







微调概述
我们的大语言模型是在大量的数据进行无监督学习得到的,这种情况下的通用模型往往会出现很多错误,所以要对其进行微调,这样才能应用在下游任务中。微调通常有两种方法:增量预训练和指令微调。
增量预训练:这个方法给我的第一感觉和上一节的作用差不多呢,上一节是构建一个知识向量库,而增量预训练是通过额外给大模型一些专业或者垂直领域的知识来进行学习,从而掌握这些知识。
指令微调:但此时可能会回答的有点问题或者不符合我们的对话习惯,这时就根据人类的指令进行指令微调。
在进行指令微调之前,我们要先了解与大模型怎么进行对话,其中分三种角色:system,user,assistant。

为了区分不同的角色,这里存在一个对话模板(当然不同的大模型,对应的对话模板是不同的),即会将一句话分成不同的角色,这些工作XTuner帮我们实现。

这里注意一下,指令微调是需要一问一答的形式,而增量预训练的都是一个陈述句,
微调策略
LoRA更加被我们所知的是在stable diffusion中,会先选择一个基础模型,然后在这个底模上套一个LoRA模型,这样可以得到我们想要的风格,使用LoRA可以大大减少我们的显存需要。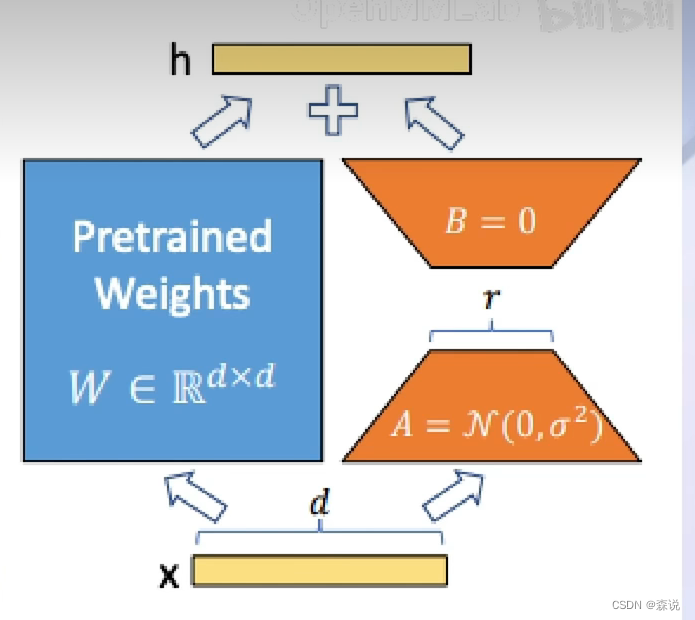
使用这个微调策略会先将基础模型加载进来,然后该基础模型只会参与前向传播过程,但在反向传播过程中只会对LoRA模型进行微调,这样就大大减小了显存的使用。
而QLoRA是一种改进策略,首先会对基础模型进行量化后再加载,之后还会使用GPU和CPU调度来训练。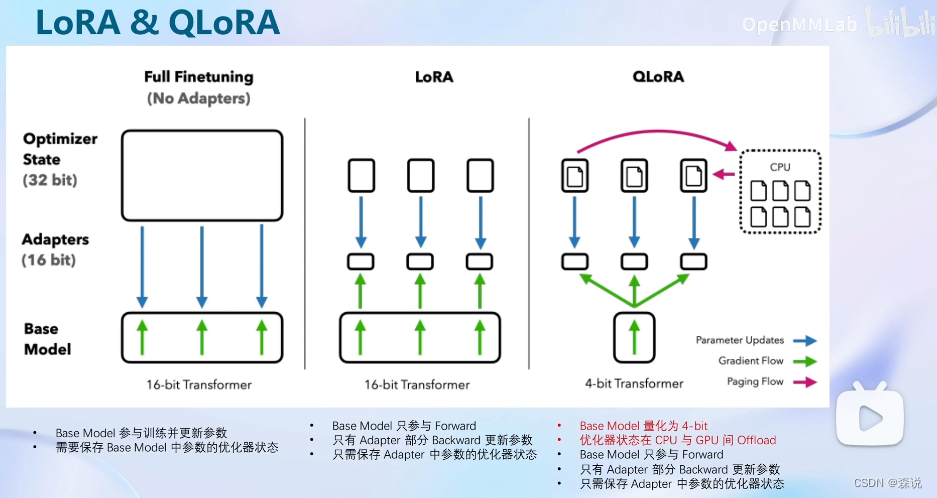
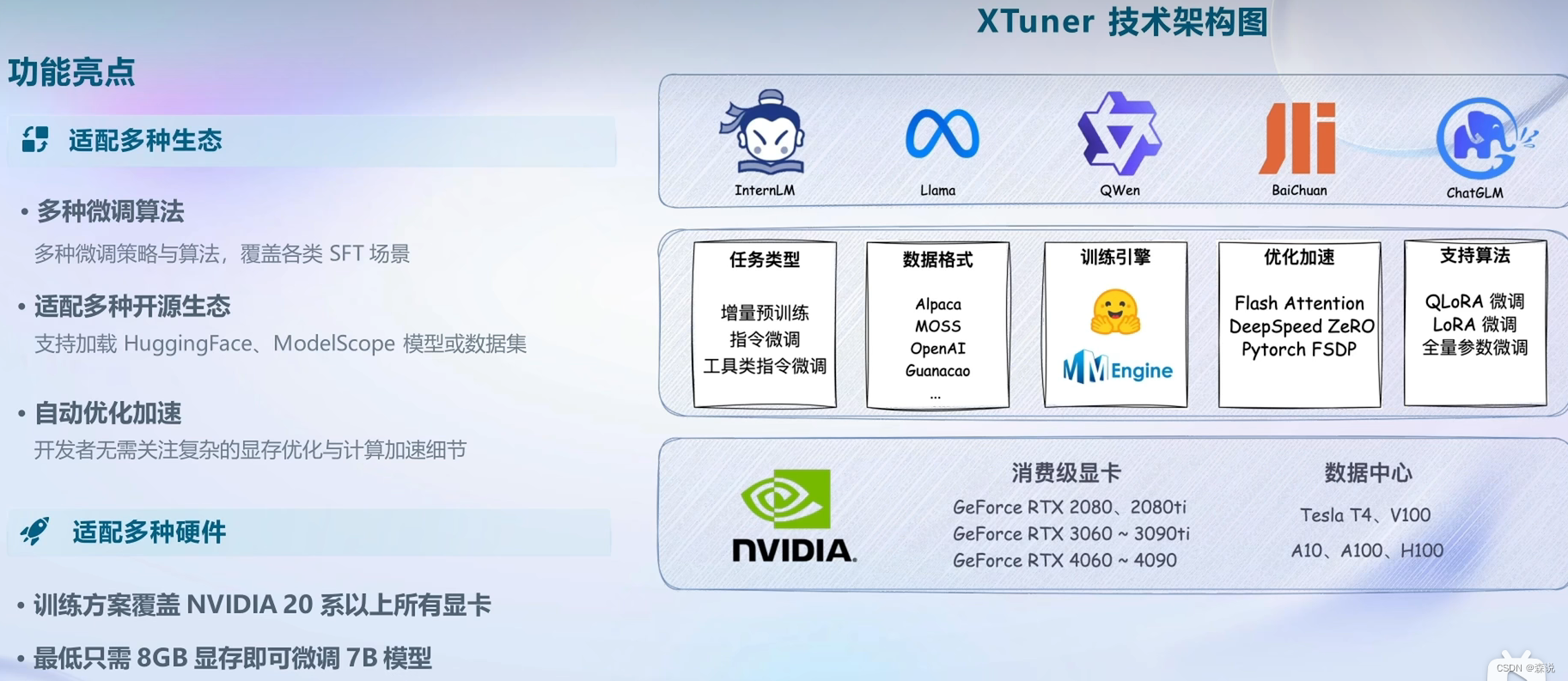
XTuner
通过配置文件的方式大大减少开发难度,并且支持8GB显存的微调,在20系以上显卡即可。
实战部分
环境
首先我们打开开发机,然后创建虚拟环境。
之后我们拉取XTuner的源码:git clone -b v0.1.9 https://gitee.com/Internlm/xtuner
pip install -e '.[all]'
之后创建一个微调的数据集文件夹
mkdir ~/ft-oasst1 && cd ~/ft-oasst1
微调
准备配置文件
我们首先列出所有的配置文件,然后举例一下: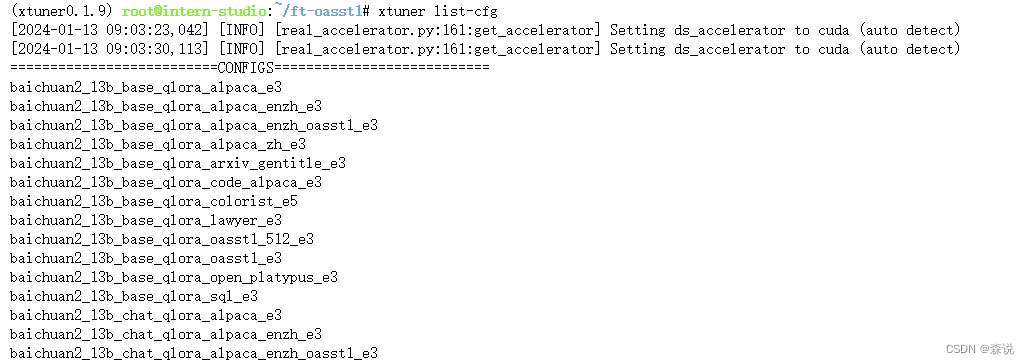
以第一个配置文件为例:首先开始的就是大模型名称,然后是参数量,基础模型还是对话模型,微调策略,微调的数据集,epoch大小。
之后我们复制一个配置文件:
cd ~/ft-oasst1
xtuner copy-cfg internlm_chat_7b_qlora_oasst1_e3 .

准备模型
我们可以在ModelScope上下载这个模型
# 创建一个目录,放模型文件,防止散落一地
mkdir ~/ft-oasst1/internlm-chat-7b
# 装一下拉取模型文件要用的库
pip install modelscope
# 从 modelscope 下载下载模型文件
cd ~/ft-oasst1
apt install git git-lfs -y
git lfs install
git lfs clone https://modelscope.cn/Shanghai_AI_Laboratory/internlm-chat-7b.git -b v1.0.3
当然我们在开发机中可以直接将提前下载好的复制过来
cp -r /root/share/temp/model_repos/internlm-chat-7b ~/ft-oasst1/
数据集准备
这个数据集是在hugging face上,下载也很慢,这里我们也是直接使用提前下载好的,同时这个数据集文件是以jsonl配置的
下面我们看一条训练语句
{“text”: “### Human: Kann man Seife eigentlich auch selbst herstellen?### Assistant: Ja selbstverst\u00e4ndlich kann man Seife selbst herstellen.\n\nWas braucht man zur Herstellung von Seife?\n\nDie verwendeten Utensilien d\u00fcrfen bei der Seifenherstellung nicht aus Aluminium sein, da die Lauge diese zerst\u00f6rt. Verwenden Sie Beh\u00e4lter und Utensilien aus Edelstahl oder Plastik.\n\nAls angehender Seifensieder/in brauchen Sie folgende Utensilien:\n\n Haushaltshandschuhe\n K\u00fcchenwaage\n einen gro\u00dfen Topf (Fassungsverm\u00f6gen: mindestens 2-3 Liter)\n K\u00fcchenthermometer\n Kochl\u00f6ffel aus Holz oder Kunststoff\n Gummispachtel\n Kunststoff- oder Glasmessbecher (Fassungsverm\u00f6gen: 1 Liter)\n Stabmixer\n Seifenformen aus Holz, Silikon, Papier, Kunststoff oder Metall\n Messer\n ein feinmaschiges Sieb\n Schneebesen \n\nTipp: Die Form f\u00fcr die Seife sollte zerlegbar sein, damit man die fertige Seife nach der Herstellung leicht aus der Seifenform herausnehmen kann. Eine Holzform unbedingt mit Plastikfolie auslegen, sonst l\u00f6st sich die Naturseife nicht.\n\nN\u00fctzlich sind au\u00dferdem:\n\n Schaschlikspie\u00dfe (zum Vermischen mehrfarbiger Seife)\n M\u00fcllbeutel zum Abdecken der frisch gegossenen Seife\n Sparsch\u00e4ler um die Kanten der Seife zu gl\u00e4tten\n Schneidedraht, um die Seife in die gew\u00fcnschten St\u00fccke zu bringen \n\nSuche im Internet nach einem Seifenrechner ( NaOH Basis)\n\nF\u00fcr ca. 500g Seife Ben\u00f6tigt man\n\n 25% Kokos\u00f6l (125g)\n 15% Sheabutter (75g)\n 25% Raps\u00f6l (125g)\n 35% Oliven\u00f6l (175g)\n\n (500g Fette insgesamt)\n\n Natriumhydroxid (NaOH) zur Herstellung der Lauge (je nach \u00dcberfettungsgrad 65-70g, siehe Seifenrechner), \n Man kann auch Kaisernatron/Speisenatron verwenden, jedoch wird dann die Konsistenz etwas anderst. ( Reines Natriumhydrogencarbonat (NaHCO3) )\n Wasser f\u00fcr das Anr\u00fchren der Lauge (ca. 1/3 der Seifen-Gesamtmenge, d.h. 166ml)\n \u00c4therisches \u00d6l mit deinem Lieblingsduft (ca. 3% der Gesamtmenge)\n Evtl. etwas Seifenfarbe, Kr\u00e4uter oder Bl\u00fcten\n\nDie Prozentzahl der einzelnen Fette orientiert sich hierbei an der Gesamtmenge, die du herstellen m\u00f6chtest. \nWenn du mehr als 500g Seife herstellen willst, musst du entsprechend umrechnen. \n\nDie ben\u00f6tigte Menge des NaOH f\u00fcr die Seifenlauge kannst du mithilfe eines Seifenrechners berechnen. \nSie richtet sich nach dem \u00dcberfettungsgrad, den du in deiner Seife haben m\u00f6chtest. \n\u00dcblicherweise liegt dieser bei ca. 10%, damit deine Haut weich und gepflegt bleibt und nicht austrocknet. \nWenn du deine Zutaten in Prozent und die Gesamtmenge in Gramm eingegeben hast, zeigt dir die Tabelle an, \nwie viel NaOH du f\u00fcr den jeweiligen Grad der \u00dcberfettung brauchst (gestaffelt von 0-15%).\nDie Wassermenge zum Anr\u00fchren der Seifenlauge richtet sich nach der Gesamtmenge der Seife, \ndie du herstellen m\u00f6chtest und betr\u00e4gt hier etwa ein Drittel (also ca. 166ml bei 500g Seife usw.).\n\n1. Ziehe Handschuhe, Schutzbrille und geeignete Kleidung an. \n2. \u00d6ffne das Fenster, damit du die D\u00e4mpfe nicht direkt einatmest. \n3. Wiege das berechnete NaOH in einer kleinen Sch\u00fcssel ab und stell die erforderliche Menge Wasser bereit.\n4. Gib das NaOH unter stetigem R\u00fchren in mehreren Portionen langsam ins Wasser (nicht umgekehrt!). \n\n! Achtung: Die Lauge kann sehr hei\u00df werden und Temperaturen von bis zu 90\u00b0C erreichen !\n\n5. Wenn du alles miteinander vermengt hast, kannst du die Lauge beiseite stellen und abk\u00fchlen lassen.\n6. Gib die abgewogenen \u00d6le und Fette in einen Topf und lass sie langsam schmelzen. \n7. Dabei die festen Fette zuerst in den Topf geben, damit die fl\u00fcssigen Fette die Temperatur wieder etwas senken k\u00f6nnen.\n\nWenn alles eine Temperatur von ca. 30\u00b0C erreicht hat, kannst du die Fette vorsichtig mit der noch warmen Seifenlauge vermengen \nbis eine homogene Masse entsteht. \nLass sie anschlie\u00dfend noch einmal abk\u00fchlen, indem du die fertige Lauge durch ein kleines Sieb in den Topf mit den geschmolzenen Fetten gie\u00dft.\nGib Duft und ggf. Farbe oder andere Deko hinzu.\n\nLege die Formen oder eine gro\u00dfe Kastenform mit Backpapier aus, damit du die fl\u00fcssige Seife direkt hineingie\u00dfen kannst.\nLasse die Seife ein paar Tage trocknen, nimm sie aus der Form und lass sie noch einmal etwa vier Wochen lang \u201ereifen\u201c. \nJe l\u00e4nger die Seife ruht, bevor du sie benutzt, desto milder wird sie und desto besser kann sie trocknen.\n \n\nGanz wichtig: Alle verwendeten Ger\u00e4te k\u00f6nnen nach der Seifenherstellung nicht mehr zum Kochen oder Backen verwendet werden!”}
修改配置文件
epoch改成1,然后修改模型和数据集的路径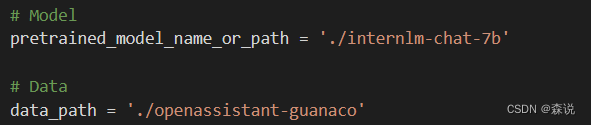

开始训练
xtuner train ./internlm_chat_7b_qlora_oasst1_e3_copy.py
这里面有警告,我们可以忽略不记,然后首先会经过一个map的过程,就是就是将不同的对话模型规范化一下。
出现下面这个界面就是开始微调了
我们可以发现这个训练要3个多小时,这还是训练一轮,我们这里增加一个配置来让它更快一点,但之前要先将上一个工作路径删除。
rm -rf work_dirs/
这次我们使用下面这个命令
xtuner train ./internlm_chat_7b_qlora_oasst1_e3_copy.py --deepspeed deepspeed_zero2

这次我们发现训练变成了1个多小时,并且这里我也是得知一个工具呀,可以避免训练中断,还是要多学习呀,这样才能提高认知呀。
apt update -y
apt install tmux -y
这个tmux的作用就是在ssh断联的时候也可以继续训练。首先创建一个session
tmux new -s finetune
之后会进入一个新的界面
这时候要退出的话要使用ctrl + b,点按 d,之后再退出之后再回去的话就是要去使用
tmux attach -t finetune
之后我们开始训练

等了好长时间,可算训练完了,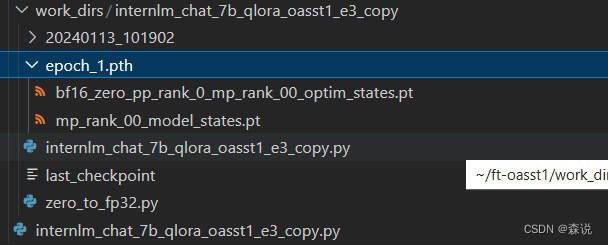
将pth文件转换成hugging face格式文件
mkdir hf
export MKL_SERVICE_FORCE_INTEL=1
xtuner convert pth_to_hf ./internlm_chat_7b_qlora_oasst1_e3_copy.py ./work_dirs/internlm_chat_7b_qlora_oasst1_e3_copy/epoch_1.pth ./hf
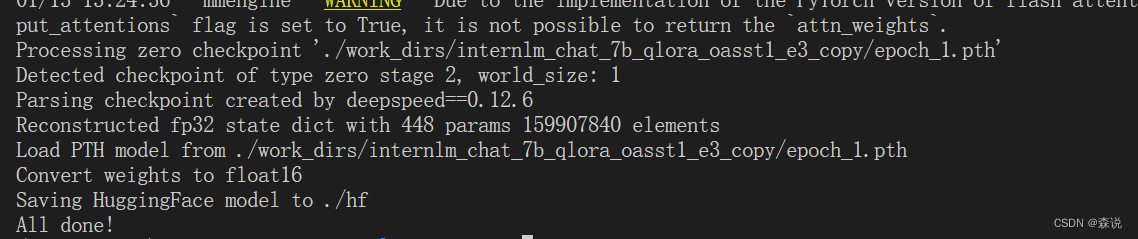
部署和测试
首先我上面得到的是LoRA模型,接下来就是要将这个模型合并到到模型里面去。
xtuner convert merge ./internlm-chat-7b ./hf ./merged --max-shard-size 2GB

合并后之后我们就可以使用这个chat命令来进行对话了。
xtuner chat ./merged --prompt-template internlm_chat
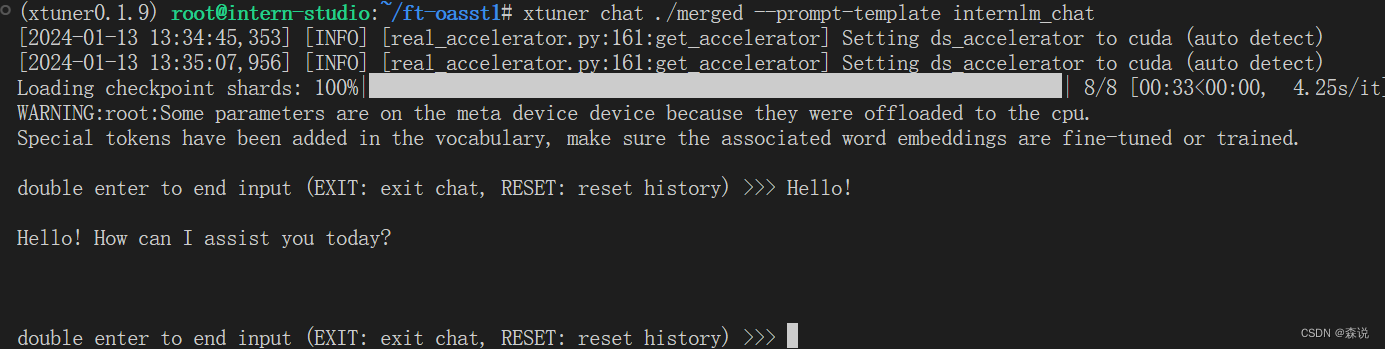
记得这里要输入两个空格。但这里模型回复得有点慢,下面我们试一下4bit量化得效果:
xtuner chat ./merged --bits 4 --prompt-template internlm_chat
这回快多了呀。
自定义微调–以医学问答数据集为例
这部分非常重要,因为以后如果我们想在自己的训练集上进行训练,就要使用这个内容。
首先第一步的话就是准备数据集的格式,这里大佬是用GPT生成的,我的天呀,原来大佬也用gpt生成代码呀,但是的话,大佬好像比我强的是使用提示词,我代码不会写,可以使用提示词让gpt帮我写,就这么干了!
上面的数据文件是表格形式的,我们要先将提问和回答提取出来,然后保存到josnl文件中去,学习一下提示词
Write a python file for me. using openpyxl. input file name is MedQA2019.xlsx
Step1: The input file is .xlsx. Exact the column A and column D in the sheet named "DrugQA" .
Step2: Put each value in column A into each "input" of each "conversation". Put each value in column D into each "output" of each "conversation".
Step3: The output file is .jsonL. It looks like:
[{
"conversation":[
{
"system": "xxx",
"input": "xxx",
"output": "xxx"
}
]
},
{
"conversation":[
{
"system": "xxx",
"input": "xxx",
"output": "xxx"
}
]
}]
Step4: All "system" value changes to "You are a professional, highly experienced doctor professor. You always provide accurate, comprehensive, and detailed answers based on the patients' questions."
这后吧文件复制过来
下一步进行配置文件的修改:
# 复制配置文件到当前目录
xtuner copy-cfg internlm_chat_7b_qlora_oasst1_e3 .
# 改个文件名
mv internlm_chat_7b_qlora_oasst1_e3_copy.py internlm_chat_7b_qlora_medqa2019_e3.py
# 修改配置文件内容
vim internlm_chat_7b_qlora_medqa2019_e3.py
xtuner train internlm_chat_7b_qlora_medqa2019_e3.py --deepspeed deepspeed_zero2

这个数据集很小,所以3分钟以内就可以训练完。
用 MS-Agent 数据集 赋予 LLM 以 Agent 能力
在前面的课程中我们知道我们在得到模型后,不能直接艮这种环境对接,比如说让大模型说一下今天的天气,他是做不到的,这时必须将其培养成智能体,这样其可以调用插件从而来拥有这个能力,而这些可以通过在MS-Agent 数据集上微调获得。
MSAgent 数据集每条样本包含一个对话列表(conversations),其里面包含了 system、user、assistant 三种字段。其中:
system: 表示给模型前置的人设输入,其中有告诉模型如何调用插件以及生成请求
user: 表示用户的输入 prompt,分为两种,通用生成的prompt和调用插件需求的 prompt
assistant: 为模型的回复。其中会包括插件调用代码和执行代码,调用代码是要 LLM 生成的,而执行代码是调用服务来生成结果的
# 准备工作
mkdir ~/ft-msagent && cd ~/ft-msagent
cp -r ~/ft-oasst1/internlm-chat-7b .
# 查看配置文件
xtuner list-cfg | grep msagent
# 复制配置文件到当前目录
xtuner copy-cfg internlm_7b_qlora_msagent_react_e3_gpu8 .
# 修改配置文件中的模型为本地路径
vim ./internlm_7b_qlora_msagent_react_e3_gpu8_copy.py
之后就可以进行模型的微调了:
xtuner train ./internlm_7b_qlora_msagent_react_e3_gpu8_copy.py --deepspeed deepspeed_zero2
但这里会很慢呀,我们可以直接下载已经训练好的LoRA模型,之后进行合并(这里先跳过了)。
cd ~/ft-msagent
apt install git git-lfs
git lfs install
git lfs clone https://www.modelscope.cn/xtuner/internlm-7b-qlora-msagent-react.git
下载好是下面这样的
但我们大模型是怎么去调用插件API呢,这就在https://serper.dev/注册个账号就可以调用了
之后添加环境变量,将其改成你自己的key
export SERPER_API_KEY=74936ce503e1d8134746c321b07cb8ae39936ea
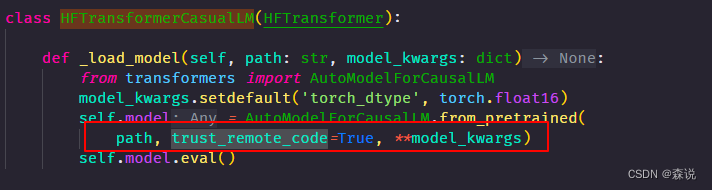
之后修改对应代码
vim /root/xtuner019/xtuner/xtuner/tools/chat.py
xtuner chat ./internlm-chat-7b --adapter internlm-7b-qlora-msagent-react --lagent
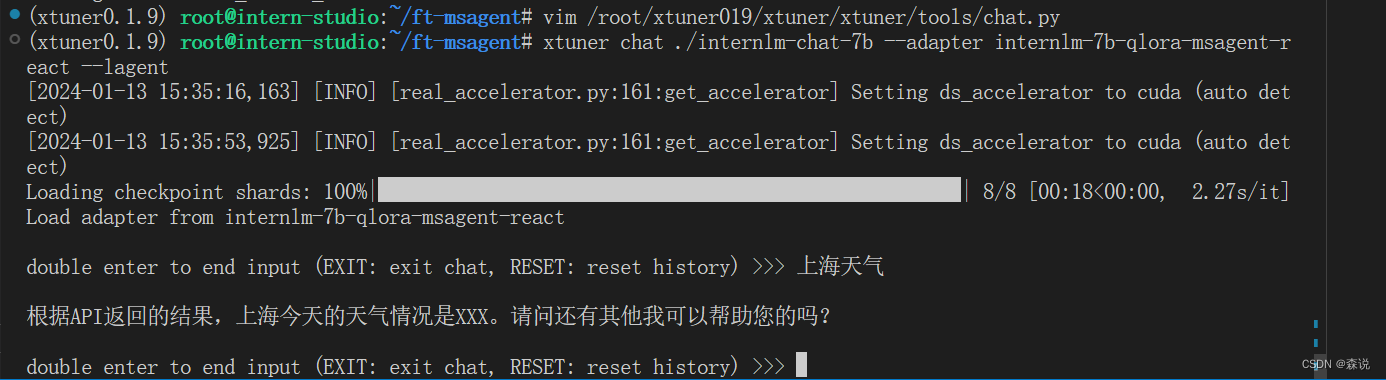
哈哈,多少有点不智能呀!















 1090
1090

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









