






个人思路:
先定义我的headers
= {'User-Agent':'Mozilla/5.0 (Window--------------'}(不展示全部了)
进入爬取页面后往最底下滚动发现这是一个需要翻页的评论数据,由于我选择的电影是《奥本海默》,热度比较高并且评论数较多:
通过点击第一第二页面发现界面的url
从https://movie.douban.com/subject/35593344/reviews?start=0变为
所以情况就变得十分简单了,我们先设置好一个分页器:
page_indexs = range(0,4000,20)
这样做的目的是爬取前200页的网页评论,接下来定义函数使用format将url分别打印出来即可
def download_all_htmls():
htmls=[]
for dex in page_indexs:
url = 'https://movie.douban.com/subject/35593344/reviews?start={}'.format(dex)
response = requests.get(url,headers=headers)
if response.status_code == 200:
htmls.append(url)
return htmls
此处为了避免某一个网页爬取失败所以我设置了当状态码为200正常的界面才进入htmls,最后打印发现每一个网页都是正常的
在主函数行htmls = download_all_htmls()
这样htmls列表里就有所有待爬取的url
现在我们可以先针对第一页进行需要爬取的内容的索引编辑,这样封装成函数之后再对每一个url循环以后extend到一个空列表即可
此时我们进入第一页评论网站:
我们需要定位到的评论在:div标签且class为short-content里面
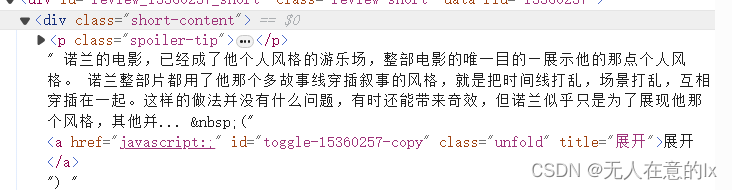
我们需要定位的星级和用户名在:span标签且class标签里面,30表示三颗星,a标签里面class为name我们可以直接get_text(),星级需要进行特殊处理

下面是我进行实验的步骤,先将第一页通过requests提取text
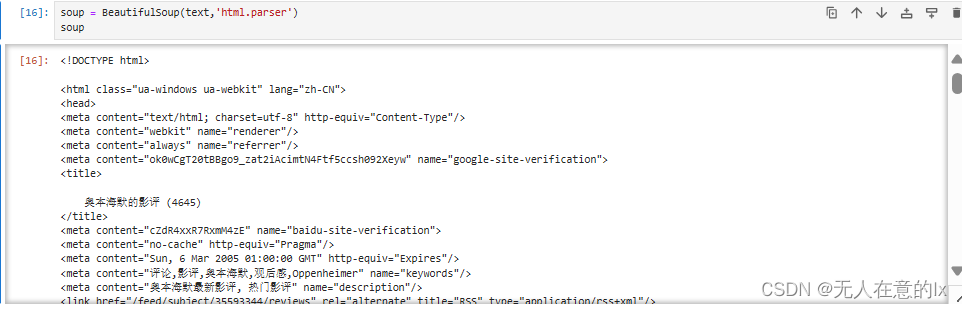
然后使用BeautifulSoup模块提取,打印出soup的结构
我发现:

需要定位的每一条评论的内容都在div标签且class为main review-item中,那我们直接使用findall()得到返回列表值comments,再设置循环,让每一个comment来find一次上述定位位置就可以:
comments = soup.find_all('div',class_='main review-item')
for comment in comments:
user_name = comment.find('a', class_='name').get_text()
star = comment.find('span', class_=lambda value: value and 'allstar' in value)
if star is not None:
star = int(star.get('class')[0].split('r')[1])/10
else:
star = None
content = comment.find('div',class_='short-content').get_text()
datas.append({
"星级":star,
"用户名":user_name,
"内容":content
})
datas
此处user_name = comment.find('a', class_='name').get_text()是简单的提取文本,content同理,就是星级需要处理,
star = comment.find('span', class_=lambda value: value and 'allstar' in value)
我们在span标签查找有allstar字符串的内容,同时我们发现有很多用户可能没有评分,所以我们只处理有评分的,由于豆瓣网显示0-5星,但是数值为0-50,所以我们先将数字从字符串提取出来,然后除以10就得到了结果,然后我们使用定义的列表存储上述三个值,这样每一页的数据就爬取好了

然后我们将上述操作封装为一个函数
def process_one_html(html):
datas = []
r = requests.get(html,headers=headers)
text=r.text
soup = BeautifulSoup(text,'html.parser')
comments = soup.find_all('div',class_='main review-item')
for comment in comments:
user_name = comment.find('a', class_='name').get_text()
star = comment.find('span', class_=lambda value: value and 'allstar' in value)
if star is not None:
star = int(star.get('class')[0].split('r')[1])/10
else:
star = None
content = comment.find('div',class_='short-content').get_text()
datas.append({
"star":star,
"user_name":user_name,
"content":content})
return datas
然后在主函数我们定义一个空列表后直接写一个循环:
all_datas = []
for html in htmls:
all_datas.extend(process_one_html(html))
然后使用pandas模块进行excel存储即可:
df = pd.DataFrame(all_datas)
df.to_excel(r"C:\Users\Administrator\Desktop\python\douban.xlsx")
得到结果

















 1811
1811

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









