







背景
因为最近学弟要做毕业设计,他们电脑也训练不动呀,于是我就想着使用paddle复现一下,计划就在flychairs上训练一下,有个过程就可以了,并且可能也没有其他人做,正好也可以给别人借鉴一下,现在ai studio上有人复现了RAFT和FlowNet,我们这里借鉴RAFT进行书写,毕竟很多都是通用的嘛。
项目创建
这里大家先在ai studio上创建个账号,这个我就不演示了,很简单,https://aistudio.baidu.com/index
然后把这个项目https://aistudio.baidu.com/projectdetail/5656224?contributionType=1创建一个副本,之后cpu启动,点击确定,这时启动项目就可以给我们8点算力,这样的话我们使用v100 16G每天可以白嫖4小时,也够了。
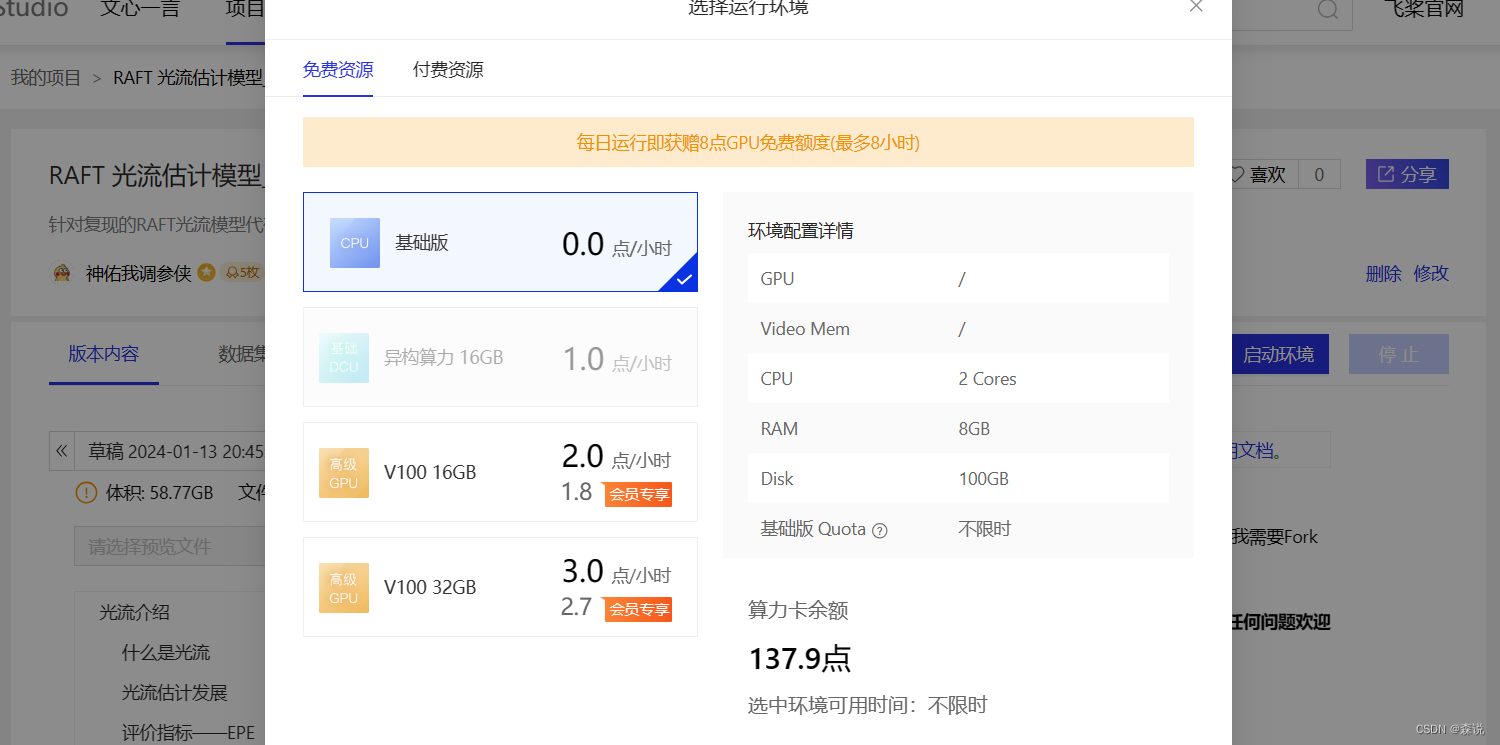
之后创建我会放出我的pwc-net的项目,也是创建副本。
数据部分
首先我们直接从RAFT中把这两个文件复制过来,这些工具就不重新写了,然后我们看一下这两个文件有光流的读写,光流转png等,等用到的时候我们在说。
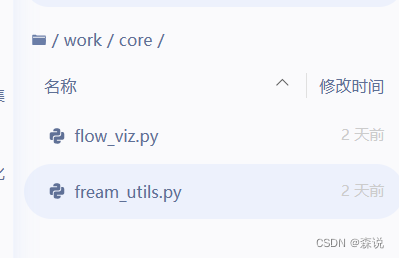
之后对于数据读取最重要的就是书写dataset和dataloader,这里因为我们用的是同一个数据集,所以这部分是可以进行copy的,但如果后面要写无监督可能就要自己写了。

Flowdataset类
上面最重要的就是datasets这个文件,我们这里详细的看下这个文件,这里先是创建一个Flowdataset的类,继承dataset,这里包括一些基本的东西,_getitem__和_len__等。这里面是先判断是否使用数据增强,就是如果给了参数就会创建一个数据增强对象,然后创建几个变量。
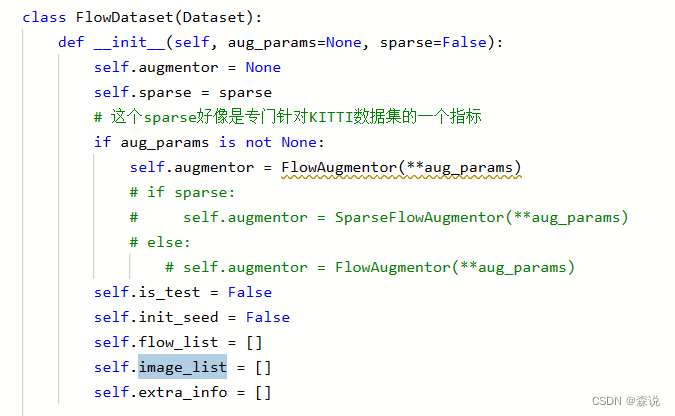
这里面的image_list要注意一下,这个里面是放了两张图片和光流(不是只有图片),从下图也可以看到,之后将其判断是否是灰度图像或数据增强,之后返回tensor的float32形式。
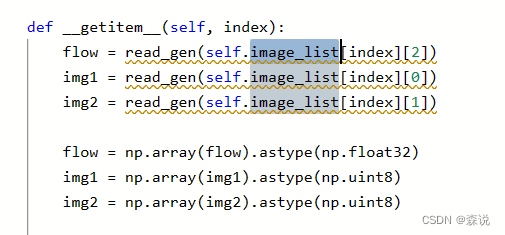
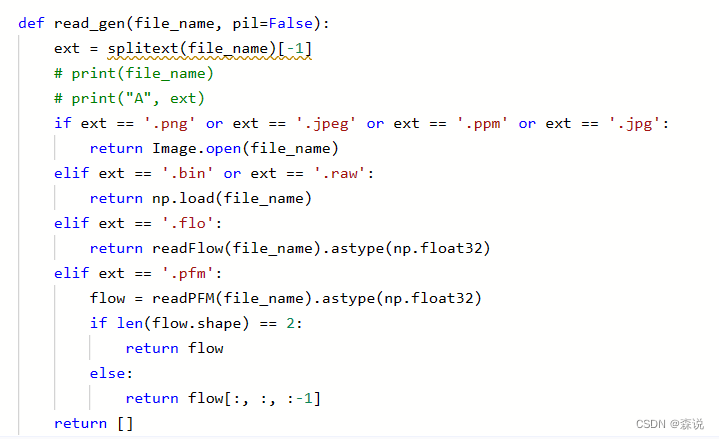
这里面也使用了read_gen来读取,我们看一下这个函数,不得不说,这个函数封装的蛮好的,必须积累一下:它根据不同的数据格式有不同读取方法,然后返回数据。
数据增强
之后我们看一下这个数据增强器里面有什么吧:

sintel和flychairs的类
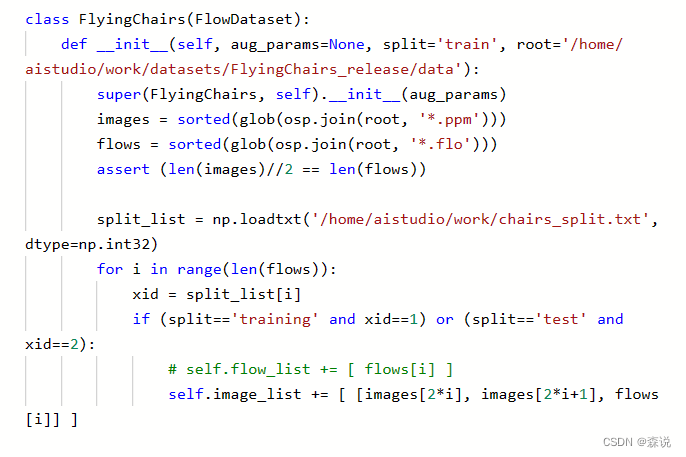
之后创建了一个sintel和flychairs的类,继承Flowdataset,主要就是确定了image_list的列表,这样就可以dataloader了。
dataloader
这个就是使用上面的dataset和一些训练参数来获取dataloader,然后返回这个dataloader。

测试
下面我们来测试一下这些代码,看看是什么效果吧。
我们先把数据切分文件复制一下:chirs_split.txt用于划分FlyingChairs的训练集和验证集
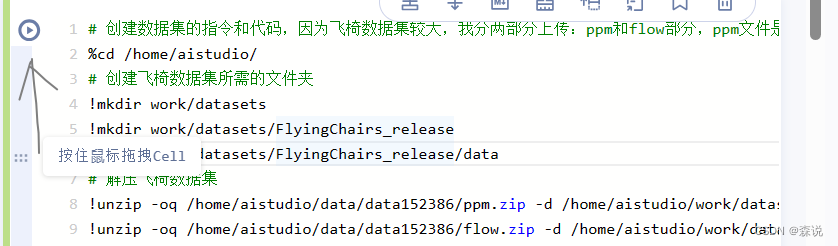
之后我们开始解压一下数据集,这里面是有两个文件夹,放两帧图片和光流,但之后我们要在解压后放到一个文件夹中去。
# 创建数据集的指令和代码,因为飞椅数据集较大,我分两部分上传:ppm和flow部分,ppm文件是视频帧,flow文件是光流
%cd /home/aistudio/
# 创建飞椅数据集所需的文件夹
!mkdir work/datasets
!mkdir work/datasets/FlyingChairs_release
!mkdir work/datasets/FlyingChairs_release/data
# 解压飞椅数据集
!unzip -oq /home/aistudio/data/data152386/ppm.zip -d /home/aistudio/work/datasets/FlyingChairs_release/data/
!unzip -oq /home/aistudio/data/data152386/flow.zip -d /home/aistudio/work/datasets/FlyingChairs_release/data/
from shutil import move
import os
# 检查解压后的文件数量
ppm_files = os.listdir('/home/aistudio/work/datasets/FlyingChairs_release/data/ppm/')
flow_files = os.listdir('/home/aistudio/work/datasets/FlyingChairs_release/data/flow/')
print(f"Number of PPM files: {len(ppm_files)}")
print(f"Number of Flow files: {len(flow_files)}")
# 移动文件
for f in ppm_files:
move(os.path.join('/home/aistudio/work/datasets/FlyingChairs_release/data/ppm/', f),
'/home/aistudio/work/datasets/FlyingChairs_release/data/')
for f in flow_files:
move(os.path.join('/home/aistudio/work/datasets/FlyingChairs_release/data/flow/', f),
'/home/aistudio/work/datasets/FlyingChairs_release/data/')
# 检查文件是否成功移动
final_files = os.listdir('/home/aistudio/work/datasets/FlyingChairs_release/data/')
print(f"Number of files after moving: {len(final_files)}")
# 删除原始文件夹
os.rmdir('/home/aistudio/work/datasets/FlyingChairs_release/data/ppm/')
os.rmdir('/home/aistudio/work/datasets/FlyingChairs_release/data/flow/')
# 打印结果,看是否可以得到except的数字
expected_files = 68616
if len(final_files) == expected_files:
print(f"Success! Got the expected number of files: {expected_files}")
else:
print(f"Warning: The number of files may not match the expected count.")
这个运行要花很长时间。但是这也太慢了吧,我都等一个小时了。。。。。。

可算完事了,文件总数是对的。之后我们写一个代码来测试一下dataloader
可以看到没什么问题,下一步就是去干模型了。















 1924
1924











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









