







 文章介绍了如何在Elasticsearch中使用不同分词器(如默认分词器、ik_smart和ik_max_word),自定义词库的配置方法,以及如何在创建新索引时考虑分词器的选择。作者还分享了如何处理远程词库和nginx设置的过程。
文章介绍了如何在Elasticsearch中使用不同分词器(如默认分词器、ik_smart和ik_max_word),自定义词库的配置方法,以及如何在创建新索引时考虑分词器的选择。作者还分享了如何处理远程词库和nginx设置的过程。
2、测试分词器
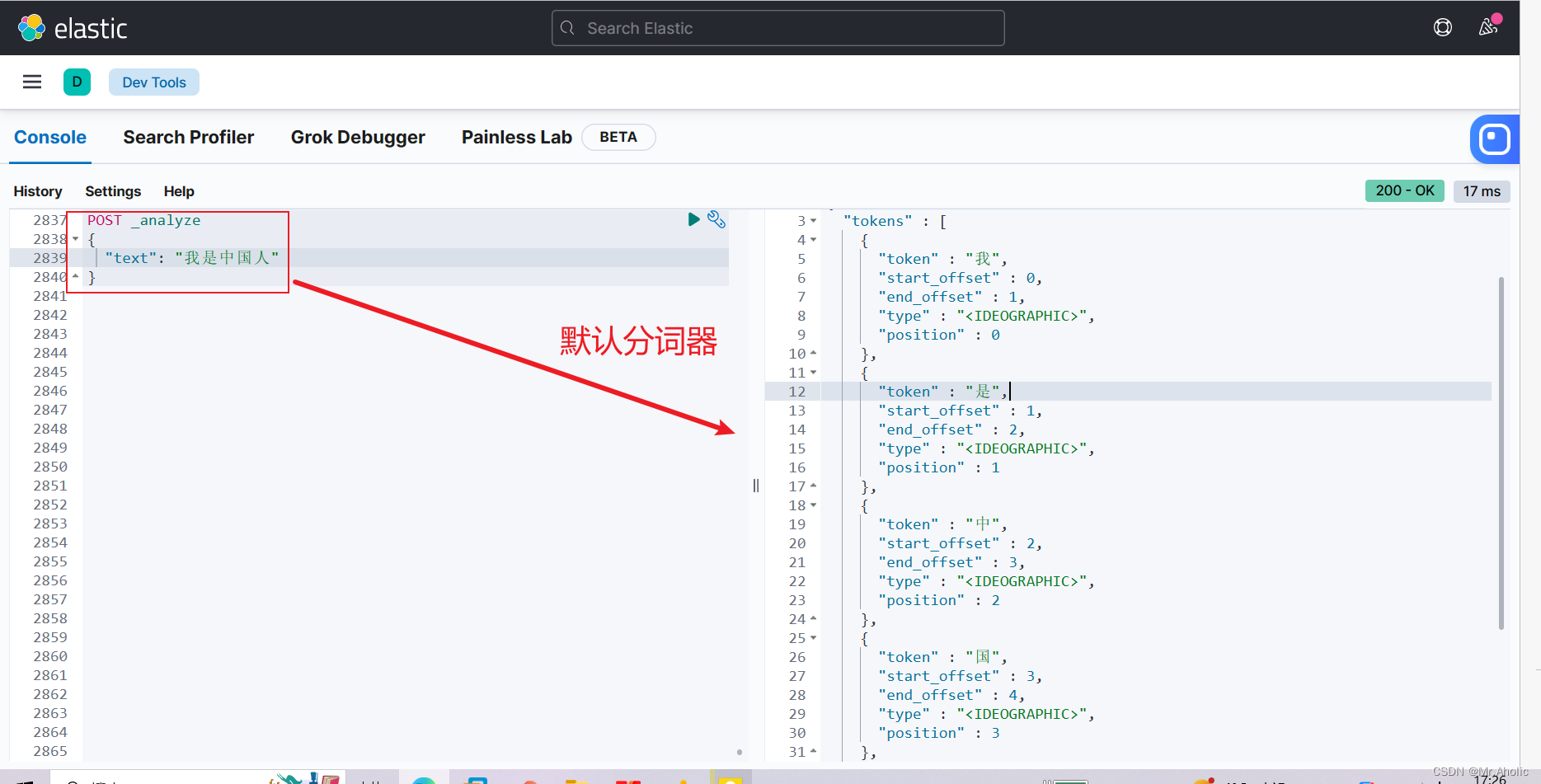
1.1 默认分词器
POST _analyze
{
"text": "我是中国人"
}
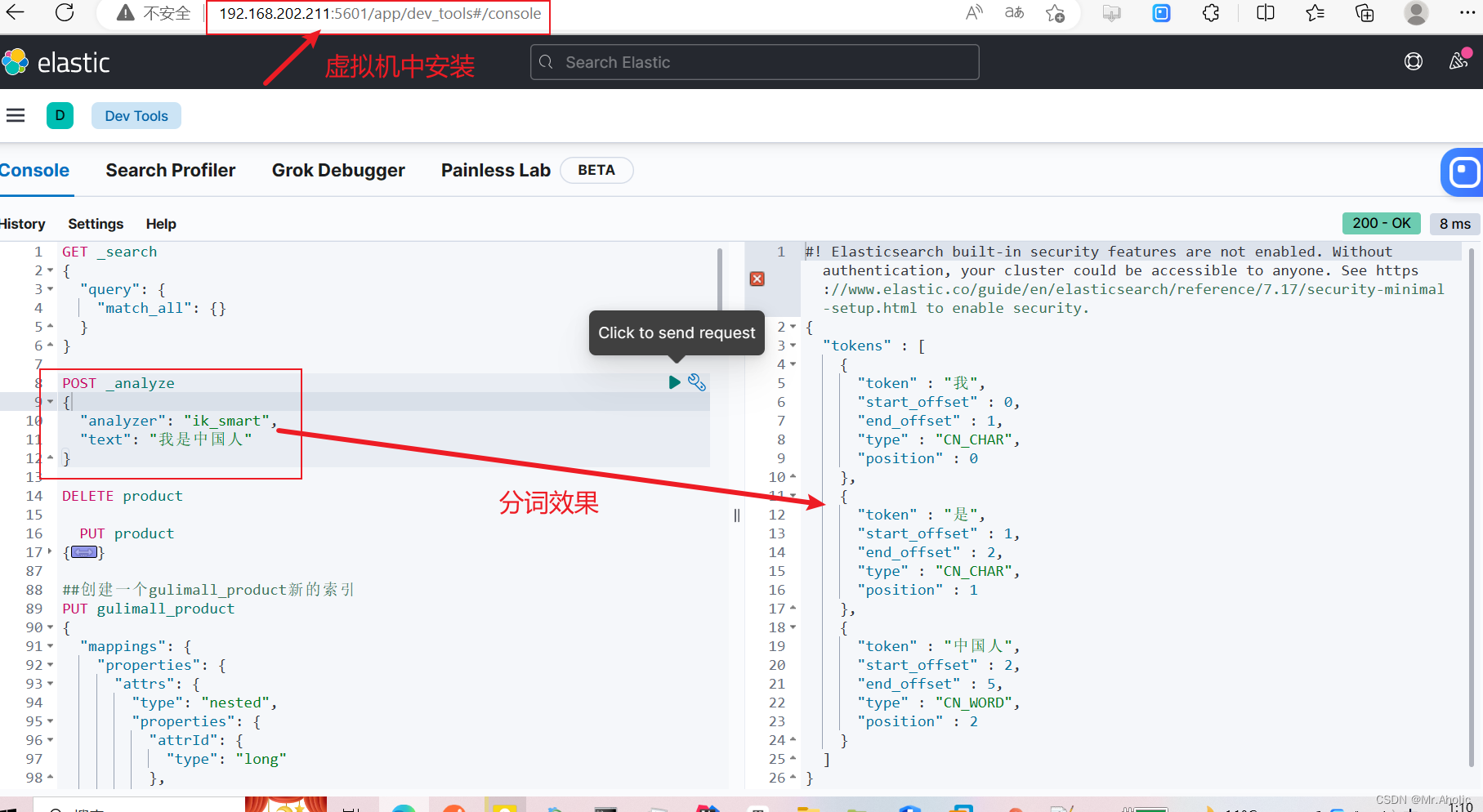
1.2 使用分词器(1)
POST _analyze
{
"analyzer": "ik\_smart",
"text": "我是中国人"
}
1.3 使用分词器(2)
POST _analyze
{
"analyzer": "ik\_max\_word",
"text": "我是中国人"
}
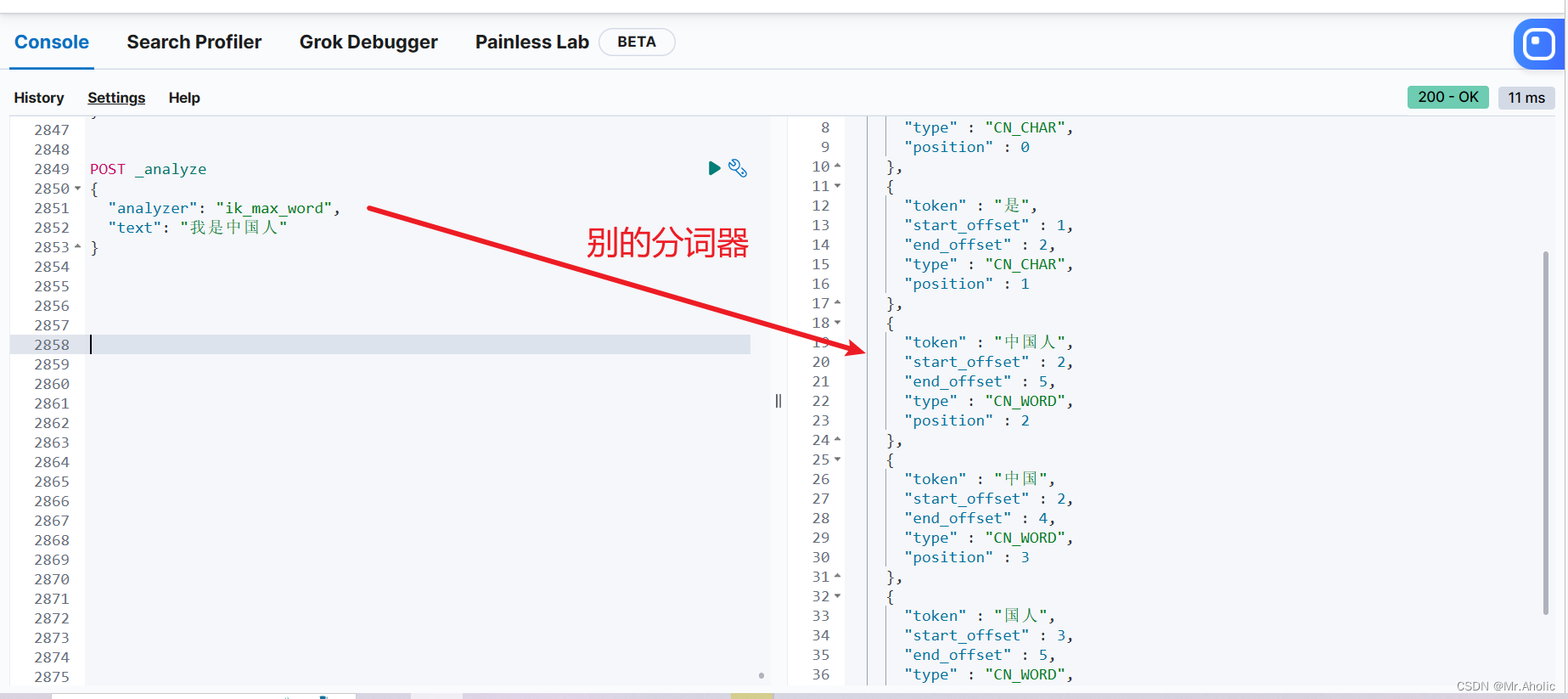
提示:能够看出不同的分词器,分词有明显的区别,所以以后定义一个索引不能再使用默认的 mapping 了,要手工建立 mapping, 因为要选择分词器
3、自定义词库
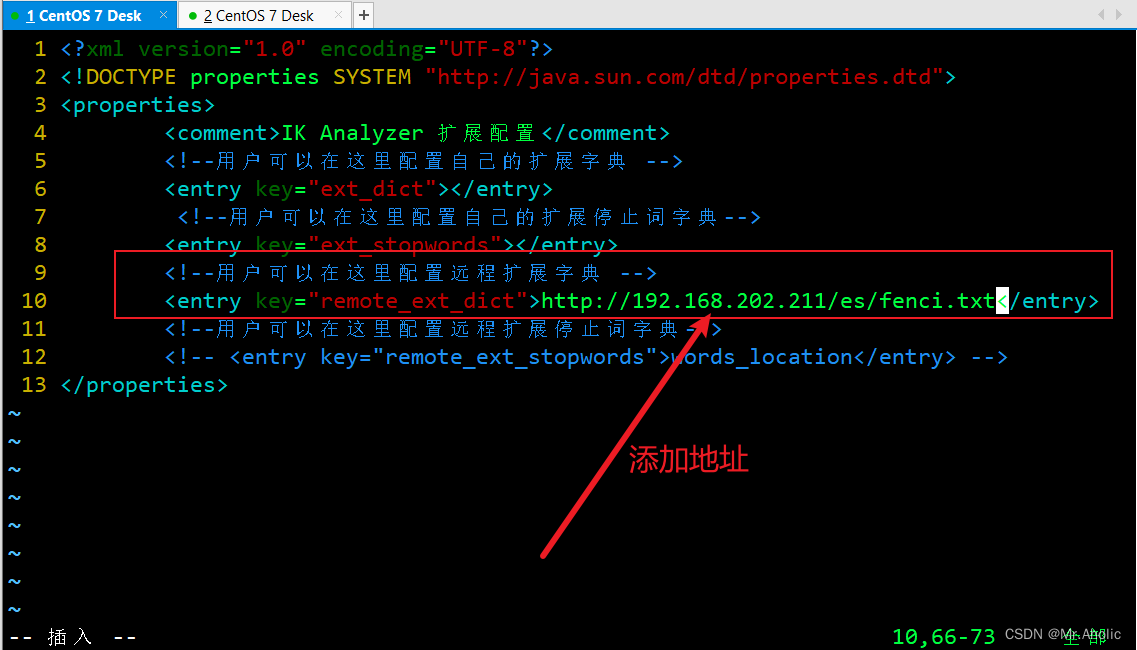
3.1 修改IKAnalyzer.cfg.xml
修改/usr/share/elasticsearch/plugins/ik/config/中的 IKAnalyzer.cfg.xml ,如果进行了目录挂载,只需要在外部对应目录修改就行,我这里的外部挂载目录是:/mydata/elasticsearch/plugins/ik/config

3.2 nginx的设置
首先你要安装了nginx,我这以下操作步骤是基于nginx挂载到外部目录。
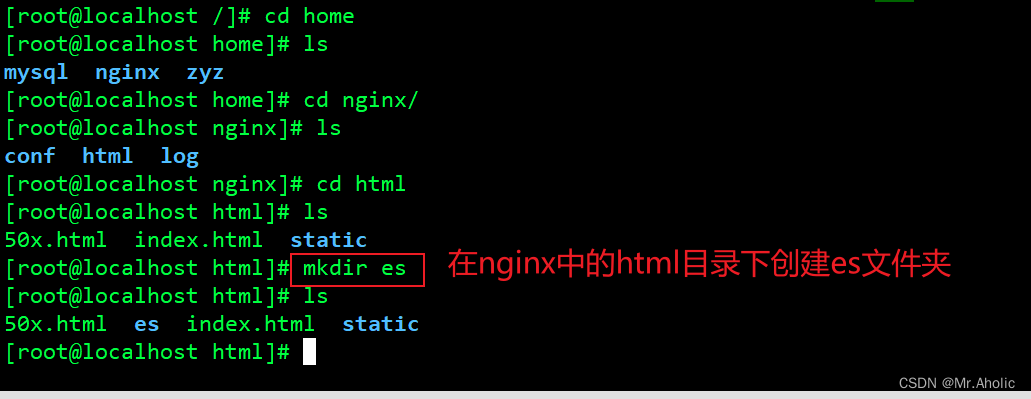
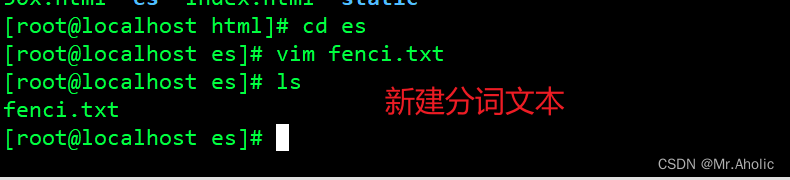
需要将这个链接地址放置到IKAnalyzer.cfg.xml中对应的远程词库目录
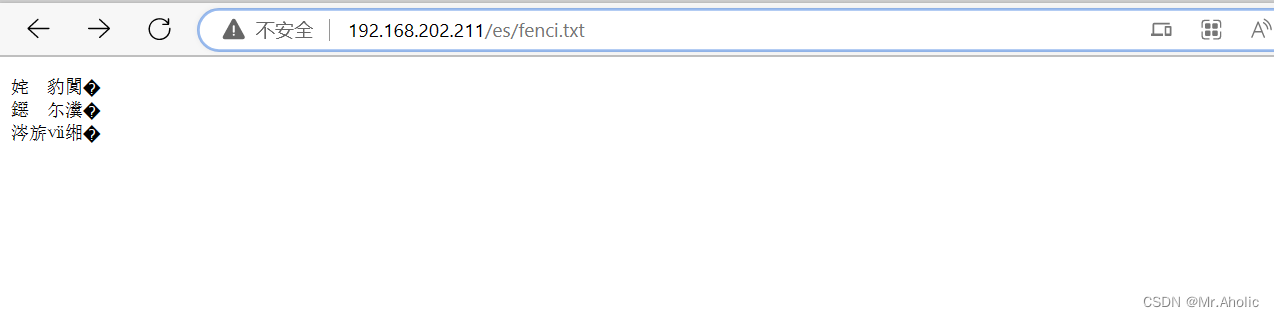
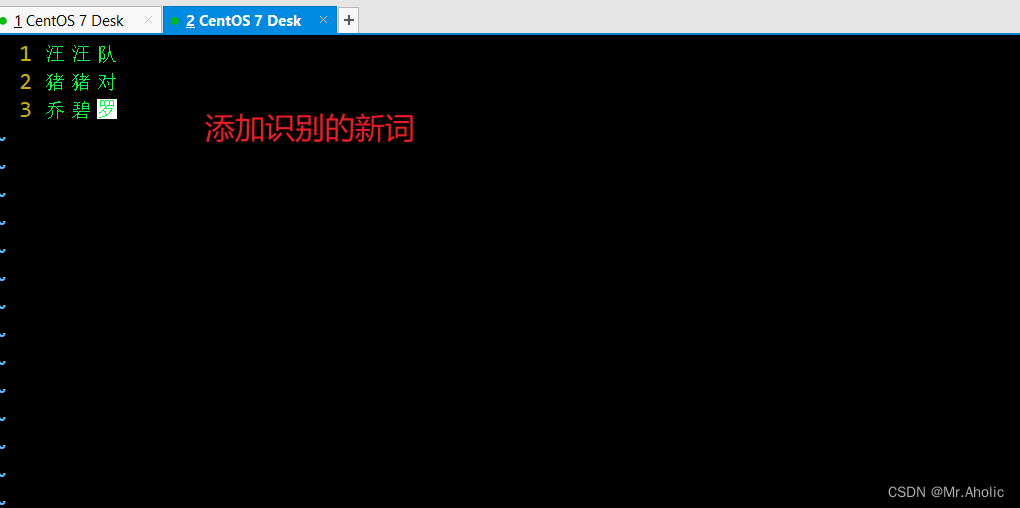
1.3 测试
POST _analyze
{
"analyzer": "ik\_max\_word",
"text": "汪汪队和猪猪对讨论乔碧罗"
}
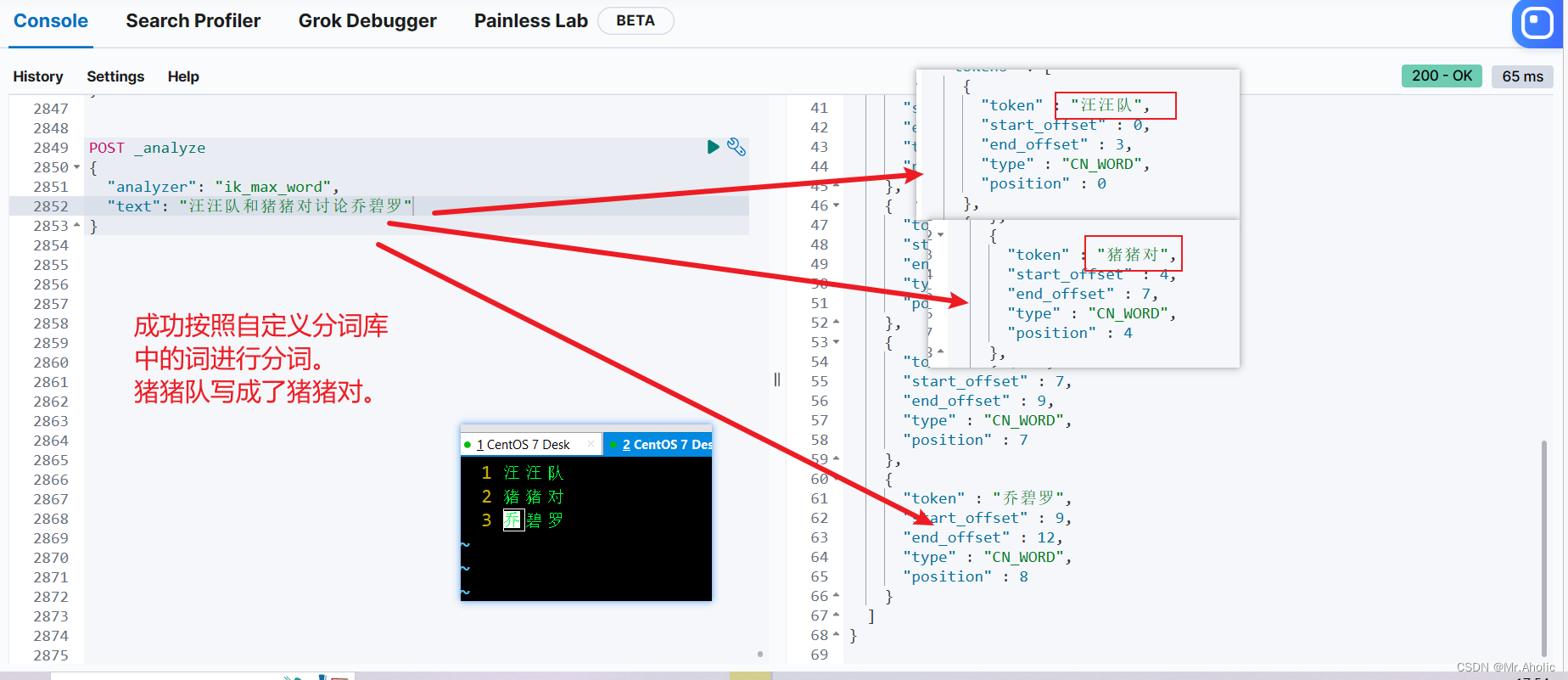
5、后语
我这里最终的目的是项目中要使用到分词器的使用、不安装不行要执行的语句
我的代码执行结束后、报的是这个索引找不到。所以要创建、创建又需要用到分词器。
##创建一个gulimall_product新的索引
PUT gulimall_product
{
"mappings": {
"properties": {
"attrs": {
"type": "nested",
"properties": {
"attrId": {
"type": "long"
},
"attrName": {
"type": "keyword"
},
"attrValue": {
"type": "keyword"
}
}
},
"brandId": {
"type": "long"
},
"brandImg": {
"type": "keyword"
},
"brandName": {
"type": "keyword"
},
"catalogId": {
"type": "long"
},
"catalogName": {
"type": "keyword"
},
"hasStock": {
"type": "boolean"
},



**既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!**
**由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新**
**[需要这份系统化资料的朋友,可以戳这里获取](https://bbs.csdn.net/topics/618545628)**
阶课程,涵盖了95%以上大数据知识点,真正体系化!**
**由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新**
**[需要这份系统化资料的朋友,可以戳这里获取](https://bbs.csdn.net/topics/618545628)**
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









