






希尔排序是插入排序的一种,其又称为“缩小增量排序”。
当待排序的数据个数较少且待排序序列的数据基本有序时,直接插入排序效率较高。希尔排序基于以上两点,从“减少数据个数”和“序列基本有序”两方面对直接插入排序进行了改进。算法步骤:
希尔排序实质上是采用分组插入的方法,先将整个待排序数据序列分割成几组,从而减少参与直接插入排序的数据量,对每组分别进行直接插入排序,然后增加每组的数据量,重新分组。这样当经过几次分组排序后,整个序列中的数据“基本有序”时,再对全体数据进行一次直接插入排序。
希尔对数据的分组,不是简单地“逐段分割”,而是将相隔某个“增量”的数据分成一组。
①第一趟取增量d1(d1<n)把全部数据分成d1个组,所有间隔为d1的数据分在同一组,在各
个组中进行直接插入排序。
②第二趟取增量d2(d2<d1),重复上述的分组和排序。
③依次类推,直到所取的增量dt=1(dt<d(t-1),<…<d2<d1),所有记录在同一组中进行直接
插入排序为止。
排序过程如下图:
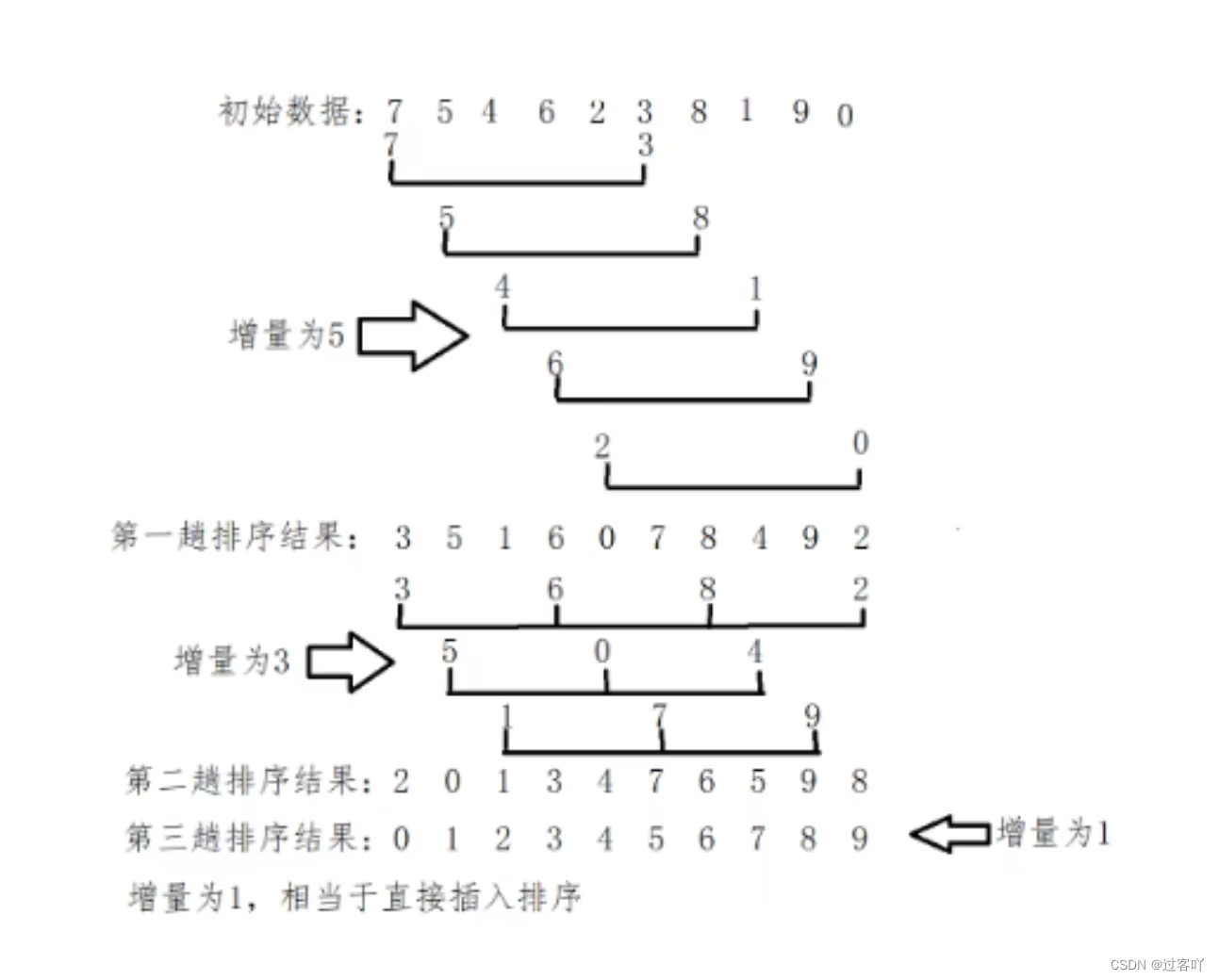
(1)第一趟取增量d1=5,所有间隔为5的数据分在同一组,全部数据分成5组,在各个组中分别进行直接插入排序,排序结果为上图第一趟排序结果所示。
(2)第二趟取增量d2=3,所有间隔为3的数据分在同一组,全部数据分成3组,在各个组中分别进行直接插入排序,排序结果为上图第二趟排序结果所示。
(3)第三趟取增量d=1,对整个序列进行一趟直接插入排序,排序完成,排序结果为上图第三趟排序结果所示。
增量越大,数据的跳跃幅度就越大,能使大的数据更快到后面的位置,使小的数据更快到前面的位置,但序列的“有序性”更差;相反,增量越小,数据的跳跃幅度就越小,数据到达最后相应位置更慢,但序列更接近有序。
具体代码如下:
#include<stdio.h>
// 希尔排序
void ShellSort(int* a, int n) {
int gap = n;//gap为每次的增量
while (gap >= 2) {
gap /= 2;//使最后一次增量gap为1
for (int i = 0; i < n - gap; i++) {
int end = i;
int tmp = a[end + gap];
while (end >= 0) {
if (tmp < a[end]) {
a[end + gap] = a[end];
end -= gap;
}
else {
break;
}
}
a[end + gap] = tmp;
}
}
}
int main()
{
int a[] = { 7,5,4,6,2,3,8,1,9,0 };
ShellSort(a, sizeof(a) / sizeof(int));
for (int i = 0; i < n; i++) {
printf("%d ", a[i]);
}
printf("\n");
return 0;
}上述代码运行结果为:

















 852
852











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











