







数据如下:
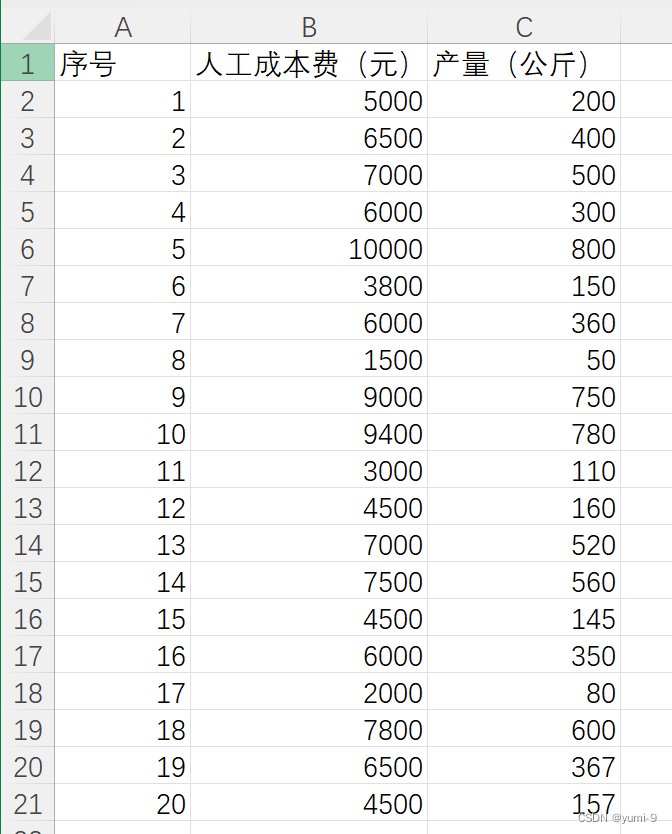
代码如下:
import copy
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
# 读取excel 并将其向量化为训练数据集x y
data = pd.read_excel("D:\python\python_for_beginner\成本产量数据表.xlsx", head=None, index_col=None, usecols='B' )
x_train = np.asarray(data.stack())
print(x_train)
data = pd.read_excel("D:\python\python_for_beginner\成本产量数据表.xlsx", head=None, index_col=None, usecols='C' )
y_train = np.asarray(data.stack())
print(y_train)
# 开始实现线性回归
# 函数准备
# 线性拟合函数 返回函数值列表
def computer_model_output(x, w, b):
m = x.shape[0]
f_wb = np.zeros(m)
for i in range(m):
f_wb[i] = w * x[i] + b
return f_wb
# 成本函数 返回总偏差
def compute_cost(x, y, w, b):
m = x.shape[0]
total_cost =0
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1096
1096

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









