








前言
通过爬虫技术对图片进行批量爬取可以说是我们必备的爬虫技巧之一,网络爬虫也叫做网络机器人,可以代替人们自动地在互联网中进行数据信息的采集与整理。在大数据时代,信息的采集是一项重要的工作,如果单纯靠人力进行信息采集,不仅低效繁琐,搜集的成本也会提高。
这里先对要运用的第三方库进行安装。
本文选取的函数库主要为requests、lxml、etree。
打开anaconda prompt,这是anaconda的交互界面,很多指令在该界面直接输入,便可直接下载众多函数库。
conda install lxml
conda install requests
目标网页
引入库
import os
import requests
from lxml import etree
隐藏爬虫身份
如今很多网站设置了反爬系统,我们对爬虫身份进行隐藏,将其隐藏为正常的用户访问,具体操作如下:
首先,我们随意打开一个网站,右键点击检查:
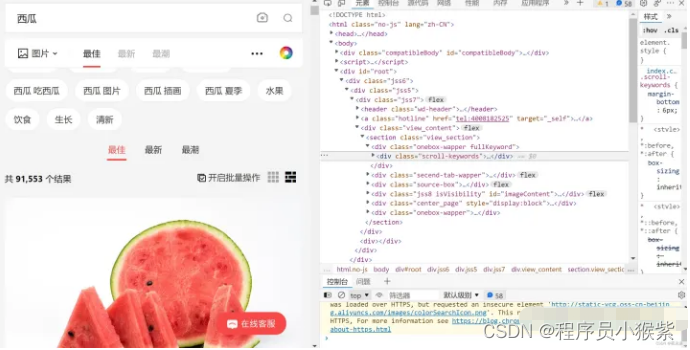
打开后,点击网络,并且ctrl+r刷新:
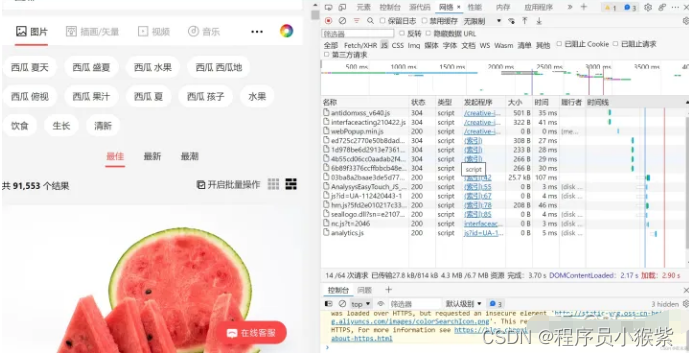
刷新后随机点一个名称从标头往下翻,一般可以在请求标头上找到User-Agent并且复制(没有就换个名称接着找):
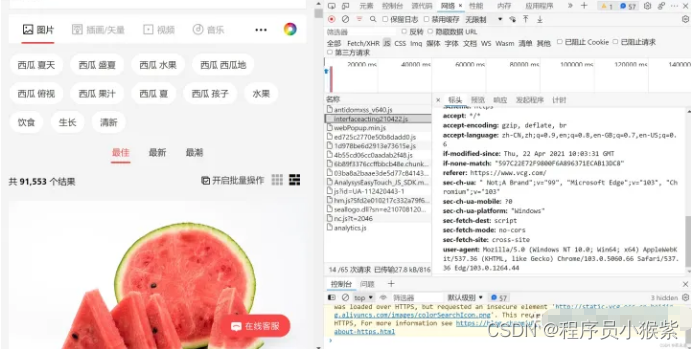
随后在代码中添加如下:
#输入网站的地址
url = https://pic.netbian.com/4kdongman/
#隐藏爬虫身份
header = {
'User_Agent':'粘贴复制的user-agent'
}
获取目标地址
在元素这一栏中找到(在页面中选择一个元素进行检查)这个图标,选择你想要爬取的照片,会自动帮你定位到该图片所在的标签。
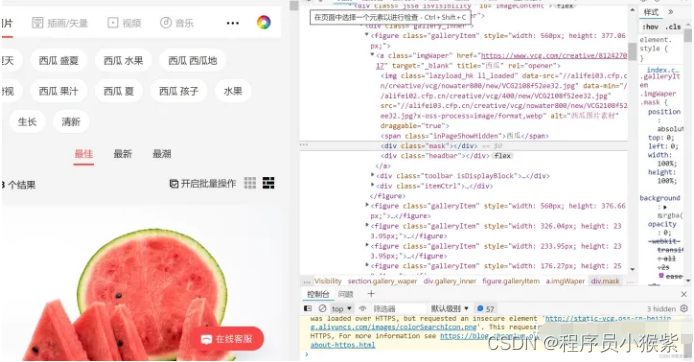
还是这张图片,找到要下载的图片地址在a标签下的img src中,再次进行匹配。
网页抓取
通过requests库对网页的地址进行访问申请
response = requests.get(url,header)
此时我们可以通过对page的状态码查看来判断是否访问成功(返回值为200代表访问成功)
response_status = response.status_code
print(response_status)
获取网页文本并将文本解析
page_text = response.text
tree = etree.HTML(page_text)
文本匹配
首先观察,发现所有的图片地址都在figure标签中,所有的figure标签又都存在于 div class=“gallery_inner” 中,所以我们先匹配到div这个标签。
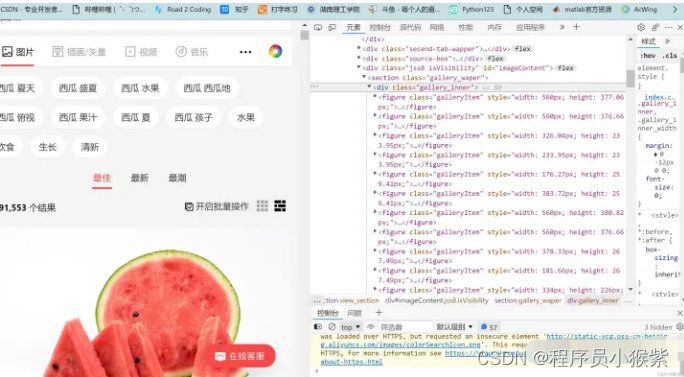
在xpath中//表示在该本文中搜索所有的div标签,[@class=“gallery_inner”]则将div标签限定,再通过/figure找到所有的标签。
xpath进行匹配:
figure_list = tree.xpath('//div[@class="gallery_inner"]/figure')
接着我们对所有的li标签进行循环,依次对每个图片地址进行操作。
for figure in figure_list:
img_src = figure.xpath('./a/img/@data-src')[0]
img_src = 'https:' + img_src
img_name = img_src.split('/')[-1]
img_data = requests.get(url=img_src,headers=header).content
img_path = 'piclitl/' + img_name
with open(img_path, 'wb') as fp:
fp.write(img_data)
print(img_name, '下载成功')
大致框架搭好后运行,发现了两个报错:
一、在对figure标签请求时,匹配没有结果出现列表超出范围的报错。
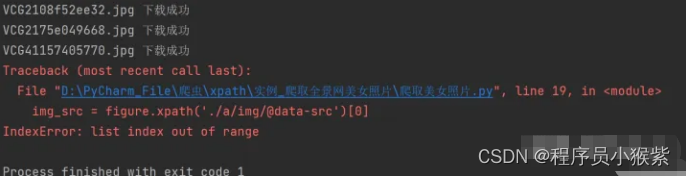
通过对网站的分析,我们发现图中创意视频推荐也在figure标签中,所以但其实际上没有a和img标签,所以匹配没有结果,导致程序直接报错停止。
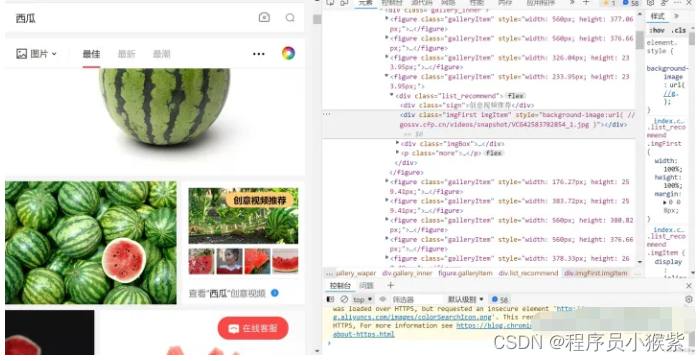
这里采用try…expect…语句让程序遇到此类报错时直接跳过
try:
img_src = figure.xpath('./a/img/@data-src')[0]
except(IndexError):
print('未成功匹配到字段')
二、当匹配没有结果时,我们选择跳过,所以此时对图片数据申请时没有结果
try:
img_data = requests.get(url=img_src, headers=header).content
except(requests.exceptions.InvalidURL):
print('没有访问地址')
以上便是利用python网络爬虫对图片进行批量爬取,如果你对爬虫感兴趣,不妨以本文为案例,打开爬虫世界的大门。
完整代码
from lxml import etree
import requests
import os
if __name__ == '__main__':
url = 'https://www.vcg.com/creative-image/xigua/'
header = {
'User_Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.5005.63 Safari/537.36 Edg/102.0.1245.39'
}
response = requests.get(url=url, headers=header)
response.encoding = 'utf-8'
page_text = response.text
tree = etree.HTML(page_text)
figure_list = tree.xpath('//div[@class="gallery_inner"]/figure')
if not os.path.exists('./piclitl'):
os.makedirs('./piclitl')
for figure in figure_list:
try:
img_src = figure.xpath('./a/img/@data-src')[0]
except(IndexError):
print('未成功匹配到字段')
img_src = 'https:' + img_src
img_name = img_src.split('/')[-1]
try:
img_data = requests.get(url=img_src, headers=header).content
except(requests.exceptions.InvalidURL):
print('没有访问地址')
img_path = 'piclitl/' + img_name
with open(img_path, 'wb') as fp:
fp.write(img_data)
print(img_name, '下载成功')
关于Python技术储备
学好 Python 不论是就业还是做副业赚钱都不错,但要学会 Python 还是要有一个学习规划。最后大家分享一份全套的 Python 学习资料,给那些想学习 Python 的小伙伴们一点帮助!
一、Python所有方向的学习路线
Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

二、Python必备开发工具

三、Python视频合集
观看零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。
四、实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
五、Python练习题
检查学习结果。

上述这份完整版的Python全套学习资料已经上传CSDN官方,如果需要可以微信扫描下方CSDN官方认证二维码 即可领取
👉[[CSDN大礼包:《python安装包&全套学习资料》免费分享]](安全链接,放心点击)
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









