







Linux虚拟机Hive基本安装详细步骤(具体步骤请下滑到第三点)
目录
Linux虚拟机Hive基本安装详细步骤(具体步骤请下滑到第三点)
2、 mysql-connector-java-5.1.27-bin.jar 下载
一、为什么要在虚拟机中安装Hive?
1.学习和实验:虚拟机提供了一个相对封闭和独立的环境,允许开发人员和学生在不影响其主要操作系统的情况下学习和实验Hive。这使得可以轻松地建立、测试和调整Hive集群,以便更好地理解其工作原理。
2.开发和调试:虚拟机环境可用于本地开发和调试Hive查询、数据处理流程和其他大数据任务。这种方式可以节省与在实际大数据集群上开发和调试相关任务相关的成本和时间。
3.演示和培训:虚拟机可以用于演示Hive和其他大数据工具的功能,以便在培训和演示中提供更好的学习体验。它们可以帮助教育机构、培训机构和企业培训师向学员和员工展示如何使用Hive。
4.离线使用:有些情况下,网络连接可能不稳定或不可用,虚拟机中安装的Hive集群允许用户在没有网络连接的情况下继续工作。
5.版本控制:通过使用虚拟机,您可以轻松创建和管理不同版本的Hive集群,以便测试和比较各个版本的功能和性能。
6.隔离和安全性:虚拟机提供了一种将Hive环境隔离到虚拟容器中的方式,从而降低潜在的安全风险,因为虚拟机可以在隔离的环境中运行。
二、Hive是什么?
Hive 是一种开源的数据仓库工具,Hive 提供了一种基于 Hadoop 的数据仓库基础设施,允许用户查询和分析大规模的数据集,通常用于大数据处理和分析任务。
Hive的关键特点及概念:
1.SQL-Like 查询语言:Hive 使用类似于 SQL 的查询语言,称为 Hive QL(HQL),允许用户以熟悉的方式查询数据。
2.数据存储和管理:Hive 使用 Hadoop 分布式文件系统(HDFS)来存储和管理数据。它可以处理多种数据格式,包括文本、JSON、Parquet 等,同时提供表、分区和分桶等数据组织结构。
3.元数据存储:Hive 使用元数据存储来维护有关数据的结构信息,包括表的模式、列名和数据位置等。用户可以轻松地创建、修改和查询表,而无需深入了解数据的物理存储方式。
4.扩展性和可编程性:Hive 是可扩展的,允许用户编写自定义函数和用户定义的聚合函数(UDF 和 UDAF),以便在查询中执行自定义操作。这增加了 Hive 的功能和适用性。
5.作业调度和优化:Hive 通过内置的查询优化器来优化查询计划,以提高查询性能。它还可以与 Hadoop 集群管理工具(如 YARN)一起使用,以实现作业调度和资源管理。
6.集成生态系统:Hive紧密集成了大数据生态系统中的其他工具,如 Hadoop MapReduce、Spark、Tez 等。这允许用户在不同的大数据工具之间进行无缝切换,根据任务的需求选择合适的工具。
三、Hive基本安装
1、下载安装
(打开下载地址后,如下图点击 apache-hive-3.1.2-bin.tar.gz 下载)

2、上传jar包
cd /usr/local/tage/进入tage文件夹下 rz 或者直接拖入(下面方法为直接拖入)

ll 查看压缩包是否存在

3、解压
tar -zxvf apache-hive-3.1.2-bin.tar.gz -C/usr/local/server
解压之后回到 server 文件夹下查看是否成功
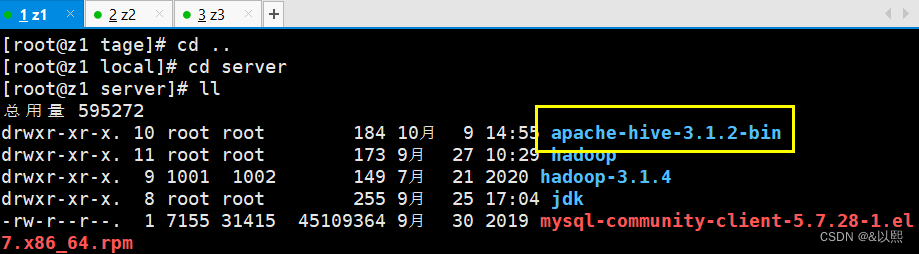
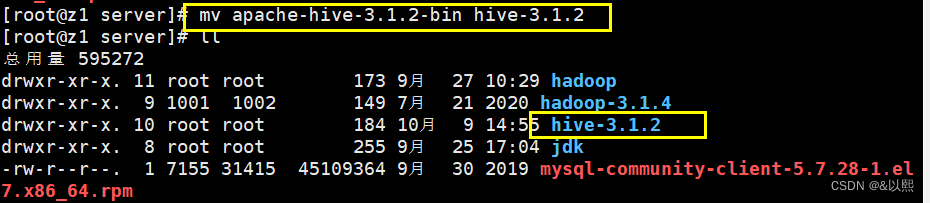
为了方便,我们给他改一个名字,方便我们之后使用
mv apache-hive-3.1.2-bin.tar.gz hive-3.1.2(下面运行是因为我已经改了一次名字,所以没有.tar.gz后缀,你们第一次运行就复制上面的命令就好啦)
建立软链接
ln -s hive-3.1.2/ hive ![]()

4、添加环境变量
vi /etc/profile回车之后按键盘上的 i 键,在最下面输入一下内容:
export HIVE_HOME=/usr/local/server/hive
export PATH=$PATH:$HIVE_HOME/bin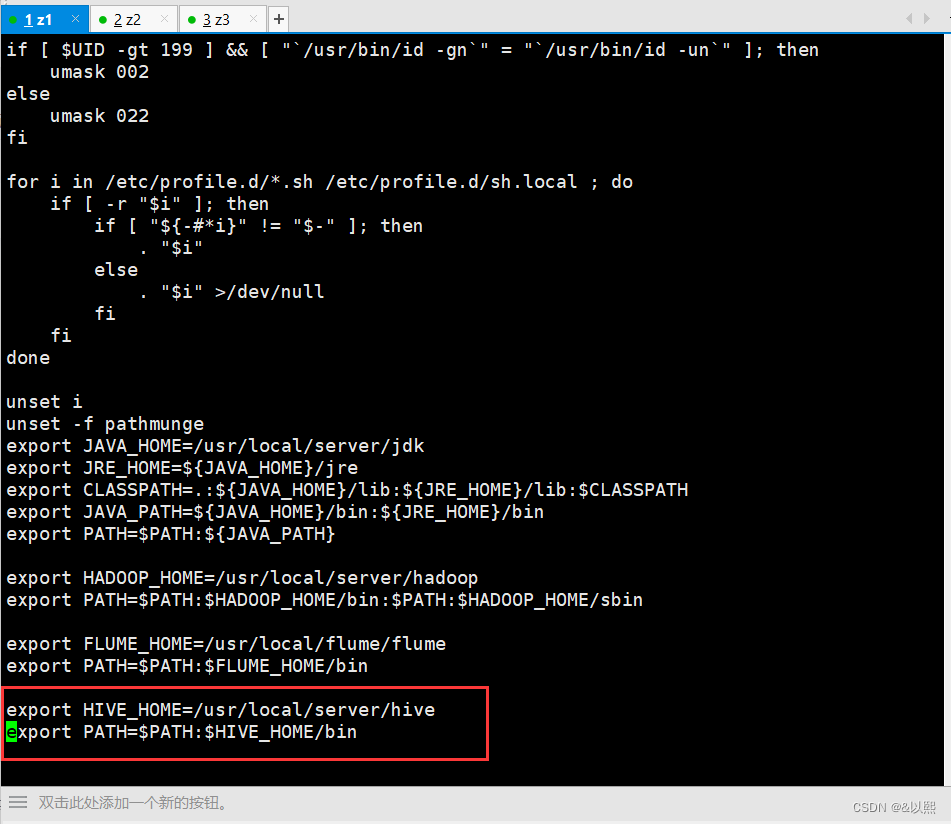
输入完毕后按 Esc 键 输入:wq 回车 就保存好啦!

:wq表示,保存并退出。如果只按:q,则是只退出不保存。:q!表示强制退出。
添加完环境变量后一定要记得更新环境变量
source /etc/profile
在 Linux 系统中,环境变量是一些系统级别的变量,用于存储系统的配置信息和用户的个性化设置。/etc/profile 是一个系统级别的 shell 脚本文件,用于设置系统级别的环境变量。当用户登录系统时,/etc/profile 会被自动执行一次,从而设置系统级别的环境变量。但是,如果在当前终端会话中修改了环境变量,而没有重新加载 /etc/profile,那么这些修改不会生效。此时,可以使用 “source /etc/profile” 命令重新加载 /etc/profile,使得当前终端会话中的程序可以使用最新的环境变量配置。
5、解决jar包冲突
先去到 lib 文件夹下进行
cd /usr/local/server/hive/lib/
hive文件夹中的lib文件夹是用来存放Hive所需的依赖库的。这些依赖库包括Hadoop、Hive自身的jar包以及其他第三方jar包等。
Hive是建立在Hadoop之上的数据仓库工具,因此需要依赖Hadoop的相关库。同时,Hive也提供了自己的一些jar包,如hive-exec.jar、hive-metastore.jar等,这些jar包包含了Hive的核心功能,而这些jar包都存放在lib文件夹下。此外,Hive还支持用户自定义函数(UDF),用户可以将自己编写的UDF打包成jar包放在lib文件夹中,以供Hive使用。
解决jar包冲突:将 log4j-sif4j-imp1l-2.10.0.jar 的后缀名改为bak
mv log4j-sif4j-imp1l-2.10.0.jar log4j-slf4j-impi-2.10.0.bak ll 查看lib里面的文件:很明显可以看出,后缀名改了之后,包的颜色也随之改变了
ll 查看lib里面的文件:很明显可以看出,后缀名改了之后,包的颜色也随之改变了

6、初始化元数据库
依旧在 lib 文件夹下:删除原有的 guava-19.0.jar
rm -f guava-19.0.jarrm是Linux系统下的删除命令,-f参数表示强制删除,即使文件被保护或不存在也会被删除。

将自己刚下载的 guava-27.0-jre.jar 放入该文件夹下(rz 或者直接拖入。下面方法为直接拖入)

初始化数据库
先进入 bin 文件夹下,运行命令

schematool -dbType derby -initSchema
运行到最后是这个样子就初始化成功啦
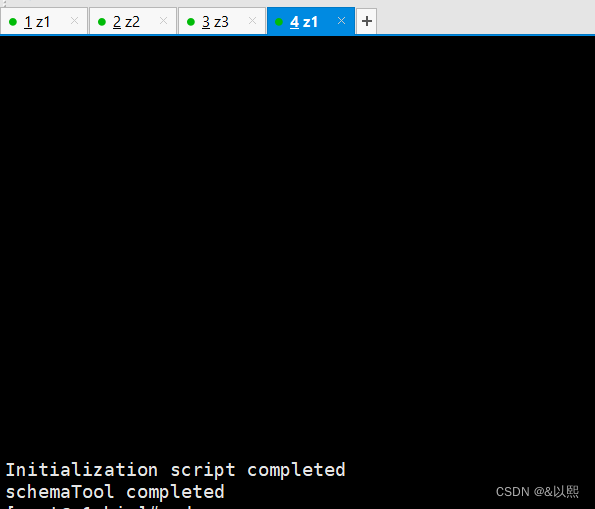
四、元数据配置
1、将 mysql 拷贝到 lib 下

2、 mysql-connector-java-5.1.27-bin.jar 下载

3、上传jar包,方法同上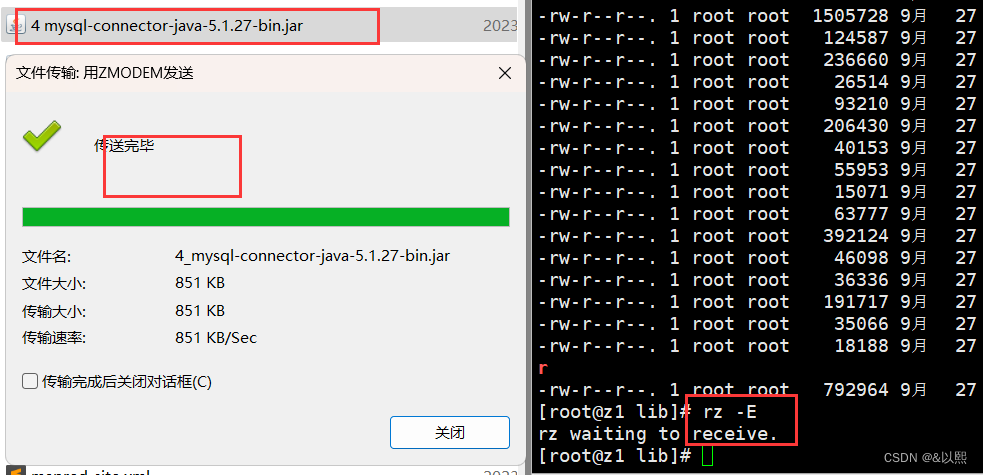
4、配置hive元数据支持为mysql
去到 hive/conf 文件下并新建 hive-site.xml
cd /usr/local/server/hive/conf/
vi hive-site.xml
5、编辑插入 hive-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- jdbc 连接的 URL -->
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://192.168.238.111:3306/metastore?useSSL=false</value>
</property>
<!-- jdbc 连接的 Driver -->
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<!-- jdbc 连接的 username -->
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<!-- jdbc 连接的 password -->
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
</property>
<!-- Hive 元数据存储版本的验证 -->
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
</property>
<!-- 元数据存储授权 -->
<property>
<name>hive.metastore.event.db.notification.api.auth</name>
<value>false</value>
</property>
<!-- Hive 默认在 HDFS 的工作目录 -->
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/usr/local/server/hive/warehouse</value>
</property>
<!-- 指定存储元数据要连接的地址 -->
<property>
<name>hive.metastore.uris</name>
<value>thrift://192.168.238.111:9083</value>
</property>
<!-- 指定 hiveserver2 连接的 host -->
<property>
<name>hive.server2.thrift.bind.host</name>
<value>192.168.238.111</value>
</property>
<!-- 指定 hiveserver2 连接的端口号 -->
<property>
<name>hive.server2.thrift.port</name>
<value>10000</value>
</property>
<property>
<name>hive.cli.print.header</name>
<value>true</value>
</property>
<property>
<name>hive.cli.current.db</name>
<value>true</value>
</property>
<property>
<name>hive.server2.enable.doAs</name>
<value>false</value>
</property>
</configuration>
插入完成后,保存退出。
6、登录mysql
mysql -uroot -p123456
create database metastore;
show databases;
exit;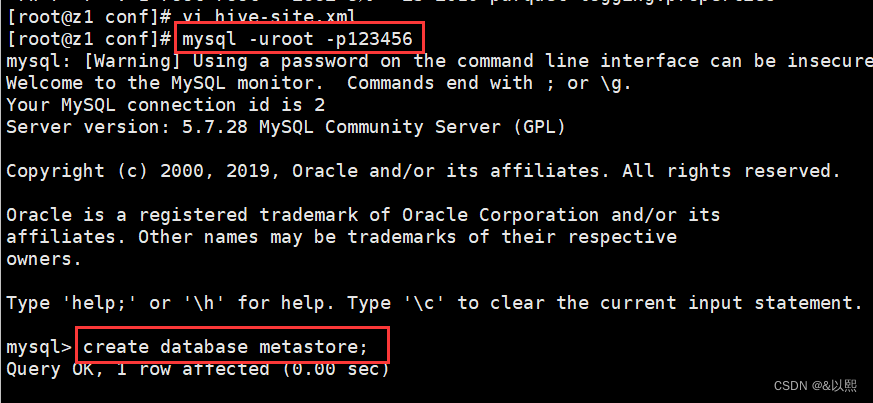

7、初始化元数据库
先去到mysql文件下
cd /var/lib/mysql/
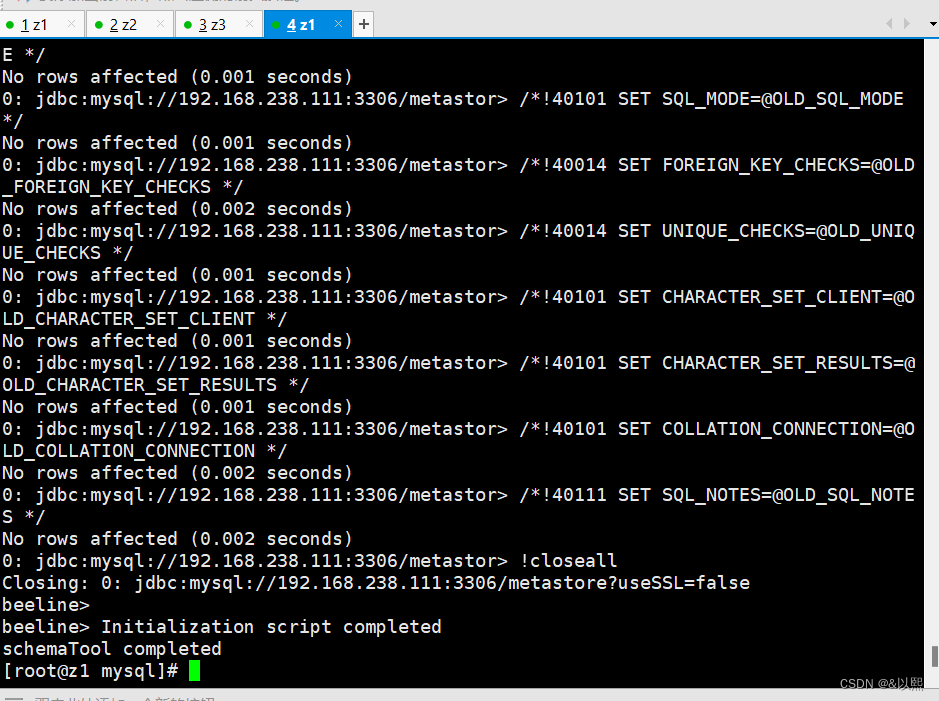
schematool -initSchema -dbType mysql -verbose初始化成功!
五、Hive启动检测
1、编写启动脚本
cd /usr/local/server/hive/ && cd bin && touch hiveservice.sh 6& chmod77hiveservice.sh && vi hiveservice.sh
将以下内容添加到文件中
#!/bin/bash
HIVE_LOG_DIR=$HIVE_HOME/logs
if [ ! -d $HIVE_LOG_DIR ]
then
mkdir -p $HIVE_LOG_DIR
fi
#检查进程是否运行正常,参数1为进程名,参数2为进程端口
function check_process()
{
pid=$(ps -ef 2>/dev/null | grep -v grep | grep -i $1 | awk '{print $2}')
ppid=$(netstat -nltp 2>/dev/null | grep $2 | awk '{print $7}' | cut -d '/' -f 1)
echo $pid
[[ "$pid" =~ "$ppid" ]] && [ "$ppid" ] && return 0 // return 1
}
function hive_start()
{
metapid=$(check_process HiveMetastore 9083)
cmd="nohup hive --service metastore > $HIVE_LOG_DIR/metastore.log 2>&1&"
[ -z "$metapid" ] && eval $cmd || echo "Metastroe服务已启动"
server2pid=$(check_process HiveServer2 10000)
cmd="nohup hive --service hiveserver2>$HIVE_LOG_DIR/hiveServer2.log 2>&1 &"
[ -z "$server2pid" ] && eval $cmd || echo"HiveServer2服务已启动"
}
function hive_stop()
{
metapid=$(check_processHiveMetastore 9083)
[ "$metapid" ] && kill $metapid || echo"Metastore服务未启动"
server2pid=$(check_process HiveServer2 10000)
[ "$server2pid" ] && kill $server2pid || echo"HiveServer2服务未启动"
}
case $1 in "start")
hive_start
;;
"stop")
hive_stop
;;
"restart")
hive_stop
sleep 2
hive_start
;;
"status")
check_process HiveMetastore 9083 >/dev/null && echo"Metastore服务运行正常" || echo "Metastore服务运行异常"
check_process HiveServer2 10000 >/dev/null && echo"HiveServer2服务运行正常" || echo"HiveServer2服务运行异常"
;;
*)
echo Invalid Args!
echo 'Usage: '$(basename $0)' start|stop|restart|status'
;;
esac保存退出。
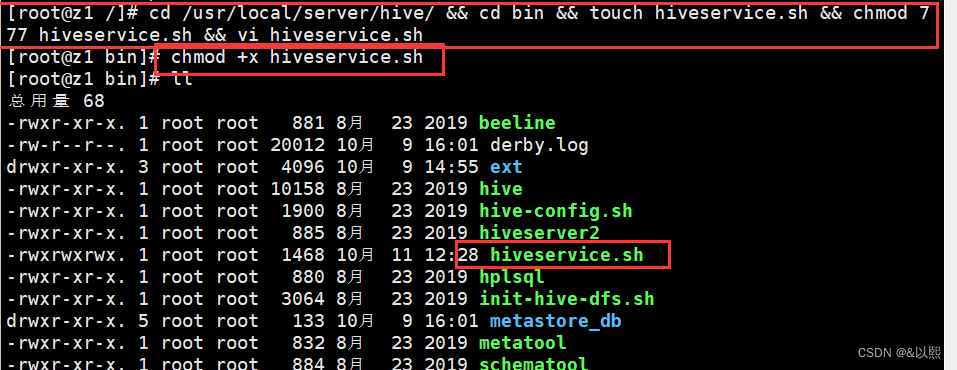
2、启动脚本执行赋权
chmod +x hiveservice.sh运行之前

运行之后
3、配置 hive 日志路径
先去hive/conf文件夹下,将 hive-log4j2.properties.template 的名字修改为 hive-log4j2.properties
cd /usr/local/server/hive/conf/
mv hive-log4j2.properties.template hive-log4j2.properties
mv的用法:
①将源文件重命名为目标文件名:mv [源文件] [目标文件]
②将源文件移动到目标目录中:mv [源文件] [目标目录]
③将源目录移动到目标目录中:mv [源目录] [目标目录]
将 property.hive.log.dir 的值修改为以下内容
vi hive-log4j2.properties
property.hive.log.dir = /usr/local/server/hive/logs![]()

保存退出。
4、hive启动检测
#执行脚本启动
cd /usr/local/server/hive/bin/
hiveservice.sh start
./hiveserver2
hive
注意:启动hive之前,请先启动集群,不然你就会像这样有许多许多缺口报错

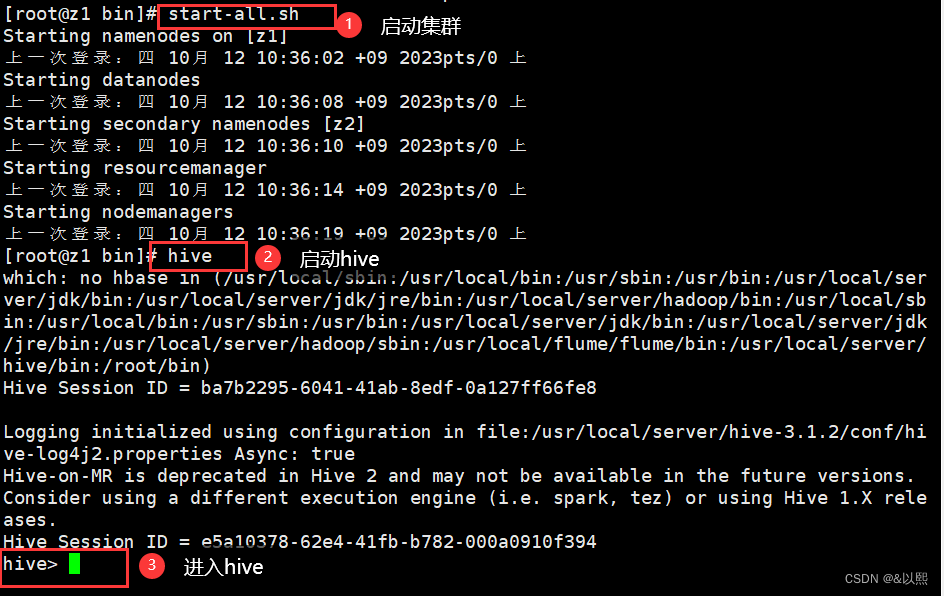
show databases
好了,到这里就结束了,你的hive已经安装成功!















 5205
5205











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









