







1,为啥要学习他的底层原理
实现,在前面我们只用了urlopen,如下图
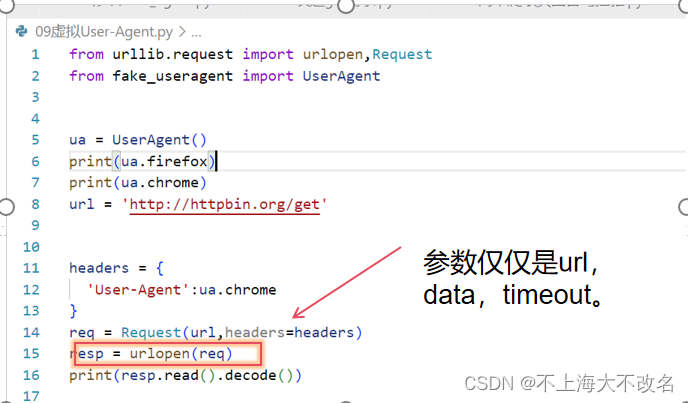
所以,根据查阅资料:
当我获取一个URL我们使用一个opener(一个urllib.OpenerDirector的实例)。在前面,我们都是使用的默认的opener,也就是urlopen。它是一个特殊的opener,可以理解成opener的一个特殊实例,传入的参数仅仅是url,data,timeout。
如果我们需要用到Cookie,只用这个opener是不能达到目的的,所以我们需要。
2,实现原理
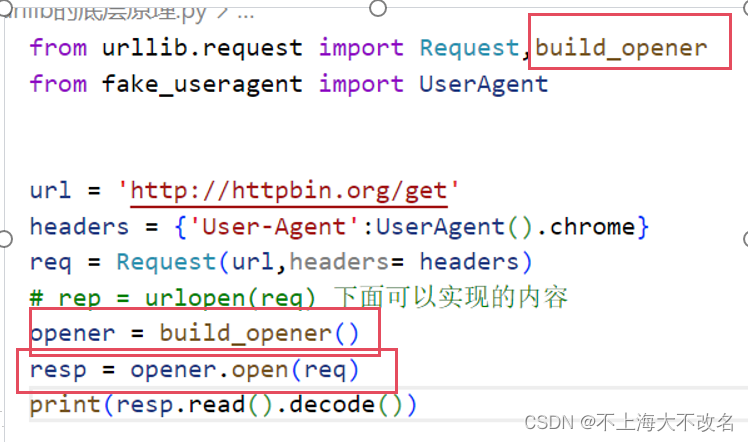
上面是简单的urllib的实现原理,大家可以直接店看看(右键+Ctrl)我用的VScode!
前面我们也说到为什么要使用build_opener,因为urllib的功能单一,如果我们想要实现其他功能,此时就需要使用Handler。如下图
from urllib.request import Request,build_opener
from fake_useragent import UserAgent
from urllib.request import HTTPHandler
url = 'http://httpbin.org/get'
headers = {'User-Agent':UserAgent().chrome}
req = Request(url,headers= headers)
handler = HTTPHandler(debuglevel=1)
opener = build_opener(handler)
resp = opener.open(req)
print(resp.read().decode())
在网上的说法,就是,如下图,更好理解:
















 750
750

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











