







time.sleep --------我认为是最简单的反爬手段
如何分析URL地址与构造URL参数的思路。
使用别的网站也可以写函数测试,因为网站随时有可能会变。
from urllib.request import Request,urlopen
from time import sleep
# 函数测试
def spider_music(page):
# 构造 URL地址
for num in range(1,page+1):
url = f"https://www.bilibili.com/movie/index/?from_spmid=666.7.index.1#st=2&style_id=-1&area=2&release_date=-1&season_status=-1&order=2&sort=0&page={num}"
# 构造请求对象
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/123.0.0.0 Safari/537.36 Edg/123.0.0.0'}
# 发送请求
req = Request(url,headers=headers)
resp = urlopen(req)
# 获取响应
print(resp.getcode())
print(resp.geturl())
# 休眠
sleep(2)#https://www.bilibili.com/movie/index/?from_spmid=666.7.index.1#st=2&style_id=-1&area=2&release_date=-1&season_status=-1&order=2&sort=0&page=3
# 测试
if __name__ == "__main__":
spider_music(3)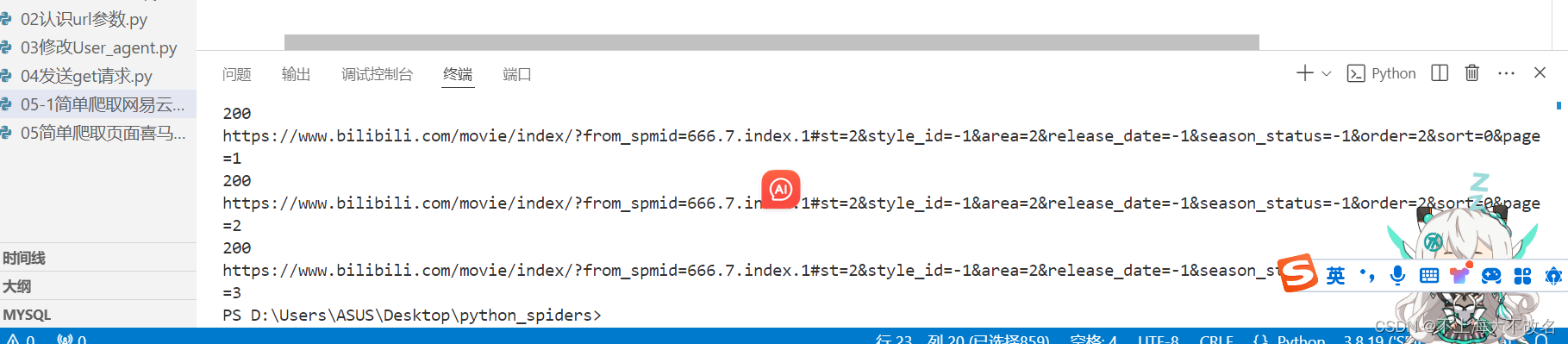

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











