






实现 strStr()
题目描述
实现 strStr() 函数。
给定一个 haystack 字符串和一个 needle 字符串,在 haystack 字符串中找出 needle 字符串出现的第一个位置 (从0开始)。如果不存在,则返回 -1。
示例 1:
输入:haystack = "sadbutsad", needle = "sad"
输出:0
解释:"sad" 在下标 0 和 6 处匹配。
第一个匹配项的下标是 0 ,所以返回 0 。
示例 2:
输入:haystack = "leetcode", needle = "leeto"
输出:-1
解释:"leeto" 没有在 "leetcode" 中出现,所以返回 -1
说明: 当 needle 是空字符串时,我们应当返回什么值呢?这是一个在面试中很好的问题。 对于本题而言,当 needle 是空字符串时我们应当返回 0 。这与C语言的 strstr() 以及 Java的 indexOf() 定义相符。
解题思路





自己解题
暴力法实现无意义,就是让字符串needle与字符串haystack的所有长度为m的子串均匹配一次。
为了减少不必要的匹配,我们每次匹配失败即立刻停止当前子串的匹配,对下一个子串进行匹配。如果当前字串匹配成功,就返回当前子串开始的位置即可。如果所有子串都匹配失败,则返回-1
substring()也可以
class Solution {
public int strStr(String haystack, String needle) {
int m = needle.length();
int n = haystack.length();
for (int i = 0; i + m <= n; i++) {
boolean flag = true;
for (int j = 0; j < m; j++) {
if (haystack.charAt(i + j) != needle.charAt(j)) {
flag = false;
break;
}
}
if (flag) {
return i;
}
}
return -1;
}
}
复杂度分析:
时间复杂度:O(nm),其中n是字符串haystack的长度,m是字符串needle的长度。最坏情况下需要将字符串needle与字符串haystack的所有长度为m的子串均匹配一次。
空间复杂度:O(1),只需要常数的空间保存若干变量。
参考解题
KMP算法
暴力法的时间复杂度是O(mn),而KMP的时间复杂度是O(m+n),是因为其能在非完全匹配的过程中提取到有效信息进行复用,以减少重复匹配的消耗
暴力法匹配字符串,当出现不同位置时,将原字符串的指针移动至本次起始点的下一个位置,匹配串的指针移动至起始位置。继续尝试匹配,发现对不上,原串的指针会一直往后移动,知道能够与匹配串对上位置。
原文链接:https://blog.csdn.net/guliguliguliguli/article/details/130779516
class Solution {
//前缀表(不减一)Java实现
public int strStr(String haystack, String needle) {
if (needle.length() == 0) return 0;
int[] next = new int[needle.length()];
getNext(next, needle);
int j = 0;
for (int i = 0; i < haystack.length(); i++) {
while (j > 0 && needle.charAt(j) != haystack.charAt(i))
j = next[j - 1];
if (needle.charAt(j) == haystack.charAt(i))
j++;
if (j == needle.length())
return i - needle.length() + 1;
}
return -1;
}
private void getNext(int[] next, String s) {
int j = 0;
next[0] = 0;
for (int i = 1; i < s.length(); i++) {
while (j > 0 && s.charAt(j) != s.charAt(i))
j = next[j - 1];
if (s.charAt(j) == s.charAt(i))
j++;
next[i] = j;
}
}
}
补充
注意next数组的求解
private void getNext(int[] next, String s) {
int j = 0;
next[0] = 0;
for (int i = 1; i < s.length(); i++) {
while (j > 0 && s.charAt(j) != s.charAt(i))
j = next[j - 1];
if (s.charAt(j) == s.charAt(i))
j++;
next[i] = j;
}
}
}
找到重复的子字符串
题目描述
给定一个非空的字符串,判断它是否可以由它的一个子串重复多次构成。给定的字符串只含有小写英文字母,并且长度不超过10000
示例 1:
输入: s = "abab"
输出: true
解释: 可由子串 "ab" 重复两次构成。
示例 2:
输入: s = "aba"
输出: false
示例 3:
输入: s = "abcabcabcabc"
输出: true
解释: 可由子串 "abc" 重复四次构成。 (或子串 "abcabc" 重复两次构成。)
解题思路
在一个串中查找是否出现过另一个串,这是KMP所擅长的
当一个字符串由重复子串组成的,最长相等前后缀不包含的子串就是最小重复子串
- 前缀是指不包含最后一个字符的所有以第一个字符开头的连续子串;
- 后缀是指不包含第一个字符的所有以最后一个字符结尾的连续子串
在由重复子串组成的字符串中,最长相等前后缀不包含的子串就是最小重复子串,这里拿字符串s:abababab 来举例,ab就是最小重复单位,如图所示:
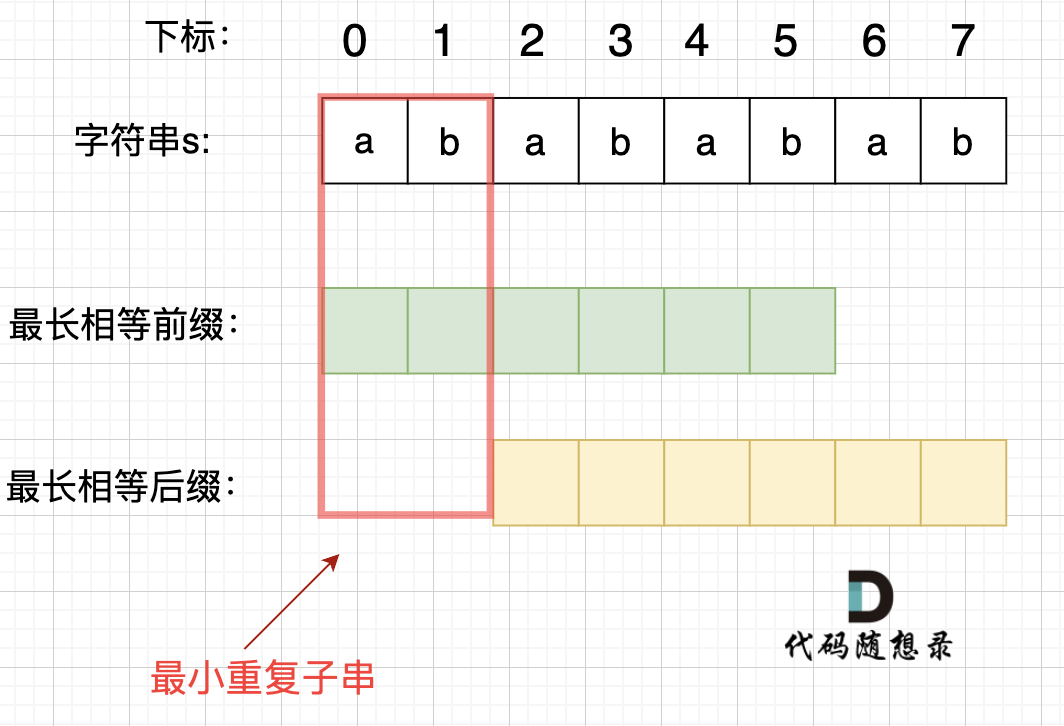 ****
****
如何找到最小重复子串
这里有同学就问了,为啥一定是开头的ab呢。 其实最关键还是要理解 最长相等前后缀,如图:
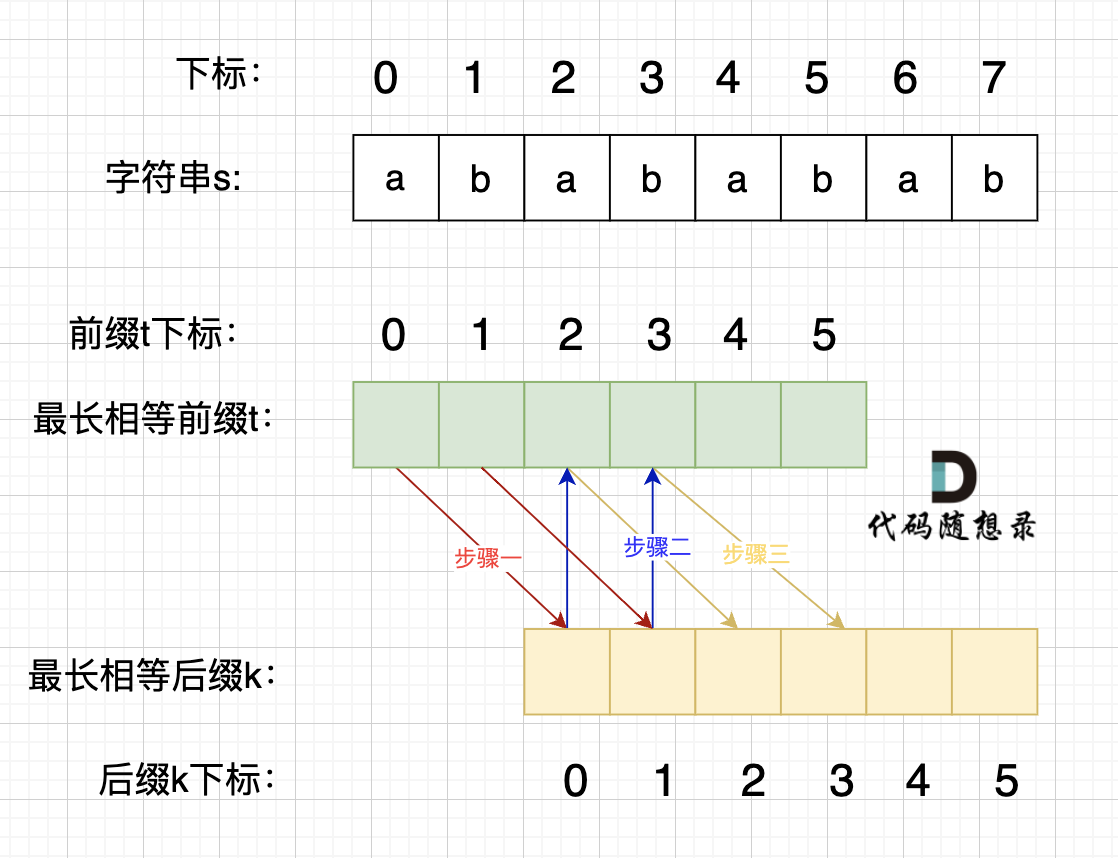
步骤一:因为 这是相等的前缀和后缀,t[0] 与 k[0]相同, t[1] 与 k[1]相同,所以 s[0] 一定和 s[2]相同,s[1] 一定和 s[3]相同,即:,s[0]s[1]与s[2]s[3]相同 。
步骤二: 因为在同一个字符串位置,所以 t[2] 与 k[0]相同,t[3] 与 k[1]相同。
步骤三: 因为 这是相等的前缀和后缀,t[2] 与 k[2]相同 ,t[3]与k[3] 相同,所以,s[2]一定和s[4]相同,s[3]一定和s[5]相同,即:s[2]s[3] 与 s[4]s[5]相同。
步骤四:循环往复。
所以字符串s,s[0]s[1]与s[2]s[3]相同, s[2]s[3] 与 s[4]s[5]相同,s[4]s[5] 与 s[6]s[7] 相同。
正是因为 最长相等前后缀的规则,当一个字符串由重复子串组成的,最长相等前后缀不包含的子串就是最小重复子串。
所以只需要判断:
if (next[len - 1] > 0 && len % (len - next[len - 1]) == 0) {//源字符串长度-最长相等前后缀的长度;这个值如果能被字符串长度整除,说明存在
return true;
}
return false;
}
自己解题
假设原字符串S是由子串s重复N次而成的,则S+S则有子串s重复2N次,那么现在有S=Ns,S+S=2Ns,其中N>=2。如果条件成立,掐头去尾破坏两个s,S+S中至少还有2(N-1)s,又因为N>=2,因此在S+S的索引从[0,length-2]中必出现一次以上
class Solution {
public boolean repeatedSubstringPattern(String s) {
return (s + s).substring(1, (s + s).length() - 1).contains(s);
}
}
KMP
class Solution {
public boolean repeatedSubstringPattern(String s) {
int len = s.length();
int[] next = new int[s.length()];
getNext(next, s);
/*
在由重复子串组成的字符串中,最长相等前后缀不包含的子串就是最小重复子串
重复子串的最小单位就是字符串里最长相等前后缀所不包含的子串
*/
if (next[len - 1] > 0 && len % (len - next[len - 1]) == 0) {//源字符串长度-最长相等前后缀的长度;这个值如果能被字符串长度整除,说明存在
return true;
}
return false;
}
private void getNext(int[] next, String s) {
int j = 0;
next[0] = 0;
for (int i = 1; i < s.length(); i++) {
while (j > 0 && s.charAt(j) != s.charAt(i))
j = next[j - 1];
if (s.charAt(j) == s.charAt(i))
j++;
next[i] = j;
}
}
}
参考解题
class Solution {
public boolean repeatedSubstringPattern(String s) {
if (s.equals(""))
return false;
int len = s.length();
// 原串加个空格(哨兵),使下标从1开始,这样j从0开始,也不用初始化了
s = " " + s;
char[] chars = s.toCharArray();
int[] next = new int[len + 1];
// 构造 next 数组过程,j从0开始(空格),i从2开始
for (int i = 2, j = 0; i <= len; i++) {
// 匹配不成功,j回到前一位置 next 数组所对应的值
while (j > 0 && chars[i] != chars[j + 1])
j = next[j];
// 匹配成功,j往后移
if (chars[i] == chars[j + 1])
j++;
// 更新 next 数组的值
next[i] = j;
}
// 最后判断是否是重复的子字符串,这里 next[len] 即代表next数组末尾的值
if (next[len] > 0 && len % (len - next[len]) == 0) {
return true;
}
return false;
}
}
补充
- 前缀是指不包含最后一个字符的所有以第一个字符开头的连续子串;
- 后缀是指不包含第一个字符的所有以最后一个字符结尾的连续子串
在由重复子串组成的字符串中,最长相等前后缀不包含的子串就是最小重复子串
if (next[len - 1] > 0 && len % (len - next[len - 1]) == 0)
/*
原字符串长度-最长相等前后缀的长度next[len - 1];这个值如果能被字符串长度整除,说明存在
*/
今日所学的KMP算法较难,尤其是next数组的求解
ps:部分图片和代码来自代码随想录和Leetcode官网














 713
713











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









