







三种抓取方式
- 直接调用请求接口(最方便,这里使用该方法) HttpClient,OKHttp,RestTemplate,Hutool
- 等网页渲染出明文内容后,从前端页面的内容抓取
- 有些网站可能是动态请求的,不会一次性加载所有的数据,而是要你点击某个按钮,输入某个验证码才会显示出数据 -> 无头浏览器
数据抓取的流程
- 分析数据源(怎么获取)
- 拿到数据后怎么处理
- 写入数据库等存储
获取文章
离线抓取方式
具体操作
- 过滤请求
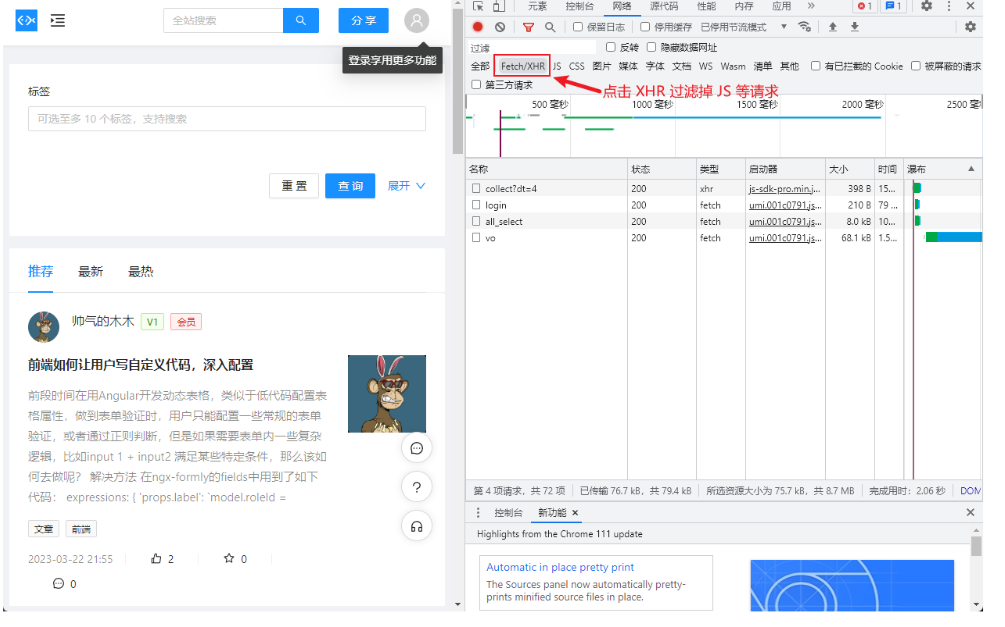
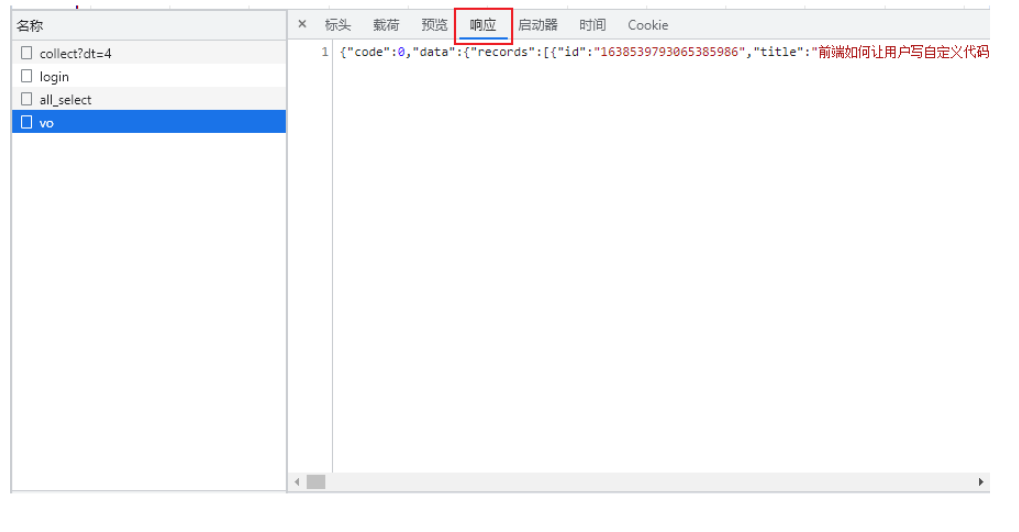
- 将响应的数据复制到data/passage.json文件中
- 引入Hutool依赖
<!-- https://hutool.cn/docs/index.html#/ -->
<dependency>
<groupId>cn.hutool</groupId>
<artifactId>hutool-all</artifactId>
<version>5.8.16</version>
</dependency>
- 查看官方文档
https://hutool.cn/docs/index.html#/
- 编写测试类
获取用于爬虫的数据
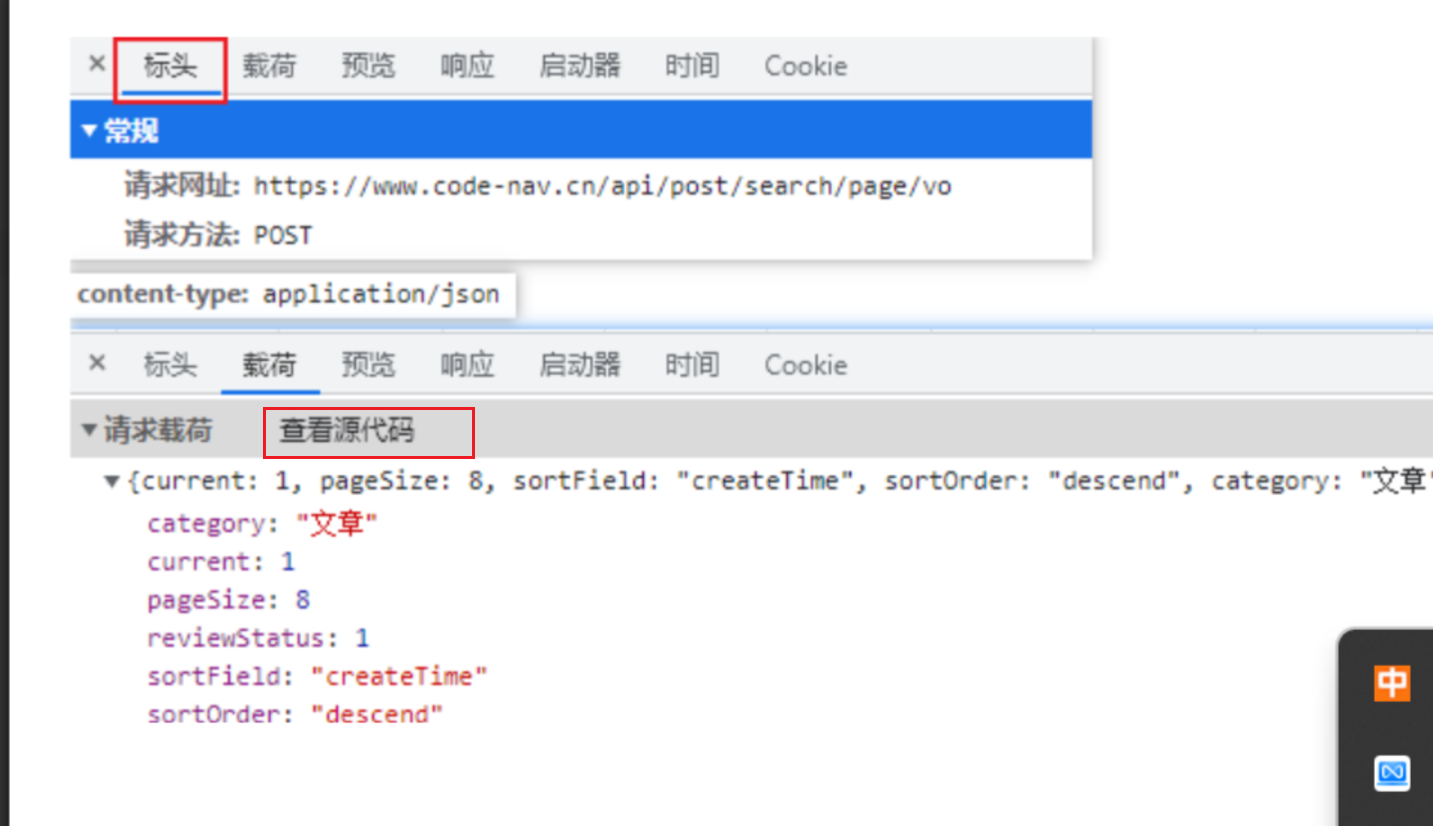
编写测试类
@SpringBootTest
public class CrawlerTest {
@Resource
private PostService postService;
@Test
void testFetchPassage() {
//1.获取数据
String json = "{\"current\":1,\"pageSize\":8,\"sortField\":\"createTime\",\"sortOrder\":\"descend\",\"category\":\"文章\",\"tags\":[],\"reviewStatus\":1}";
String url = "https://api.code-nav.cn/api/post/search/page/vo";
String result = HttpRequest.post(url)
.body(json)
.execute().body();
//2.处理数据:json转对象
Map<String, Object> map = JSONUtil.toBean(result, Map.class);
JSONObject data = (JSONObject) map.get("data");
JSONArray records = (JSONArray) data.get("records");
List<Post> postList = new ArrayList<>();
for (Object record : records) {
Post post = new Post();
JSONObject tempRecord = (JSONObject) record;
post.setId(0L);
post.setTitle(tempRecord.getStr("title"));
post.setContent(tempRecord.getStr("content"));
//这里将json数组转为列表再转为json字符串,不知道是为了干什么,为什么不直接把json数组转为json字符串呢?
JSONArray tags = (JSONArray) tempRecord.get("tags");
List<String> tagList = tags.toList(String.class);
// System.out.println(JSONUtil.toJsonStr(tags));
post.setTags(JSONUtil.toJsonStr(tagList));
System.out.println(JSONUtil.toJsonStr(tagList));
post.setUserId(1L);
postList.add(post);
//3.写入数据库
postService.saveBatch(postList);
}
}
}
- 写入一次性任务
// 取消@Component注释每次项目启动都会执行run任务
//@Component
@Slf4j
public class FetchInitPostList implements CommandLineRunner {
@Resource
private PostService postService;
@Override
public void run(String... args) {
//1.获取数据
String json = "{\"current\":1,\"pageSize\":8,\"sortField\":\"createTime\",\"sortOrder\":\"descend\",\"category\":\"文章\",\"tags\":[],\"reviewStatus\":1}";
String url = "https://api.code-nav.cn/api/post/search/page/vo";
String result = HttpRequest.post(url)
.body(json)
.execute().body();
//2.处理数据:json转对象
Map<String, Object> map = JSONUtil.toBean(result, Map.class);
JSONObject data = (JSONObject) map.get("data");
JSONArray records = (JSONArray) data.get("records");
List<Post> postList = new ArrayList<>();
for (Object record : records) {
Post post = new Post();
JSONObject tempRecord = (JSONObject) record;
post.setId(0L);
post.setTitle(tempRecord.getStr("title"));
post.setContent(tempRecord.getStr("content"));
//这里将json数组转为列表再转为json字符串,不知道是为了干什么,为什么不直接把json数组转为json字符串呢?
JSONArray tags = (JSONArray) tempRecord.get("tags");
List<String> tagList = tags.toList(String.class);
//JSONUtil.toJsonStr(tags);
post.setTags(JSONUtil.toJsonStr(tagList));
post.setUserId(1L);
postList.add(post);
//3.写入数据库
postService.saveBatch(postList);
}
}
}
获取用户
每个网站的用户都是自己的,没必要抓取
获取图片
实时抓取:我们自己的网站不存在这些数据,用户要搜的时候,直接从别人的接口(网站)去搜
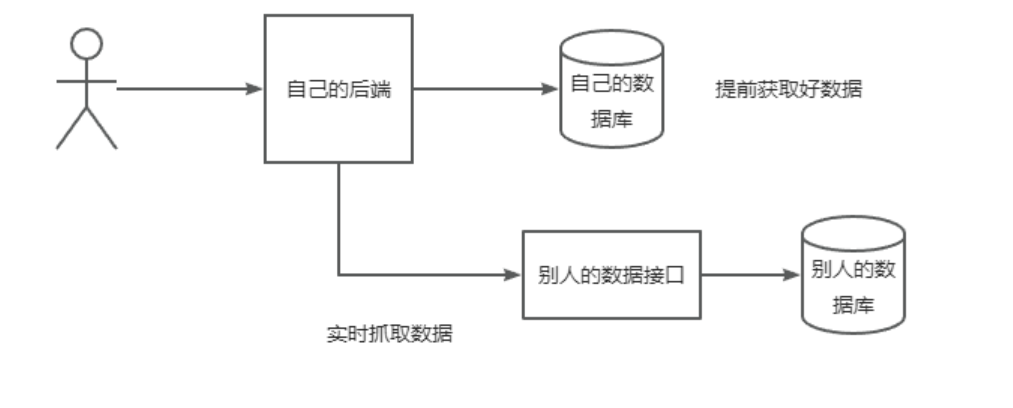
jsoup库:获取到HTML文档,然后从中解析出需要的字段
jsoup操作
- 导入依赖
<!-- https://mvnrepository.com/artifact/org.jsoup/jsoup -->
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.15.3</version>
</dependency>
- 打开官网 (https://jsoup.org/),获取示例代码
Document doc = Jsoup.connect("https://en.wikipedia.org/").get();
log(doc.title());
Elements newsHeadlines = doc.select("#mp-itn b a");
for (Element headline : newsHeadlines) {
log("%s\n\t%s",
headline.attr("title"), headline.absUrl("href"));
}
- 通过在网页前端html界面找对应的css选择器,拿到需要的内容
- 测试代码
//抓取图片
@Test
void testFetchPicture() throws IOException {
int current = 1;
String url = "https://cn.bing.com/images/search?q=%E5%B0%8F%E9%BB%91%E5%AD%90&form=HDRSC2&first=" + current;
Document doc = Jsoup.connect(url).get();
Elements elements = doc.select(".iuscp.isv"); //数组,每个元素是每一张图片
for (Element element : elements) {
//取图片地址murl
String m = element.select(".iusc").attr("m");
Map<String,Object> map = JSONUtil.toBean(m, Map.class);
String murl = (String) map.get("murl");
//取标题
String title = element.select(".inflnk").attr("aria-label");
System.out.println(murl);
System.out.println(title);
}
}














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









