







目录
一、Kafka 的介绍
1.1 消息队列的作用
常见的MQ消息中间件有很多,例如ActiveMQ、RabbitMQ、Kafka、RocketMQ等等。那么为什么我们要使用它呢?因为它能很好的帮我解决一些复杂特殊的场景:
1️⃣ 高并发的流量削峰
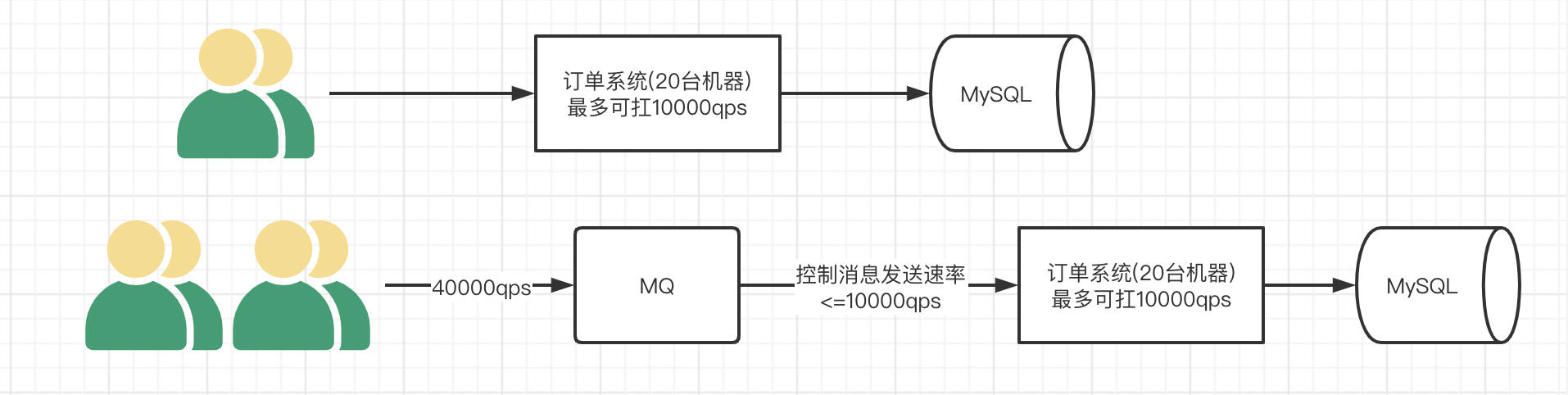
举个例子,假设某订单系统每秒最多能处理一万次订单,也就是最多承受的10000qps,这个处理能力应付正常时段的下单时绰绰有余,正常时段我们下单一秒后就能返回结果。但是在高峰期,如果有两万次下单操作系统是处理不了的,只能限制订单超过一万后不允许用户下单。使用消息队列做缓冲,我们可以取消这个限制,把一秒内下的订单分散成一段时间来处理,这时有些用户可能在下单十几秒后才能收到下单成功的操作,但是比不能下单的体验要好。
2️⃣ 应用解耦
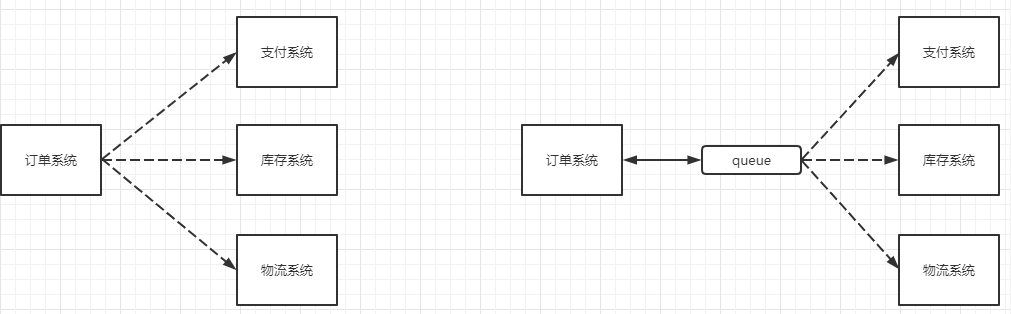
以电商应用为例,应用中有订单系统、库存系统、物流系统、支付系统。用户创建订单后,如果耦合调用库存系统、物流系统、支付系统,任何一个子系统出了故障,都会造成下单操作异常。当转变成基于消息队列的方式后,系统间调用的问题会减少很多,比如物流系统因为发生故障,需要几分钟来修复。在这几分钟的时间里,物流系统要处理的内存被缓存在消息队列中,用户的下单操作可以正常完成。当物流系统恢复后,继续处理订单信息即可,中单用户感受不到物流系统的故障,提升系统的可用性。
3️⃣ 异步处理
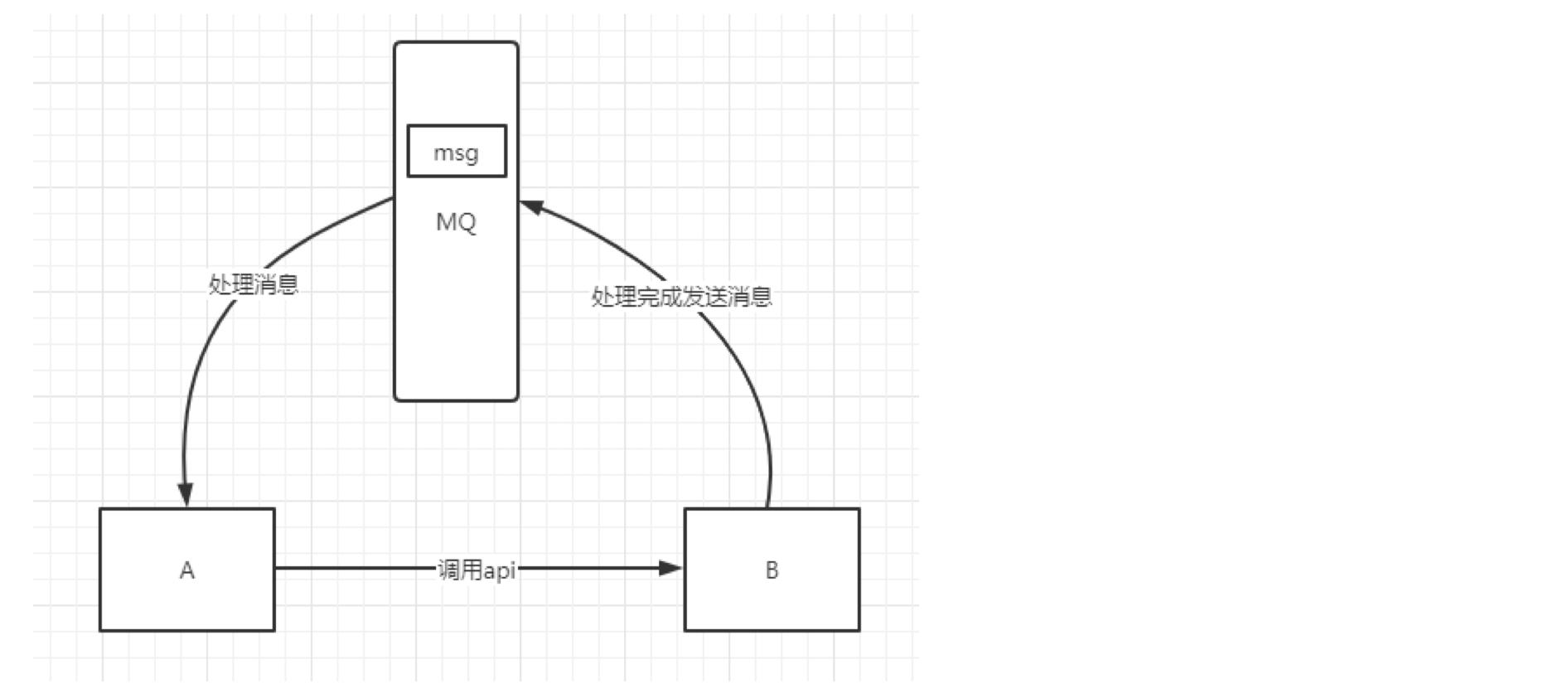
有些服务间调用是异步的,例如 A 调用 B,B 需要花费很长时间执行,但是 A 需要知道 B 什么时候可以执行完,以前一般有两种方式,A 过一段时间去调用 B 的查询 api 查询。或者 A 提供一个 callback api, B 执行完之后调用 api 通知 A 服务。这两种方式都不是很优雅,使用消息队列,可以很方便解决这个问题,A 调用 B 服务后,只需要监听 B 处理完成的消息,当 B 处理完成后,会发送一条消息给 MQ,MQ 会将此消息转发给 A 服务。这样 A 服务既不用循环调用 B 的查询 api,也不用提供 callback api。同样B 服务也不用做这些操作。A 服务还能及时的得到异步处理成功的消息。
4️⃣ 分布式事务
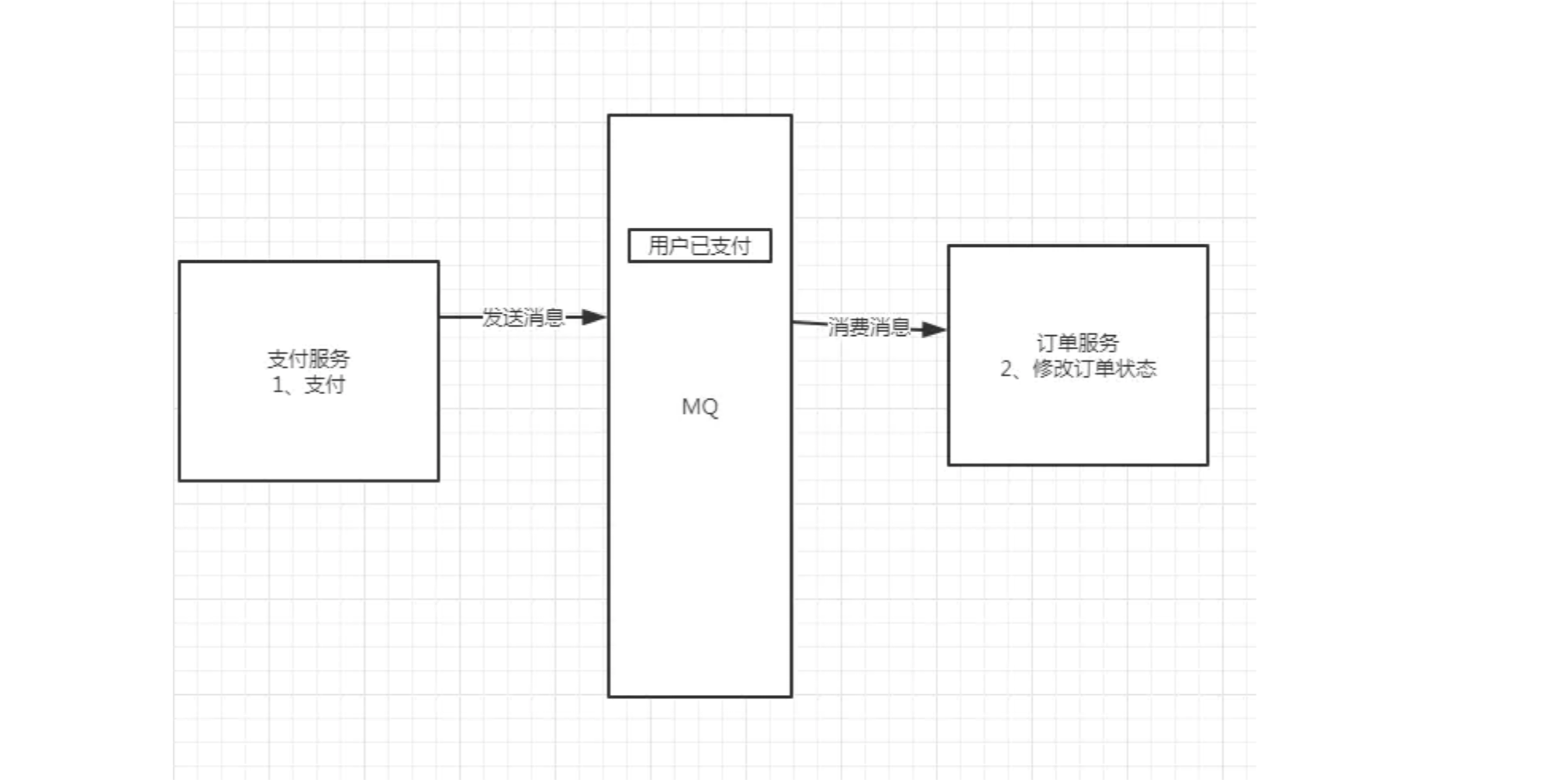
以订单服务为例,传统的方式为单体应用,支付、修改订单状态、创建物流订单三个步骤集成在一个服务中,因此这三个步骤可以放在一个jdbc事务中,要么全成功,要么全失败。而在微服务的环境下,会将三个步骤拆分成三个服务,例如:支付服务,订单服务,物流服务。三者各司其职,相互之间进行服务间调用,但这会带来分布式事务的问题,因为三个步骤操作的不是同一个数据库,导致无法使用jdbc事务管理以达到一致性。而 MQ 能够很好的帮我们解决分布式事务的问题,有一个比较容易理解的方案,就是二次提交。基于MQ的特点,MQ作为二次提交的中间节点,负责存储请求数据,在失败的情况可以进行多次尝试,或者基于MQ中的队列数据进行回滚操作,是一个既能保证性能,又能保证业务一致性的方案,如下图所示:
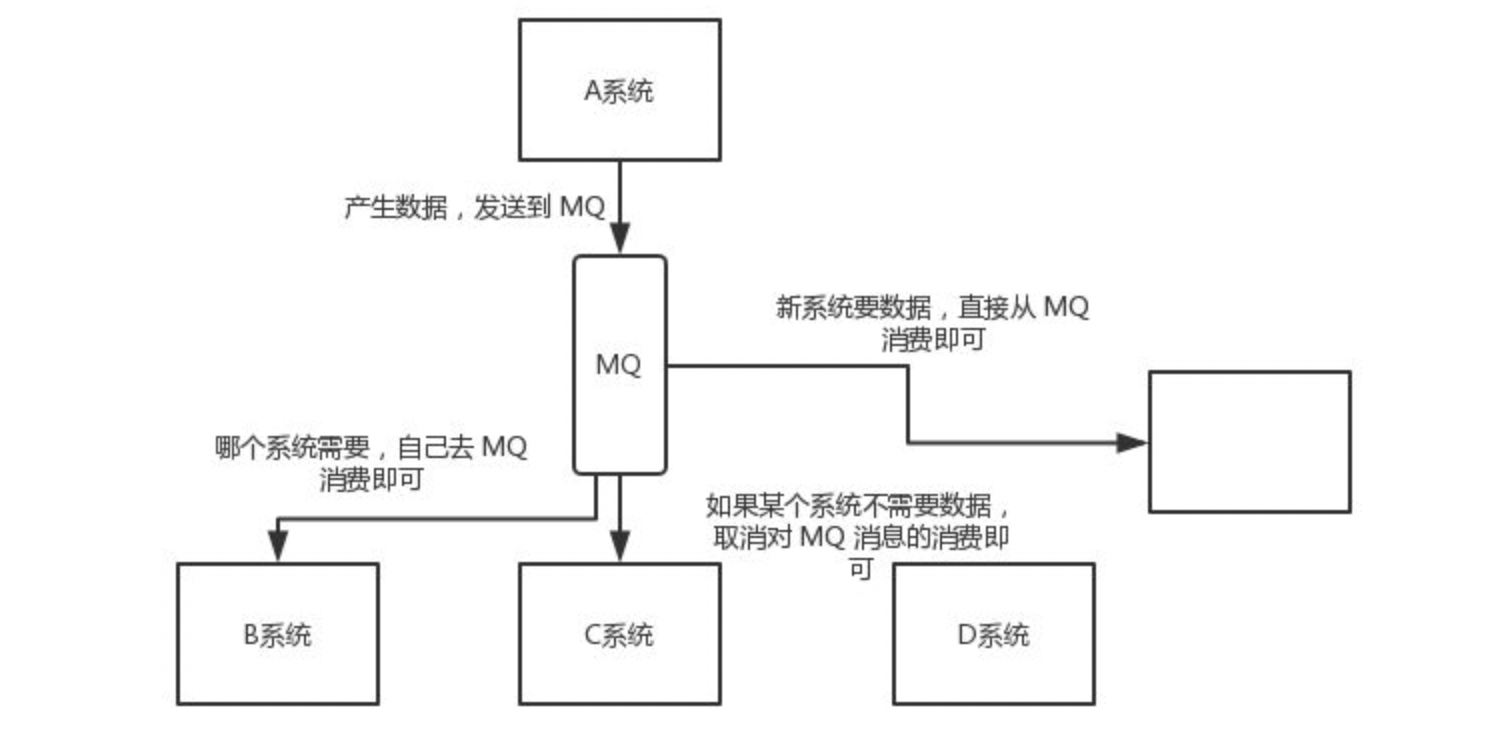
5️⃣ 数据分发
MQ 具有发布订阅机制,不仅仅是简单的上游和下游一对一的关系,还有支持一对多或者广播的模式,并且都可以根据规则选择分发的对象。这样一份上游数据,众多下游系统中,可以根据规则选择是否接收这些数据,能达到很高的拓展性。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











