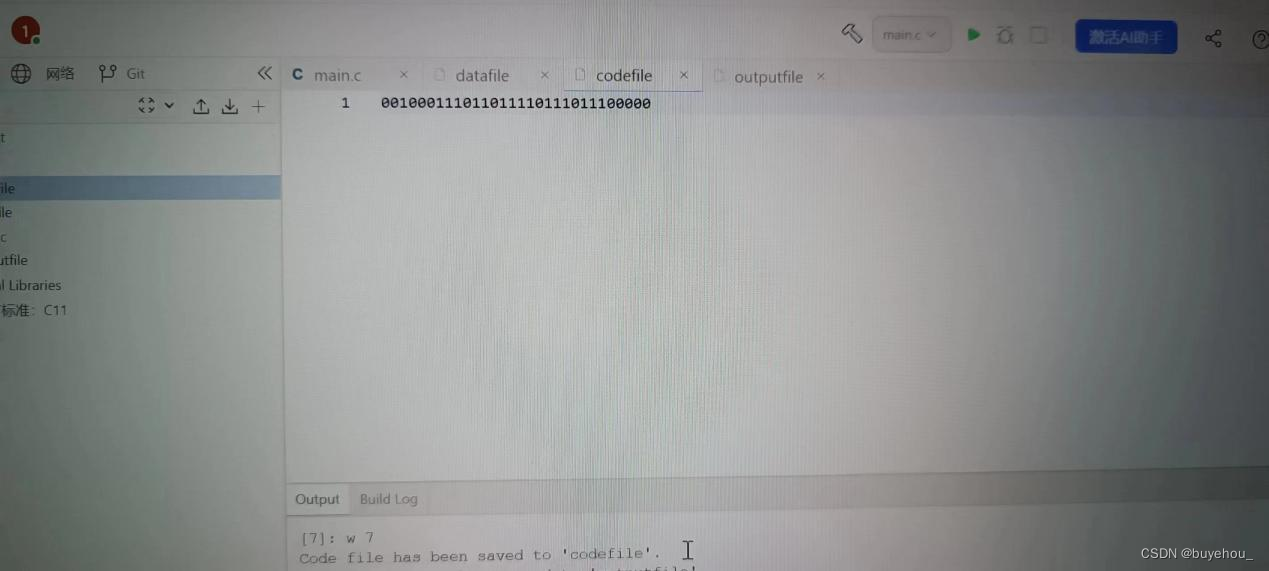
编码:利用已建好的哈夫曼树对待发送电文(读取来自文件tobetrans.dat)进行编码,然后将结果保存在磁盘文件codefile中。
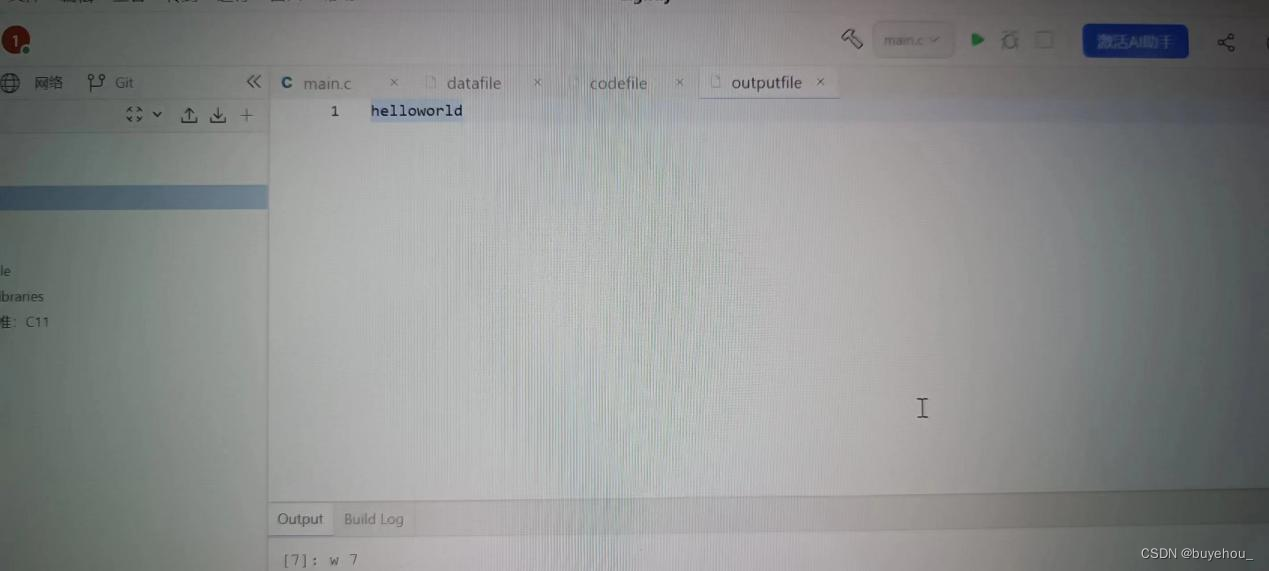
解码:利用已建好的哈夫曼树,对文件codefile中代码进行译码,结果存入文件textfile中。
参考文献:
[1] 谭浩强. C程序设计(第2版).北京:清华大学出版社,2004
[2] 严蔚敏,吴伟民.数据结构.北京:清华大学出版社,2005



















 3222
3222

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











