







需求分析
为了帮大家更快地发现和自己兴趣相同的朋友
匹配多个,并且按照匹配的相似度从高到低排序
根据标签来匹配
- 找有共同标签最多的用户
- 共同标签越多,分数越高,越排在前面
- 如果没有匹配的用户,随机推荐几个
实现(编辑距离算法)
算法介绍
编辑距离算法:https://blog.csdn.net/DBC_121/article/details/104198838
最小编辑距离:第一个字符串通过最少多少次操作(增删改)可以变成第二个字符串
(扩展)带权重的匹配算法:余弦相似度匹配算法
为什么用map存呢?
怎么对所有用户匹配,取top
直接取出所有用户,依次和当前用户计算分数,取top num(花了54秒)
如何优化?
- 切忌不要在数据量大的时候循环输出日志(取消掉日志后 20 秒) √
- Map 存了所有的分数信息,占用内存
解决:维护一个固定长度的有序集合(sortedSet),只保留分数最高的几个用户(时间换空间) - 细节:剔除自己 √
- 尽量只查需要的数据:
a. 过滤掉标签为空的用户 √
b. 根据部分标签取用户(前提是能区分出来哪个标签比较重要)
c. 只查需要的数据(比如 id 和 tags) √(7.0s) - 提前查?(定时任务)
a. 提前把所有用户给缓存(不适用于经常更新的数据)
b. 提前运算出来结果,缓存(针对一些重点用户,提前缓存)
大数据推荐,比如说有几亿个商品,难道要查出来所有的商品? 难道要对所有的数据计算一遍相似度?
检索 => 召回 => 粗排 => 精排 => 重排序等等
检索:尽可能多地查符合要求的数据(比如按记录查)
召回:查询可能要用到的数据(不做运算)
粗排:粗略排序,简单地运算(运算相对轻量)
精排:精细排序,确定固定排位
数据结构使用
treemap(排序只能按照key进行排序,把相似度设置为key的话,相似度重复的话key会冲突) - > list<pair<User,Long>> (key:用户的下标,value:最小编辑距离(相似度))
代码实现
在utils包下新建编辑距离算法工具类
传入参数:两个字符串列表
传出:最小编辑距离(第一个字符串通过最少多少次操作(增删改)可以变成第二个字符串)
package com.example.CampusPartnerBackend.utils;
import java.util.List;
import java.util.Objects;
/**
* 算法工具类
*
* @author yupi
*/
public class AlgorithmUtils {
/**
* 编辑距离算法(用于计算最相似的两组标签)
*
* @param tagList1
* @param tagList2
* @return
*/
//改造后的方法
public static int minDistance(List<String> tagList1, List<String> tagList2) {
int n = tagList1.size();
int m = tagList2.size();
if (n * m == 0) {
return n + m;
}
int[][] d = new int[n + 1][m + 1];
for (int i = 0; i < n + 1; i++) {
d[i][0] = i;
}
for (int j = 0; j < m + 1; j++) {
d[0][j] = j;
}
for (int i = 1; i < n + 1; i++) {
for (int j = 1; j < m + 1; j++) {
int left = d[i - 1][j] + 1;
int down = d[i][j - 1] + 1;
int left_down = d[i - 1][j - 1];
if (!Objects.equals(tagList1.get(i - 1), tagList2.get(j - 1))) {
left_down += 1;
}
d[i][j] = Math.min(left, Math.min(down, left_down));
}
}
return d[n][m];
}
/**
* 编辑距离算法(用于计算最相似的两个字符串)
* 原理:https://blog.csdn.net/DBC_121/article/details/104198838
*
* @param word1
* @param word2
* @return
*/
//模板
public static int minDistance(String word1, String word2) {
int n = word1.length();
int m = word2.length();
if (n * m == 0) {
return n + m;
}
int[][] d = new int[n + 1][m + 1];
for (int i = 0; i < n + 1; i++) {
d[i][0] = i;
}
for (int j = 0; j < m + 1; j++) {
d[0][j] = j;
}
for (int i = 1; i < n + 1; i++) {
for (int j = 1; j < m + 1; j++) {
int left = d[i - 1][j] + 1;
int down = d[i][j - 1] + 1;
int left_down = d[i - 1][j - 1];
if (word1.charAt(i - 1) != word2.charAt(j - 1)) {
left_down += 1;
}
d[i][j] = Math.min(left, Math.min(down, left_down));
}
}
return d[n][m];
}
}
controller层接口
/**
* 根据标签匹配程度给用户推荐信息
*
* @param num 展示多少用户
* @param request
* @return
*/
@GetMapping("/match")
public BaseResponse<List<User>> matchUsers(long num, HttpServletRequest request) {
if (num <= 0 || num > 20) {
throw new BusinessException(ErrorCode.PARAMS_ERROR);
}
User loginUser = userService.getLoginUser(request);
List<User> userList = userService.matchUsers(num, loginUser);
return ResultUtils.success(userList);
}
业务层代码
业务逻辑
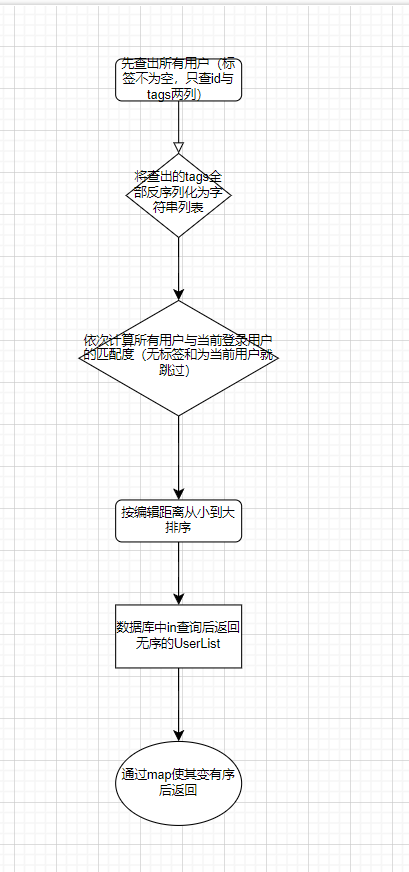
代码实现
@Override
public List<User> matchUsers(long num, User loginUser) {
//先全部查出来,不查tags为空的,只查id与tags两列
QueryWrapper<User> queryWrapper = new QueryWrapper<>();
queryWrapper.select("id", "tags");
queryWrapper.isNotNull("tags");
List<User> userList = this.list();
Gson gson = new Gson();
String tag = loginUser.getTags();
List<String> tagList1 = gson.fromJson(tag, new TypeToken<List<String>>() {
}.getType());
//答案
List<Pair<User, Long>> list = new ArrayList<>();
//反序列化为list<String>
for (int i = 0; i < userList.size(); i++) {
User user = userList.get(i);
String tags = user.getTags();
List<String> tagsList2 = gson.fromJson(tags, new TypeToken<List<String>>() {
}.getType());
//依次计算所有用户与当前用户的匹配度(无标签和为当前用户就跳过)
if (StringUtils.isEmpty(tags) || Objects.equals(user.getId(), loginUser.getId())) {
continue;
}
long distance = AlgorithmUtils.minDistance(tagList1, tagsList2);
list.add(new Pair<>(user,distance));
}
//按编辑距离从小到大排序
List<Pair<User, Long>> topUserPairList = list.stream()
.sorted((a, b) -> (int) (a.getValue() - b.getValue()))
.limit(num)
.collect(Collectors.toList());
// 原本顺序的 userId 列表
List<Long> userIdList = topUserPairList.stream().map(pair -> pair.getKey().getId()).collect(Collectors.toList());
QueryWrapper<User> userQueryWrapper = new QueryWrapper<>();
userQueryWrapper.in("id",userIdList);//变无序了
// 1, 3, 2
// User1、User2、User3
// 1 => User1, 2 => User2, 3 => User3
Map<Long, List<User>> listMap = this.list(userQueryWrapper)
.stream()
.map(user -> getSafetyUser(user))
.collect(Collectors.groupingBy(User::getId));
//最终列表
List<User> finalUserList = new ArrayList<>();
for(Long userId:userIdList){
finalUserList.add(listMap.get(userId).get(0));
}
return finalUserList;
}















 563
563











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









