








最全的Linux教程,Linux从入门到精通
======================
-
linux从入门到精通(第2版)
-
Linux系统移植
-
Linux驱动开发入门与实战
-
LINUX 系统移植 第2版
-
Linux开源网络全栈详解 从DPDK到OpenFlow

第一份《Linux从入门到精通》466页
====================
内容简介
====
本书是获得了很多读者好评的Linux经典畅销书**《Linux从入门到精通》的第2版**。本书第1版出版后曾经多次印刷,并被51CTO读书频道评为“最受读者喜爱的原创IT技术图书奖”。本书第﹖版以最新的Ubuntu 12.04为版本,循序渐进地向读者介绍了Linux 的基础应用、系统管理、网络应用、娱乐和办公、程序开发、服务器配置、系统安全等。本书附带1张光盘,内容为本书配套多媒体教学视频。另外,本书还为读者提供了大量的Linux学习资料和Ubuntu安装镜像文件,供读者免费下载。

本书适合广大Linux初中级用户、开源软件爱好者和大专院校的学生阅读,同时也非常适合准备从事Linux平台开发的各类人员。
需要《Linux入门到精通》、《linux系统移植》、《Linux驱动开发入门实战》、《Linux开源网络全栈》电子书籍及教程的工程师朋友们劳烦您转发+评论
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
一、配置Hadoop环境
1.查看Hadoop解压位置
pwd

2.配置环境变量
vim /etc/profile

3.编辑环境变量
“/opt/server/hadoop”填自己Hadoop的存放位置。
export HADOOP_HOME=/opt/server/hadoop
export PATH=$PATH:$HADOOP_HOME/bin

4.重启环境变量
source /etc/profile

5.查看Hadoop版本,查看成功就表示Hadoop安装成功了
hadoop version

二、修改配置文件
1.检查三台虚拟机:
是否都安装了jdk和hadoop并且配置了环境变量,确保虚拟机之间都能互相ping通以及两两之间能够ssh免密登陆,都完成了网卡、主机名、hosts文件等配置。
| ip地址 | 主机名 | 节点 |
|---|---|---|
| 192.168.147.200 | hadoop | 主节点 |
| 192.168.147.201 | hadoop2 | 子节点 |
| 192.168.147.203 | hadoop3 | 子节点 |
2.切换到配置文件目录
cd /opt/server/hadoop/etc/hadoop

3.修改 hadoop-env.sh 文件
路径改成自己的jdk安装路径(vim命令用不了就用vi)
vim hadoop-env.sh
export JAVA_HOME=/opt/server/jdk


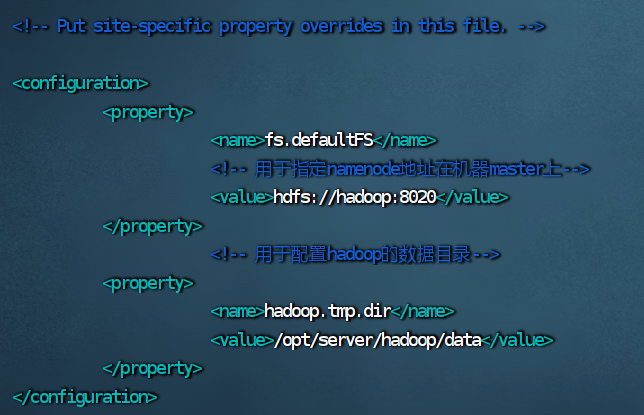
4.修改 core-site.xml 文件
vim core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<!-- 用于指定namenode地址在机器master上-->
<value>hdfs://hadoop:8020</value>
</property>
<!-- 用于配置hadoop的数据目录-->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/server/hadoop/data</value>
</property>
</configuration>

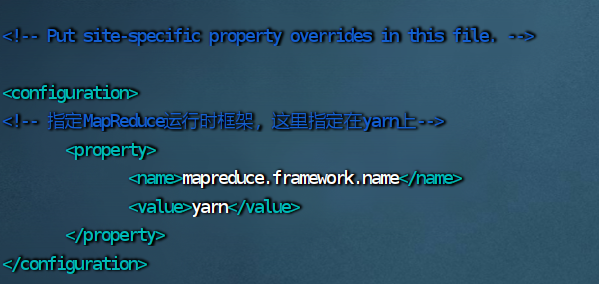
5.修改 mapred-site.xml 文件
vim mapred-site.xml
<configuration>
<!-- 指定MapReduce运行时框架,这里指定在yarn上-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>

6.修改 hdfs-site.xml 文件
vim hdfs-site.xml
<configuration>
<!--指定HDFS副本的数量,不能超过机器节点数-->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!-- 为secondary namenode配置所在的IP和端口-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop2:50090</value>
</property>
</configuration>


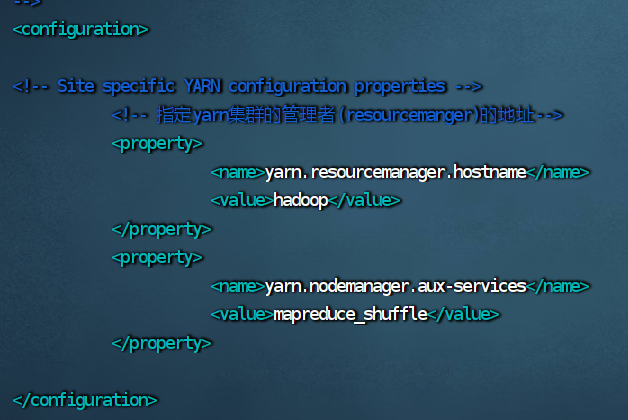
7.修改 yarn-site.xml 文件
vim yarn-site.xml
<configuration>
<!-- 指定yarn集群的管理者(resourcemanger)的地址-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>

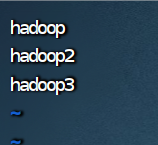
8.修改 workers 文件
vim workers
hadoop
hadoop2
hadoop3

三、给hadoop2、hadoop3分发文件
1.到存放hadoop的文件夹下
cd /opt/server/

2.1.给hadoop2和hadoop3拷贝文件和环境变量
scp -r hadoop-3.2.4/ root@hadoop2:/opt/server/hadoop-3.2.4/
scp /etc/profile root@hadoop2:/etc/profile


2.2.给hadoop2和hadoop3创建软连接
ln -s hadoop-3.2.4/ hadoop

2.3.检查hadoop2和hadoop3是否拷贝成功
hadoop的配置文件拷贝给了hadoop2和hadoop3,在hadoop2打开workers。
vim workers

hadoop2的workers没被修改,说明没拷贝成功。
2.4.如果没有拷贝成功就将hadoop2和hadoop3的hadoop文件夹删除,然后在拷贝一次
rm -rf hadoop-3.2.4

重复2.1的操作
四、修改脚本文件
1.切换到hadoop的sbin目录下
脚本文件都在sbin文件下。
cd /opt/server/hadoop/sbin
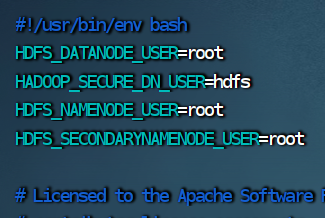
2.修改 start-dfs.sh 脚本文件
vim start-dfs.sh
HDFS_DATANODE_USER=root
HADOOP_SECURE_DN_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root

3.修改 stop-dfs.sh 脚本文件
vim stop-dfs.sh
HDFS_DATANODE_USER=root
HADOOP_SECURE_DN_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root


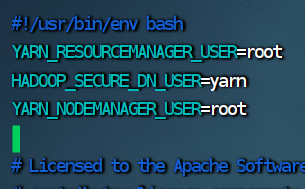
4.修改start-yarn.sh 脚本文件
vim start-yarn.sh
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root

4.修改 start-yarn.sh 脚本文件
vim start-yarn.sh
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root


5.修改 stop-yarn.sh 脚本文件
vim stop-yarn.sh
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root


五、启动hadoop集群
1.格式化HDFS
hadoop namenode -format


2.启动hadoop
启动hadoop和yarn一定要在sbin目录下。
./start-dfs.sh

3.启动yarn
./start-yarn.sh
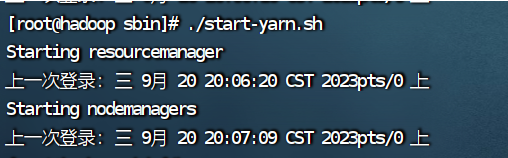
4.查看进程
jps
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 281
281

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









