







好久没有爬虫了,今天突然叫爬豆瓣,有点懵了,不过看了看以前爬的,一葫芦画瓢整了一个这个。bs4和requests yyds!
分析一波
爬取的地址:https://movie.douban.com/subject/26588308/comments
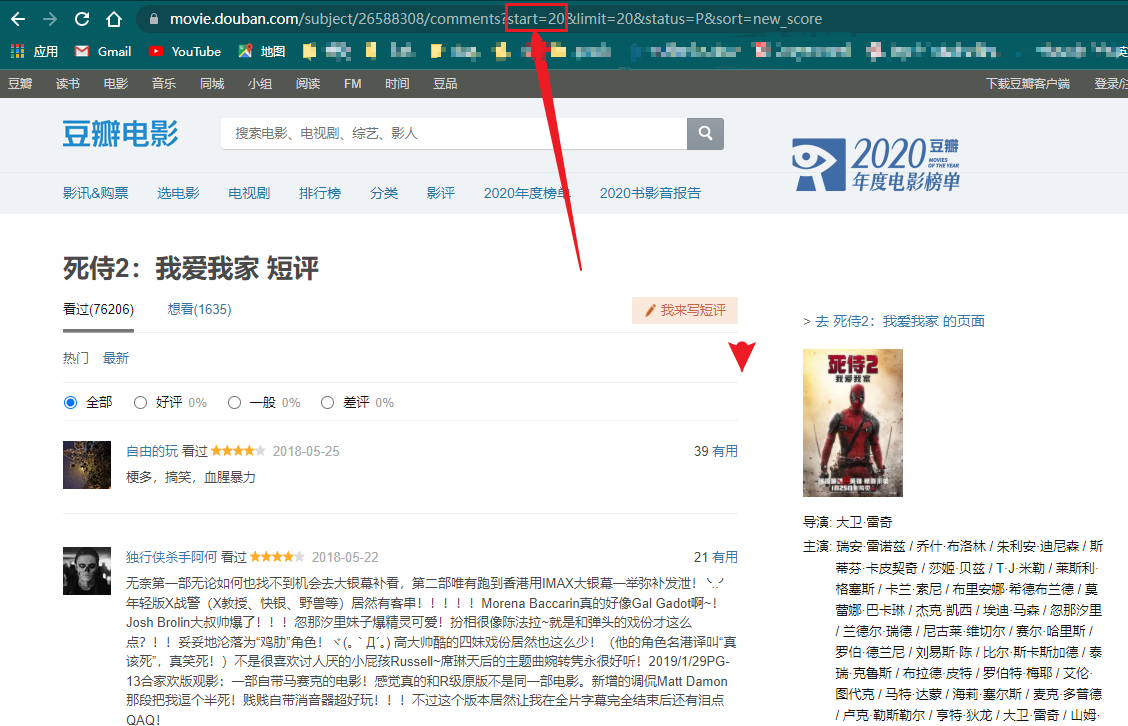
- 每次翻页可以看到只和start有关,一页展示20条评论
- 下图是第二页的url,故第一页的start就是0
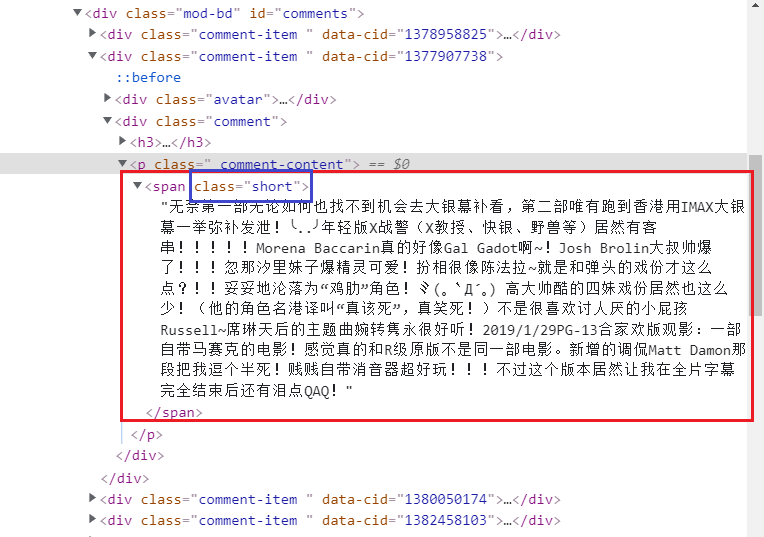
- 评论在span标签里面(class属性为short)
代码
import urllib.request
from bs4 import BeautifulSoup
import time
absolute = "https://movie.douban.com/subject/26588308/comments"
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.71 Safari/537.36',
}
comment_list = []
#解析html
def get_data(html):
soup  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 2486
2486











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









