 Linux网络服务与Shell脚本编程详解
Linux网络服务与Shell脚本编程详解




文档信息
| 文档类别 | 正式文档 |
|---|---|
| 文档名称 | linux系统初级课 |
| 版本 | 1.2-lxx–002 |
| 编写负责人/编写时间 | 李秀秀/2023年2月20日 |
| 审核负责人/审核时间 | 年 月 日 |
| 批准人/批准时间 | 年 月 日 |
文档保密
本文档为西安鸥鹏互联科技有限公司保密文档,为西安鸥鹏所属资产,文档传播仅限于西安鸥鹏云原生部门内部,任何人不能在未经授权的情况私自外传,责任人包括离职人员与实习人员,正式入职人员,一经发现西安鸥鹏有权追究其法律责任。
变更记录----------------------------
1. 1.0为主干版本号。云原生部门所有人必须以主干版本为基础输出授课的标准分支版本。分支版本命名格式为主干版本加讲师名字英文缩写,如王挺伟授课版本为1.0-wtw-001表示王挺伟的授课第一版。分支版本需要和主干版本的知识点,内容比重相吻合,如需添加、删除知识点,上报部门主管,经讨论审核后修正主干版本号。
2. 云原生部门全体讲师可以修订知识点内容,最好是授课口吻的修订,包括讲解思路,例子,逻辑,欢迎部门全体讲师输出优质的修订版本。修订记录需要填入下边表格。
| 日期 | 版本号 | 变更内容 | 修订者 |
|---|---|---|---|
| 2024年10月9日 | 1.2-lxx-002 |
授课时间明细
第一部分:网络服务
| 章 节 | 章节名称 | 内容介绍 | 时间分配(天) |
|---|---|---|---|
| 第零章 | 准备工作 | 1.linux环境部署 | 0.5 |
| 第一章 | 例行性工作 | 1、单一执行的例行性工作 2、循环执行的例行性工作 | 0.5 |
| 第二章 | 时间服务器 | 1、软件安装 2、配置时间服务器客户端 3、配置时间服务器服务端 | 0.5 |
| 第三章 | 远程连接服务器 | 1、远程连接服务器简介 2、连接加密技术简介 3、ssh服务配置 4、用户登录ssh服务器 | 0.5 |
| 第四章 | web服务器 | 1、web服务器简介 2、web服务器的类型 3、web服务器基本配置 4、虚拟主机配置实战 | 2 |
| 第五章 | nfs服务器 | 1、简介 2、nfs配置 3、配置autofs自动挂载 | 0.5 |
| 第六章 | DNS域名解析服务器 | 1、DNS简介 2、DNS域名解析的过程 3、DNS服务器配置 | 1 |
| 第七章 | selinux | 1、selinux的说明 2、selinux的工作原理 3、selinux的启动、关闭与查看 4、selinux对linux服务的影响 | 0.5 |
| 第八章 | 防火墙 | 1、什么是防火墙 2、iptables 3、firewalld | 0.5 |
| 第九章 | Ubuntu系统 | 1、什么是Ubuntu系统 2、安装部署Ubuntu系统 3、Ubuntu系统的网络配置 4、Ubuntu系统的软件包安装 | 0.5 |
| 第十章 | mysql安装部署 | 1、二进制安装部署mysql 2、源码安装mysql数据库 | 0.5 |
| 答疑 | 答疑 | 根据第一部分的linux中的网络服务部分进行答疑 | 0.5 |
第二部分:shell脚本编程
| 章节 | 章节名称 | 内容介绍 | 时间分配 |
|---|---|---|---|
| 第一章 | shell基本知识 | 1、为什么学习和使用shell编程 2、什么是shell 3、shell的分类 4、作为程序设计的语言——shell 5、如何学好shell 6、shell脚本的书写规范 7、shell脚本的执行方式 8、执行脚本的方法 9、shell脚本的退出状态码 | 0.5 |
| 第二章 | shell的变量 | 1、什么是变量 2、变量的命名 3、查看单个变量的值 4、变量的定义 5、变量的分类 6、取消变量 7、变量的运算 | 0.5 |
| 第三章 | shell条件测试 | 1、条件测试的基本语法 2、文件测试表达式 3、字符串测试表达式 4、整数测试表达式 5、逻辑操作符 | 0.5 |
| 第四章 | 流程控制之条件判断 | 1、if单分支结构 2、if双分支结构 3、if多分支结构 4、多条件判断语句case | 0.5 |
| 第五章 | 流程控制之循环 | 1、for循环 2、while循环 3、until循环 4、退出循环和程序 | 0.5 |
| 第六章 | 文本搜索工具——grep | 1、grep工具的使用 | 0.5 |
| 第七章 | 正则表达式 | 1、基本正则表达式 2、扩展正则表达式 | 0.5 |
| 第八章 | shell编程之sed | 1、sed工作原理 2、sed基本语法 3、模式空间中的编辑操作 | 0.5 |
| 第九章 | shell编程之awk | 1、什么是awk 2、awk的工作流程 3、awk的基本语法 | 1 |
| 答疑 | 答疑 | 根据第二部分shell脚本编程部分进行答疑 | 0.5 |
授课要求
1. 白天课9:15讲师必须进教室开始每日一讲,早上9:30必需开始正式讲课,12:00结束,下午1:45必须进入教室,下午2:00准时开始授课,5:00结束。当天讲课内容当天完,所有讲师不得讲当天授课内容延迟至其他日期,讲不完的可以拖堂处理。如遇特殊情况需要延迟至其他日期的需报教学主管审批,原则上新人讲师将适当放宽此条件。晚上或者下午课也是提前15分进入教室,规则如上。
2. 上课的演示环境必须提前配置好,网络初级课适当放宽此要求,HCIP等课程需要提前配置好环境与IP地址等,严禁配置实验环境占用大量授课时间,占用大量时间者安教学事故处理。
3. 白天课上午休息一次,时长为15分钟,下午休息一次时长为15分钟。原则上上午休息时间在10:30到11:00之间,下午休息时间在3:00-3:30之间。严禁过长休息,休息时长超23分钟者并且不能说明必要性的按照教学事故处理。晚上课或者下午课,中间休息10分钟,应该在授课后80-110分钟之间,休息时长超过17分钟者为过长。
4. 白天课下午结束后,预留10-20分钟时间让学员完成当天思维导图总结的填空,学员提交后方可离开,期间讲师需将当天录屏上传至公司小鹅通的课程专栏,并上传课后作业。晚上或者下午课执行相同标准。
5. 讲师授课需重点清晰,时间分配也需在重点知识上多花时间,非重点少花时间,合理分配授课时间。
6. 讲师讲授重点、难理解的知识点,需要举例,举例要求贴近生活浅显易懂,清晰明了,有条件的建议画图说明,也上需要体现在个人的授课文档版本中,作为讲师优质课评选的重要依据。
7. 讲师讲授课程内容,需梳理出良好的知识授课逻辑做到逻辑清晰,层层递进,需要体现在个人的授课文档版本中,此项也是讲师优质课评选的重要依据 。
8. 讲师授课中需保持放松状态,以平等的态度对待学生,侃侃而谈而不是居高临下,娓娓道来而不是强行灌输。此项内容会通过录屏抽查以及问卷反馈作为讲师优质课评选的重要依据。
授课前2天资料分享
讲师被拉入初级课必须分享如下资料至群中。
Linux 需要用到的软件
链接:https://pan.xunlei.com/s/VNFDfdt40Xb72E0LMZgO2guOA1#
提取码:fzud
链接:https://pan.baidu.com/s/1CrwEZq1oYVrwFBawNvaHHw
提取码:rhel
授课讲师自我介绍
自我介绍在开课第一天必须进行,如果顾问在场则由顾问介绍。
授课讲师宣读授课注意事项
0. 提前15分钟进入课堂。 ---守时是一种美德,更是一种良好的工作态度与习惯
1. 课堂中可以随时提问。 ---思考才是进步的本质
2. 课堂中需参与讲师互动。 ---融入课堂你会学的更轻松,更专注
3. 课后需按时完成作业任务。 ---学而不思则罔,思而不学则殆。古人诚不欺我,作业是这俩句话的最佳实践。
4. 课前分享,上午课前分享-技术类,下午课前分享-自由分享非技术类。 ---好交流分享能力是高薪的开端
5. 注册博客,总结所学。 ---获得大公司青睐的习惯,总结作业每次必交。
准备工作
基本命令 用户管理 权限 rwx u+s g+s o+t
1.vi/vim *
2.nmcli nmtui *
3.fdisk parted --lvm ***
4.rpm ****
yum/dnf/dnf-3
源码安装 ****
#本地源
[root@localhost yum.repos.d]# mount /dev/sr0 /mnt
[root@localhost yum.repos.d]# vim /etc/yum.repos.d/base.repo
[base]
name=base
baseurl=file:///mnt/BaseOS
gpgcheck=0
[app]
name=appstream
baseurl=file:///mnt/AppStream
gpgcheck=0
#yum install lrzsz -y
[root@localhost yum.repos.d]# ll /mnt/AppStream/
total 986
dr-xr-xr-x. 2 root root 1005568 Apr 4 2020 Packages
dr-xr-xr-x. 2 root root 4096 Apr 4 2020 repodata
[root@localhost yum.repos.d]# ll /mnt/BaseOS/
total 296
dr-xr-xr-x. 2 root root 301056 Apr 4 2020 Packages
dr-xr-xr-x. 2 root root 2048 Apr 4 2020 repodata
第一部分 网络服务
第一章 例行性工作(任务计划)
场景:
-
生活中,我们有太多场景需要使用到闹钟,比如早上 7 点起床,下午 4 点开会,晚上 8 点购物,等等。
-
在 Linux 系统里,我们同样也有类似的需求。比如我们想在凌晨 1 点将文件上传服务器,或者在晚上 10 点确认系统状态,等等。
-
但我们不可能一直守在电脑前,毕竟我们也需要下班/睡觉,还要陪女朋友(new一个也行)。而且即使在上班期间,如果到点了还需要人工操作,未免效率太低了。
-
at命令就是为这个需求而诞生的。使用at命令,你可以在特定时间自动完成你所设定的任务,也可以实现自动化,非常方便快捷!
1、单一执行的例行性工作
**单一执行的例行性工作:**仅处理执行一次就结束了
1.1 at配置文件
-
/etc/at.allow,写在该文件的人可以使用at命令
-
/etc/at.deny,黑名单
-
两个文件如果都不存在,只有root能使用
#at工作调度对应的系统服务
[root@localhost ~]# ps -ef | grep at
[root@localhost ~]# systemctl status atd
#at的工作文件存放目录
[root@localhost ~]# ll /var/spool/at
#at工作的日志文件
[root@localhost ~]# ll /var/log/cron
at命令执行过程分析
- 第一步:寻找/etc/at.allow (白名单)是否存在,写在该文件中用户才可执行at命令
- 第二步:若/etc/at.allow不存在,则寻找/etc/at.deny(黑名单)文件,写在该文件中的用户不能使用at命令
- 第三步:若两个文件都不存在则只有root用户可以使用at命令
- 注意:若拒绝某用户使用at命令则可以将用户名写入到/etc/at.deny中
1.2 at命令详解
命令格式:at [参数] [时间]
参数:
-V 显示版本
-m 当任务完成之后,即使没有标准输出,将给用户发送邮件
-l atq的别名,可列出目前系统上面的所有该用户的at调度
-d atrm的别名,可以取消一个在at调度中的工作
-v 使用较明显的时间格式,列出at调度中的任务列表
-c 可以列出后面接的该项工作的实际命令内容(脚本)
-f 从文件中读取作作业
时间格式:
HH:MM 在今天的HH小时MM分钟执行,如果今天的这个时间点已经过了,则明
天执行
HH:MM YYYY-MM-DD 强制规定在某年某月的某一天的特殊时刻进行该工作 MMDDYY
now + 2 minutes 从现在开始几分钟minutes, hours, days, or weeks
#定义三分钟之后显示hello
[root@server ~]# at now + 3 minutes
2、循环执行的例行性工作crond
- crond 是 Linux 下用来周期地执行某种任务或等待处理某些事件的一个守护进程,在安装完成操作系统后,默认会安装 crond 服务工具,且 crond 服务默认就是自启动的,若需要安装则执行如下命令:
[root@server ~]# yum install crontabs # 安装,注意包名
[root@server ~]# systemctl status crond # 查看状态
-
crond 进程每分钟会定期检查是否有要执行的任务,如果有,则会自动执行该任务,crontab 命令需要 crond 服务支持
-
linux 任务调度的工作主要分为以下两类:
- 系统执行的工作**:**系统周期性所要执行的工作,如备份系统数据、清理缓存
- 个人执行的工作:某个用户定期要做的工作,例如每隔 10 分钟检查邮件服务器是否有新信,这些工作可由每个用户自行设置
2.1 crontab的工作过程
- 当系统中有 /etc/cron.allow 文件时,只有写入此文件的用户可以使用 crontab 命令,没有写入的用户不能使用 crontab 命令。同样,如果有此文件,/etc/cron.deny 文件会被忽略,因为 /etc/cron.allow 文件的优先级更高
- 当系统中只有 /etc/cron.deny 文件时,写入此文件的用户不能使用 crontab 命令,没有写入文件的用户可以使用 crontab 命令
- 两个文件如果都不存在,只有root能使用
- crontab 执行的每一项工作都会被 记录到 /var/log/cron 这个日志文件中
- 当用户使用 crontab 新建工作之后,该项工作就会被记录到 /var/spool/cron/目录里面
#crontab工作调度对应的系统服务
[root@localhost ~]# systemctl status crond
#crontab工作的日志文件
[root@localhost ~]# ll /var/log/cron
#用户定义计划任务的文件所在目录
[root@localhost ~]# ll /var/spool/cron/
2.2 crontab命令详解
crontab [-u user] [-l| -r | -e]
执行crontab 命令就是在修改
/var/spool/cron中的定时任务文件。
循环执行的例行性工作:每隔一定的周期就需要执行一次
[root@localhost ~]# crontab --help
crontab: invalid option -- '-'
crontab: usage error: unrecognized option
Usage:
crontab [options] file
crontab [options]
crontab -n [hostname]
Options:
-u <user> define user
-e edit user's crontab
-l list user's crontab
-r delete user's crontab (清空)
-i prompt before deleting
-n <host> set host in cluster to run users' crontabs
-c get host in cluster to run users' crontabs
-s selinux context
-V print version and exit
-x <mask> enable debugging
crontab计划任务的时间格式:
| 分 | 时 | 日 | 月 | 周 |
|---|---|---|---|---|
| 0-59 | 0-23 | 1-31 | 1-12 | 0-7 0/7 |
date 月日时分年.秒
crontab计划任务的时间格式中的特殊符号:
| 特殊字符 | 含义 |
|---|---|
| * | 代表任何时刻 |
| , | 代表分隔时段 |
| - 0-59 | 代表一段时间范围 |
| /数字 | 指定时间的间隔频率,例如每 3 分钟进行一次,*/3 |
注:%在crontab里面有特殊含义,如果有命令里面需要使用%,需要使用\转义。
#每天早上9点整说good morning
[root@server ~]# crontab -e
0 9 * * * wall "good morning"
注:wall命令用于向系统当前所有打开的终端上输出信息。
通过wall命令可将信息发送给每位同意接收公众信息的终端机用户,若不给予其信息内容,则wall命令会从标准输入设备读取数据,然后再把所得到的数据传送给所有终端机用户。
定时邮件发送任务:
-
设置邮件发送告警功能,每1分钟发送一封邮件
-
安装邮件服务
[root@server ~]# yum install s-nail -y
- 配置邮件服务
[root@server ~]# vim /etc/mail.rc
# 最后一行添加以下内容:
set from=lxx1xxxxxxxxxxx@163.com
set smtp=smtp.163.com
set smtp-auth-user=lxx1065372838@163.com
set smtp-auth-password=HUaxxxxxxxxxxxxxxx
set smtp-auth=login
# 注意:该文件输入完毕有的系统需要强制保存退出,输入wq!
- 测试邮件服务
[root@server ~]# echo 123 | mail -s "123" lxx1xxxxxxxx@163.com
- 设置定时任务
[root@server ~]# crontab -e
MAILTO=lxx1065372838@163.com
* * * * * echo "警告" | mail -v -s "test " lxx1xxxxxxx@163.com
书写定时任务的注意事项
- 6 个字段都不能为空,如果不确定则使用*表示任意时间
- crontab命令任务的最小时间单位为分钟,最大有效时间为月,如:2024年某时执行、3点30分30秒这样的时间日期无法被识别
- 定义时间时,日期和星期最好不要一起出现,由于都是以天为单位,非常让管理员混淆
- 在定时任务中不能,不管是写命令还是在脚本中写命令,最好都用绝对路径,相对路径有时会报错
2.3 系统的计划任务(对系统所有用户都生效的任务文件)
[root@localhost ~]# cat /etc/crontab
SHELL=/bin/bash
PATH=/sbin:/bin:/usr/sbin:/usr/bin
MAILTO=root
# For details see man 4 crontabs
# Example of job definition:
# .---------------- minute (0 - 59)
# | .------------- hour (0 - 23)
# | | .---------- day of month (1 - 31)
# | | | .------- month (1 - 12) OR jan,feb,mar,apr ...
# | | | | .---- day of week (0 - 6) (Sunday=0 or 7) OR sun,mon,tue,wed,thu,fri,sat
# | | | | |
# * * * * * user-name command to be executed
当需要同一时间执行多个脚本时,可以将这多个脚本放在一个目录下,然后使用run-parts来执行。
run-parts:该命令可将后面接的“目录”内的所有文件找出来执行。
可唤醒停机期间的工作任务
anacron 可以处理关机状态时未执行的计划任务,anacron不能指定何时执行某项任务,而是以天为单位或是在开机后立刻进入anacron的操作(/etc/anacrontab)。它会去检测停机期间应该进行但是并没有进行的crontab任务,并将该任务执行一遍,然后anacron就会自动停止了
课堂练习:
实验一:定义三分钟之后显示hello
at now + 3 minutes
at>wall hello
实验二 : 每天早上9点整,说good morning
crontab -e
00 09 * * * wall "good morning"
注释:
- wall命令用于向系统当前所有打开的终端上输出信息。
- 通过wall命令可将信息发送给每位同意接收公众信息的终端机用户,若不给予其信息内容,则wall命令会从标准输入设备读取数据,然后再把所得到的数据传送给所有终端机用户。
实验三:指定某些用户不可以执行计划任务
/etc/at.deny
/etc/cron.deny
实验四:系统级别例行性任务
[root@localhost ~]# vim /etc/crontab
练习
题目:
1. 每分钟执行命令
2. 每小时执行
3. 每天凌晨3点半和12点半执行脚本
30 3,12 * * * /usr/bin/bash a.sh
4. 每隔6小时,相当于6,12,18,24点半执行脚本
5. 30代表半点,8-18/2表示早上8点到下午18点之间每隔2小时执行脚本
6. 每天晚上9点30重启nginx
7. 每月1和10号凌晨4点45执行脚本
8. 每周六和周日凌晨1点10分执行命令
9. 每天18点到23点之间,且每隔30分钟执行一次
10. 每隔一小时执行一次
11. 在4月份的周一到周三的上午11点执行脚本
12. 每天早上7点到上午11点且每2小时执行一次
13. 每天6点执行脚本
14. 每周六凌晨4点执行
15. 每周六凌晨4点05执行
16. 每天8:40执行
17. 在每天10:31且每隔2小时执行一次
18. 每周一到周五2:00执行
19. 每周一到周五8:00和9:00执行
20. 每天10:00,16:00执行
答案:
1. */1 * * * * cmd
2. 0 * * * * cmd
3. 30 3,12 * * * cmd
4. 30 */6 * * * cmd
5. 30 8-18/2 * * * cmd
6. 30 21 * * * /usr/bin/systemctl restart nginx
7. 45 4 1,10 * * cmd
8. 10 1 * * 6,0 cmd
9. 0,30 18-23 * * * cmd 或 */30 18-23 * * * cmd
10. 0 */1 * * * cmd 或 0 * * * * cmd
11. 0 11 * 4 1-3 cmd
12. 0 7-11/2 * * * cmd
13. 0 6 * * * cmd
14. 0 4 * * 6 cmd
15. 5 4 * * 6 cmd
16. 40 8 * * * cmd
17. 31 10/2 * * * cmd
18. 0 2 * * 1-5 cmd
19. 0 8,9 * * 1-5 cmd
20. 0 10,16 * * * cmd
第二章 时间服务器
服务:是运行在操作系统后台的一个或多个程序,为用户或系统提供某项特定的服务。服务配置最多的是网络服务,网络服务通常就是为其他用户,其他计算机提供某项功能服务。
简介
重要性
- 由于IT系统中,准确的计时非常重要,有很多种原因需要准确计时:
- 在网络传输中,数据包括和日志需要准确的时间戳
- 各种应用程序中,如订单信息,交易信息等 都需要准确的时间戳
Linux的两个时钟
- 硬件时钟RTC (Real Time Clock):即BIOS时钟,也就是我们主板中用电池供电的时钟,是将时间写入到BIOS中,系统断电后时间不会丢失,可以在开机时通过主板程序中进行设置
# 查看硬件时间
[root@server ~]# hwclock
2023-05-30 09:48:32.535594+08:00
- 系统时钟 (System Clock) :顾名思义也就是Linux系统内核时钟、软件时钟,是由Linux内核来提供的,系统时钟是基于内存,如果系统断电时间就会丢失**
# 查看系统时间
[root@server ~]# date
2023年 05月 30日 星期二 09:50:50 CST
[root@server ~]# date -s 10:00 # 修改为错误的时间
2023年 05月 30日 星期二 10:00:00 CST
[root@server ~]# date
2023年 05月 30日 星期二 10:00:01 CST
[root@server ~]# hwclock -s # 向硬件时间同步
[root@server ~]# date
2023年 05月 30日 星期二 09:51:50 CST
date命令设置
[root@server ~]# date # 显示
[root@server ~]# date +"%Y-%m-%d %H:%M:%S" # 格式显示
# 设置日期时间
[root@server ~]# date -s 2023-11-15
2023年 11月 15日 星期三 00:00:00 CST
[root@server ~]# date -s 14:33:33
2023年 11月 15日 星期三 14:33:33 CST
[root@server ~]# date
2023年 11月 15日 星期三 14:33:34 CST
- 注意:以便于以后的实验正常执行,可恢复快照后继续
设置日期时间
timedatectl命令设置
# [root@server ~]# timedatectl # 显示当前的日期和时间
Local time: 三 2023-11-15 13:00:26 CST # 本地时间
Universal time: 三 2023-11-15 05:00:26 UTC # 世界时间
RTC time: 三 2023-11-15 06:16:16 # 硬件时间
Time zone: Asia/Shanghai (CST, +0800) # 时区
System clock synchronized: yes # 时间是否已同步
NTP service: active # 时间同步服务已启动
RTC in local TZ: no # no表示硬件时钟设置为协调世界时(UTC),yes表示硬件时钟设置为本地时间
[root@server ~]# systemctl status chronyd # 查看时间同步服务状态(由于默认使用chrony服务同步时间,不再使用ntp服务)
[root@server ~]# timedatectl set-ntp no # 关闭时间同步,以方便修改日期时间
[root@server ~]# systemctl status chronyd
[root@server ~]# timedatectl set-time "2023-12-12" # 设置新日期
[root@server ~]# timedatectl set-time "12:12:12"
[root@server ~]# timedatectl
Local time: 二 2023-12-12 12:12:22 CST
Universal time: 二 2023-12-12 04:12:22 UTC
RTC time: 二 2023-12-12 04:12:23
Time zone: Asia/Shanghai (CST, +0800)
System clock synchronized: no
NTP service: inactive
RTC in local TZ: no
[root@server ~]# timedatectl list-timezones | grep Asia # 查看可用时区
[root@server ~]# timedatectl set-timezone Asia/Shanghai # 设置时区
NTP
- NTP:(Network Time Protocol,网络时间协议)是由RFC 1305定义的时间同步协议,用来在分布式时间服务器和客户端之间进行时间同步。
- NTP基于UDP报文进行传输,使用的UDP端口号为123
- NTP可以对网络内所有具有时钟的设备进行时钟同步,使网络内所有设备的时钟保持一致,从而使设备能够提供基于统一时间的多种应用,对于运行NTP的本地系统,既可以接受来自其他时钟源的同步,又可以作为时钟源同步其他的时钟,并且可以和其他设备互相同步。
- NTP的其精度在局域网内可达0.1ms,在互联网上绝大多数的地方其精度可以达到1-50ms
Chrony介绍
- chrony是一个开源的自由软件,它能帮助你保持系统时钟与时钟服务器(NTP)同步,因此让你的时间保持精确。
- chrony由两个程序组成,分别是chronyd和chronyc
- chronyd:是一个后台运行的守护进程,用于调整内核中运行的系统时钟和时钟服务器同步。它确定计算机增减时间的比率,并对此进行补偿。
- chronyc:提供了一个用户界面,用于监控性能并进行多样化的配置。它可以在chronyd实例控制的计算机上工作,也可以在一台不同的远程计算机上工作
- 注意:Chrony与NTP都是时间同步软件,两个软件不能够同时开启,会出现时间冲突,RHEL8+中默认使用chrony作为时间服务器,不在支持NTP软件包
[root@server ~]# systemctl status ntp # 查看ntp状态
安装与配置
安装:
# 默认已安装,若需要安装则可执行:---可以不做
[root@server ~]# yum install chrony -y
[root@server ~]# systemctl start chronyd
[root@server ~]# systemctl enable chronyd
Chrony配置文件分析
- 主配置文件:/etc/chrony.conf
[root@server ~]# vim /etc/chrony.conf
# 使用 pool.ntp.org 项目中的公共服务器。
# 或者使用server开头的服务器,理论上想添加多少时间服务器都可以
# iburst表示的是首次同步的时候快速同步
pool pool.ntp.org iburst
# 根据实际时间计算出服务器增减时间的比率,然后记录到一个文件中,在系统重启后为系统做出最佳时间 补偿调整。
driftfile /var/lib/chrony/drift
# 如果系统时钟的偏移量大于1秒,则允许系统时钟在前三次更新中步进。
# Allow the system clock to be stepped in the first three updates if its offset is larger than 1 second.
makestep 1.0 3
# 启用实时时钟(RTC)的内核同步。
# Enable kernel synchronization of the real-time clock (RTC).
rtcsync
# 通过使用 hwtimestamp 指令启用硬件时间戳
# Enable hardware timestamping on all interfaces that support it.
#hwtimestamp *
# Increase the minimum number of selectable sources required to adjust the system clock.
#minsources 2
# 指定 NTP 客户端地址,以允许或拒绝连接到扮演时钟服务器的机器
# Allow NTP client access from local network.
#allow 192.168.48.0/24
# Serve time even if not synchronized to a time source.
# local stratum 10
# 指定包含 NTP 身份验证密钥的文件。
# Specify file containing keys for NTP authentication.
# keyfile /etc/chrony.keys
# 指定日志文件的目录。
# Specify directory for log files.
logdir /var/log/chrony
# 选择日志文件要记录的信息。
# Select which information is logged.
# log measurements statistics tracking
同步时间服务器
授时中心
210.72.145.44 国家授时中心
ntp.aliyun.com 阿里云
s1a.time.edu.cn 北京邮电大学
s1b.time.edu.cn 清华大学
s1c.time.edu.cn 北京大学
s1d.time.edu.cn 东南大学
s1e.time.edu.cn 清华大学
s2a.time.edu.cn 清华大学
s2b.time.edu.cn 清华大学
s2c.time.edu.cn 北京邮电大学
s2d.time.edu.cn 西南地区网络中心
s2e.time.edu.cn 西北地区网络中心
s2f.time.edu.cn 东北地区网络中心
s2g.time.edu.cn 华东南地区网络中心
s2h.time.edu.cn 四川大学网络管理中心
s2j.time.edu.cn 大连理工大学网络中心
s2k.time.edu.cn CERNET桂林主节点
s2m.time.edu.cn 北京大学
ntp.sjtu.edu.cn 202.120.2.101 上海交通大学
实验1
- 同步时间
- 第一步:先修改成错误时间确认时区CST
[root@server ~]# date -s 10:30
2023年 05月 30日 星期二 10:30:00 CST
- 第二步:编制chrony的配置文件
[root@server ~]# vim /etc/chrony.conf
# 定位第3行,删除后添加阿里的时间同步服务地址
server ntp.aliyun.com iburst
# 注意:也可以先清空chrony.conf内容,将阿里开源提供的时间服务器推荐配置复制粘贴到该文件中
pool ntp.aliyun.com iburst
- 第三步:重启服务
[root@server ~]# systemctl restart chronyd
- 第三步:时间同步
[root@server ~]# date 查看时间
[root@server ~]# chronyc sources -v
.-- Source mode '^' = server, '=' = peer, '#' = local clock.
/ .- Source state '*' = current best, '+' = combined, '-' = not combined,
| / 'x' = may be in error, '~' = too variable, '?' = unusable.
|| .- xxxx [ yyyy ] +/- zzzz
|| Reachability register (octal) -. | xxxx = adjusted offset,
|| Log2(Polling interval) --. | | yyyy = measured offset,
|| \ | | zzzz = estimated error.
|| | | \
MS Name/IP address Stratum Poll Reach LastRx Last sample
==========================================================================
^* 203.107.6.88 2 6 17 56 +493us[ -335us] +/- 34ms
- 第五步:查看时间是否同步
[root@server ~]# timedatectl status
Local time: 二 2023-05-30 10:24:39 CST
Universal time: 二 2023-05-30 02:24:39 UTC
RTC time: 二 2023-05-30 02:24:40
Time zone: Asia/Shanghai (CST, +0800)
System clock synchronized: yes # yes 表名已同步
NTP service: active
RTC in local TZ: no
[root@server ~]# date
2023年 05月 30日 星期二 10:26:14 CST
实验2
-
搭建本地时间同步服务器
-
架构
| 性质 | IP地址 | 同步对象 |
|---|---|---|
| 服务端server | 192.168.48.130 | ntp.aliyun.com |
| 客户端node1 | 192.168.48.131 | 192.168.48.130 |
-
要求
- 服务端server向阿里时间服务器进行时间同步
- 客户端node1向服务端server进行时间同步
-
第一步:定位服务端server
# 安装软件
[root@server ~]# yum install chrony -y # 默认已安装
# 编辑配置文件,定位第3行,修改为阿里的时间服务地址
[root@server ~]# vim /etc/chrony.conf
server ntp.aliyun.com iburst
# 重启服务
[root@server ~]# systemctl restart chronyd
# 测试
[root@server ~]# chronyc sources -v
[root@server ~]# timedatectl status
# 设置允许客户端时间同步
[root@server ~]# vim /etc/chrony.conf
26 allow 192.168.48.131/24 # 定位第26行,设置谁可以访问本机进行同步
[root@server ~]# systemctl restart chronyd
- 第二步:定位客户端node1
# 安装软件
[root@node1 ~]# yum install chrony -y
# 编辑配置文件
[root@node1 ~]# vim /etc/chrony.conf # 修改第3行为server的地址
server 192.168.48.130 iburst
# 重启服务
[root@node1 ~]# systemctl restart chronyd
# 测试
[root@node1 ~]# chronyc sources -v
.-- Source mode '^' = server, '=' = peer, '#' = local clock.
/ .- Source state '*' = current best, '+' = combined, '-' = not combined,
| / 'x' = may be in error, '~' = too variable, '?' = unusable.
|| .- xxxx [ yyyy ] +/- zzzz
|| Reachability register (octal) -. | xxxx = adjusted offset,
|| Log2(Polling interval) --. | | yyyy = measured offset,
|| \ | | zzzz = estimated error.
|| | | \
MS Name/IP address Stratum Poll Reach LastRx Last sample
=========================================================================
^* 192.168.48.130 3 6 17 39 +20us[ +252us] +/- 38ms
[root@node1 ~]# timedatectl status
Local time: 二 2023-05-30 11:08:37 CST
Universal time: 二 2023-05-30 03:08:37 UTC
RTC time: 二 2023-05-30 03:08:38
Time zone: Asia/Shanghai (CST, +0800)
System clock synchronized: yes
NTP service: active
RTC in local TZ: no
- 注意:客户端同步失败的原因
- 检查网络连通性,需要能ping通
- 检查服务端的allow参数
- 需要重启服务
chronyc sources输出分析
- M:这表示信号源的模式。*^表示服务器,=*表示对等方,#表示本地连接的参考时钟。
- S:此列指示源的状态
| ***** | chronyd当前同步到的源 |
|---|---|
| + | 表示可接受的信号源,与选定的信号源组合在一起 |
| - | 表示被合并算法排除的可接受源 |
| ? | 表示已失去连接的源 |
| x | 表示chronyd认为是虚假行情的时钟(即,其时间与大多数其他来源不一致) |
| ~ | 表示时间似乎具有太多可变性的来源 |
- Name/IP address:显示服务器源的名称或IP地址
- Stratum:表示源的层级,层级1表示本地连接的参考时钟,第2层表示通过第1层级计算机的时钟实现同步,依此类推
- Poll:表示源轮询频率,以秒为单位,值是基数2的对数,例如值6表示每64秒进行一次测量,chronyd会根据当时的情况自动改变轮询频率
- Reach:表示源的可达性的锁存值(八进制数值),该锁存值有8位,并在当接收或丢失一次时进行一次更新,值377表示最后八次传输都收到了有效的回复
- LastRx:表示从源收到最近的一次的时间,通常是几秒钟,字母m,h,d或y分别表示分钟,小时,天或年
- Last sample:表示本地时钟与上次测量时源的偏移量,方括号左侧的数字表示原始测量值,方括号右侧表示偏差值,*+/-*指示器后面的数字表示测量中的误差范围。正偏移表示本地时钟位于源时钟之前
其它命令
- 查看时间服务器的状态
[root@server ~]# chronyc sourcestats -v
- 查看时间服务器是否在线
[root@server ~]# chronyc activity -v
- 同步系统时钟
[root@server ~]# chronyc -a makestep
常见时区
- **UTC 整个地球分为二十四时区,每个时区都有自己的本地时间。在国际无线电通信场合,为了统一起见,使用一个统一的时间,称为通用协调时(UTC, Universal Time Coordinated)。
- GMT 格林威治标准时间 (Greenwich Mean Time)指位于英国伦敦郊区的格林尼治天文台的标准时间,因为本初子午线被定义在通过那里的经线。(UTC与GMT时间基本相同,本文中不做区分)
- CST 中国标准时间 (China Standard Time)GMT + 8 = UTC + 8 = CST
- DST夏令时(Daylight Saving Time) 指在夏天太阳升起的比较早时,将时间拨快一小时,以提早日光的使用。(中国不使用)
第三章 远程连接服务器
简介
概念
- 远程连接服务器通过文字或图形接口方式来远程登录系统,让你在远程终端前登录linux主机以取得可操作主机接口(shell),而登录后的操作感觉就像是坐在系统前面一样
功能:
-
分享主机的运算能力
-
服务器类型:有限度开放连接
-
工作站类型:只对内网开放
分类
文字接口:
- 明文传输:Telnet、RSH等,目前非常少用
# 使用wireshark抓包分析工具验证telnet明文传输
[root@server ~]# yum install telnet-server -y # 安装telnet
[root@server ~]# systemctl start telnet.socket # 启动服务
# 使用xshell 新建telnet连接
# 在https://www.wireshark.org/download.html下载安装wireshar
# 启动wireshark,选择捕获VMnet8网卡
# 在xshell中输入ip a 或其它命令
# 在wireshark选择记录后单右->追踪流->TCP流
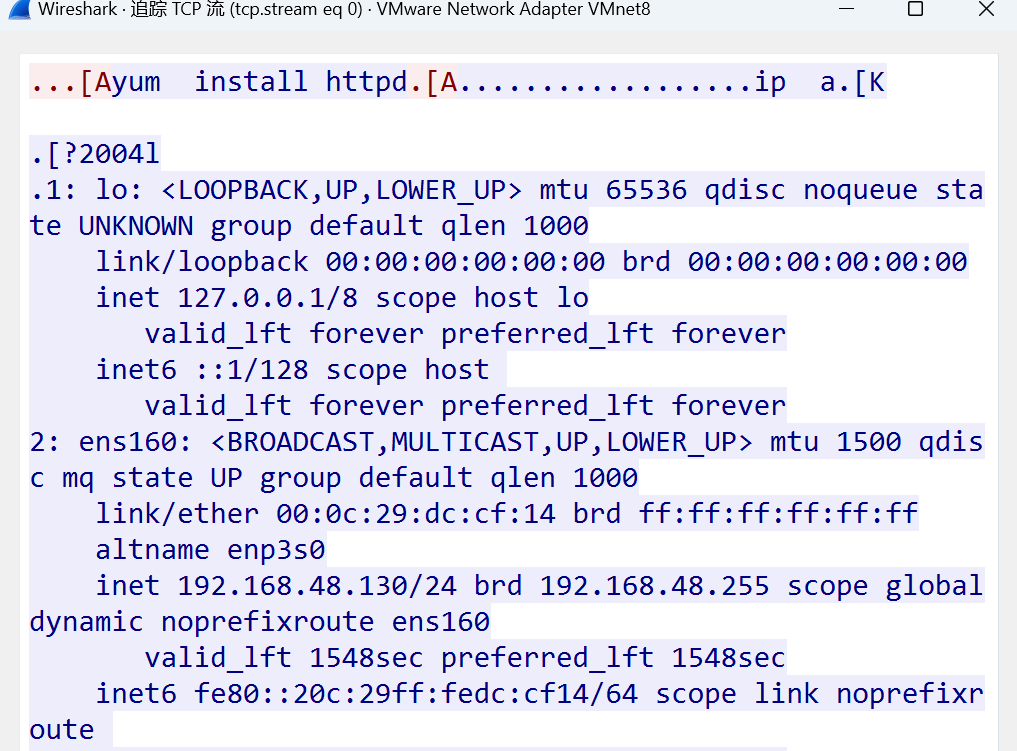
# 可以看到是明文传输
- 加密传输:SSH为主,已经取代明文传输
# 关闭上述telnet连接,建立ssh连接,查看是否为加密传输
图形接口:
- XDMCP、VNC、XRDP等
文字接口连接服务器:
-
SSH(Secure Shell Protocol,安全壳程序协议)由 IETF 的网络小组(Network Working Group)所制定,可以通过数据包加密技术将等待传输的数据包加密后再传输到网络上。
-
ssh协议本身提供两个服务器功能:
- 一个是类似telnet的远程连接使用shell的服务器;
- 另一个就是类似ftp服务的sftp-server,提供更安全的ftp服务。
连接加密技术简介
- 目前常见的网络数据包加密技术通常是通过“非对称密钥系统”来处理的。
- 主要通过两把不一样的公钥与私钥来进行加密与解密的过程。
密钥解析:
- 公钥(public key):提供给远程主机进行数据加密的行为,所有人都可获得你的公钥来将数据加密。
- 私钥(private key):远程主机使用你的公钥加密的数据,在本地端就能够使用私钥来进行解密。私钥只有自己拥有。
**对称加密:**同一秘钥既可以进行加密也可以进行解密
优势:使用一个秘钥它的加密效率高一些(快一些)
缺陷:秘钥传输的安全性(在网络传输中不传输秘钥)
应用: 传输数据(数据的双向传输)
**非对称加密:**产生一对秘:公钥:公钥加密 私钥:私钥解密(不会进行网络传输)
缺陷:公钥的安全性 客户端去访问一个服务器(假设数据被我们的hacker拦截了,hacker发送了自己的公钥给客户端,客户端用 hacker的公钥对数据进行加密,然后hacker用自己的私钥进行解密。从而获取到用户传送的隐私(用户和密码)信息,进一步对服务器动机);传送速度慢(效率低)
优势:安全性更高
应用: 单向的认证阶段(建立安全的连接保证后面对称加密的秘钥安全)

SSH工作过程:tcp/22
- 服务端与客户端要经历如下五个阶段:
| 过程 | 说明 |
|---|---|
| tcp三次握手版本号协商阶段 | SSH目前包括SSH1和SSH2两个版本,双方通过版本协商确定使用的版本 |
| 密钥和算法协商阶段 | SSH支持多种加密算法,双方根据本端和对端支持的算法,协商出最终使用的算法 |
| 认证阶段 | SSH客户端向服务器端发起认证请求,服务器端对客户端进行认证 |
| 会话请求阶段 | 认证通过后,客户端向服务器端发送会话请求 |
| 交互会话阶段 | 会话请求通过后,服务器端和客户端进行信息的交互 |
版本协商阶段
-
服务器端打开端口22,等待客户端连接;
-
客户端向服务器端发起TCP初始连接请求,TCP连接建立后,服务器向客户端发送第一个报文,包括版本标志字符串,格式为
SSH-<主协议版本号>.<次协议版本号>.<软件版本号>,协议版本号由主版本号和次版本号组成,软件版本号主要是为调试使用。 -
客户端收到报文后,解析该数据包,如果服务器的协议版本号比自己的低,且客户端能支持服务器端的低版本,就使用服务器端的低版本协议号,否则使用自己的协议版本号。
-
客户端回应服务器一个报文,包含了客户端决定使用的协议版本号。服务器比较客户端发来的版本号,决定是否能同客户端一起工作。如果协商成功,则进入密钥和算法协商阶段,否则服务器断开TCP连接
-
注意:上述报文都是采用明文方式传输
密钥和算法协商阶段
-
服务器端和客户端分别发送算法协商报文给对端,报文中包含自己支持的公钥算法列表、加密算法列表、MAC(Message Authentication Code,消息验证码)算法列表、压缩算法列表等等
-
服务器端和客户端根据对端和本端支持的算法列表得出最终使用的算法
-
服务器端和客户端利用DH交换(Diffie-Hellman Exchange)算法、主机密钥对等参数,生成会话密钥和会话ID。
进行秘钥交换:dh**迪菲-赫尔曼**算法 https://blog.csdn.net/itworld123/article/details/115902978 素数又叫质数。素数,指的是“大于1的整数中,只能被1和这个数本身整除的数”。 **20以内的素数**:2、3、5、7、11、13、17、19. DH秘钥交换算法数学模型 - 客户端发往服务器的DH初始化参数:ecdh public key - 客户端发送自己的公钥给服务器 - 服务端发送自己的公钥给客户端 - 计算出对称加密的秘钥(sessionkey)--NewKeys - 客户端计算出对称加密的秘钥(sessionkey)--newkeys - 解决了一个问题:保证了进行传输时候对称加密秘钥的安全。(能不能用的上这个秘钥,还取决于认证阶段是否成功)
都生成一个非对称秘钥(公钥私钥)
-
由此,服务器端和客户端就取得了相同的会话密钥和会话ID。对于后续传输的数据,两端都会使用会话密钥进行加密和解密,保证了数据传送的安全。在认证阶段,两端会使用会话用于认证过程
-
会话密钥的生成:
- 客户端需要使用适当的客户端程序来请求连接服务器,服务器将服务器的公钥发送给客户端。(服务器的公钥产生过程:服务器每次启动sshd服务时,该服务会主动去找/etc/ssh/ssh_host*文件,若系统刚装完,由于没有这些公钥文件,因此sshd会主动去计算出这些需要的公钥文件,同时也会计算出服务器自己所需要的私钥文件。)
- 服务器生成会话ID,并将会话ID发给客户端。
- 若客户端第一次连接到此服务器,则会将服务器的公钥数据记录到客户端的用户主目录内的~/.ssh/known_hosts。若是已经记录过该服务器的公钥数据,则客户端会去比对此次接收到的与之前的记录是否有差异。客户端生成会话密钥,并用服务器的公钥加密后,发送给服务器。
- 服务器用自己的私钥将收到的数据解密,获得会话密钥。
- 服务器和客户端都知道了会话密钥,以后的传输都将被会话密钥加密
认证阶段(两种认证方法):
-
SSH客户端向服务端发起认证请求,服务端对客户端进行认证
(1)基于口令的认证:


(2)基于公钥的认证:

1.Client将自己的公钥存放在Server上,追加在文件authorized_keys中。
2.Server端接收到Client的连接请求后,会在authorized_keys中匹配到Client的公钥pubKey,并生成随机数R,用Client的公钥对该随机数进行加密得到pubKey®,然后将加密后信息发送给Client。
3.Client端通过私钥进行解密得到随机数R,然后对随机数R和本次会话的SessionKey利用MD5生成摘要Digest1,发送给Server端。
4.Server端会也会对R和SessionKey利用同样摘要算法生成Digest2。
5.Server端会最后比较Digest1和Digest2是否相同,完成认证过程。
-
注:服务器端对客户端进行认证,如果认证失败,则向客户端发送认证失败消息,其中包含可以再次认证的方法列表。客户端从认证方法列表中选取一种认证方法再次进行认证,该过程反复进行。直到认证成功或者认证次数达到上限,服务器关闭连接为止
第四阶段:会话请求阶段:
认证通过后,客户端向服务器端发送会话请求,建立新的连接
**第五阶段:交互会话阶段:**会话请求通过后,服务器端和客户端进行信息的交互
传输数据的的阶段:数据时要被加密(对称加密方式),对称加密的秘钥就是sessionKey(客户端和服务服务端在秘钥交换阶段互相计算出来的,sessionKey未进行网络传输)
SSH服务配置
安装ssh
[root@server ~]# yum install openssh-server
配置文件分析:
[root@server ~]# vim /etc/ssh/sshd_config
21.#Port 22 # 默认监听22端口,可修改
22.#AddressFamily any # IPV4和IPV6协议家族用哪个,any表示二者均有
23.#ListenAddress 0.0.0.0 # 指明监控的地址,0.0.0.0表示本机的所有地址(默认可修改)
24.#ListenAddress :: # 指明监听的IPV6的所有地址格式
26.#HostKey /etc/ssh/ssh_host_rsa_key # rsa私钥认证,默认
27.#HostKey /etc/ssh/ssh_host_ecdsa_key # ecdsa私钥认证
28.#HostKey /etc/ssh/ssh_host_ed25519_key # ed25519私钥认证
34 #SyslogFacility AUTH # ssh登录系统的时会记录信息并保存在/var/log/secure
35.#LogLevel INFO # 日志的等级
39.#LoginGraceTime 2m # 登录的宽限时间,默认2分钟没有输入密码,则自动断开连接
40 PermitRootLogin yes # 允许管理员root登录
41.#StrictModes yes # 是否让sshd去检查用户主目录或相关文件的权限数据
42.#MaxAuthTries 6 # 最大认证尝试次数,最多可以尝试6次输入密码。之后需要等待某段时间后才能再次输入密码
43.#MaxSessions 10 # 允许的最大会话数
49.AuthorizedKeysFile .ssh/authorized_keys # 选择基于密钥验证时,客户端生成一对公私钥之后,会将公钥放到.ssh/authorizd_keys里面
65 #PasswordAuthentication yes # 登录ssh时是否进行密码验证
66 #PermitEmptyPasswords no # 登录ssh时是否允许密码为空
……
123.Subsystem sftp /usr/libexec/openssh/sftp-server #支持 SFTP ,如果注释掉,则不支持sftp连接
AllowUsers user1 user2 #登录白名单(默认没有这个配置,需要自己手动添加),允许远程登录的用户。如果名单中没有的用户,则提示拒绝登录
ssh实验
实验1
-
修改ssh服务器端的端口号
-
第一步:服务端操作,编辑配置文件,修改端口号
[root@server ~]# vim /etc/ssh/sshd_config # 定位第21行,去掉# 后修改端口号
21 Port 2222
- 第二步:服务端操作,重启服务
[root@server ~]# systemctl restart sshd # 注意:ssh的服务名位sshd
- 第三步:客户端操作,ssh登录服务端
[root@node1 ~]# ssh root@192.168.48.130
# 尝试登录被拒绝,22端口已关闭
ssh: connect to host 192.168.48.130 port 22: Connection refused
root@node1 ~]# ssh -p 2222 root@192.168.48.130 # 指明以2222端口登录服务端
The authenticity of host '[192.168.48.130]:2222 ([192.168.48.130]:2222)' can't be established.
ED25519 key fingerprint is SHA256:K7nvJFkfIh+p9YytEGR44wLbTfpB0Y52oVou0UdG6nc.
This key is not known by any other names
Are you sure you want to continue connecting (yes/no/[fingerprint])? yes # 输入yes
Warning: Permanently added '[192.168.48.130]:2222' (ED25519) to the list of known hosts.
root@192.168.48.130's password: # 输入服务端账户密码
Activate the web console with: systemctl enable --now cockpit.socket
Register this system with Red Hat Insights: insights-client --register
Create an account or view all your systems at https://red.ht/insights-dashboard
Last login: Tue May 30 13:57:25 2023 from 192.168.48.1
[root@server ~]#
# 注销登录
[root@server ~]# exit # 注销,回到node1主机,或者使用ctrl+d进行注销
注销
Connection to 192.168.48.130 closed.
实验2
-
拒绝root账户远程登录
-
方法:使用配置文件中的Permitrootlogin参数进行实现
-
参数值:
| 参数类别 | 是否允许ssh登录 | 登录方式 | 交互shell |
|---|---|---|---|
| yes | 允许 | 无限制 | 无限制 |
| no | 不允许 | 无 | 无 |
| prohibit-password | 允许 | 仅允许使用密码 | 无限制 |
| forced-commands only | 允许 | 仅允许密钥 | 授权的口令 |
[root@server ~]# vim /etc/ssh/sshd_config
PasswordAuthentication no
[root@Server ~]# vim /etc/ssh/sshd_config.d/01-permitrootlogin.conf
PermitRootLogin no # yes修改为no
- 第二步:服务端重启服务
[root@server ~]# systemctl restart sshd
- 第三步:客户端,测试
[root@node1 ~]# ssh root@192.168.48.130
root@192.168.48.130's password: # 拒绝root连接ssh
Permission denied, please try again.
实验3
- 允许特定账户进行ssh登录,其它账户无法登录
- 第一步:服务端添加新账户
[root@server ~]# useradd test
[root@server ~]# passwd test
- 第二步:服务端修改主配置文件
[root@server ~]# vim /etc/ssh/sshd_config
AllowUsers test # 第一行添加
[root@server ~]# systemctl restart sshd
- 第三步:客户端测试
[root@node1 ~]# ssh test@192.168.48.130
The authenticity of host '192.168.48.130 (192.168.48.130)' can't be established.
ED25519 key fingerprint is SHA256:K7nvJFkfIh+p9YytEGR44wLbTfpB0Y52oVou0UdG6nc.
This key is not known by any other names
Are you sure you want to continue connecting (yes/no/[fingerprint])? yes # 输入yes
Warning: Permanently added '192.168.48.130' (ED25519) to the list of known hosts.
test@192.168.48.130's password: # 密码123456
Register this system with Red Hat Insights: insights-client --register
Create an account or view all your systems at https://red.ht/insights-dashboard
[test@server ~]$ # 按下ctrl+d进行注销
注销
[root@node1 ~]# ssh root@192.168.48.130 # 测试其它账户可否登录
root@192.168.48.130's password:
Permission denied, please try again
Port 22
PermitRootLogin yes
PasswordAuthentication yes
AllowUsers USERNAME
AuthorizedKeysFile .ssh/authorized_keys #加载秘钥文件(公钥文件)
实验4
ssh-keygen
- ssh-keygen是用于生成、管理、转换密钥的工具
- 格式:
[root@server ~]# ssh-keygen -t rsa
- 分析
- -t:指定密钥类型
- rsa:使用rsa公钥加密算法,可以产生公钥和私钥
- 执行后会在对应账户目录中产生一个隐藏目录.ssh,其中有2个文件
- id_rsa:私钥文件
- id_rsa.pub:公钥文件
虚拟之间实现密钥的登录(免密登录)
-
预处理:2台机子都恢复快照
-
第一步:定位客户端,制作公私钥对
[root@node1 ~]# ssh-keygen -t rsa # 一路回车
- 第二步:定位客户端,将公钥上传到服务器端
[root@node1 ~]# ssh-copy-id root@192.168.48.130 # 输入服务端的账户及IP地址
The authenticity of host '192.168.48.130 (192.168.48.130)' can't be established.
ED25519 key fingerprint is SHA256:K7nvJFkfIh+p9YytEGR44wLbTfpB0Y52oVou0UdG6nc.
This key is not known by any other names
Are you sure you want to continue connecting (yes/no/[fingerprint])? yes # 输入yes
/usr/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed
/usr/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys
root@192.168.48.130's password: # 输入服务端root账户的的密码
Number of key(s) added: 1
Now try logging into the machine, with: "ssh 'root@192.168.48.130'"
and check to make sure that only the key(s) you wanted were added.
# 注意:客户端将公钥上传到服务器端后,服务器端的/root/.ssh/authorized_keys文件会存储客户端的公钥数据
- 第三步:客户端测试
[root@node1 ~]# ssh root@192.168.48.130
Activate the web console with: systemctl enable --now cockpit.socket
Register this system with Red Hat Insights: insights-client --register
Create an account or view all your systems at https://red.ht/insights-dashboard
Last login: Wed Mar 22 11:31:31 2023
[root@server ~]#
- 第四步:由于是要实现服务端与客户端相互免密,则将上述操作在服务端在执行一遍
实验5
-
xshell使用密钥登陆
-
之前xshell使用的是密码登录,现在通过密钥的配置,实现无密码登录
# 注意:先在服务器端检查/root/.ssh/authorized_keys是否存在,它时存储公钥的文件,若不存在需要新建
# 服务器端操作
[root@server ~]# cd /root
[root@server ~]# ls -a
[root@server ~]# mkdir .ssh
[root@server ~]# cd .ssh
[root@server .ssh]# vim authorized_keys
# 有时需要注意.ssh目录的权限
- 打开xshell开始操作,新建密钥:
- 下一步:
- 设置密钥文件名加密密码(可不设)
- 产生公钥,并另存为文件
- 将windows中保存的公钥文件以记事本的方式打开,复制内容,拷贝到Linux服务器端的
/root/.ssh/authorized_keys文件中后保存退出,并重启服务:
[root@server .ssh]# systemctl restart sshd
- xshell中新建会话:
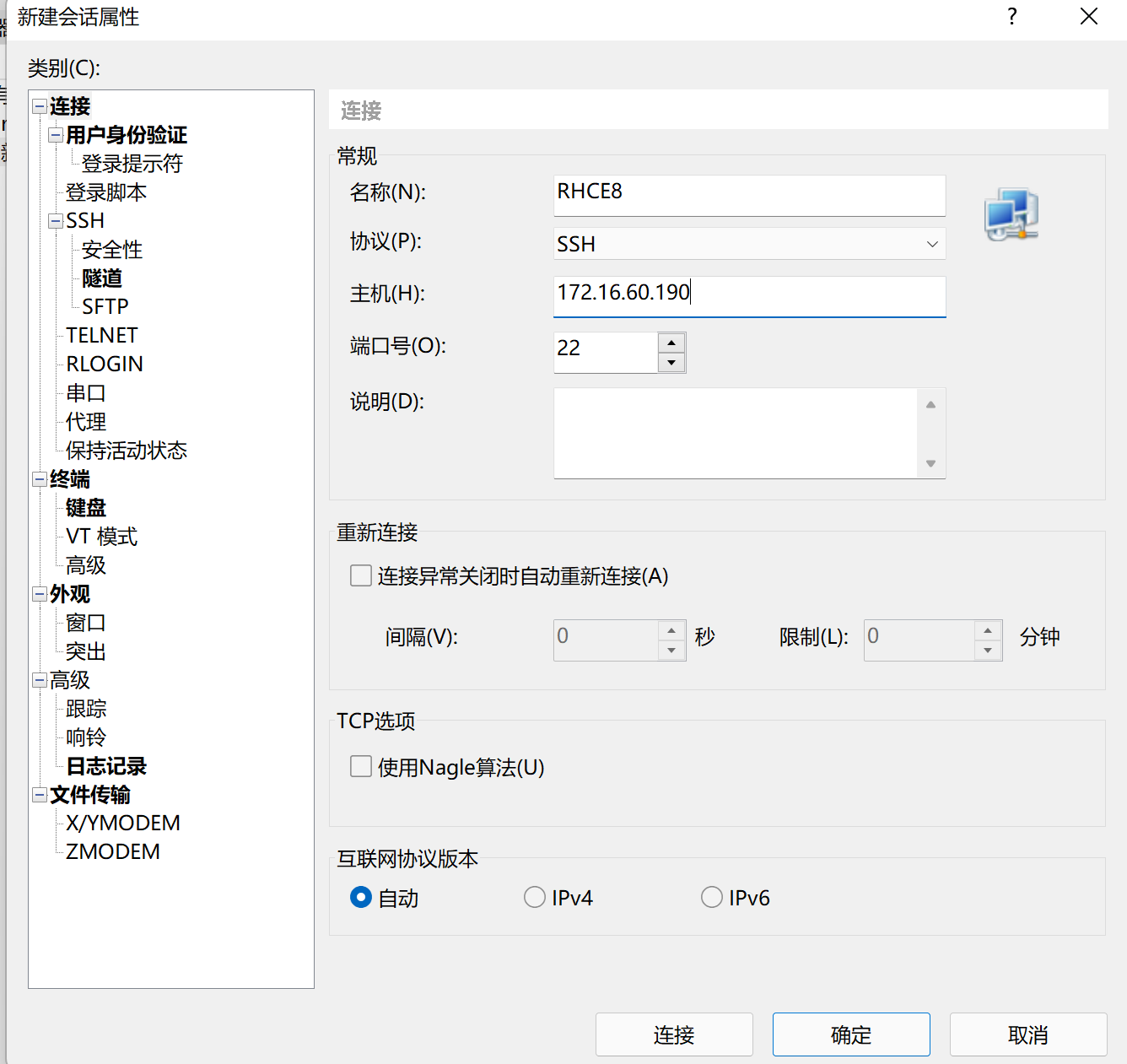
- 点击用户身份验证,选择Public Key 方式验证登录,点击连接
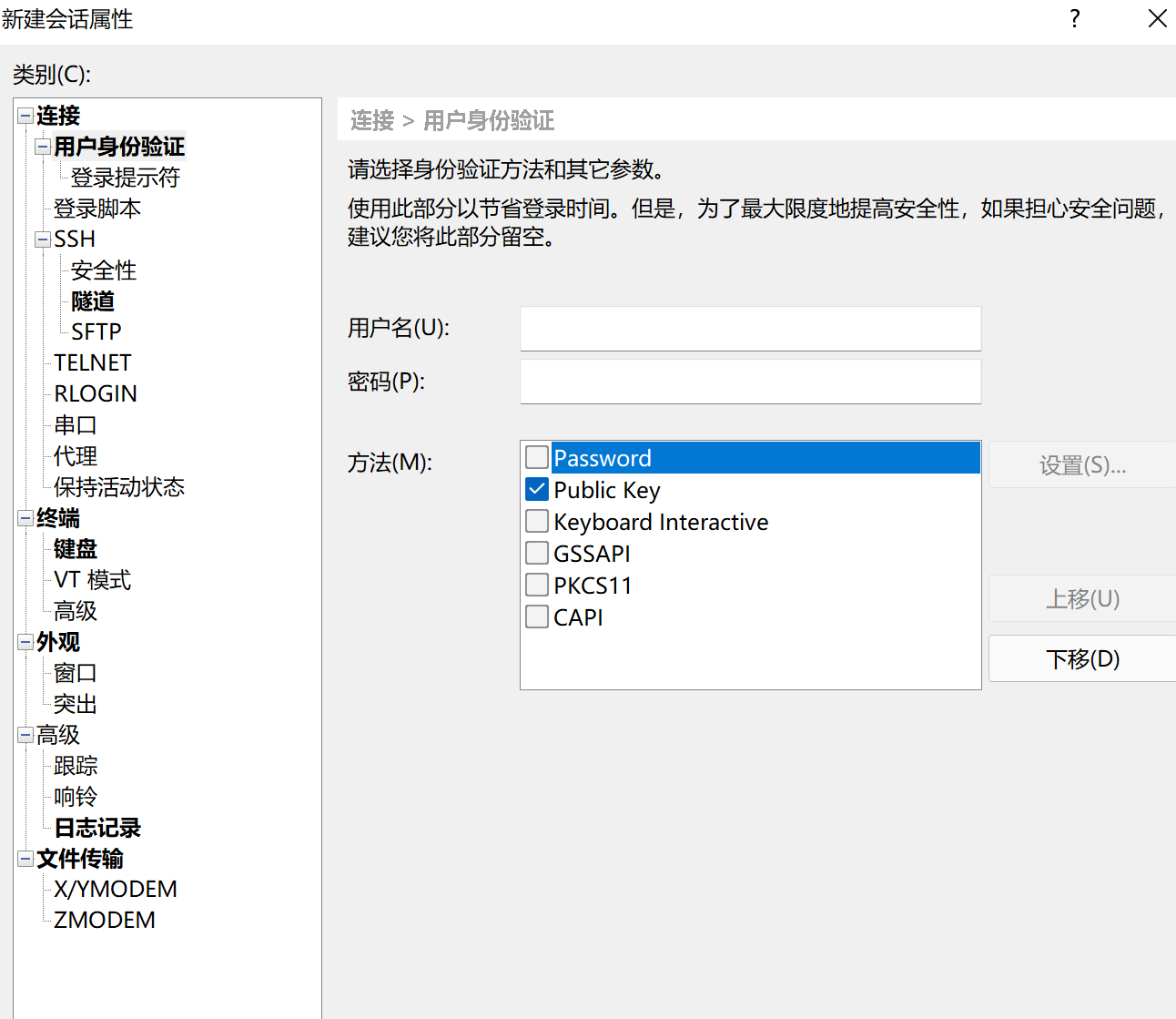
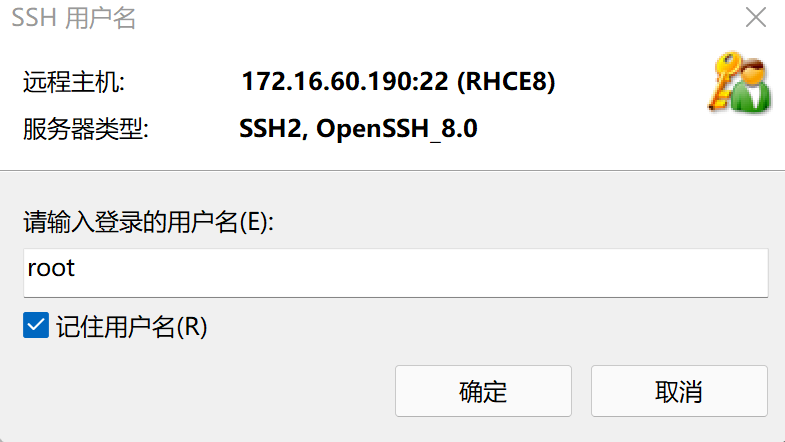
- 设置以什么身份登录:
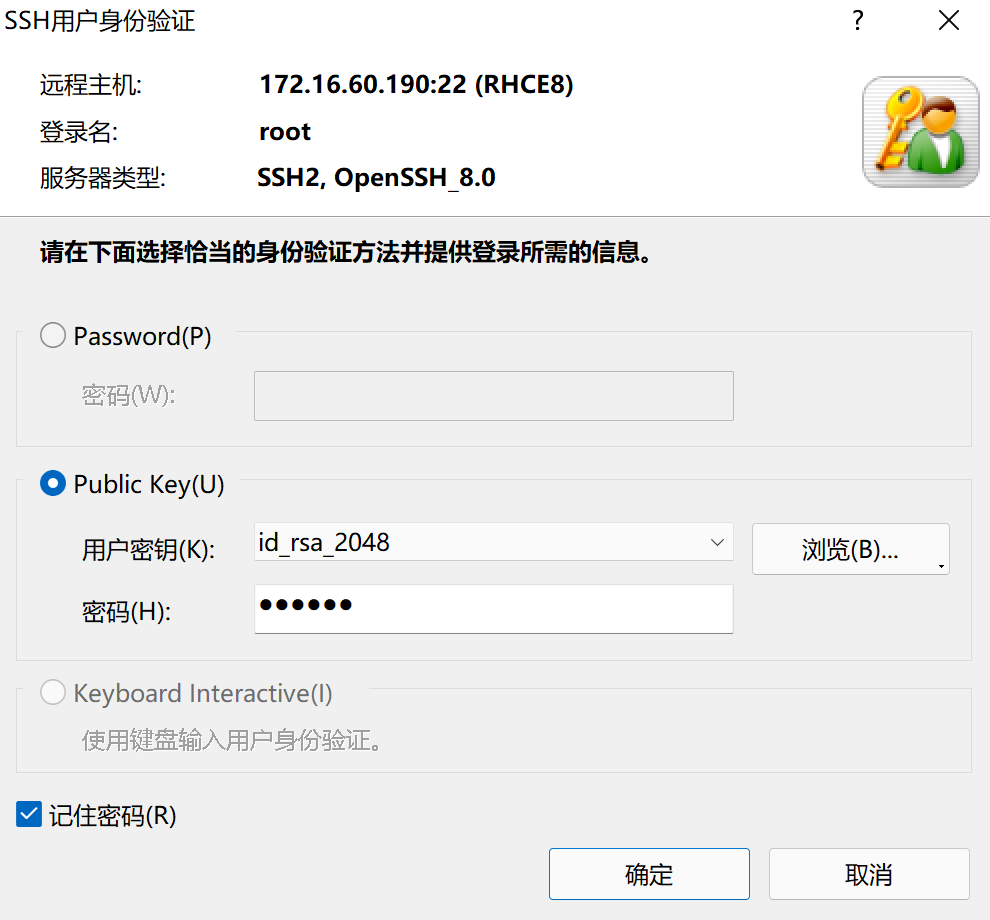
- 输入密钥密码
- 成功
第四章 web服务器 www http apache nginx
www简介
-
Web网络服务也叫WWW(World Wide Web 全球信息广播)万维网服务,一般是指能够让用户通过浏览器访问到互联网中文档等资源的服务
-
Web 网络服务是一种被动访问的服务程序,即只有接收到互联网中其他主机发出的请求后才会响应,最终用于提供服务程序的 Web 服务器会通过 HTTP(超文本传输协议)或HTTPS(安全超文本传输协议)把请求的内容传送给用户,如图:

常见Web服务程序介绍:
- Windows系统中默认Web服务程序是I I S(Internet Information Services),这是一款图形化的网站管理工具,IIS程序不光能提供Web网站服务,还能够提供FTP、NMTP、SMTP等服务功能,但只能在Windows系统中使用

- 2004 年 10 月 4 日,为俄罗斯知名门户站点而开发的 Web 服务程序 Nginx 横空出世。Nginx程序作为一款轻量级的网站服务软件,因其稳定性和丰富的功能而快速占领服务器市场,但Nginx 最被认可的还当是低系统资源占用、内存少且并发能力强,因此得到了国内诸如新浪、网易、腾讯等门户站的青睐

- Apache——取自美国印第安人土著语Apache,寓意着拥有高超的作战策略和无穷的耐性,由于其跨平台和安全性广泛被认可且拥有快速、可靠、简单的API扩展。目前拥有很高的Web服务软件市场占用率,全球使用最多的Web服务软件,开源、跨平台(可运行于Unix,linux,windows中)

- Tomcat——属于轻量级的Web服务软件,一般用于开发和调试JSP代码,通常认为Tomcat是Apache的扩展程序

服务器主机
- 网站是由域名、网页源程序和主机空间组成的,其中主机空间则是用于存放网页源代码并能够将网页内容展示给用户,虽然本小节与Apache服务没有直接关系,但如果您想要在互联网中搭建网站并被顺利访问,主机空间一定不能选错

-
虚拟主机:在一台服务器中分出一定的磁盘空间供用户放置网站、存放数据等,仅提供基础的网站访问、数据存放与传输流量功能,能够极大的降低用户费用,也几乎不需要管理员维护除网站数据以外的服务,适合小型网站
-
VPS(Virtual Private Server):在一台服务器中利用OpenVZ、Xen或KVM等虚拟化技术模拟出多个“主机”,每个主机都有独立的IP地址、操作系统,实现不同VPS之间磁盘空间、内存、CPU资源、进程与系统配置间的完全隔离,管理员可自由使用分配到的主机中的所有资源,所以需要有一定的维护系统的能力,适合小型网站
-
云服务器(ECS):是一种整合了计算、存储、网络,能够做到弹性伸缩的计算服务,其使用起来与VPS几乎一样,但差别是云服务器建立在一组集群服务器中,每个服务器都会保存一个主机的镜像(备份),大大的提升了安全稳定性,另外还具备了灵活性与扩展性,用户只需按使用量付费的即可,适合大中小型网站。
-
独立服务器:这台服务器仅提供给您使用,详细来讲又可以区分为租用方式与托管方式
- 租用方式:用户只需将硬件配置要求告知IDC服务商,服务器硬件设备由机房负责维护,运维管理员一般需要自行安装相应的软件并部署网站服务,租期可以为月、季、年,减轻了用户初期对硬件设备的投入,适合大中型网站。
- 托管方式:用户需要自行购置服务器后交给IDC服务供应商的机房进行管理(缴纳管理服务费用),用户对服务器硬件配置有完全的控制权,自主性强,但需要自行维护、修理服务器硬件设备,适合大中型网站。
- 另外有必要提醒,选择主机空间供应商时请一定要注意看口碑,综合分析再决定购买,某些供应商会有限制功能、强制添加广告、隐藏扣费或强制扣费等恶劣行为,一定一定不要上当!
主要数据
- 服务器所提供的最主要数据是超文本标记语言(Hyper Text Markup Language,HTML)、多媒体文件(图片、影像、声音、文字等,都属于多媒体或称为超媒体),HTML只是一些纯文本数据,通过所谓的标记来规范所要显示的数据格式
浏览器
- 客户端收到服务器的数据之后需要软件解析服务器所提供的数据,最后将效果呈现在用户的屏幕上。
- 那么著名的浏览器就有内建在Windows操作系统内的IE浏览器(淘汰)和Microsoft Edge,还有Firefox浏览器和Google的chrome浏览器
网址及HTTP简介
- web服务器提供的这些数据大部分都是文件,那么我们需要在服务器端先将数据文件写好,并且放置在某个特殊的目录下面,这个目录就是我们整个网站的首页,在redhat中,这个目录默认在 /var/www/html 。
- 浏览器是通过你在地址栏中输入你所需要的网址来取得这个目录的数据的
URL
-
Uniform Resource Locator,统一资源定位符,对可以从互联网上得到的资源的位置和访问方法的一种简洁的表示,是互联网上标准资源的地址
-
网址格式:
<协议>://<主机或主机名>[:port]/<目录资源,路径>/资源文件名 -
协议::http、https、ftp等
-
主机地址或者主机名:主机地址就是服务器在因特网所在的IP地址。如果是主机名的话,那么就需要域名解析了
-
端口号(port):http为80,https为443 (IANA:互联网数字分配机构)
- 0-1023:永久地分配给固定的应用程序使用
- 1024-41951:注册端口,但要求不是特别严格,分配给程序注册为某应用使用
- 41952-60000:客户端程序随机使用的端口,动态端口,或私有端口
http请求方法:
- 工作机制:

- 在http通信中,每个http请求报文都包含一个方法,用以告诉web服务器端需要执行哪些具体的动作,这些动作包括:获取指定web页面、提交内容到服务器、删除服务器上资源文件等。

- 状态代码:由三位数字组成,第一个数字定义了响应的类别,且有五种可能取值
- 1xx:指示信息 —— 表示请求已接收,继续处理
- 2xx:成功 —— 表示请求已被成功接收、理解、接
- 3xx:重定向 —— 要完成请求必须进行更进一步的操作
- 4xx:客户端错误 —— 请求有语法错误或请求无法实现
- 5xx:服务器端错误 —— 服务器未能实现合法的请求
- 常见状态代码、状态描述的说明如下:
- 200 OK:客户端请求成功
- 400 Bad Request:客户端请求有语法错误,不能被服务器所理解
- 401 Unauthorized:请求未经授权,这个状态代码必须和 WWW-Authenticate 报头域一起使用
- 403 Forbidden:服务器收到请求,但是拒绝提供服务
- 404 Not Found:请求资源不存在,举个例子:输入了错误的URL
- 500 Internal Server Error:服务器发生不可预期的错误
- 503 Server Unavailable:服务器当前不能处理客户端的请求,一段时间后可能恢复正常
http://www.baidu.com
HTTP协议请求的工作流程:

特点

www服务器的类型
静态网站
- 仅提供用户浏览的单向静态网页,单纯是由服务器单向提供数据给客户端,Server不需要与client端有互动,可以浏览网站,但是无法数据上传。
动态网站
- 该站可以让服务器与用户互动,常见的例如留言板,博客。这种类型的网站需要通过“网页程序语言”来实现与用户互动的行为。常见的例如:PHP网页程序语言,配合数据库系统来进行数据的读、写。当你在向服务器请求数据时,其实是通过服务器端同一个网页程序在负责将数据读出或写入数据库,变动的是数据库的内容,网页程序并没有任何改变。
- 另外一种交互式的动态网页主要是在客户端实现。服务端将可执行的程序代码(JavaScript)传送给客户端,客户端的浏览器如果提供JavaScript的功能,那么该程序就可以在客户端的计算机上面工作了;另外一种可在客户端执行的就是flash动画格式,在这种动画格式内还可以进行程序设计

静态页面资源特征
处理文件类型:如.html、jpg、.gif、.mp4、.swf、.avi、.wmv、.flv等-
地址中不含有问号"?"或&等特殊符号。.htm .html
保存在网站服务器文件系统上的,是实实在在保存在服务器上的文件实体
页内容是固定不变的,因此,容易被搜索引擎收录
网页页面交互性交差,因为不能与数据库配合
网页程序在用户浏览器端解析,当客户端向服务器请求数据时,服务器会直接从磁盘文件系统上返回数据(不做任何解析)
优势:
访问的效率比较高
网页内容是固定不变的,因此,容易被搜索引擎收录
网页程序在用户浏览器端解析,当客户端向服务器请求数据时,服务器会直接从磁盘文件系统上返回数据(不做任何解析)
劣势:
网页页面交互性交差,因为不能与数据库配合
保存在网站服务器文件系统上的,是实实在在保存在服务器上的文件实体
动态网页资源
所谓的动态网页是与静态网页相对而言的,也就是说,动态网页的URL后缀不是.html .htm、.xml、.shtml、.js css 等静态网页的常见扩展名形式,而是.asp、.aspx、.php、.js、.do、.cgi等形式
请求响应信息,发给事务端进行处理,由服务端处理完成,将信息返回给客户端,生成的页面称为动态页面
动态网页资源特点
网觅扩展名后缀常见为:.asp、.aspx、.php、.js、.do、.cgi
网页页面交互性强,可以与数据库配合
地址中含有问号"?"或 & 等特殊符号
不便于被搜索引擎收录
优势:
1.客户端与服务端交互能力强
劣势:
1.访问的效率比较低
2.不便于被搜索引擎收录
http 80 8080
Apache: http服务器是一个模块化的服务器,可以运行几乎所有广泛使用的计算机平台上。属于应用服务器。Apache支持模块多,性能稳定,apache本身是静态解析,但也可以通过扩展脚本、模块等支持动态页面。(apache可以支持phpcgiperl,但是使用java的话需要tomcat在apache后台支持,将java请求由apache转给tomcat处理)
tomcat:应用(java)服务器,他只是一个servlet容器,可以认为是apache的扩展,但是可以独立用于apache运行。
nginx:相对一Apache占用更少的内存及资源一个轻量级服务器,是一个高性能的http和反向代理服务器,同时也是一个IMPA/POP3/SMTP代理服务器。
3、web服务器基本配置
[root@localhost nginx]# tree /etc/nginx
/etc/nginx
├── conf.d #辅助配置(子配置文件)目录
├── default.d
├── fastcgi.conf #php界面解析通用网关接口配置
├── fastcgi.conf.default
├── fastcgi_params #用以翻译nginx的变量供php识别
├── fastcgi_params.default
├── koi-utf
├── koi-win
├── mime.types #用以配置文件的媒体文件类型
├── mime.types.default
├── nginx.conf #主配置文件
├── nginx.conf.default
├── scgi_params
├── scgi_params.default
├── uwsgi_params #用以配置nginx的变量供python识别
├── uwsgi_params.default
└── win-utf
#/usr/share/nginx/html #默认的nginx网站根目录
#/var/log/nginx #nginx的日志文件目录
#nginx服务配置文件nginx.conf的结构
#############全局配置(无{}标志)############
user nginx; #进程所属用户
worker_processes auto; #线程数量CPU核心数,(双核4线程,可以设置为4)
error_log /var/log/nginx/error.log; #错误日志文件路径
pid /run/nginx.pid; #nginx pid文件位置
include /usr/share/nginx/modules/*.conf; #导入功能模块配置文件
#######################################################
##################性能配置(有{}标志)############
events {
worker_connections 1024; #tcp连接数
}
########################################################
##################http模块配置(有{}标志)############
http { #http区块开始 132
log_format main '$remote_addr - $remote_user [$time_local] "$request" '
'$status $body_bytes_sent "$http_referer" '
'"$http_user_agent" "$http_x_forwarded_for"'; #日志显示格式定义
access_log /var/log/nginx/access.log main; #访问日志文件位置
sendfile on; #开启高效文件传输
tcp_nopush on; #性能优化参数
tcp_nodelay on; #性能优化参数
keepalive_timeout 65; #持久连接或超时时间
types_hash_max_size 4096; #性能优化参数
include /etc/nginx/mime.types; #可解析的静态资源类型
default_type application/octet-stream;
include /etc/nginx/conf.d/*.conf; #加载子配置文件
server { #server区块开始,就相当于一个虚拟主机
listen 80;
listen [::]:80;
server_name _; #服务名
root /usr/share/nginx/html; #主页存放主路径(/)
include /etc/nginx/default.d/*.conf; #子配置文件路径
location / { #定义URI /匹配符匹配的是root设置的URI路径
root html;
index index.html index.htm; #链接的网页文件
}
error_page 404 /404.html; #404错误的返回页面
location = /404.html { #location 定义用户请求的uri,并返回相应的资源文件
}
error_page 500 502 503 504 /50x.html; #5xx状态返回的页面
location = /50x.html {
}
}
}
########################################################


⚠️uri中的斜线,如:
-
location /test { # 尾部无/ ... } location /test/ { ... } -
不带 / 当访问 http://www.nginx-test.com/test 时, Nginx 先找是否有 test 目录,如果有则找 test 目录下的 index.html ;如果没有 test 目录, nginx则会找是否有 test 文件。
-
带 / 当访问 http://www.nginx-test.com/test 时,只是查找 test 目录下的 index.html 。
-
server_name指令一般用于指定虚拟主机的域名,在匹配时有以下四中写法
- 精确匹配:server_name http://www.nginx.com ;
- 左侧匹配:server_name *.http://nginx.com ;
- 右侧匹配:server_name www.nginx.* ;
- 正则匹配:server_name ~^www.nginx.*$ ;
- 注:匹配优先级:精确匹配 > 左侧通配符匹配 > 右侧通配符匹配 > 正则表达式匹配
-
root指令与alias指令区别
-
root指令用于静态资源目录位置,它可以写在 http 、 server 、 location 等配置中,root指令定义的路径会与 URI 叠加产生最终访问路径,如:
-
location /image { root /opt/nginx/static; } # 当用户访问 www.test.com/image/1.png 时,实际在服务器找的路径是 /opt/nginx/static/image/1.png -
alias也是指定静态资源目录位置,但只能访问指定的绝对路径,不会叠加目录,只能写在 location 中且末尾一定要添加 / , 如:
-
location /image { alias /opt/nginx/static/image/; } #当用户访问 www.test.com/image/1.png 时,实际在服务器找的路径是 /opt/nginx/static/image/1.png
-
-
location匹配路径
-
格式:
-
location [ = | ~ | ~* | ^~ ] uri { ... } -
匹配规则:
- = 精确匹配;
- ~ 正则匹配,区分大小写;
- ~* 正则匹配,不区分大小写;
- ^~ 匹配以某个字符串开头,不是正则匹配;
- / 通用匹配,如果没有其它匹配,任何请求都会匹配到
- 注:匹配优先级:= > ^~ > ~ > ~* > 不带任何字符。
-
示例
-
server { listen 80; server_name www.nginx-test.com; # 只有当访问 www.nginx-test.com/match_all/ 时才会匹配到/usr/share/nginx/html/match_all/index.html location = /match_all/ { root /usr/share/nginx/html index index.html } # 当访问 www.nginx-test.com/1.jpg 等路径时会去 /usr/share/nginx/images/1.jpg 找对应的资源 location ~ \.(jpeg|jpg|png|svg)$ { root /usr/share/nginx/images; } # 当访问 www.nginx-test.com/bbs/ 时会匹配上 /usr/share/nginx/html/bbs/index.html location ^~ /bbs/ { root /usr/share/nginx/html; index index.html index.htm; } } # 注意: location / { root html; index index.html index.htm; } # 其/不是根目录而是统统都匹配到指定路径,而指定路径为html ,即nginx的默认网页目录/usr/share/nginx/html
-
nginx.conf 配置文件的语法规则
- 配置文件由指令与指令块构成
- 每条指令以 “;” 分号结尾,指令与参数间以空格符号分隔
- 指令块以 {} 大括号将多条指令组织在一起
- include 语句允许组合多个配置文件以提升可维护性
- 通过 # 符号添加注释,提高可读性
- 通过 $ 符号使用变量
- 部分指令的参数支持正则表达式,例如常用的 location 指令
测试案例:
实现在自定义路径/www下网页内容访问。
服务器:
#systemctl stop firewalld
#setenforce 0
#dnf install nginx
#vim /etc/nginx/nginx.conf
server {
.....
root /www;
....
}
#mkdir /www
#echo helloworld > /www/index.html
#systemctl restart nginx
客户端
浏览器: http://172.25.250.132
案例一:多ip访问多网站
[root@localhost ~]# systemctl stop firewalld
[root@localhost ~]# setenforce 0
[root@localhost ~]# yum install nginx
第一种方式:
[root@localhost ~]# nmcli connection modify ens32 ipv4.method manual ipv4.addresses 192.168.10.130/24 ipv4.gateway 192.168.10.2 ipv4.dns 114.114.114.114 +ipv4.addresses 192.168.10.129/24
[root@localhost ~]# nmcli connection up ens32
Connection successfully activated (D-Bus active path: /org/freedesktop/NetworkManager/ActiveConnection/2)
第二种方式:
[root@localhost ~]# nmtui
[root@server nginx]# nmcli connection up ens160
[root@node1 ~]# cat /etc/nginx/conf.d/test_ip.conf
server {
listen 192.168.10.129:80;
root /www/ip/129;
location / { #配置/==/www/ip/100下的资源文件
}
}
server {
listen 192.168.10.130:80;
root /www/ip/130;
location / { #配置/==/www/ip/100下的资源文件
index index.html;
}
}
[root@node1 ~]# mkdir /www/ip/{129,130} -pv
mkdir: created directory '/www/ip'
mkdir: created directory '/www/ip/129'
mkdir: created directory '/www/ip/130'
[root@node1 ~]# echo this is 129 > /www/ip/129/index.html
[root@node1 ~]# echo this is 130 > /www/ip/130/index.html
[root@node1 ~]# systemctl restart nginx
[root@node1 ~]# curl 192.168.10.130
this is 130
##################################
1.前提配置 关防火墙 关selinux
2.安装web服务程序nginx
3.当前主机添加多地址(ip a) 注:网段是虚拟默认获取的网段
4.自定义nginx配置文件通过多地址区分多网站
/etc/nginx/conf.d/test_ip.conf
server { #标记为一个虚拟主机
}
5.根据配置在主机创建数据文件
6.重启服务加载配置
7.客户端连接测试
curl
elink
[root@bogon ~]# systemctl restart nginx 配置文件有问题
Job for nginx.service failed because the control process exited with error code.
See “systemctl status nginx.service” and “journalctl -xeu nginx.service” for details.
[root@bogon ~]#
使用cpolar实现内网穿透
- 使用nginx建立网站
- 部署文档:https://dashboard.cpolar.com/get-started
案例二:多端口访问多网站
[root@bogon ~]# nmcli connection modify ens160 +ipv4.addresses 192.168.10.129/24
[root@bogon ~]# nmcli connection up ens160
连接已成功激活(D-Bus 活动路径:/org/freedesktop/NetworkManager/ActiveConnection/3)
[root@node1 ~]# cat /etc/nginx/conf.d/test_port.conf
server {
listen 192.168.10.129:10000;
root /www/port/10000;
location / {
}
}
server {
listen 192.168.10.129:8909;
root /www/port/8909;
location / {
}
}
[root@node1 ~]# echo 8909 > /www/port/8909/index.html
[root@node1 ~]# echo 10000 > /www/port/10000/index.html
[root@node1 ~]# systemctl restart nginx
[root@node1 ~]# curl http://192.168.10.129:8909
8909
案例三:多域名
第一步:
[root@node1 ~]# cat /etc/nginx/conf.d/test_name.conf
server {
listen 192.168.10.129:80;
root /www/name/node1;
server_name www.node1.com;
location / {
}
}
server {
listen 192.168.10.129:80;
root /www/name/node2;
server_name www.node2.com;
location / {
}
}
第二步:
[root@node1 ~]# mkdir -pv /www/name/{node1,node2}
mkdir: created directory '/www/name'
mkdir: created directory '/www/name/node1'
mkdir: created directory '/www/name/node2'
[root@node1 ~]# echo node1 > /www/name/node1/index.html
[root@node1 ~]# echo node2 > /www/name/node2/index.html
[root@node1 ~]# systemctl restart nginx
第三步:
客户端测试windows:C:\Windows\System32\drivers\etc 编辑hosts文件添加本地域名解析信息
ip www.haha.com
通过浏览器http://www.node1.com
linux客户端测试:[root@node1 ~]# vim /etc/hosts
追加写入
192.168.10.129 www.node1.com www.node2.com
[root@node1 ~]# curl www.node1.com
node1
案例四:虚拟目录和用户控制
[root@node1 ~]# cat /etc/nginx/conf.d/test_alias.conf
server {
listen 192.168.10.129:80;
root /www/ip/129;
location /real/ {
alias /openlab/real/;
#alias /www/ip/129/real /openlab/real;
}
}
#当用户访问 192.168.10.129/real/index.html 时,实际在服务器找的路径是 /openlab/real/index.html
[root@node1 ~]# mkdir /openlab/real -pv
[root@node1 ~]# echo this is real > /openlab/real/index.html
[root@node1 ~]# systemctl restart nginx.service
[root@node1 ~]# curl http://192.168.10.129/real/
this is real
############用户认证###########
[root@node1 ~]# cat /etc/nginx/conf.d/test_alias.conf
server {
listen 192.168.10.129:80;
root /www/ip/129;
location /real {
alias /openlab/real/;
auth_basic on;
auth_basic_user_file /etc/nginx/users;
}
}
[root@node1 ~]#yum provides htpasswd
[root@node1 ~]# yum install httpd-tools
[root@node1 ~]# htpasswd -c /etc/nginx/users tom
New password:
Re-type new password:
Adding password for user tom
[root@node1 ~]# systemctl restart nginx
[root@node1 ~]# curl 192.168.10.129/real/ -u tom
Enter host password for user 'tom':
this is real
案例五:https/443
(1)https简介
超文本传输协议HTTP协议被用于在Web浏览器和网站服务器之间传递信息。HTTP协议以明文方式发送内容,不提供任何方式的数据加密,如果攻击者截取了Web浏览器和网站服务器之间的传输报文,就可以直接读懂其中的信息,因此HTTP协议不适合传输一些敏感信息,比如信用卡号、密码等。为了解决HTTP协议的这一缺陷,需要使用另一种协议:安全套接字层超文本传输协议HTTPS。 tcp 443
HTTPS(全称:Hyper Text Transfer Protocol over Secure Socket Layer 或 Hypertext Transfer Protocol Secure,超文本传输安全协议),是以安全为目标的HTTP通道。HTTPS并不是一个新协议,而是HTTP+SSL(TLS)。原本HTTP先和TCP(假定传输层是TCP协议)直接通信,而加了SSL后,就变成HTTP先和SSL通信,再由SSL和TCP通信,相当于SSL被嵌在了HTTP和TCP之间。

SSL 是“Secure Sockets Layer”的缩写,中文叫做“安全套接层”。它是在上世纪90年代中期,由网景公司设计的。到了1999年,SSL 应用广泛,已经成为互联网上的事实标准。IETF 就把SSL 标准化。标准化之后SSL被改为 TLS(Transport Layer Security传输层安全协议)。
SSL协议分为两层:
-
SSL握手协议(SSL Handshake Protocol):它建立在SSL记录协议之上,用于在实际的数据传输开始前,通讯双方进行身份认证、协商加密算法、交换加密密钥等。
-
SSL记录协议 (SSL Record Protocol):它建立在可靠的传输协议(如TCP)之上,为高层协议提供数据封装、压缩、加密等基本功能。
SSL协议提供的服务:
1)认证用户和服务器,确保数据发送到正确的客户机和服务器 防伪装
2)加密数据以防止数据中途被窃取 数据泄露
3)维护数据的完整性,确保数据在传输过程中不被改变 数据篡改
(2)https协议加密所使用的算法
HASH是把任意长度的输入(又叫做预映射pre-image)通过散列算法变换成固定长度的输出,该输出就是散列值。Hash算法特别的地方在于它是一种单向算法,用户可以通过hash算法对目标信息生成一段特定长度的唯一hash值,却不能通过这个hash值重新获得目标信息。因此Hash算法常用在不可还原的密码存储、信息完整性校验等。
常见的HASH算法:MD2、MD4、MD5、HAVAL、SHA、SHA-1、HMAC、HMAC-MD5、HMACSHA1。
共享密钥加密(对称密钥加密):加密和解密使用相同密钥。
对称加密算法:DES、3DES、DESX、Blowfish、IDEA、RC4、RC5、RC6和AES。
公开密钥加密(非对称密钥加密):公开密钥加密使用一对非对称的密钥。一把叫做私有密钥,一把叫做公开密钥。私有密钥不能让其他任何人知道,而公开密钥则可以随意发布,任何人都可以获得。使用此加密方式,发送密文的一方使用公开密钥进行加密处理,对方收到被加密的信息后,再使用自己的私有密钥进行解密。利用这种方式,不需要发送用来解密的私有密钥,也不必担心密钥被攻击者窃听盗走。
常见的非对称加密算法:RSA、ECC(移动设备用)、Diffie-Hellman、El Gamal、DSA(数字签名用)。
但由于公开密钥比共享密钥要慢,所以我们就需要综合一下他们两者的优缺点,使他们共同使用,而这也是HTTPS采用的加密方式。在交换密钥阶段使用公开密钥加密方式,之后建立通信交换报文阶段则使用共享密钥加密方式。
如何证明公开密钥本身是货真价实的公开密钥?如,正准备和某台服务器建立公开密钥加密方式下的通信时,如何证明收到的公开密钥就是原本预想的那台服务器发行的公开密钥。或许在公开密钥传输过程中,真正的公开密钥已经被攻击者替换掉了。这个时候就需要第三方公证单位来帮忙啦。
对称加密
我的理解是: 首先我们需要协商使用什么算法(AES), 接着我们通过相同的密钥对数据进行加密即可实现:明文 + 密钥 ==> 密文 密文 + 密钥 ==> 明文。由此我们可以看出, 都使用相同的密钥,一旦密钥泄露, 那么数据相当于公开。 优点: 效率高。 改进:能不能提前把密钥加密,只能由服务端才能解密。
非对称加密
是网络通信的基石, 保证了非对称加密 密钥的安全。 首先, 非对称加密需要 私钥 和 公钥, 公钥加密的数据只能由私钥解开, 而私钥加密的数据只能由公钥解开。 公钥存储在客服端, 私钥存储在服务端, 永远不对外暴漏。
流程:首先客服端请求公钥, 服务端响应公钥, 之后客服端通过公钥加密数据传输, 服务端通过私钥解密获取信息。
存在的安全隐患: 我们的公钥是直接进行传输的, 那么黑客就可以得到我们的公钥从而获取信息。
非对称加密 + 对称加密
客服端请求公钥响应后, 客服端通过公钥可以加密一串随机数,作为以后信息传输对称加密的密钥, 而这串随机数也只能由服务端的私钥才能解析。
服务端通过私钥解析后, 通过对称加密对数据进行加密。
问题: 假如在客服端请求公钥的时候, 就被黑客拦截, 充当了服务器, 给了黑客的公钥给客服端, 此问题产生的主要原因是: 报文可能被篡改, 客服端完全相信服务端!
加密技术:公钥加密, 私钥解密
签名技术: 公钥解密, 私钥加密
数字签名 解决报文被篡改
数字签名(又称公钥数字签名)是只有信息的发送者才能产生的别人无法伪造的一段数字串,这段数字串同时也是对信息的发送者发送信息真实性的一个有效证明。
(1). 能确定消息确实是由发送方签名并发出来的,因为别人假冒不了发送方的签名。
(2). 数字签名能确定消息的完整性 , 证明数据是否未被篡改过。
发送者将数据先于hash算法生成信息摘要, 然后用私钥加密生成数字签名, 一起发送给接收方。
接收方只有用发送者的公钥才能解密被加密的数据, 然后通过hash对原文参数一个摘要信息, 进行比对, 即可确认报文是否被篡改。
问题: 我们的公钥还是不安全的在网络中传输, 解决证书
证书 解决服务端身份问题
有专门的机构进行颁发, 而证书中包含了你的公钥, 同时包含数字签名
此后我们请求公钥改为请求证书, 如何保证不会得到一个假证书了! 我们CA机构在已把证书嵌套在了浏览器以及操作系统, 所以证书都不用经过网络自然不会出现假的。
1.请求连接,tcp三次握手 确认版本
2.秘钥套件的协商,开始身份认证(非对称算法)证书验证 协商对称算法[客户端验证服务器身份]
3.建立ssl 会话链接
4.加密会话交互
5.断开会话链接
TLS完整的通信流程
第一阶:段客户端端申请建立https连接

第二阶段:客户端和服务器确认加密版本,加密套件

1.浏览器向服务器发送一个clientHello的报文

客户端产生一个随机数Random(ClientRandom)
会话ID:第一次肯定为空
Cipher suite: 加密套件(秘钥交换,完整性校验算法,对称机密算法 ,算法列表)
2.服务端向客户端回复一个ServerHello(确认使用的TLS的版本,以及加密套件)
Random随机数:服务产生的(ServerRandom)
SessionID: 0
Cipher suite:确认使用加密套件
Compression method: null 不压缩
Extension: 扩展字段
第三阶段:证书发送验证 (客户端验证证书取出公钥,用公钥加密生成的对称秘钥发送个服务器通知改变加密信息传递)
3.服务器向客户端发送Certificate (服务器的身份证,证书由第三方权威机构颁发)
4.服务器向客户端发送serverkey Exchange(通过和客户端协商的密码算法套件发送Pubkey结合HD算法生成Premastersecret(最终加密的会话秘钥))
5.certificate Request 可选报文(认证可以是单向也可以是双向,一般都是单向客户端验证服务端身份,服务端验证客户端客户端也需要发送证书)
6.ServerHello Done 服务端发送握手信息完毕
7.客户端回复服务器报文Certificate 如果有第五阶段则提交客户端的证书进行认证

8.ClientKey Exchange 秘钥交换信息和步骤4类似
9.ChangeCiper Spec: 通知消息(消息改变通知,及后面消息要进行加密了)
10.Encrypted Handshake Messges 校验数据包的完整性MD5(hash)将数据包的值进行散列最后和服务端的散列值进行比较一致意味着沟通过程中没有第三者的介入
第四阶段:服务收到消息,用私钥解密取,确认对称秘钥通知客户端ssl通道建立完成

11.服务器向客户端回包:NewSession Ticket(建立会话票据,提供会话票据)
12.change cipher Spec: 改变密码通知加密发送信息
13.encrypted Handshake message (Finished)
第五阶段:客户端和服务端可以通过加密通道开始数据通信

Application Data(http)客户端和服务端可以通过加密通道开始数据通信
第六阶段:客户端断开连接
Encrypted Alert

秘钥交换的大概过程:
ClientHello客户端产生一个随机数C,Serverhello服务端产生一个随机数S--公开, 还需要一个随机数(加密)
serverhello过程中发送serverkeyexchange发送公钥pubkey给客户端
客户端通过clientkeychange发送通过pubkey加密的随机数Pre_master
服务端对客户端的发送的加密Pre_master进行解密
最终客户端和服务端各自掌握了三个随机数利用复杂的交换算法进行计算协商出彼此的对称秘钥
注:
TLS1.3 提供 1-RTT 的握手机制,还是以 ECDHE 密钥交换过程为例,握手过程如下。将客户端发送 ECDH 临时公钥的过程提前到 ClientHello ,同时删除了 ChangeCipherSpec 协议简化握手过程,使第一次握手时只需要1-RTT,来看具体的流程:
• 客户端发送 ClientHello 消息,该消息主要包括客户端支持的协议版本、DH密钥交换参数列表KeyShare;
• 服务端回复 ServerHello,包含选定的加密套件;发送证书给客户端;使用证书对应的私钥对握手消息签名,将结果发送给客户端;选用客户端提供的参数生成 ECDH 临时公钥,结合选定的 DH 参数计算出用于加密 HTTP 消息的共享密钥;服务端生成的临时公钥通过 KeyShare 消息发送给客户端;
• 客户端接收到 KeyShare 消息后,使用证书公钥进行签名验证,获取服务器端的 ECDH 临时公钥,生成会话所需要的共享密钥;
• 双方使用生成的共享密钥对消息加密传输,保证消息安全。
x509 .key .csr .crt
#key是私钥文件
#crt是由证书颁发机构(CA)签名后的证书,或者是开发者自签名的证书,包含证书持有人的信息,持有人的公钥,以及签署者的签名等信息
[root@www certs]# openssl req -utf8 -new -key jiami.key -x509 -days 100 -out jiami.crt
------------------------------------------------RHEL7--------------------------------
(第一种) [root@localhost certs]# make jiami.crt
-------------------------------------------------------------------------------------
!!!!!!!注意!!!!!!!!!!!!!!!!
(第二种) #openssl req -newkey rsa:4096 -nodes -sha256 -keyout haha.key -x509 -days 365 -out haha.crt
----------------------------------------------x509 key csr crt-----------------------
[root@www certs]# openssl genrsa 2048 > openlab.key
(第三种) #openssl req -utf8 -new -key openlab.key -x509 -days 365 -out openlab.crt
---------------------------------------------------------------------------------
x509 ---- .key私钥文件 .crs 未签名的证书文件 .crt 签名后的证书
[root@node1 ~]# vim /etc/nginx/conf.d/test_https.conf
[root@node1 ~]# cat /etc/nginx/conf.d/test_https.conf
server {
listen 192.168.10.129:443 ssl http2 ;
root /www/https;
ssl_certificate /etc/pki/tls/certs/openlab.crt;
ssl_certificate_key /etc/pki/tls/private/openlab.key;
location / {
}
}
[root@node1 ~]# mkdir /www/https
[root@node1 ~]# echo this is https > /www/https/index.html
root@node1 ~]# openssl genrsa -out /etc/pki/tls/private/openlab.key
[root@node1 ~]# openssl req -utf8 -new -key /etc/pki/tls/private/openlab.key -x509 -days 365 -out /etc/pki/tls/certs/openlab.crt
You are about to be asked to enter information that will be incorporated
into your certificate request.
What you are about to enter is what is called a Distinguished Name or a DN.
There are quite a few fields but you can leave some blank
For some fields there will be a default value,
If you enter '.', the field will be left blank.
-----
Country Name (2 letter code) [XX]:86
State or Province Name (full name) []:xi'an
Locality Name (eg, city) [Default City]:shannxi
Organization Name (eg, company) [Default Company Ltd]:open
Organizational Unit Name (eg, section) []:ce
Common Name (eg, your name or your server's hostname) []:local
Email Address []:admin
[root@node1 ~]# systemctl restart nginx
[root@node1 ~]# curl https://192.168.10.129
curl: (60) SSL certificate problem: self-signed certificate
More details here: https://curl.se/docs/sslcerts.html
curl failed to verify the legitimacy of the server and therefore could not
establish a secure connection to it. To learn more about this situation and
how to fix it, please visit the web page mentioned above.
[root@node1 ~]# curl https://192.168.10.129 -k
this is https
案例六:动态网站LAMP lnmp
[root@node1 ~]# echo "<?php phpinfo(); ?>" > /usr/share/nginx/html/index.php
[root@node1 ~]# nmcli connection modify ens160 +ipv4.addresses 192.168.10.131/24
[root@node1 ~]# nmcli connection up ens160
Connection successfully activated (D-Bus active path: /org/freedesktop/NetworkManager/ActiveConnection/3)
补充:
自定义php界面配置解析
#vim /etc/nginx/test_php.conf
server {
listen 192.168.10.131:80;
root /www;
location = / {
root /www;
fastcgi_pass unix:/run/php-fpm/www.sock;
fastcgi_index index.php;
fastcgi_param SCRIPT_FILENAME $document_root$fastcgi_script_name;
include fastcgi_params;
}
}
#它指定了 FastCGI 后端服务器(这里是 PHP - FPM)的位置。 php-fpm 9000
#当请求的是一个目录时,在这个目录下寻找index.php文件作为默认的处理脚本,并将请求传递给 FastCGI 后端(如 PHP - FPM)来处理这个index.php文件。
#告诉 FastCGI 后端(如 PHP - FPM)要执行的脚本文件的完整路径
#包含一个名为fastcgi_params的文件。这个文件通常包含了一系列的通用 FastCGI 参数设置。这些参数定义了如何将 Nginx 中的请求信息(如请求方法、请求头、客户端 IP 等)传递给 FastCGI 后端。
echo "<?php phpinfo(); ?>" > /www/index.php
案例七:autoindex on;当不存在网页文件时实现文件共享
[root@node1 conf.d]# cat ./test_ip.conf
server {
listen 192.168.10.130:80;
root /www/ip/130;
location / { #配置/==/www/ip/100下的资源文件
autoindex on; # 增加内容
}
}
[root@node1 conf.d]# mv /www/ip/130/index.html{,.bak}
[root@node1 conf.d]# touch /www/ip/130/{1,2,3,4}
[root@node1 conf.d]# systemctl restart nginx
文件传输方式
***scp rsync
http https
sftp------xftp
lrzsz rz sz
第五章 nfs服务器
1、简介
NFS(Network File System,网络文件系统)是FreeBSD支持的文件系统中的一种,它允许网络中的计算机(不同的计算机、不同的操作系统)之间通过TCP/IP网络共享资源,主要在unix系列操作系统上使用。在NFS的应用中,本地NFS的客户端应用可以透明地读写位于远端NFS服务器上的文件,就像访问本地文件一样。

NFS服务器可以让PC将网络中的NFS服务器共享的目录挂载到本地端的文件系统中,而在本地端的系统中看来,那个远程主机的目录就好像是自己的一个磁盘分区一样。
由于NFS支持的功能比较多,而不同的功能都会使用不同的程序来启动,每启动一个功能就会启用一些端口来传输数据,因此NFS的功能所对应的端口并不固定,而是随机取用一些未被使用的小于1024的端口用于传输。但如此一来就会产生客户端连接服务器的问题,因为客户端需要知道服务器端的相关端口才能够连接。
此时就需要RPC(Remote Procedure Call,远程过程调用)的服务。由于当服务器在启动NFS时会随机选取数个端口号,并主动向RPC注册,所以RPC知道每个NFS功能所对应的端口号,RPC将端口号通知给客户端,让客户端可以连接到正确的端口上去。RPC采用固定端口号port 111来监听客户端的需求并向客户端响应正确的端口号。
注:在启动NFS之前,要先启动RPC,否则NFS会无法向RPC注册。另外,RPC若重新启动,原来注册的数据会消失不见,因此RPC重启后,它管理的所有服务都需要重新启动以重新向RPC注册。
2、nfs配置
案例一:nfs共享文件
[root@localhost ~]# dnf install nfs-utils
#systemctl stop firewalld
#setenforce 0
#systemctl start nfs-server
#服务端(192.168.168.128)
[root@server public]# vim /etc/exports
/pub *(ro)
#共享目录 主机名(权限)
#可以使用完整的IP或者是网络号,例如172.24.8.128或172.24.8.0/24或者172.24.8.128/255.255.255.0;也可以使用*表示所有主机
#权限相关参数可以写多个,多个参数之间用逗号隔开,具体相关参数说明如下:
[root@server ~]# mkdir /pub
[root@server ~]# touch /pub/{1..10}
[root@server public]# exportfs -ra
Client
#dnf install nfs-utils -y
#mkdir /p
#mount 192.168.10.135:/public /p
------------------------------------------
#showmount -e 192.168.10.135 查看共享的文件系统
注:client 管理员root访问nfs文件系统默认做了用户映射root --nobody(65534)
#mount -o remount,ro /nfs
#mount -o ro 192.168.10.130:/public /nfs
注:
一个挂载点目录可以同时挂载多个文件系统,通过挂载点查看是最后一次挂载文件系统中的数据文件。
| 参数值 | 说明 |
|---|---|
| rw,ro | 该目录共享的权限是可读写还是只读,但最终能否读写,还是与 文件系统的rwx有关 |
| sync,async | sync代表数据会同步写入到内存与硬盘中,async则代表数据会 先暂存于内存当中,而非直接写入硬盘 |
| no_root_squash root_squash | 若客户端在共享目录里创建的文件的所属者和所属组是root用户 和root组,那么显示文件的属主和属组时有以下两种情况: no_root_squash表示,文件的所属者和所属组是root用户和 root组;root_squash表示将root用户和组映射为匿名用户和组 (默认设置)。 |
| all_squash no_all_squash | all_squash:客户端所有用户创建文件时,客户端会将文件的用户 和组映射为匿名用户和组no_all_squash:客户端普通用户创建的 文件的UID和GID是多少,服务端就显示为多少(默认设置) |
| anonuid= anongid= | 将文件的用户和组映射为指定的UID和GID,若不指定默认为 65534(nfsnobody) |
[root@server data]# chmod o+w /data/
[root@server data]# systemctl disable firewalld --now
[root@server data]# getenforce
Enforcing
[root@server data]# setenforce 0
[root@server data]# systemctl restart nfs-server
[root@server data]# showmount -e 192.168.168.128
Export list for 192.168.168.128:
/data 192.168.168.140
#客户端(192.168.168.140)
[root@client ~]# showmount -e 192.168.168.128
Export list for 192.168.168.128:
/data 192.168.168.140
[root@client ~]# mkdir -p /nfsclient/client-data/
[root@client ~]# mount 192.168.168.128:/data /nfsclient/client-data/
[root@client ~]# df -h
Filesystem Size Used Avail Use% Mounted on
devtmpfs 898M 0 898M 0% /dev
tmpfs 910M 0 910M 0% /dev/shm
tmpfs 910M 9.6M 901M 2% /run
tmpfs 910M 0 910M 0% /sys/fs/cgroup
/dev/mapper/centos-root 37G 1.8G 36G 5% /
/dev/sda1 1014M 150M 865M 15% /boot
tmpfs 182M 0 182M 0% /run/user/0
192.168.168.128:/data 40G 6.2G 34G 16% /nfsclient/client-data
架设一台NFS服务器,并按照以下要求配置
1、开放/nfs/shared目录,供所有用户查询资料
2、开放/nfs/upload目录,为192.168.xxx.0/24网段主机可以上传目录,
并将所有用户及所属的组映射为nfs-upload,其UID和GID均为210
3、将/home/tom目录仅共享给192.168.xxx.xxx这台主机,并只有用户tom对该目录有读写权限
回顾开机自动挂载:
#vim /etc/fstab
.....
#文件系统名名称 挂载点目录 格式化类型 默认参数 开机是否备份 开机是否检查
172.25.250.132:/test /t nfs4 defaults 0 0
/dev/sr0 /mnt iso9660 defaults 0 0
#mount -a #加载/etc/fstab文件中的文件系统在当前主机状态下挂载(检测是否配置有问题)
3、配置autofs自动挂载
在一般NFS文件系统的使用过程中,如果客户端要使用服务端所提供的文件系统,可以在 /etc/rc.d/rc.local 中设置开机时自动挂载( /etc/rc.d/rc.local 文件中写入的命令,在每次启动系统用户登录之前都会执行一次);也可以在登录系统后手动利用mount来挂载。
由于网络的问题,NFS服务器与客户端的连接不会一直存在,当我们挂载了NFS服务器之后,任何一方脱机都可能造成另外一方等待超时。为了解决这样的问题,就出现了下面的想法:
- 当客户端在有使用NFS文件系统的需求时才让系统自动挂载。
- 当NFS文件系统使用完毕后,让NFS自动卸载。
于是就产生了autofs这个服务。
autofs这个服务是在客户端的上面,它会持续的检测某个指定的目录,并预先设置当使用到该目录的某个子目录时,将会取得来自服务器端的NFS文件系统资源,并进行自动挂载的操作。
#客户端配置autofs
[root@client ~]# yum install autofs -y
[root@client ~]# grep suibian /etc/auto.master
/client /etc/auto.suibian
#本地端目录 具体挂载配置文件
[root@client ~]# cat /etc/auto.suibian
upload 192.168.168.128:/nfs/upload
#本地端子目录 挂载参数 服务器:服务器对应目录
[root@client ~]# systemctl restart autofs
#触发自动挂载
[root@client ~]# cd /client
[root@client ~]# cd upload
[root@bogon ~]# cat /etc/nginx/conf.d/nextcloud.conf
server {
listen 80;
root /var/www/html/nextcloud;
location / {
try_files $uri u r i / / i n d e x . p h p ? uri/ /index.php? uri//index.php?query_string;
}
location ~ ^/(?:build|tests|config|lib|3rdparty|templates|data)/ {
deny all;
}
location ~ ^/(?:.|autotest|occ|issue|indie|db_|console) {
deny all;
}
location ~ .php(?:$|/) {
fastcgi_split_path_info ^(.+.php)(/.+)$;
include fastcgi_params;
fastcgi_param SCRIPT_FILENAME d o c u m e n t r o o t document_root documentrootfastcgi_script_name;
fastcgi_param PATH_INFO $fastcgi_path_info;
fastcgi_pass unix:/run/php-fpm/www.sock;
}
}
-----------------------------------------------------
确保服务器的时间准备性,如果和实际偏差比较大会导致安全链接问题,影响应用商店访问
确认php.int文件中的参数限制内存限制和执行时间限制
Vim /etc/php.ini
Memory_limit = 512M
Max_execution_time = 300;
第六章 DNS域名解析服务器 hosts
概述
产生原因
-
IP 地址:是互联网上计算机唯一的逻辑地址,通过 IP 地址实现不同计算机之间的相互通信,每台联网计算机都需要通过 IP 地址来互相联系和分别,但由于 IP 地址是由一串容易混淆的数字串构成,人们很难记忆所有计算机的 IP 地址,这样对于我们日常工作生活访问不同网站是很困难的。
-
基于这种背景,人们在 IP 地址的基础上又发展出了一种更易识别的符号化标识,这种标识由人们自行选择的字母和数字构成,相比 IP 地址更易被识别和记忆,逐渐代替 IP 地址成为互联网用户进行访问互联的主要入口。这种符号化标识就是域名
-
域名虽然更易被用户所接受和使用,但计算机只能识别纯数字构成的 IP 地址,不能直接读取域名。因此要想达到访问效果,就需要将域名翻译成 IP 地址。而 DNS 域名解析承担的就是这种翻译效果
作用:
-
DNS(Domain Name System)是互联网上的一项服务,用于将域名和IP地址进行相互映射,使人更方便的访问互联网
-
正向解析:域名->IP
-
反向解析:IP->域名
连接方式
-
DNS使用53端口监听网络
-
查看方法:
-
DNS默认以UDP这个较快速的数据传输协议来查询,但没有查询到完整的信息时,就会再次以TCP协议重新查询则启动DNS时,会同时启动TCP以及UDP的port53
因特网的域名结构
拓扑:
- 由于因特网的用户数量较多,则因特网命名时采用层次树状结构的命名方法。
- 域名(domain name):任何一个连接在因特网上的主机或路由器,都有一个唯一的层次结构的名称
- 域(domain):是名字空间中一个可被管理的划分结构。
- 注意:域名只是逻辑概念,并不代表计算机所在的物理地点
分类
-
国家顶级域名:采用ISO3166的规定,如:cn代表中国,us代表美国,uk代表英国,等等。国家域名又常记为CCTLD(country code top-level domains,cc表示国家代码contry-code)
-
通用顶级域名:最常见的通用顶级域名有7个
- com (公司企业)
- net (网络服务机构)
- org (非营利组织)
- int (国际组织)
- gov (美国的政府部门)
- mil (美国的军事部门)
- edu(教育机构)
-
基础结构域名(infrastructure domain):这种顶级域名只有一个,即arpa,用于反向域名解析,因此称为反向域名
域名服务器类型划分
- 组织架构:

- 根域名服务器:最高层次的域名服务器,所有的根域名服务器都知道所有的顶级域名服务器的域名和IP地址。本地域名服务器要对因特网上任何一个域名进行解析,只要自己无法解析,就首先求助根域名服务器。则根域名服务器是最重要的域名服务器。假定所有的根域名服务器都瘫痪了,那么整个DNS系统就无法工作。所以根域名服务器并不直接把待查询的域名直接解析出IP地址,而是告诉本地域名服务器下一步应当找哪一个顶级域名服务器进行查询。

-
在与现有IPv4根服务器体系架构充分兼容基础上,由我国下一代互联网国家工程中心领衔发起的“雪人计划”于2016年在美国、日本、印度、俄罗斯、德国、法国等全球16个国家完成25台IPv6(互联网协议第六版)根服务器架设,事实上形成了13台原有根加25台IPv6根的新格局,为建立多边、民主、透明的国际互联网治理体系打下坚实基础。中国部署了其中的4台,由1台主根服务器和3台辅根服务器组成,打破了中国过去没有根服务器的困境。
-
顶级域名服务器:负责管理在该顶级域名服务器注册的二级域名
-
权威域名服务器:负责一个“区”的域名服务器
-
本地域名服务器:本地域名服务器不属于域名服务器的层次结构,当主机发出DNS查询时,这个查询报文就发送给本地域名服务器
-
为了提高域名服务器的可靠性,DNS域名服务器都把数据复制到几个域名服务器来保存,如:
- 主服务器:在特定区域内具有唯一性,负责维护该区域内的域名与 IP 地址之间的对应关系(真正干活的)
- 从服务器:从主服务器中获得域名与 IP 地址的对应关系并进行维护,以防主服务器宕机等情况(打下手的)
- 缓存服务器:通过向其他域名解析服务器查询获得域名与 IP 地址的对应关系,并将经常查询的域名信息保存到服务器本地,以此来提高重复查询时的效率,一般部署在企业内网的网关位置,用于加速用户的域名查询请求
DNS域名解析过程
分类:
-
递归解析:DNS 服务器在收到用户发起的请求时,必须向用户返回一个准确的查询结果。如果 DNS 服务器本地没有存储与之对应的信息,则该服务器需要询问其他服务器,并将返回的查询结果提交给用户
-
迭代解析(反复):DNS 服务器在收到用户发起的请求时,并不直接回复查询结果,而是告诉另一台 DNS 服务器的地址,用户再向这台 DNS 服务器提交请求,依次反复,直到返回查询结果
解析图:
图:

过程分析
- 第一步:在浏览器中输入www . google .com 域名,本地电脑会检查浏览器缓存中有没有这个域名对应的解析过的 IP 地址,如果缓存中有,这个解析过程就结束。浏览器缓存域名也是有限制的,不仅浏览器缓存大小有限制,而且缓存的时间也有限制,通常情况下为几分钟到几小时不等,域名被缓存的时间限制可以通过 TTL 属性来设置。这个缓存时间太长和太短都不太好,如果时间太长,一旦域名被解析到的 IP 有变化,会导致被客户端缓存的域名无法解析到变化后的 IP 地址,以致该域名不能正常解析,这段时间内有一部分用户无法访问网站。如果设置时间太短,会导致用户每次访问网站都要重新解析一次域名
- 第二步:如果浏览器缓存中没有数据,浏览器会查找操作系统缓存中是否有这个域名对应的 DNS 解析结果。其实操作系统也有一个[域名解析]的过程,在 Linux 中可以通过 / etc/hosts 文件来设置,而在 windows 中可以通过配置 C:\Windows\System32\drivers\etc\hosts 文件来设置,用户可以将任何域名解析到任何能够访问的 IP 地址。例如,我们在测试时可以将一个域名解析到一台测试服务器上,这样不用修改任何代码就能测试到单独服务器上的代码的业务逻辑是否正确。正是因为有这种本地 DNS 解析的规程,所以有黑客就可能通过修改用户的域名来把特定的域名解析到他指定的 IP 地址上,导致这些域名被劫持
- 第三步:前两步是在本地电脑上完成的,若无法解析时,就要用到我们网络配置中的 “DNS 服务器地址” 了。操作系统会把这个域名发送给这个本地 DNS 服务器。每个完整的内网通常都会配置本地 DNS 服务器,例如用户是在学校或工作单位接入互联网,那么用户的本地 DNS 服务器肯定在学校或工作单位里面。它们一般都会缓存域名解析结果,当然缓存时间是受到域名的失效时间控制的。大约 80% 的域名解析到这里就结束了,后续的 DNS 迭代和递归也是由本地 DNS 服务器负责
- 第四步:如果本地 DNS 服务器仍然没有命中,就直接到根 DNS 服务器请求解析
- 第五步:根 DNS 服务器返回给本地 DNS 域名服务器一个顶级 DNS 服务器地址,它是国际顶级域名服务器,如. com、.cn、.org 等,全球只有 13 台左右
- 第六步:本地 DNS 服务器再向上一步获得的顶级 DNS 服务器发送解析请求
- 第七步:接受请求的顶级 DNS 服务器查找并返回此域名对应的 Name Server 域名服务器的地址,这个 Name Server 服务器就是我要访问的网站域名提供商的服务器,其实该域名的解析任务就是由域名提供商的服务器来完成。 比如我要访问 www.baidu.com,而这个域名是从 A 公司注册获得的,那么 A 公司上的服务器就会有 www.baidu.com 的相关信息
- 第八步:返回该域名对应的 IP 和 TTL 值,本地 DNS 服务器会缓存这个域名和 IP 的对应关系,缓存时间由 TTL 值控制
- 第九步:Name Server 服务器收到查询请求后再其数据库中进行查询,找到映射关系后将其IP地址返回给本地DNS服务器
- 第十步:本地DNS服务器把解析的结果返回给本地电脑,本地电脑根据 TTL 值缓存在本地系统缓存中,域名解析过程结束在实际的 DNS 解析过程中,可能还不止这 10 步,如 Name Server 可能有很多级,或者有一个 GTM 来负载均衡控制,这都有可能会影响域名解析过程
- 注意:
- 从客户端到本地DNS服务器是属于递归查询,而DNS服务器之间使用的交互查询就是迭代查询
- 114.114.114.114是国内移动、电信和联通通用的DNS,手机和电脑端都可以使用,干净无广告,解析成功率相对来说更高,国内用户使用的比较多,而且速度相对快、稳定,是国内用户上网常用的DNS。
- 223.5.5.5和223.6.6.6是阿里提供的免费域名解析服务器地址
- 8.8.8.8是GOOGLE公司提供的DNS,该地址是全球通用的,相对来说,更适合国外以及访问国外网站的用户使用
搭建DNS域名解析服务器
概述
- BIND:Berkeley Internet Name Domain ,伯克利因特网域名解析服务是一种全球使用最广泛的、最高效的、最安全的域名解析服务程序
安装软件
[root@server ~]# yum install bind -y
bind服务中三个关键文件
-
/etc/named.conf : 主配置文件,共59行,去除注释和空行之和有效行数仅30行左右,用于设置bind服务程序的运行
-
/etc/named.rfc1912.zones : 区域配置文件(zone),用于保存域名和IP地址对应关系文件的所在位置,类似于图书目录,当需要修改域名与IP映射关系时需要在此文件中查找相关文件位置
-
/var/named 目录:数据配置文件目录,该目录存储保存域名和IP地址映射关系的数据文件
主配置文件分析
-
主配置文件共4部分组成
- options{}
- logging{}
- zone{}
- include
-
常用参数:
[root@server ~]# vim /etc/named.conf
options { # 全局参数设置
listen-on port 53 { 127.0.0.1; }; # 重要,监听允许访问的ip与端口,可以使用IP地址、网段、所有主机(any)
listen-on-v6 port 53 { ::1; };# 重要,监听允许访问的ipV6与端口
directory "/var/named"; # DNS数据目录位置,默认即可
dump-file "/var/named/data/cache_dump.db"; # 默认缓存文件位置,默认即可
statistics-file "/var/named/data/named_stats.txt"; # DNS状态文件保存文件,默认即可
memstatistics-file "/var/named/data/named_mem_stats.txt"; # 内存状态文件保存文件,默认即可
secroots-file "/var/named/data/named.secroots"; # 安全根服务器保存位置,默认即可
recursing-file "/var/named/data/named.recursing"; # 递归查询文件保存位置,默认即可
allow-query { localhost; }; # 重要,表示允许那些客户端进行访问,可以书写IP地址、网段、所有主机(any)
recursion yes; # 重要,允许递归查询,若删除则为迭代查询
dnssec-validation yes; # 开启加密,默认即可
managed-keys-directory "/var/named/dynamic"; # 指定目录中文件保存位置,用于管理密钥(DNSSEC)
pid-file "/run/named/named.pid"; # pid文件保存路径,默认即可
session-keyfile "/run/named/session.key"; # 会话密钥存储路径,自动生成,默认即可
logging { # 指定日志记录的分类及其存储目录
channel default_debug { # 设置日志输出方式
file "data/named.run"; # 产生日志信息文件的位置
severity dynamic; # 日志级别
};
};
zone "." IN { # zone 表示区域, "." 表示根,此处设置DNS根服务器的相关内容
type hint; # 表示服务器的类型为根
file "named.ca"; # 用于保存dns根服务器信息的文件,存储路径/var/named/named.ca,一共有13台ipv4和13台ipv6根服务器信息
};
include "/etc/named.rfc1912.zones"; # 表示当前DNS服务器的区域配置文件位置
include "/etc/named.root.key"; # 密钥存储文件位置
- 一般需要修改三部分:
- listen-on port 53 { 127.0.0.1; }; 即监听ip及端口
- allow-query { localhost; }; 允许那些客户端访问
- recursion yes; 是否开启递归查询
区域配置文件
作用:
- /etc/named.rfc1912.zones文件为bind服务程序的区域配置文件,用来保存域名与IP地址映射关系文件的位置,是一系列功能模板的集合
区域配置文件示例分析
- 正向解析
zone "localhost.localdomain" IN { # 正向解析域名
type master; # 服务类型:master表示主服务器,slave表示从服务器,hint根服务器
file "named.localhost"; # 域名与IP地址规则文件存储位置
allow-update { none; }; # 允许那些客户端动态更新本机域名解析
};
# allow-update:允许更新解析库内容,一般关闭
# allow-query: 允许查询的主机,白名单
# allow-tranfter : 允许同步的主机,白名单,常用
# allow-recursion: 允许递归的主机
- 反向解析:
zone "1.0.0.127.in-addr.arpa" IN { # 表示127.0.0.1的反向解析配置,IP地址需要倒置书写,只需书写网段即可
type master;
file "named.loopback"; # 反向解析的规则文件保存位置
allow-update { none; };
};
正向解析资源文件
概述:
- 查看:
[root@server ~]# vim /var/named/named.localhost
- 注意:推荐对该模板文件进行局部修改
模板内容分析:
$TTL 1D # 设置生存周期时间,为1天,$表示宏定义
@ IN SOA @ rname.invalid. (
# @ :表示zone域,现在表示域名,如baidu.com
# IN SOA : 授权信息开始
# rname.invalid. : 域名管理员的邮箱(不能使用@,使用点替代邮件分隔符@)
0 ; serial # 序列号,10位以内的整数
1D ; refresh # 更新频率为1天
1H ; retry # 失败重试时间为1小时
1W ; expire # 失效时间1周
3H ) ; minimum # 缓存时间为3小时
IN NS ns.域名.
ns IN A 域名解析服务器IP地址
www IN A 域名解析服务器IP地址
bbs IN A 域名解析服务器IP地址
mail IN A 域名解析服务器IP地址
# A:表示IPv4地址, AAAA表示IPv6地址

域名解析记录分析
域名解析记录分析
- A记录:A 代表 Address,用来指定域名对应的 IP 地址,如将 item.taobao.com 指定到 115.238.23.xxx,将 switch.taobao.com 指定到 121.14.24.xxx
- MX记录:Mail Exchange,就是可以将某个域名下的邮件服务器指向自己的 Mail Server,如 taobao.com 域名的 A 记录 IP 地址是 115.238.25.xxx,如果将 MX 记录设置为 115.238.25.xxx,即 xxx@taobao.com 的邮件路由,DNS 会将邮件发送到 115.238.25.xxx 所在的服务器,而正常通过 Web 请求的话仍然解析到 A 记录的 IP 地址
- NS记录:为某个域名指定 DNS 解析服务器,也就是这个域名由指定的 IP 地址的 DNS 服务器取解析
- CNAME 记录:Canonical Name,即别名解析。所谓别名解析就是可以为一个域名设置一个或者多个别名,如将 aaa.com 解析到 bbb.net、将 ccc.com 也解析到 bbb.net,其中 bbb.net 分别是 aaa.com 和 ccc.com 的别名
- TXT 记录:为某个主机名或域名设置说明,如可以为 ddd.net 设置 TXT 记录为 “这是 XXX 的博客” 这样的说明
反向解析资源文件
[root@server ~]# vim /var/named/named.loopback
$TTL 1D
@ IN SOA @ rname.invalid. (
0 ; serial
1D ; refresh
1H ; retry
1W ; expire
3H ) ; minimum
IN NS ns.域名. # 域名服务器记录,注意结尾的点
ns IN A 域名解析服务器的IP地址
IP地址 PTR 域名. # PTR 指针记录,用于反向解析
实验1:正向解析
| 服务端IP | 客户端IP | 网址 |
|---|---|---|
| 192.168.48.130 | 192.168.48.131 | www.openlab.com |
准备工作
# 服务端及客户端都关闭安全软件
[root@server ~]# setenforce 0
[root@server ~]# systemctl stop firewalld
# 服务端安装bind软件
[root@server ~]# yum install bind -y
# 服务端配置静态IP
[root@server ~]# nmcli c modify ens32 ipv4.method manual ipv4.addresses 192.168.48.130/24 ipv4.gateway 192.168.48.2 ipv4.dns 114.114.114.114
[root@server ~]# nmcli c reload
[root@server ~]# nmcli c up ens32
连接已成功激活(D-Bus 活动路径:/org/freedesktop/NetworkManager/ActiveConnection/2)
# 客户端设置静态IP
[root@node1 ~]# nmcli c modify ens32 ipv4.method manual ipv4.addresses 192.168.48.131/24 ipv4.gateway 192.168.48.2 ipv4.dns 114.114.114.114
[root@node1 ~]# nmcli c reload
[root@node1 ~]# nmcli c up ens32
连接已成功激活(D-Bus 活动路径:/org/freedesktop/NetworkManager/Act
DNS配置
- 第一步:服务端操作,编辑bind主配置文件
[root@server ~]# vim /etc/named.conf
# 需改2行
listen-on port 53 { any; }; # any为允许所有主机
allow-query { any; };
- 第二步:服务端操作,编辑区域配置文件,可以选择一个模版修改局部(推荐),也可以全部清空重启写入数据
[root@server ~]# vim /etc/named.rfc1912.zones
zone "openlab.com" IN { # 双引号中输入,表示管理那个区域
type master;
file "openlab.com.zone"; # 双引号中输入,表示数据配置文件的名称,注意:不写路径
allow-update { none; };
};
- 第三步:服务端操作,编辑数据配置文件,使用拷贝命令将模版文件(/var/named/named.localhost)复制一份在修改局部,注意:拷贝时需要加-a参数,即拷贝内容及文件属性保证文件内容一致、权限等信息不变
[root@server ~]# cd /var/named # 切换到数据配置文件存储路径
[root@server named]# ls
data dynamic named.ca named.empty named.localhost named.loopback slaves
[root@server named]# cp -a named.localhost openlab.com.zone # -a 完整拷贝
[root@server named]# vim openlab.com.zone # 完整格式修改如下
$TTL 1D
openlab.com. IN SOA ns.opeblab.com. admin.openlab.com. (
0 ; serial
1D ; refresh
1H ; retry
1W ; expire
3H ) ; minimum
openlab.com. IN NS ns.openlab.com.
ns.openlab.com. IN A 192.168.48.130
www.openlab.com. IN A 192.168.48.130
ftp.openlab.com. IN A 192.168.48.130
bbs.openlab.com. IN A 192.168.48.130
www1.openlab.com. IN CNAME www.openlab.com.
- 第四步:服务端重启服务
[root@server named]# systemctl restart named
测试
- 定义客户端,将客户端的dns修改为服务端的IP地址
# 编辑客户端网卡配置文件
[root@node1 ~]# vim /etc/sysconfig/network-scripts/ifcfg-ens32
dns=192.168.48.130; # dns改为服务端的IP地址
[root@node1 ~]# nmcli c reload
[root@node1 ~]# nmcli c up ens32
连接已成功激活(D-Bus 活动路径:/org/freedesktop/NetworkManager/ActiveConnection/4)
# 定位客户端测试
[root@node1 ~]# nslookup www.openlab.com
Server: 192.168.48.130
Address: 192.168.48.130#53
Name: www.openlab.com
Address: 192.168.48.130
[root@node1 ~]# nslookup # 进入交互模式
> bbs.openlab.com
Server: 192.168.48.130
Address: 192.168.48.130#53
Name: bbs.openlab.com
Address: 192.168.48.130
> # ctrl+d退出
[root@node1 ~]# dig www.opnelab.com
; <<>> DiG 9.16.23-RH <<>> www.opnelab.com
;; global options: +cmd
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: NXDOMAIN, id: 32112
;; flags: qr rd ra; QUERY: 1, ANSWER: 0, AUTHORITY: 1, ADDITIONAL: 1
;; OPT PSEUDOSECTION:
; EDNS: version: 0, flags:; udp: 1232
; COOKIE: 518104d477dc5c0801000000647eb0d120c077e2842cd3b4 (good)
;; QUESTION SECTION:
;www.opnelab.com. IN A
;; AUTHORITY SECTION:
com. 863 IN SOA a.gtld-servers.net. nstld.verisign-grs.com. 1686024343 1800 900 604800 86400
;; Query time: 0 msec
;; SERVER: 192.168.48.130#53(192.168.48.130)
;; WHEN: Tue Jun 06 12:06:41 CST 2023
;; MSG SIZE rcvd: 151
[root@node1 ~]# nslookup www1.openlab.com
Server: 192.168.48.130
Address: 192.168.48.130#53
www1.openlab.com canonical name = www.openlab.com.
Name: www.openlab.com
Address: 192.168.48.130
注意:第三步数据配置文件可以进行精简
- SOA起始授权记录:openlab.com. IN SOA ns.openlab.com. admin.openlab.com. (),表示openlab.com.这个域名指定dns服务器为ns.openlab.com.这台主机,以及其它附加信息
- ns记录:openlab.com. IN NS ns.openlab.com. ,声明openlab.com.这个域名的dns服务器为ns.openlab.com.主机
- 以上区别:NS记录仅仅只是声明该域内哪台主机是dns服务器,用来提供名称解析服务,NS记录不会区分哪台dns服务器是master哪台dns服务器是slave。而SOA记录则用于指定哪个NS记录对应的主机是master dns服务器,也就是从多个dns服务器中挑选一台任命其为该域内的master dns服务器,其他的都是slave,都需要从master上获取域相关数据
- A记录:表示那台主机解析为什么IP地址
- CNAME记录:别名,www1.openlab.com.主机解析为www.openlab.com.主机在查找对应IP
- 精简原则:
- 可以使用@替代域名,如@替代openlab.com.
- 可以使用空格或tab重复继承上一行第一列的值
- 可以省略域名,会自动补全,如:www为www.openlab.com.
- 配置文件可以省略如下:
[root@server named]# vim openlab.com.zone
$TTL 1D
@ IN SOA ns.openlab.com. admin.openlab.com. (
0 ; serial
1D ; refresh
1H ; retry
1W ; expire
3H ) ; minimum
NS ns.openlab.com.
ns IN A 192.168.48.130
www IN A 192.168.48.130
ftp IN A 192.168.48.130
bbs IN A 192.168.48.130
www1 IN CNAME www
实验2:反向解析
- 基于上例的正向解析
| 服务端IP | 客户端IP | 网址 |
|---|---|---|
| 192.168.48.130 | 192.168.48.131 | www.openlab.com |
准备工作
# 服务端及客户端都关闭安全软件
[root@server ~]# setenforce 0
[root@server ~]# systemctl stop firewalld
# 服务端安装bind软件
[root@server ~]# yum install bind -y
# 服务端配置静态IP
[root@server ~]# nmcli c modify ens160 ipv4.method manual ipv4.addresses 192.168.48.130/24 ipv4.gateway 192.168.48.2 ipv4.dns 114.114.114.114
[root@server ~]# nmcli c reload
[root@server ~]# nmcli c up ens160
连接已成功激活(D-Bus 活动路径:/org/freedesktop/NetworkManager/ActiveConnection/2)
# 客户端设置静态IP
[root@node1 ~]# nmcli c modify ens160 ipv4.method manual ipv4.addresses 192.168.48.131/24 ipv4.gateway 192.168.48.2 ipv4.dns 192.168.48.130 # 注意,此处dns改为服务端的IP地址,后续就不用再单独修改
[root@node1 ~]# nmcli c reload
[root@node1 ~]# nmcli c up ens160
连接已成功激活(D-Bus 活动路径:/org/freedesktop/NetworkManager/Act
DNS设置
- 第一步:服务端操作,编辑主配置文件
[root@server ~]# vim /etc/named.conf
# 需改2行
listen-on port 53 { any; }; # any为允许所有主机
allow-query { 192.168.48.131; }; # 此处也可以写为IP地址
- 第二步:服务端操作,编辑区域配置文件,添加反向解析记录,注意:区域名称中IP地址反向书写,只需书写网段号
[root@server named]# vim /etc/named.rfc1912.zones
zone "48.168.192.in-addr.arpa" IN {
type master;
file "192.168.48.arpa";
allow-update { none; };
};
- 第三步:服务端操作,编辑数据配置文件,复制一份反向解析模版(/var/named/named.loopback),复制时需要加-a 参数,在修改局部即可
[root@server ~]# cd /var/named
[root@server named]# ls
data dynamic named.ca named.empty named.localhost named.loopback slaves
[root@server named]# cp -a named.loopback 192.168.48.arpa
[root@server named]# vim 192.168.48.arpa
$TTL 1D
@ IN SOA ns.openlab.com. jenny.qq.com. (
0 ; serial
1D ; refresh
1H ; retry
1W ; expire
3H ) ; minimum
IN NS ns.openlab.com.
ns.openlab.com. IN A 192.168.48.130
130 IN PTR ns.openlab.com.
130 IN PTR www.openlab.com.
130 IN PTR ftp.openlab.com.
- 第四步:重启服务
[root@server named]# systemctl restart named
客户端测试
[root@node1 ~]# nslookup 192.168.48.130
130.48.168.192.in-addr.arpa name = www.openlab.com.
130.48.168.192.in-addr.arpa name = ftp.openlab.com.
130.48.168.192.in-addr.arpa name = ns.openlab.com.
部署DNS从服务器
作用:
-
DNS作为重要的互联网基础设施服务,保证 DNS 域名解析服务的正常运转至关重要,只有这样才能提供稳定、快速且不间断的域名查询服务
-
DNS 域名解析服务中,从服务器可以从主服务器上获取指定的区域数据文件,从而起到备份解析记录与负载均衡的作用,因此通过部署从服务器可以减轻主服务器的负载压力,还可以提升用户的查询效率
-
注意:
- 时间同步必须保持一致性
- bind最好使用同一版本
实验3:主从DNS服务器
完全区域传送
-
将一个区域文件复制到多个服务器上的过程叫做区域传送。
-
将主服务器上的所有信息复制到辅助服务器上来实现完全区域传送,即复制整个区域文件
-
服务器说明:
| 设备 | IP | 系统 |
|---|---|---|
| 主服务器 | 192.168.48.130 | Euler |
| 从服务器 | 192.168.48.131 | Euler |
- 第一步:两个服务器恢复快照,预处理、安装软件、设置网卡信息
setenforce 0 # # 两个服务器都处理
systemctl stop firewalld
yum install bind -y # 两个服务器都安装
# 主服务器IP信息:
[root@server ~]# nmcli c modify ens32 ipv4.method manual ipv4.addresses '192.168.48.130/24' ipv4.gateway '192.168.48.2' ipv4.dns '192.168.48.130'
# dns改为自己,是本机具备测试功能
[root@server ~]# nmcli c reload
[root@server ~]# nmcli c up ens32
# 从服务器IP信息
[root@node1 ~]# nmcli c modify ens32 ipv4.method manual ipv4.addresses '192.168.48.131/24' ipv4.gateway '192.168.48.2' ipv4.dns '192.168.48.131'
[root@node1 ~]# nmcli c reload
[root@node1 ~]# nmcli c up ens32
- 第二步:主服务端操作,编辑主配置文件设置监听IP
# 主服务端操作:
[root@server ~]# vim /etc/named.conf
listen-on port 53 { 192.168.48.130; }; # {}中改为any。也可写为本机IP
allow-query { any; }; # {}中改为any,也可写为服务端
- 第三步:主服务端操作打开区域配置文件,添加如下内容,重点为:允许从服务器的同步请求,即修改为 allow-transfer {允许同步区域信息的主机IP;};参数
[root@server ~]# vim /etc/named.rfc1912.zones
# 修改为以下内容:
zone "openlab.com" IN {
type master;
file "openlab.com.zone";
allow-transfer { 192.168.48.131; };
};
zone "48.168.192.in-addr.arpa" IN {
type master;
file "192.168.48.arpa";
allow-transfer { 192.168.48.131; };
};
- 第二步:主服务端操作,设置正反向解析数据配置文件,内容如下:
# 正向解析:
[root@server ~]# cd /var/named
[root@server ~]# ls
[root@server ~]# cp -a named.localhost openlab.com.zone
[root@server ~]# vim openlab.com.zone
# 配置内容如下:
$TTL 1D
@ IN SOA ns.openlab.com. admin.openlab.com. (
0 ; serial
1D ; refresh
1H ; retry
1W ; expire
3H ) ; minimum
NS ns.openlab.com.
NS slave.openlab.com.
ns IN A 192.168.48.130
www IN A 192.168.48.130
bbs IN A 192.168.48.130
ftp IN CNAME www
slave IN A 192.168.48.131
# 反向解析:
[root@server ~]# cd /var/named
[root@server ~]# ls
[root@server ~]# cp -a named.loopback 192.168.48.arpa
[root@server ~]# vim /var/named/192.168.48.arpa
#配置内容如下:
$TTL 1D
@ IN SOA ns.openlab.com admin.openlab.com. (
0 ; serial
1D ; refresh
1H ; retry
1W ; expire
3H ) ; minimum
NS ns.openlab.com.
NS slave.openlab.com.
130 IN PTR ns.openlab.com.
130 IN PTR www.openlab.com.
130 IN PTR bbs.openlab.com.
130 IN PTR ftp.openlab.com.
131 IN PTR slave.openlab.com.
- 第三步:主服务端操作,重启服务
[root@server ~]# systemctl restart named
- 第四步:从服务端操作,修改主配置文件:
[root@node1 ~]# vim /etc/named.conf
11 listen-on port 53 { 192.168.48.131; };
19 allow-query { any; };
- 第五步:从服务端操作,修改区域配置文件,填写主服务器的 IP 地址与要抓取的区域信息,注意此时的服务类型应该是 slave(从)
[root@node1 ~]# vim /etc/named.rfc1912.zones
# 清空后,添加以下内容
zone "openlab.com" IN {
type slave;
masters { 192.168.48.130; };
file "slaves/openlab.com.zone";
};
zone "48.168.192.in-addr.arpa" IN {
type slave;
masters { 192.168.48.130; };
file "slaves/192.168.48.arpa";
};
- 第六步:从服务端操作,重启服务,注意:当从服务器的 DNS 服务程序在重启后,就自动从主服务器上同步了数据配置文件,且该文件默认会放置在区域配置文件中所定义的目录位置中
[root@node1 ~]# cd /var/named/slaves
[root@node1 ~]# ls # 启动服务前查看解析配置文件为空
[root@node1 ~]# systemctl start named
[root@node1 ~]# ls # 启动服务后自动拉取
- 第七步:从服务端操作,确认从服务端的网卡DNS地址修改为自己的IP:192.168.48.131,使从服务器自身也能提供的 DNS 域名解析服务,在进行测试
[root@node1 ~]# nslookup www.openlab.com
[root@node1 ~]# nslookup 192.168.48.130
[root@node1 ~]# dig @192.168.48.130 www.openlab.com
增量区域传送
-
功能:仅复制区域里变化的文件
-
第一步:主服务端操作,修改数据配置文件
[root@server ~]# vim /var/named/openlab.com.zone
$TTL 1D
@ IN SOA openlab.com. admin.openlab.com. (
1 ; serial # 修改,需要加1
3 ; refresh # 修改
1H ; retry
1W ; expire
3H ) ; minimum
NS ns.openlab.com.
MX 8 mail.openlab.com. # 添加
NS slave.openlab.com.
ns IN A 192.168.48.130
www IN A 192.168.48.130
bbs IN A 192.168.48.130
mail IN A 192.168.48.130 # 添加
ftp IN CNAME www
slave IN A 192.168.48.131
www1 IN CNAME www # 添加
# 注意:1 ; serial 处的序号数字必须加1,否则从服务端不更新
- 第二步:主服务端操作,重启服务
[root@server ~]# systemctl restart named
- 第三步:从服务端操作,重启服务
[root@node1 ~]# systemctl restart named
- 第四步:从服务端操作,测试
[root@node1 ~]# nslookup mail.openlab.com
[root@node1 ~]# nslookup www1.openlab.com
注意:
- 序号需要比原序号大
- 更新频率可以改小一点,这样比较快看到实验结果
- 需要写一条关于从服务器的NS和A记录,不然新增的数据有时能更新有时无法更新
第七章 selinux
1、selinux的说明
SELinux是Security-Enhanced Linux的缩写,意思是安全强化的linux。
SELinux 主要由美国国家安全局(NSA)开发,当初开发的目的是为了避免资源的误用。
DAC(Discretionary Access Control)自主访问控制系统
MAC(Mandatory Access Control)强制访问控制系统
2、selinux的工作原理
SELinux是通过MAC的方式来控制管理进程,它控制的主体是进程,而目标则是该进程能否读取的文件资源。
主体(subject):就是进程
目标(object):被主体访问的资源,可以是文件、目录、端口等。
策略(policy):由于进程与文件数量庞大,因此SELinux会依据某些服务来制定基本的访问安全策略。这些策略内还会有详细的规则(rule)来指定不同的服务开放某些资源的访问与否。目前主要的策略有:
- targeted:针对网络服务限制较多,针对本机限制较少,是默认的策略;
- strict:完整的SELinux限制,限制方面较为严格。
安全上下文(security context):主体能不能访问目标除了策略指定外,主体与目标的安全上下文必须一致才能够顺利访问。
最终文件的成功访问还是与文件系统的rwx权限设置有关 。
#查看文件的安全上下文
[root@localhost ~]# ls -Z
-rw-------. root root system_u:object_r:admin_home_t:s0 anaconda-ks.cfg
drwxr-xr-x. root root unconfined_u:object_r:admin_home_t:s0 home
安全上下文用冒号分为四个字段:
Identify:role:type:
- 身份标识(Identify):相当于账号方面的身份标识,主要有以下三种常见的类型:
root:表示root的账号身份;
system_u:表示程序方面的标识,通常就是进程;
unconfined_u:代表的是一般用户账号相关的身份。 - 角色(role):通过角色字段,可知道这个数据是属于程序、文件资源还是代表用户。一般角色有:
object_r:代表的是文件或目录等文件资源;
system_r:代表的是进程。 - 类型(type):在默认的targeted策略中,Identify与role字段基本上是不重要的,重要的在于这个类型字段。而类型字段在文件与进程的定义不太相同,分别是:
type:在文件资源上面称为类型。
domain:在主体程序中则称为域。xxxx_xxx_xxx_t
domain需要与type搭配,则该程序才能够顺利读取文件资源。 - 最后一个字段是和MLS和MCS相关的东西,代表灵敏度,一般用s0、s1、s2来命名,数字代表灵敏度的分级。数值越大、灵敏度越高。
3、selinux的启动、关闭与查看
(1)SELinux三种模式
- enforcing:强制模式,代表SELinux正在运行中,开始限制domain/type。
- permissive:宽容模式,代表SELinux正在运行中,不过仅会有警告信息并不会实际限制domain/type的访问。
- disabled:关闭,SELinux并没有实际运行。
#查看目前的模式
[root@localhost ~]# getenforce
Enforcing
#查看目前的selinux使用的策略
[root@localhost ~]# sestatus
SELinux status: enabled # 是否启用selinux
SELinuxfs mount: /sys/fs/selinux #selinux的相关文件数据挂
载点
SELinux root directory: /etc/selinux
Loaded policy name: targeted #目前的策略
Current mode: enforcing
Mode from config file: enforcing
Policy MLS status: enabled
Policy deny_unknown status: allowed
Max kernel policy version: 31
#查看selinux的策略:
[root@localhost ~]# vim /etc/selinux/config
改变策略之后需要重新启动;
如果由enforcing或permissive改成disabled,或由disabled改为其它两个,也必须要重新启动。
将selinux模式在enforcing和permissive之间切换的方法为:
setenforce 0 转换成permissive宽容模式
setenforce 1转换成enforcing强制模式
(2)修改安全上下文
临时生效
chcon [-R] [-t type] [-u user] [-r role] 文件
-R:连同该目录下的子目录也同时修改;
-t:后面接安全上下文的类型字段;
-u:后面接身份识别;
-r:后面接角色
chcon [-R] --reference=范例文件 文件 将文件的安全上下文按照范例文件修改
restorecon [-Rv] 文件或目录
-R:连同子目录一起修改;
-v:将过程显示到屏幕上
restorecon怎么会知道每个目录记载的默认selinux type类型呢?因为系统将每个目录的默认selinux type类型记录在/etc/selinux/targeted/contexts/目录内。但是该目录内有很多不同的数据,所以我们可以用semanage这个命令的功能来查询与修改。
semanage {login|user|port|interface|fcontext|translation} -l
semanage fcontext -{a|d|m} [-frst] file_spec
-l为查询;
-a:增加一些目录的默认安全上下文的设置;
-m:修改;
-d:删除。
-t 类型
安装policycoreutils-gui
执行system-config-selinux
4、selinux对linux服务的影响
chronyd ssh nginx nfs named
实验一:使用httpd服务演示安全上下文值的设定
#服务端的IP地址为172.24.8.130,服务端的设置如下:
[root@localhost ~]# systemctl disable firewalld --now
[root@localhost ~]# getenforce
Enforcing
[root@localhost ~]# vim /etc/httpd/conf.d/host.conf
<directory /www>
allowoverride none
require all granted
</directory>
<virtualhost 172.24.8.130:80>
documentroot /www/80
servername 172.24.8.130
</virtualhost>
[root@localhost ~]# mkdir -pv /www/80
[root@localhost ~]# echo this is 80 > /www/80/index.html
[root@localhost ~]# systemctl restart httpd
通过客户端测试,只能访问到http服务的测试界面
#修改自定义目录的安全上下文的值:
[root@localhost ~]# chcon -t httpd_sys_content_t /www/ -R
也可以将自定义目录的安全上下文的值按照/var/www/html文件修改:
[root@localhost ~]# chcon -R --reference=/var/www/html /www
修改之后即可成功访问。
实验二:使用web服务端口的改变来演示端口的设定
[root@localhost ~]# vim /etc/httpd/conf.d/host.conf
<directory /www>
allowoverride none
require all granted
</directory>
listen 8888
<virtualhost 172.24.8.130:8888>
documentroot /www/8888
servername 172.24.8.130
</virtualhost>
[root@localhost ~]# mkdir /www/8888
[root@localhost ~]# echo this is 8888 > /www/8888/index.html
[root@localhost ~]# systemctl restart httpd
#服务重启失败,查看日志
[root@localhost ~]# tail -f /var/log/messages
#添加8888端口为服务端口:
[root@localhost ~]# semanage port -a -t http_port_t -p tcp 8888
[root@localhost ~]# systemctl restart httpd
#测试可以访问成功
**总结: **
selinux访问控制
1.服务配置时如果对服务程序的数据文件自定义路径时,selinux开启必须对数据文件的标签进行修改。
2.服务配置时自定义端口,需要更改端口的标签
第八章 防火墙
1、什么是防火墙
防火墙:防火墙是位于内部网和外部网之间的屏障,它按照系统管理员预先定义好的规则来控制数据包的进出。
防火墙又可以分为硬件防火墙与软件防火墙。硬件防火墙是由厂商设计好的主机硬件,这台硬件防火墙的操作系统主要以提供数据包数据的过滤机制为主,并将其他不必要的功能拿掉。软件防火墙就是保护系统网络安全的一套软件(或称为机制),例如Netfilter与TCP Wrappers都可以称为软件防火墙。这儿主要介绍linux系统本身提供的软件防火墙的功能,那就是Netfilter,即数据包过滤机制。
数据包过滤,也就是分析进入主机的网络数据包,将数据包的头部数据提取出来进行分析,以决定该连接为放行或抵挡的机制。由于这种方式可以直接分析数据包头部数据,包括硬件地址,软件地址,TCP、UDP、ICMP等数据包的信息都可以进行过滤分析,因此用途非常广泛(主要分析OSI七层协议的2、3、4层)。由此可知,linux的Netfilter机制可以进行的分析工作有:
包过滤型防火墙
源目 ip 端口 协议传输层tcp/udp icmp
- 拒绝让Internet的数据包进入主机的某些端口; 80
- 拒绝让某些来源ip的数据包进入;
- 服务协议
- 拒绝让带有某些特殊标志(flag)的数据包进入,最常拒绝的就是带有SYN的主动连接的标志了;
- 分析硬件地址(MAC)来决定连接与否。
虽然nft_Netfilter防火墙可以做到这么多事情,不过,某些情况下,它并不能保证我们的网络一定就很安全。例如:
-
防火墙并不能有效阻挡病毒或木马程序。(假设主机开放了www服务,防火墙的设置是一定要将www服务的port开放给client端的。假设www服务器软件有漏洞,或者请求www服务的数据包本身就是病毒的一部分时,防火墙是阻止不了的)
-
防火墙对于内部LAN的攻击无能为力(防火墙对于内部的规则设置通常比较少,所以就很容易造成内部员工对于网络无用或滥用的情况)
nftfilter这个数据包过滤机制是由linux内核内建的,不同的内核版本使用的设置防火墙策略的软件不一样,在红帽7系统中firewalld服务取代了iptables服务,但其实iptables服务与firewalld服务它们都只是用来定义防火墙策略的“防火墙管理工具”而已,他们的作用都是用于维护规则,而真正使用规则干活的是内核的netfilter。 firewalld iptables
2、iptables
(1)iptables介绍
防火墙会从以上至下的顺序来读取配置的策略规则,在找到匹配项后就立即结束匹配工作并去执行匹配项中定义的行为(即放行或阻止)。如果在读取完所有的策略规则之后没有匹配项,就去执行默认的策略。一般而言,防火墙策略规则的设置有两种:一种是“通”(即放行),一种是“堵”(即阻止)。当防火墙的默认策略为拒绝时(堵),就要设置允许规则(通),否则谁都进不来;如果防火墙的默认策略为允许时,就要设置拒绝规则,否则谁都能进来,防火墙也就失去了防范的作用。
iptables服务把用于处理或过滤流量的策略条目称之为规则,多条规则可以组成一个规则链,而规则链则依据数据包处理位置的不同进行分类,具体如下:
在进行路由选择前处理数据包,用于目标地址转换(PREROUTING);
处理流入的数据包(INPUT);
处理流出的数据包(OUTPUT);
处理转发的数据包(FORWARD);
在进行路由选择后处理数据包,用于源地址转换(POSTROUTING)。
[root@localhost ~]# yum install iptables-services.x86_64 -y
[root@localhost ~]# systemctl stop firewalld
[root@localhost ~]# systemctl start iptables
[root@server ~]# iptables -F #清空所有的规则表,清空之后客户端可以访问ssh和http服务
iptables命令可以根据流量的源地址、目的地址、传输协议、服务类型等信息进行匹配,一旦匹配成功,iptables就会根据策略规则所预设的动作来处理这些流量。

语法格式:iptables -t 表名 <-A/I/D/R> 规则链名 [规则号] <-i/o 网卡名> -p 协议名 <-s 源IP/源子网> --sport 源端口 <-d 目标IP/目标子网> --dport 目标端口 -j 动作
参数说明:iptables -A INPUT -s A -d B --dport 80 -p tcp -j REJECT
| 参数 | 说明 |
|---|---|
| -t | 对指定的表进行操作,table必须是raw,nat,filter,mangle中的一个。默认是filter 表。 |
| -p | 指定要匹配的数据包协议类型 |
| -s | –source address[/mask][,…]:把指定的一个或者一组地址作为源地址,按此规则进行过 滤。当后面没有mask 时,address 是一个地址,比如:192.168.1.1;当 mask 指定时, 可以表示一组范围内的地址,比如:192.168.1.0/255.255.255.0 |
| -d | –destination address[/mask][,…]:地址格式同上,但这里指定地址为目的地址,按此进 行过滤 |
| -i | –in-interface name:指定数据包的来自来自网络接口,比如最常见的 eth0 。注意:它 只对 INPUT,FORWARD,PREROUTING 这三个链起作用。如果没有指定此选项, 说明 可以来自任何一个网络接口。同前面类似,“!” 表示取反 |
| -o | –out-interface name:指定数据包出去的网络接口。只对 OUTPUT,FORWARD, POSTROUTING 三个链起作用 |
| -L | –list [chain] 列出链 chain 上面的所有规则,如果没有指定链,列出表上所有链的所有规 则 |
| -A | –append chain rule-specification:在指定链 chain 的末尾插入指定的规则,也就是 说,这条规则会被放到最后,最后才会被执行。规则是由后面的匹配来指定 |
| -I | –insert chain [rulenum] rule-specification:在链 chain 中的指定位置插入一条或多条 规则。如果指定的规则号是1,则在链的头部插入。这也是默认的情况,如果没有指定规 则号 |
| -D | –delete chain rule-specification -D, --delete chain rulenum:在指定的链 chain 中删除 一个或多个指定规则 |
| -R num | Replays替换/修改第几条规则 |
| -P | –policy chain target :为指定的链 chain 设置策略 target。注意,只有内置的链才允许 有策略,用户自定义的是不允许的 |
| -F | –flush [chain] 清空指定链 chain 上面的所有规则。如果没有指定链,清空该表上所有链 的所有规则 |
| -N | –new-chain chain 用指定的名字创建一个新的链 |
| -X | –delete-chain [chain] :删除指定的链,这个链必须没有被其它任何规则引用,而且这条 上必须没有任何规则。如果没有指定链名,则会删除该表中所有非内置的链 |
| -E | –rename-chain old-chain new-chain :用指定的新名字去重命名指定的链。这并不会对 链内部照成任何影响 |
| -Z | –zero [chain] :把指定链,或者表中的所有链上的所有计数器清零 |
| -j | –jump target <指定目标> :即满足某条件时该执行什么样的动作。target 可以是内置的 目标,比如 ACCEPT,也可以是用户自定义的链 |
| -h | 显示帮助信息 |
(2)实验
实验一:搭建web服务,设置任何人能够通过80端口访问。
[root@localhost ~]# iptables -I INPUT -p tcp --dport 80 -j ACCEPT
[root@localhost ~]# iptables -L --line-numbers
[root@localhost ~]# iptables -D INPUT 1
实验二:禁止所有人ssh远程登录该服务器
[root@localhost ~]# iptables -I INPUT -p tcp --dport 22 -j REJECT
#删除设置的拒绝ssh连接:
[root@localhost Desktop]# iptables -D INPUT 1
实验三:禁止某个主机地址ssh远程登录该服务器,允许该主机访问服务器的web服务。服务器地址为172.24.8.128
iptable -I INPUT -s 172.24.8.100 -d 172.24.8.128 -p tcp --dport 22 -j DROP
iptable -I INPUT -s 172.24.8.100 -d 172.24.8.128 -p tcp --dport 80 -j ACCEP
拒绝172.24.8.129通过ssh远程连接服务器:
[root@localhost ~]# iptables -I INPUT -p tcp -s 172.24.8.129 --dport 22 -j REJECT
允许172.24.8.129访问服务器的web服务:
[root@localhost ~]# iptables -I INPUT -p tcp -s 172.24.8.129 --dport 80 -j ACCEPT
案例四:iptable的规则备份
[root@localhost ~]# iptables -I INPUT -p tcp --dport 22 -s 192.168.24.0/24 -j DROP
[root@localhost ~]# iptables-save > /etc/sysconfig/iptables.bak
[root@localhost ~]# iptables-restore < /etc/sysconfig/iptables.bak
[root@localhost ~]# iptables -L
对当前linux主机不允许某个用户进行远程连接
vim /etc/sshd/sshd_config
denyUsers 用户名
密码锁定
用户shell改为/sbin/nologin
案例分析:
1.封堵网段(10.20.30.0/24),两小时后解封。
# iptables -I INPUT -s 10.20.30.0/24 -j DROP
# iptables -I FORWARD -s 10.20.30.0/24 -j DROP
# at now 2 hours at> iptables -D INPUT 1 at> iptables -D FORWARD 1
2.丢弃从外网接口(eth1)进入防火墙本机的源地址为私网地址的数据包
私网地址是:
iptables -A INPUT -i eth1 -s 192.168.0.0/16 -j DROP
iptables -A INPUT -i eth1 -s 172.16.0.0/12 -j DROP
iptables -A INPUT -i eth1 -s 10.0.0.0/8 -j DROP
3.允许本机开放从TCP端口20-1024提供的应用服务。
iptables -A INPUT -p tcp --dport 20:1024 -j ACCEPT
iptables -A OUTPUT -p tcp --sport 20:1024 -j ACCEP
4.禁止转发来自MAC地址为00:0C:29:27:55:3F的和主机的数据包
iptables -A FORWARD -m mac --mac-source 00:0c:29:27:55:3F -j DROP
5.允许防火墙本机对外开放TCP端口20、21、25、110以及被动模式FTP端口1250-1280
***iptables -A INPUT -p tcp -m multiport --dport 20,21,25,110,1250:1280 -j ACCEPT
6.禁止转发源IP地址为192.168.1.20-192.168.1.99的TCP数据包。
iptables -A FORWARD -p tcp -m iprange --src-range 192.168.1.20-192.168.1.99 -j DROP

8.
RELATED,ESTABLISHED
7.禁止其他主机ping防火墙主机,但是允许从防火墙上ping其他主机
iptables -I INPUT -p icmp --icmp-type Echo-Request -j DROP
iptables -I OUTPUT -p icmp --icmp-type Echo-Reply -j ACCEPT
iptables -I INPUT -p icmp --icmp-type destination-Unreachable -j ACCEPT

8.iptables -t nat -A POSTROUTING -s 172.24.8.0/24 -o eno16777736 -j MASQUERADE
9.也可以使用–to-source(公网地址)
#iptables -t nat -A POSTROUTING -s 172.24.8.0/24 -o eno16777736 -j SNAT --to-source 192.168.150.148
#firewall-cmd --permanent --add-masquerade --zone=public
10.使用iptables配置
#iptables -t nat -A PREROUTING -d 192.168.150.148 -p tcp --dport 80 -i eno16777736 -j DNAT --to-destination 172.24.8.100:8080
[root@A ~]# firewall-cmd --zone=public --add-forward-port=port=80:proto=tcp:toport=8080:toaddr=172.24.8.100 --permanent
success
[root@kongd ~]# firewall-cmd --reload
外网客户端测试
http://192.168.150.148 --> http://172.24.8.100:8080
3、firewalld
(1)firewalld介绍
iptables service 首先对旧的防火墙规则进行了清空,然后重新完整地加载所有新的防火墙规则,而如果配置了需要 reload 内核模块的话,过程背后还会包含卸载和重新加载内核模块的动作,而不幸的是,这个动作很可能对运行中的系统产生额外的不良影响,特别是在网络非常繁忙的系统中。
如果我们把这种哪怕只修改一条规则也要进行所有规则的重新载入的模式称为静态防火墙的话,那么 firewalld 所提供的模式就可以叫做动态防火墙,它的出现就是为了解决这一问题,任何规则的变更都不需要对整个防火墙规则列表进行重新加载,只需要将变更部分保存并更新即可,它具备对 IPv4 和 IPv6防火墙设置的支持。
相比于传统的防火墙管理工具,firewalld支持动态更新技术并加入了区域的概念。区域就是firewalld预先准备了几套防火墙策略集合(策略模板),用户可以选择不同的集合,从而实现防火墙策略之间的快速切换。
firewalld中常见的区域名称(默认为public)以及相应的策略规则:
| 区域 | 默认规则策略 |
|---|---|
| 阻塞区域 (block) | 拒绝流入的流量,除非与流出的流量相关 |
| 工作区域 (work) | 拒绝流入的流量,除非与流出的流量相关 |
| 家庭区域 (home) | 拒绝流入的流量,除非与流出的流量相关 |
| 公共区域 (public) | 不相信网络上的任何计算机,只有选择接受传入的网络连接。 ssh |
| 隔离区域 (DMZ) | 隔离区域也称为军事区域,内外网络之间增加的一层网络,起到缓冲作用。对 于隔离区域,只有选择接受传入的网络连接。 |
| 信任区域 (trusted) | 允许所有的数据包。 |
| 丢弃区域 (drop) | 拒绝流入的流量,除非与流出的流量相关 |
| 内部区域 (internal) | 等同于home区域 |
| 外部区域 (external) | 拒绝流入的流量,除非与流出的流量有关;而如果流量与ssh服务相关,则允许 流量 |
firewalld默认提供的九个zone配置文件都保存在“/usr/lib/firewalld/zones/”目录下,分别为:
block.xml drop.xml home.xml public.xml work.xml dmz.xml external.xml
internal.xml trusted.xml
在RHEL7中,firewalld服务是默认的防火墙配置管理工具,他拥有基于CLI(命令行界面)和基于GUI(图形用户界面)的两种管理方式。firewall-config和firewall-cmd是直接编辑xml文件,其中firewall-config是图形化工具,firewall-cmd是命令行工具。
安装firewalld服务的软件:
[root@localhost ~]# rpm -qa | grep firewall
firewall-config-0.3.9-14.el7.noarch
firewalld-0.3.9-14.el7.noarch
firewall-cmd命令的参数说明如下:
| 参数 | 作用 |
|---|---|
| –set-default-zone=<区域名称> | 设置默认的区域,使其永久生效 |
| –get-zones | 显示可用的区域 |
| –get-services | 显示预先定义的服务 http https ntp named nfs |
| –get-active-zones | 显示当前正在使用的区域与网卡名称 |
| –add-source= | 将源自此IP或子网的流量导向指定的区域 |
| –remove-source= | 不再将源自此IP或子网的流量导向某个指定区域 |
| –get-default-zone | 查询默认的区域名称 |
| –list-all | 显示当前区域的网卡配置参数、资源、端口以及服务等信息 |
| –list-all-zones | 显示所有区域的网卡配置参数、资源、端口以及服务等信息 |
| –add-service=<服务名> | 设置默认区域允许该服务的流量 |
| –add-port=<端口号/协议> | 设置默认区域允许该端口的流量 |
| –remove-service=<服务名> | 设置默认区域不再允许该服务的流量 |
| –remove-port=<端口号/协议> | 设置默认区域不再允许该端口的流量 |
| –reload | 让“永久生效”的配置规则立即生效,并覆盖当前的配置规则 |
| –panic-on | 开启应急状况模式 |
| –panic-off | 关闭应急状况模式 |
[root@localhost ~]# systemctl stop iptables
[root@localhost ~]# systemctl restart firewalld
[root@localhost ~]# firewall-cmd --help #查看帮助
[root@localhost ~]# firewall-cmd --list-all #查看所有的规则
[root@localhost ~]#firewall-cmd --permanent --add-service=服务名
使用firewalld配置的防火墙策略默认为当前生效,会随着系统的重启而失效。如果想让策略一直存在,就需要使用永久模式了,即在使用firewall-cmd命令设置防火墙策略时添加--permanent参数,这样配置的防火墙策略就可以永久生效了,最后想要使用这种方式设置的策略生效,只能重启或者输入命令:firewall-cmd --reload。
图形化工具 firewall-config
firewall-config
#禁止某个ip地址进行ssh访问,应该写成ip/32
#配置端口转发(在172.24.8.0网段的主机访问该服务器的80端口将被转发到5423端口)
[root@system1 ~]# firewall-cmd --permanent --add-rich-rule='rule family="ipv4" source address="172.24.8.0/24" forward-port port="80" protocol="tcp" to-port="5423" destination address=192.168.10.130'
[root@mail ~]# firewall-cmd --permanent --add-forward-port port=22:proto=tcp:toport=2222:toaddr=192.168.10.130
第九章 Ubuntu
什么是Ubuntu
概述
- Ubuntu(乌班图)属于Debian系列,Debian是社区类Linux的典范,是迄今为止最遵循GNU规范 的Linux系统。

- Debian最早由Ian Murdock于1993年创建,分为三个版本分支(branch): stable、testing 和 unstable。
- Debian最具特色的是apt-get / dpkg包管理方式,其实Redhat的YUM也是在模仿Debian的APT方式,但在二进制文件发行方式中,APT应该是最好的了。
- Ubuntu Server是Ubuntu操作系统的一个版本,是Ubuntu家族的一员,被工程设计作为互联网的骨干系统,Ubuntu Server为公共或私有数据中心带来经济和技术上的可扩展性。
Ubuntu版本简介
桌面版
- 网址:https://cn.ubuntu.com/download

- 桌面版是带有GUI界面、面向普通用户使用的操作系统,预装了可帮助用户执行日常基本活动的软件,如:视频、浏览器、文本处理、电子邮件和多媒体等,对标Windows10操作系统

服务器版
- 服务器版本用于托管网络服务器和数据库等应用程序,是专业人员使用的服务器操作系统

- 注意:
- 一般选择LTS长期更新版,LTS为“长期支持”版本每两年在4月份发布一次。LTS版本是Ubuntu的“企业级”版本,使用得最多。估计95%的Ubuntu安装都是LTS版。
- 可以在开源镜像站点下载,如阿里开源镜像

部署系统
新建虚拟机






安装系统
- 择安装语言,默认 【 English 】,直接回车

- 选择键盘,默认回车

- 安装的服务器版本,如需精简版本选择 【Minimized】最小安装,此处根据需求自行选择,本次安装选择 【 Ubuntu Server 】

- 网络设置,此处默认使用DHCP,回车即可

- Proxy(代理配置),用于访问安装程序环境和已安装系统中的包存储库和snap存储库,不用配置,回车即可

- 配置软件源,建议更改为国内镜像源提高下载速度,也可以直接回车,以后在更改

- 系统分区,选择安装磁盘,直接回车默认自动分配,需要手动分区的话选择 【custom storage layout】。**此次安装选择【Custom storage layout】**进行手动分区,按Tab进行选项选择,按空格键选中选项后回车

- 新建第一个分区:/boot,容量1GB


- 添加第二个分区:/根分区,剩余容量,不填即可


- 设置计算机名、用户名及密码
- your server name:主机名
- pick a useranme:账户名
- 注意:ubuntu默认不能设置root密码,可以安装完毕后,使用命令更改root密码

- 安装OpenSSH Server 服务,空格键选中

- 选择安装其他服务,直接跳过

- 开始系统安装

- 安装完成后选择【Reboot Now】重启系统

- 注意:出现下列报错,表示未找到光驱,回车即可

- 使用之前创建的普通账户登录

部署后的设置
设置root密码
- 由于默认的root用户没有固定密码,则可以通过下列方法更改并切换账户
andy@server:~$ sudo passwd root # 以普通账户登录后执行此命令修改root初始密码
[sudo] password for andy: # 普通账户的密码
New password: # 新的root密码
Retype new password: # 在输入一遍
passwd: password updated successfully
andy@server:~$ su - root # 切换到root账户
Password:
root@server:~#
关闭防火墙
root@server:~# systemctl status ufw # 查看ufw防火墙状态
● ufw.service - Uncomplicated firewall
Loaded: loaded (/lib/systemd/system/ufw.service; enabled; preset: enabled)
Active: active (exited) since Sat 2023-12-02 07:55:04 UTC; 13min ago
Docs: man:ufw(8)
Main PID: 624 (code=exited, status=0/SUCCESS)
CPU: 1ms
root@server:~# systemctl stop ufw
root@server:~# systemctl disable ufw
启用允许root进行ssh
root@server:~# vim /etc/ssh/sshd_config
PermitRootLogin 的参数设为yes
root@server:~# systemctl restart ssh # 注意服务接口为ssh
安装所需软件
root@server:~# apt install tree gcc make net-tools openvswitch-switch -y
制作快照
网络配置
Netplan概述
-
Netplan —— 抽象网络配置生成器 ,是一个用于配置 Linux网络的简单工具。
-
通过 Netplan ,你只需用一个 YAML文件描述每个网络接口需要配置成啥样即可。 根据这个配置描述, Netplan 便可帮你生成所有需要的配置,不管你选用的底层管理工具是啥
-
Netplan 的特点和功能:
- YAML 语法:Netplan 使用 YAML 文件格式来描述网络配置信息。YAML 格式旨在使文件易于编写、阅读和理解。您可以在每行结束时添加注释以方便自己和其他管理员查看文件。
- 多种网络选项:Netplan 支持多种网络选项,包括 IP 地址、子网掩码、网关、DNS 设置、静态路由和 DHCP 客户端等。您可以根据需要选择所需的选项并将其添加到配置文件中。
- 支持多个网络接口:Netplan 支持管理多个网络接口。无论您使用有线或无线网络,或者使用虚拟网络接口,都可以在配置文件中指定各个接口的设置。
- 自动应用配置:当您修改 Netplan 配置文件后,Netplan 会自动将其应用到相应的网络接口上。这意味着您无需手动执行命令即可生效所做的更改。
- 兼容性:Netplan 可以与旧版网络管理工具共存,并且可以在 Ubuntu 16.04 及更高版本上运行。如果您已经使用 ifupdown 或 NetworkManager 进行网络配置,您可以继续使用这些工具,或者将其与 Netplan 配置文件结合使用。
-
Netplan目前支持以下两种 网络管理工具 :
- NetworkManager
- Systemd-networkd
- 一言以蔽之,从前你需要根据不同的管理工具编写网络配置,现在 Netplan将管理工具差异性给屏蔽了。 你只需按照 Netplan规范编写 YAML 配置,不管底层管理工具是啥,一份配置走天下!

配置详解
配置文件
# 默认配置文件:/etc/netplan/*.yaml
# 本机
root@server:~# vim /etc/netplan/50-cloud-init.yaml
DHCP
network:
ethernets:
ens32:
dhcp4: true
version: 2
静态IP设置
- 注意:netplan 说明文件格式存储在下列路径下,该目录下有各种样例文件,可以提供帮助
root@server:~# cd /usr/share/doc/netplan/examples/
root@server:/usr/share/doc/netplan/examples# ls
bonding_router.yaml infiniband.yaml sriov_vlan.yam ……
# 静态IP范例
root@server:/usr/share/doc/netplan/examples# cat static.yaml
network:
version: 2
renderer: networkd
ethernets:
enp3s0: # 网卡名
addresses:
- 10.10.10.2/24 # 静态IP地址/子网掩码
nameservers:
search: [mydomain, otherdomain] # 域名
addresses: [10.10.10.1, 1.1.1.1] # DNS解析地址1 , DNS解析地址2
routes:
- to: default
via: 10.10.10.1 # 网关地址
- 查看本机IP信息
# IP and netmask:
root@server:~# ifconfig ens32 # IP:192.168.48.151
ens32: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 192.168.48.151 netmask 255.255.255.0 broadcast 192.168.48.255
inet6 fe80::20c:29ff:fee1:522e prefixlen 64 scopeid 0x20<link>
ether 00:0c:29:e1:52:2e txqueuelen 1000 (Ethernet)
RX packets 52971 bytes 74147184 (74.1 MB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 11760 bytes 744059 (744.0 KB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
# gateway: 192.168.48.2
root@server:~# route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
0.0.0.0 192.168.48.2 0.0.0.0 UG 100 0 0 ens32
# DNS:114.114.114.114
- 设置
root@server:~# vim /etc/netplan/50-cloud-init.yaml
# 清除已有内容,将静态IP范例文件内容拷贝到当前配置中,在修改,注意缩进格式
network:
ethernets:
ens32:
dhcp4: no
addresses: [192.168.48.150/24]
routes:
- to: default
via: 192.168.48.2 #via经过,路过 next hop
nameservers:
addresses: [114.114.114.114]
version: 2
- 生效
root@server:~# netplan apply
软件安装
方法
-
使用 apt 工具安装 dpkg -i apt
-
deb 软件包安装 rpm -ivh yum/dnf
-
自己下载程序源码编译安装
apt安装软件
作用
- Apt (Advanced package tool) 是一个命令行包命令行包管理工具,适用于 Ubuntu / Debian Linux。
- Apt 用于在 Ubuntu / Debian 系统中从命令行安装、删除、更新和升级 Debian 包。Apt 克服了在 apt-get 命令中注意到的问题和错误。使用 apt 命令时,用户必须具有 sudo 权限
常用命令
apt update : 更新软件仓库信息,建议在安装或升级包之前执行该命令
apt list : 列出所有可用的软件包
apt list --installed :只列出已安装的包
apt list --upgradeable :只列出可升级的包
apt install 软件包名 -y :安装新软件包
apt download 软件包名 : 下载软件包而不安装
apt remove 软件包名 : 删除软件包
apt upgrade : 升级所有软件包
apt install 包名 --only-upgrade : 要升级特定的安装包
apt full-upgrade : 全面系统升级,请务必小心,因为它可能会删除已安装的软件包并安装更新的软件包
apt search 软件包名 : 搜索软件包
apt show nginx : 查看软件包信息
apt clean : 清除apt缓存
配置apt源
- 配置文件:
/etc/apt/sources.list
- 推荐的源
序 号源 地址
1 阿里 http://mirrors.aliyun.com/ubuntu/
2 网易 http://mirrors.163.com/ubuntu/
3 搜狐 http://mirrors.sohu.com/ubuntu/
4 华为云 http://repo.huaweicloud.com/ubuntu/
5 中国官方 http://cn.archive.ubuntu.com/ubuntu/
6 官方 http://archive.ubuntu.com/ubuntu/
7 清华 http://mirrors.tuna.tsinghua.edu.cn/ubuntu/
8 中科大 http://mirrors.ustc.edu.cn/ubuntu/
- 修改:
- 打开文件:vim /etc/apt/sources.list
- 将默认的http://archive.ubuntu.com/ , 替换为 mirrors.aliyun.com ,如:

#光盘挂载 mount /dev/cdrom /cdrom
软件包的路径:/cdrom/pool/main/xxxx.deb
- 最后需要更新软件列表:
root@server:~# apt update
root@server:~# apt install kubuntu-desktop
default-display-manager 的设置。可以通过编辑 /etc/x11/default-display-manager 文件来配置默认的显示管理器。如果该文件中的值为 /usr/sbin/gdm,则会进入 gdm 图形界面;如果是 /usr/sbin/lightdm,则进入 lightdm 图形化界面;如果值为 false,则进入控制台。可以根据自己的需求进行修改,但修改后需要重启系统才能生效。
root@server:~# vim /etc/gdm3/custom.conf
WaybillEnable=ture
deb软件包安装
概念
- deb包是Debian,Ubuntu等Linux发行版的软件安装包,扩展名为.deb,是类似于rpm的软件包。
dpkg命令
- 格式:
dpkg [<选项> ...] <命令>
- 常用命令
dpkg -i 包名 : 安装软件包
dpkg -I 包名 : 查看软件包的详细信息(软件名称、版本以及大小等)
dpkg -c 包名 : 查看软件包结构
dpkg -r 包名 : 卸载软件包
- 注意:不推荐使用deb软件包,因为要解决软件包依赖问题,安装也比较麻烦。
第十章openEuler简介
概述
- openEuler的前身是运行在华为公司通用服务器上的操作系统EulerOS。
- EulerOS是一款基于Linux内核的开源操作系统,支持X86和ARM等多种处理器架构,伴随着华为公司鲲鹏芯片的研发,EulerOS 理所当然地成为与鲲鹏芯片配套的软件基础设施。2019年底,EulerOS被正式推送至开源社区,更名为openEuler。
- 当前openEuler内核源于Linux,支持鲲鹏及其他多种处理器,能够充分释放计算芯片的潜能,是由全球开源贡献者构建的高效、稳定、安全的开源操作系统,适用于数据库、大数据、云计算、人工智能等应用场景。
- openEuler是一个面向全球的操作系统开源社区,通过社区合作,打造创新平台,构建支持多处理器架构、统一和开放的操作系统,推动软硬件应用生态繁荣发展


架构

OpenEuler和主流OS的关系

信创与国产操作系统
- “信创”计划,全称是“信息技术应用创新计划”,旨在通过推广自主可控的信息技术,提高国家信息安全的保障能力和综合国力

安装OpenEuler
下载
- 网址:https://www.openeuler.org/zh/download/archive/
- 版本选择:openEuler 22.03 LTS SP3 ,即长期更新版,其使用linux内核版本如下图:

- 选择基本ISO版本:

创建虚拟机实例
- 第一步:文件菜单->新建虚拟机->典型->下一步

- 第二步:稍后安装操作系统

- 第三步:选择操作系统类型,由于OpenEuler22.03 LTS SP3使用Linux5.10内核则选择如下:

- 第四步:命名虚拟机

- 第五步:设置磁盘空间,根据虚拟机安装要求设置,如下:

- 设置32G,动态空间申请,设置为单个文件

- 第六步:自定义硬件,设置硬件参数

- 第七步:设置自定义硬件
- 内存:推荐2GB
- 处理器:1颗、2核心
- 新CD/DVD:适应ISO映像文件,点击浏览按钮,选择之前下载好的openEuler-22.03-LTS-SP2-x86_64-dvd.iso镜像文件
- 网络适配器:选择NAT模式
- 显示器:去掉"加速3D图形“的对钩
- 最终:

- 选择关闭、完成
虚拟网络编辑器
-
位置:vmware-> 编辑菜单->虚拟网络编辑器
-
作用:设置虚拟网卡的连接模式以及网段、IP、DNS、网关
-
方法:先点击上边的网络模式,在选择下方的设置按钮,一般需要查看“NAT设置”的网关地址以及最下方的网段地址
OpenEuler22.03操作系统的安装部署
-
使用鼠标点击黑色界面进入OpenEuler22.03系统,通过ctrl+alt可以释放鼠标焦点回到Windows
-
通过键盘方向键选择第一项Install openEuler 22.03-LTS-SP2 选项进行安装系统
-
选择语言:中文或英文

-
安装信息摘要设置

- 安装目的地:显示安装位置,一般为硬盘,点击自定义,在点击“完成”进行分区:

- /boot:系统启动分区,推荐500M或1GB
- swap:交换分区,4G
- /:根分区,期望容量省略,表示将剩余空间全部分配
- 方法:点击下图的加号,设置挂载点及期望容量(重复多次),点击完成,点击接收更改





- 网络和主机名:打开网卡连接

- root账户密码设置:密码为OPENlab123

- 创建用户:创建一个普通账户fox,设置密码:OPENlab123

-
安装完成后点击"重启系统"

配置OpenEuler22.03
- 登录
- 账户:root
- 密码:OPENlab123

-
xshell7建立连接
-
关闭防火墙及SELinux
[root@server ~]# vi /etc/selinux/config
[root@server ~]# systemctl stop firewalld # 关闭防火墙
[root@localhost ~]# systemctl disable firewalld # 取消开机启动
- 修改主机名
[root@localhost ~]# hostnamectl set-hostname server # server为主机名
[root@server ~]# reboot # 重启
- 修改root密码
[root@server ~]# passwd root
更改用户 root 的密码 。
新的密码:
无效的密码: 密码少于 8 个字符
重新输入新的密码:
passwd:所有的身份验证令牌已经成功更新。
- 查看yum源
[root@server ~]# cat /etc/yum.repos.d/openEuler.repo
[root@server yum.repos.d]# yum makecache # 制作缓存
- 查看网卡配置文件
[root@server ~]# cat /etc/sysconfig/network-scripts/ifcfg-ens32
- 下载所需软件
[root@server ~]# yum install vim make gcc tree net-tools tar -y
- 测试
[root@server ~]# cat /etc/os-release # 查看系统信息 cat /etc/redhat-release
[root@server ~]# lscpu # 查看cpu信息
[root@server ~]# free -m # 查看内存信息
[root@server ~]# fdisk -l # 查看磁盘信息
[root@server ~]# top # 查看进程信息
[root@server ~]# ping -c 2 www.qq.com
- 制作快照:虚拟机菜单->快照->拍摄快照->命名为“初始”->拍摄
- 使用虚拟机进行克隆,命名为node1,启动后后需要更改主机名,重启生效,重新制作node1的快照
- 可以尝试安装桌面环境(可选)
# DDE是统信软件团队研发的一款功能强大的桌面环境
[root@server ~]# yum install dde -y # 安装包容量较大,建议课后进行
[root@server ~]# systemctl set-default graphical.target # 设置以图形界面方式启动
[root@server ~]# reboot
网络配置
可视化配置
格式
[root@server ~]# nmtui

实验
- 例:为当前网卡增加一个IP地址

[root@server ~]# nmcli c up ens32
[root@server ~]# nmcli c reload
[root@server ~]# ip addr
nmcli命令
格式:
[root@server ~]# nmcli --help
用法:nmcli [选项] 对象 { 命令 | help }
查看网卡信息:
[root@server ~]# nmcli c show
[root@server ~]# nmcli c show 网卡名 # 查看网卡详细信息,点q退出
[root@server ~]# nmcli dev status # 查看已有设备的状态
[root@server ~]# nmcli dev show # 查看所有硬件设备状态
激活网卡和关闭连接
[root@server ~]# nmcli c up 网卡名
[root@server ~]# nmcli c down 网卡名 # 停用连接
添加网络连接
[root@server ~]# nmcli c add type ethernet ifname ensens32 con-name ens33 autoconnect yes ip4 192.168.48.135/24 gw4 192.168.48.2
[root@server ~]# nmcli c up ens161 # 激活
[root@server ~]# nmcli c show
- 命令解释
- 关键字:nmcli c add type
- 网络类型:ethernet
- 现有网卡名:ifname ens32
- 新网络名称:con-name ens33
- 开启自动连接:autoconnect yes
- 新连接的IP地址与网关地址:ip4 192.168.48.135/24 gw4 192.168.48.2
修改网络连接
- 例:通过ens32连接设置静态ip地址:
[root@server ~]# nmcli c mod ens32 ipv4.method manual ipv4.addresses '192.168.48.150/24' ipv4.gateway '192.168.48.2' ipv4.dns '114.114.114.114'
[root@server ~]# nmcli c up ens32 # 激活
连接已成功激活(D-Bus 活动路径:/org/freedesktop/NetworkManager/ActiveConnection/7)
[root@server ~]# ip a # 查看结果
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: ens160: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP group default qlen 1000
link/ether 00:0c:29:dc:cf:14 brd ff:ff:ff:ff:ff:ff
altname enp3s0
inet 192.168.48.150/24 brd 192.168.48.255 scope global noprefixroute ens160
-
ipv4.method manual :手动获取(静态)
-
通过配置文件查看和编辑:
[root@server ~]# vim /etc/sysconfig/network-scripts/ifcfg-ens32
TYPE=Ethernet
PROXY_METHOD=none
BROWSER_ONLY=no
BOOTPROTO=none
DEFROUTE=yes
IPV4_FAILURE_FATAL=no
IPV6INIT=yes
IPV6_AUTOCONF=yes
IPV6_DEFROUTE=yes
IPV6_FAILURE_FATAL=no
NAME=ens32
UUID=b50354dd-8e11-4494-9072-a152ea6b0783
DEVICE=ens32
ONBOOT=yes
IPADDR=192.168.48.130
PREFIX=24
GATEWAY=192.168.48.2
DNS1=114.114.114.114
删除网络连接
[root@server ~]# nmcli c show # 查看网络连接
[root@server ~]# nmcli c del ens32 # 删除
[root@server ~]# nmcli c show # 再次查看
- 以上做完之后需要恢复快照
第十一章 MySql服务
什么是数据库
数据:
- 描述事物的符号记录, 可以是数字、 文字、图形、图像、声音、语言等,数据有多种形式,它们都可以经过数字化后存入计算机。
数据库:
- 存储数据的仓库,是长期存放在计算机内、有组织、可共享的大量数据的集合。数据库中的数据按照一定数据模型组织、描述和存储,具有较小的冗余度,较高的独立性和易扩展性,并为各种用户共享,总结为以下几点:
- 数据结构化
- 数据的共享性高,冗余度低,易扩充
- 数据独立性高
- 数据由 DBMS 统一管理和控制(安全性、完整性、并发控制、故障恢复)
mysql概述
- MySQL是一个小型关系数据库管理系统,开发者为瑞典MySQL AB公司。在2008年1月16号被sun公司10亿美金收购。2009年,SUN又被Oracle以74亿美金收购。
- 目前MySQL被广泛地应用在Internet上的中小型网站中。由于体积小、速度快、总体拥有成本低,尤其是开放源代码这一特点,许多中小型网站为了降低网站总体拥有成本而选择了MySQL作为网站数据库。

版本及下载
- MySQL数据库存在多种版本,不同的版本在不同的平台上:https://dev.mysql.com/downloads/mysql/
- 也可以选择MySQL对应版本的,找到安装教程,如MySQL5.7为例:https://dev.mysql.com/doc/refman/5.7/en/installing.html
yum仓库安装
添加yum源
-
访问官方:https://www.mysql.com/
-
查看官方教程:https://dev.mysql.com/doc/refman/8.0/en/linux-installation-yum-repo.html
-
选择downloads页面的:MySQL Community (GPL) Downloads »


- 选择版本后下载yum源,注意:Euler22版本对应Centos8 即RedHat8

- 添加yum源
[root@server ~]# wget https://dev.mysql.com/get/mysql80-community-release-el8-9.noarch.rpm # 下载
[root@server ~]# rpm -ivh mysql80-community-release-el8-9.noarch.rpm # 安装
[root@server ~]# yum list | grep mysql
安装
root@server ~]# yum install mysql-community-server.x86_64
[root@server ~]# systemctl start mysqld # 启动,注意有d
[root@server ~]# systemctl status mysqld
[root@server ~]# grep 'temporary password' /var/log/mysqld.log
2023-07-09T02:38:36.368700Z 6 [Note] [MY-010454] [Server] A temporary password is generated for root@localhost: qQ6OmpD?8_.f # 查看初始登录密码
[root@server ~]# mysql -u root -p # 以root身份登录
Enter password: # 赋值初始登录密码
mysql> alter user 'root'@'localhost' identified by 'Admin123!'; # 设置新密码 8.4
mysql> alter user root@localhost identified with mysql_native_password by "Mysql@123";
mysql> show variables like 'validate_password.%'; # 查看密码设置默认的规则
+--------------------------------------+--------+
| Variable_name | Value |
+--------------------------------------+--------+
| validate_password.check_user_name | ON | # ON时,账户及密码不能相同
| validate_password.dictionary_file | | # 规则文件保存路径
| validate_password.length | 8 | # 密码长度
| validate_password.mixed_case_count | 1 | # 至少要包含大/小写字母的个数
| validate_password.number_count | 1 | # 至少要包含数字的个数
| validate_password.policy | MEDIUM | # 密码的验证强度等级
| validate_password.special_char_count | 1 | # 密码中特殊字符个数
+--------------------------------------+--------+
7 rows in set (0.01 sec)
# 默认为中级密码验证规则,密码长度8为,内容至少包含:一个大写字母、一个小写字母、一位数字和一个特殊字符
# 若密码不好记忆可以调低密码验证等级,在设置简单的密码,但生产中不推荐
mysql> set global validate_password.policy=low;
mysql> set global validate_password.length=6;
mysql> alter user 'root'@'localhost' identified by '123456';
mysql> exit
Bye
[root@server ~]# mysql -u root -p
Enter password: # 密码为123456
mysql> show databases; # 注意s和分号结尾
+--------------------+
| Database |
+--------------------+
| information_schema |
| mysql |
| performance_schema |
| sys |
+--------------------+
mysql> show global variables like 'port'; # 查看默认端口号
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| port | 3306 |
+---------------+------+
1 row in set (0.00 sec)
mysql> quit
Bye
本地RPM包安装
使用迅雷下载集合包
- 进入下载网站:https://downloads.mysql.com/archives/community/
- 如图:

上传数据
- 使用xftp将下载安装包上传到linux端
安装
[root@server ~]# cd /
[root@server /]# tar -xvf mysql-8.0.32-1.el9.x86_64.rpm-bundle.tar # 解压
[root@server /]# yum localinstall mysql-community-server-8.0.32-1.el9.x86_64.rpm \
mysql-community-client-8.0.32-1.el9.x86_64.rpm \ # 必须,客户端
mysql-community-common-8.0.32-1.el9.x86_64.rpm \ # 必须,公共库
mysql-community-icu-data-files-8.0.32-1.el9.x86_64.rpm \ # 必须,支持正则表达式的icu数据文件
mysql-community-client-plugins-8.0.32-1.el9.x86_64.rpm \ # 必须,客户端共享插件
mysql-community-libs-8.0.32-1.el9.x86_64.rpm # 不必须,开发库,开发跟MySql有关的C/C++ 项目时则需要
[root@server /]# cd ~
[root@server ~]# systemctl start mysqld
[root@server ~]# systemctl status mysqld # 查看状态
[root@server ~]# mysql -u root -p
Enter password:
ERROR 1045 (28000): Access denied for user 'root'@'localhost' (using password: NO) # 密码错误,需要重置密码
[root@server ~]# grep password /var/log/mysqld.log # 查询初始密码
2023-02-09T03:55:47.305118Z 6 [Note] [MY-010454] [Server] A temporary password is generated for root@localhost: q&2PO.yJZ+Hp
# q&2PO.yJZ+Hp为密码,需要复制
[root@server ~]# mysql -u root -p
Enter password: # 粘贴之前的密码
mysql> show databases;
ERROR 1820 (HY000): You must reset your password using ALTER USER statement before executing this statement. # 提示需要修改默认密码
mysql> alter user 'root'@'localhost' identified by 'MyNewPass1!'; # 修改密码
Query OK, 0 rows affected (0.01 sec)
mysql> exit
Bye
生产环境中使用通用二进制包安装 配置 编译 安装
作用
- 二进制包:源码包经过成功编译之后产生的包
- 优点:由于二进制包在发布之前就已经完成了编译的工作,因此用户安装软件的速度较快
- 注意:在生产环境中通用二进制包安装方法较为常用
软件包下载
- 网址:https://dev.mysql.com/downloads/mysql/
- 如图:

- 根据上图系统参数里的glibc版本和cpu架构选择对应的下载选项:

使用xftp将软件包上传到根目录
解压缩
[root@server ~]# cd /
[root@server /]# tar xvf mysql-8.0.33-linux-glibc2.17-x86_64-minimal.tar
# 解压缩后有三个子包
# mysql-8.0.33-linux-glibc2.17-x86_64-minimal.tar.xz:安装mysql必须的文件
# mysql-router-8.0.33-linux-glibc2.17-x86_64-minimal.tar.xz:官方提供的一个轻量级中间件,主要作用是在应用程序与MySQL服务器之间提供透明的路由方式,是高可用性 (HA) 解决方案的构建块
# mysql-test-8.0.33-linux-glibc2.17-x86_64-minimal.tar.xz:测试框架,用于做mysql 服务的单元,回归和一致性测试,并提供了运行单元测试和创建新单元测试的工具
# 继续解压缩
[root@server /]# tar xvf mysql-8.0.33-linux-glibc2.17-x86_64-minimal.tar.xz
[root@server /]# ls
使用前的准备
[root@server /]# mv mysql-8.0.33-linux-glibc2.17-x86_64-minimal /usr/local/mysql # 移动到默认安装目录,也可自行修改
[root@server /]# cd /usr/local/mysql
[root@server mysql]# groupadd mysql # 创建名为mysql的用户组
[root@server mysql]# useradd -r -g mysql -s /bin/false mysql # 创建名为 mysql的系统用户,将其添加到mysql用户组中,并设置其登录shell为/bin/false,以限制该用户的登录权限
[root@server mysql]# mkdir mysql-files # 创建一个名为 mysql-files 的目录,用于存放MySQL数据文件,一般存储备份数据
[root@server mysql]# chown mysql:mysql mysql-files # 将mysql-files目录的所有者和所属组设置为mysql用户和组
[root@server mysql]# chmod 750 mysql-files # 设置mysql-files目录的权限为 750,以确保只有 “mysql” 用户组的成员可以读取、写入和执行该目录
初始化软件
[root@server mysql]# bin/mysqld --initialize --user=mysql # 注意:需要复制密码
[root@server mysql]# bin/mysql_ssl_rsa_setup # 支持ssl,用于安全通信
[root@server mysql]# bin/mysqld_safe --user=mysql & # 使用后台方式以mysql用户身份启动 MySQL 服务器,mysqld_safe 是一个用于启动和监控 MySQL 服务器的脚本
# 注意:此时上述命令执行完毕处于后台运行状态,需要另行启动一个终端
[root@server ~]# ps -ef | grep mysql # 查看进程运行状态
[root@server ~]# cd /usr/local/mysql
[root@server ~]# bin/mysql -u root -p # 登录,可能报错
# 报错,需要找到下面的文件进行软连接
[root@server ~]# ln -s /usr/lib64/libncurses.so.6 /usr/lib64/libncurses.so.5
[root@server ~]# ln -s /usr/lib64/libtinfo.so.6 /usr/lib64/libtinfo.so.5
[root@server ~]# bin/mysql -u root -p
Enter password: # 粘贴之前的初始密码
mysql> alter user 'root'@'localhost' identified with mysql_native_password by '123456'; 修改密码
mysql> flush privileges; # 刷新
mysql>exit
[root@server ~]# ps -ef | grep mysql
[root@server ~]# kill -9 pid号 # 在当前终端关闭运行的mysql
设置mysql的配置文件
# 回到之前的终端,敲一个回车,显示进程以杀死
[root@server mysql]# vim /etc/my.cnf # 新建配置文件,输入以下内容:
[client]
port = 3306
socket = /tmp/mysql.sock
[mysqld]
server-id = 1
port = 3306
basedir = /usr/local/mysql
datadir = /usr/local/mysql/data
tmpdir = /tmp
socket = /tmp/mysql.sock
character-set-server = utf8mb4
collation-server = utf8mb4_general_ci
init_connect='SET NAMES utf8mb4'
default-storage-engine=INNODB
log_error = error.log
# 注意:以下是上述配置文件的解释
[client] # 客户端设置
port = 3306 # 默认端口号
socket = /tmp/mysql.sock # 启动套接字
[mysqld]
###############################基础设置#####################################
server-id = 1 # Mysql服务的唯一编号 每个mysql服务Id需唯一
port = 3306 # 端口号 3306
basedir = /usr/local/mysql # mysql安装根目录
datadir = /usr/local/mysql/data # mysql数据文件所在位置 没有改目录则创建
tmpdir = /tmp # 临时目录 比如load data infile会用到
socket = /tmp/mysql.sock # 设置socke文件所在目录
#数据库默认字符集,主流字符集支持一些特殊表情符号(特殊表情符占用4个字节)
character-set-server = utf8mb4
#数据库字符集对应一些排序等规则,注意要和character-set-server对应
collation-server = utf8mb4_general_ci
#设置client连接mysql时的字符集,防止乱码
init_connect='SET NAMES utf8mb4'
default-storage-engine=INNODB
###############################日志设置#####################################
#数据库错误日志文件
log_error = error.log
配置启动脚本
[root@server ~]# cd /usr/local/mysql/support-files
[root@bogon support-files]# dnf install chkconfig-1.24-1.el9.x86_64
[root@server support-files]# cp -a mysql.server /etc/init.d/mysql.server # 拷贝启动脚本
[root@server support-files]# cd /etc/init.d
[root@server init.d]# vim mysql.server # 增加=之后的内容
basedir=/usr/local/mysql
datadir=/usr/local/mysql/data
[root@server ~]#chkconfig --add mysql.server 添加到开机自启动服务中
[root@server ~]#chkconfig mysql.server on 开启开机启用
[root@server ~]#systemctl daemon-reload 如果重新修改配置后,重载
[root@server ~]# systemctl start mysql
[root@server ~]# vim ~/.bash_profile # 设置环境变量需添加如下语句
export PATH=$PATH:/usr/local/mysql/bin
[root@server ~]# source ~/.bash_profile
[root@server ~]# mysql -uroot -p
第二部分 shell脚本编程
第一章、shell入门基础
1.1 为什么学习和使用Shell编程
对于一个合格的系统管理员来说,学习和掌握Shell编程是非常重要的。通过编程,可以在很大程度上简化日常的维护工作,使得管理员从简单的重复劳动中解脱出来。
Shell程序的特点:
1、简单易学。
2、解释性语言,不需要编译即可执行
1.2 什么Shell
在学习Shell编程之前,必须弄清楚什么是Shell。为了能够使读者在学习具体的Shell编程之前对Shell有个基本的了解,本节将对Shell进行概括性的介绍,包括Shell的起源、功能和分类。
1.2.1 shell起源
- 1964年,美国AT&T公司的贝尔实验室、麻省理工学院及美国通用电气公司共同参与开始研发一套可以安装在大型主机上的多用户、多任务的操作系统,该操作系统的名称为Multics。
- 1970年,丹尼斯•里奇和汤普逊启动了另外一个新的多用户、多任务的操作系统的项目,他们把这个项目称之为UNICS。
- 1973年,使用C语言重写编写了Unix。通过这次编写,使得Unix得以移植到其他的小型机上面。
- 1979年,第一个重要的标准UNIX Shell在Unix的第7版中推出,并以作者史蒂夫•伯恩(Stephen Bourne)的名字命名,叫做Bourne Shell,简称为sh。
- 20世纪70年代末,C Shell作为2BSD UNIX的一部分发布,简称csh。
- 之后又出现了许多其他的Shell程序,主要包括Tenex C Shell(tcsh)、Korn Shell(ksh)以及GNU Bourne-Again shell(bash)。
1.2.2 什么是shell

Shell又称命令解释器,它能识别用户输入的各种命令,并传递给操作系统。它的作用类似于Windows操作系统中的命令行,但是,Shell的功能远比命令行强大的多。在UNIX或者localhost中,Shell既是用户交互的界面,也是控制系统的脚本语言。
1.3 shell的分类
-
Bourne Shell:标识为sh,该Shell由Steve Bourne在贝尔实验室时编写。在许多Unix系统中,该Shell是root用户的默认的Shell。
-
Bourne-Again Shell:标识为bash,该Shell由Brian Fox在1987年编写,是绝大多数localhost发行版的默认的Shell。
-
Korn Shell:标识为ksh,该Shell由贝尔实验室的David Korn在二十世纪八十年代早期编写。它完全向上兼容 Bourne Shell 并包含了C Shell 的很多特性。
-
C Shell:标识为csh,该Shell由Bill Joy在BSD系统上开发。由于其语法类似于C语言,因此称为C Shell。
如何查看当前系统支持的shell?
[root@localhost ~]# cat /etc/shells [root@HAHA ~]# cat /etc/shells /bin/sh /bin/bash /usr/bin/sh /usr/bbash
如何查看当前系统默认shell?
[root@localhost ~]# echo $SHELL
/bin/baSh
1.4 程序设计语言shell特性
Shell不仅仅是充当用户与UNIX或者localhost交互界面的角色,还可以作为一种程序设计语言来使用。通过Shell编程,可以实现许多非常实用的功能,提高系统管理的自动化水平。本节将介绍作为程序设计语言的Shell的一些特性。
shell脚本
如果有一系列经常需要使用的命令,把它存储在一个文件里,shell可以读取这个文件并顺序执行其中的命令,这样的文件就叫shell脚本。shell脚本按行解释。
(1)顺序执行:逐条执行(自上而下循环执行)
(2)选择执行:代码有一个分支:条件满足时才会执行
两个以上分支:只执行其中一个满足条件的分支
(3)循环执行:代码片断(循环体)要执行0,1或多个来回
shell脚本语言是实现linux/Unix系统管理及自动化运维所必备的重要工具,linux/unix系统的底层及基础应用软件的核心大多都涉及shell脚本的内容。
1.4.1编程语言和脚本语言区别
脚本语言含义: shell PHP Python JavaScript Perl Ruby
脚本语言是为了缩短传统的编写-编译-链接-运行过程而创建的计算机编程语言。和传统的Java,c++等编程语言不同,脚本语言不需要编译器,它需要的是解释器。也就是说,脚本语言是解释执行的,例如有一款专用的软件,而这款专用的软件上面执行特定的操作才能和我的软件进行交互,而这个操作的集合就是解释器,进行操作就是脚本语言,当我们将这个软件操作组织起来完成一个任务的时候,这就是在运用脚本语言进行编程。
编程(译)语言含义:java c c++
编程语言是用来定义计算机程学的形式语言,是一种将程序员所定义的代码,编译即翻译成计算机所认识的二进制代码的工具,所以编译语言需要编译器。
编译器和解释器最大的不同,就是一个面向的是计算机,一个面向的是某个特定的软件或者计算机某一个部分。(移植性较差,但运行效率高)
比较
1.脚本语言不需要编译器因而省去了编译的过程减少了开发的时间,而编程语言需要编译所以时间更长一点
2.脚本语言是一种动态语言,也就是说可以实时的更改代码,而不需要将程序停止下来,这是一种高级特性。而Java等编程语言是静态的语言,一旦编译完成并且运行就不能更改代码,除非将程序停止下来。
3.脚本语言非常容易学习,但是不够全面缺乏系统性而且语法较为散漫。而高级编程语言虽然相对难学,但是规则强可以编程出简洁美观的代码,并且可读性也相对较强。
4.一般来说脚本语言通用性较差,但是可以通过专门的应用来调整。
5.随着技术的发展,其实脚本语言变得越来越强,和编程语言的界限也比较模糊,比如Python,可以将它视为编程语言了,因为它很强大。
shell脚本与php/perl/python语言的区别和优势?
shell脚本的优势在于处理操作系统系统底层的业务(linux系统内部应用的都是shell脚本来完成)因为有大量的linux系统命令为他做支撑。2000多个个命令都是shell脚本编程的有力支撑,特别是grep、awk、sed等。例如:一键安装软件、优化监控报警脚本,常规的业务应用,shell开发更简单快捷,符合韵味的简单、易用高效原则。
PHP、python优势在于开发运维工具以及web界面的管理工具,web业务的开发等。处理一键软件安装、优化、报警脚本。常规业务的应用等php/python也是能够做到的。但是开发效率和shell比差很多,代码量多更复杂。
1.5 如何学好shell
学好shell编程基础知识
- 熟练使用vi(vim)编辑器 注释:3,6 s/^/# /
- 熟练掌握Linux基本命令
- 熟练掌握文本三剑客工具(grep、sed、awk)
- 熟悉常用服务器部署、优化、日志及排错
如何学好shell编程
1、掌握Shell脚本基本语法
2、形成自己的脚本开发风格
3、从简单做起,简单判断,简单循环
4、多模仿,多参考资料练习,多思考
5、学会分析问题,逐渐形成编程思维
6、编程变量名字要规范,采用驼峰语法表示
7、不要拿来主义,特别是新手
1.6 Shell脚本的基本元素
对于一个基本的Shell程序来说,应该拥有以下基本元素: .sh /script/user.sh
第1行的“#!/bin/bash”。(注:脚本用什么来解释 she-Bang 魔数)
注释:说明某些代码的功能。
可执行语句:实现程序的功能。
16.1 Shell脚本中的注释和风格**
通过在代码中增加注释可以提高程序的可读性。 传统的Shell只支持单行注释,其表示方法是一个井号“#”,从该符号开始一直到行尾都属于注释的内容。
例如
#comment1
#comment2
#comment3
…
//
/*
*/
如何实现多行注释?
用户还可以通过其他的一些变通的方法来实现多行注释,其中,最简单的方法就是使用冒号“:”配合here document,语法如下:
:<<BLOCK
....注释内容
BLOCK
1.7 Shell脚本编写规范
(1)开头指定脚本解释器 #!/bin/sh或#!/bin/bash 其他行#表示注释 名称见名知义 backup_mysql.sh,以sh结尾
(2)开头加版本版权等信息
Date:创建日期
Author:作者
Mail:联系方式
Function:功能
Version:版本
(3)脚本中尽量不用中文注释
别吝啬添加注释,必要的注释方便自己别人理解脚本逻辑和功能;
尽量用英文注释,防止本机或切换系统环境后中文乱码的困扰;
单行注释,可以放在代码行的尾部或代码行的上部;
多行注释,用于注解复杂的功能说明,可以放在程序体中,也可以放在代码块的开始部分,代码修改 时,对修改的内容
(4)多使用内部命令 内部命令可以在性能方面为你节省很多。
[root@HAHA ~]# echo $[3+4]
7
[root@HAHA ~]# expr 3 + 5
8
[root@HAHA ~]# time echo $[4+4]
8
real 0m0.000s
user 0m0.000s
sys 0m0.000s
[root@HAHA ~]# time expr 4 + 4
8
real 0m0.002s
user 0m0.000s
sys 0m0.002s
(5)没有必要使用cat命令 vim % co $ grep root /etc/passwd cat /etc/passwd | grep root
eg:cat /etc/passwd | grep guru
使用以下方式即可
eg:grep guru /etc/passwd
(6)代码缩进
代码缩进示 (shell没有强制要求,建议缩进提交代码的可阅读性,更有层次感。python严格缩进标识代码块)
#!/bin/bash
i=1
while [ $i -le 10 ]
do
if [ $i -le 9 ]
then
username=user0$i
else
username=user$i
fi
! id $username &>/dev/null && {
useradd $username
echo $username | passwd --stdin $username &>/dev/null
}
let i++
done
(7)仔细阅读出错信息 有时候我们修改了某个错误并再次运行后,系统依旧会报错。然后我们再次修改,但系统再次报错。这可能会持续很长时间。但实际上,旧的错误可能已经被纠正,只是由于出现了其它一些新错误才导致系统再次报错
(8)脚本以.sh为扩展名
eg:script-name.sh
如何快速生成脚本开头的版本版权注释信息
[root@ scripts]# cat ~/.vimrc
autocmd BufNewFile *.py,*.cc,*.sh,*.java exec ":call SetTitle()"
func SetTitle()
if expand("%:e") == 'sh'
call setline(1,"#!/bin/bash")
call setline(2,"##############################################################")
call setline(3, "# File Name: ".expand("%"))
call setline(4, "# Version: V1.0")
call setline(5, "# Author: xx")
call setline(6, "# Email: xx@163.com")
call setline(7, "# Organization: http://www.xx.com/xx/")
call setline(8, "# Created Time : ".strftime("%F %T"))
call setline(9, "# Description:")
call setline(10,"##############################################################")
call setline(11, "")
endif
endfunc
1.8 shell脚本执行
方法一:当前目录下./a.sh 文件需要执行权限
方法二:绝对路径 /test/a.sh 文件需要执行权限
方法三:用sh 或bash来执行 bash a.sh 文件不要执行权限 —建议使用方法
方法四:用source a.sh 或 . a.sh 执行会开启子shell 文件不要执行权限 (一般不用 vim /etc/init.d/network )
区别:
1、方法三:可以在脚本中不指定解释器,脚本可以没有执行权限
2、方法一和方法二脚本需要有执行权限,./script_name.sh 或/path/script_name.sh bash a.sh

3、方法四:当前shell执行,方法1-3开启子shell

自定义脚本
写脚本:show_info.sh
输出: 当前系统时间是:xxxx
输出: 当前用户: $USER
vim tab键的缩进为4个空格
"add by school1024.com`
set ts=4
set softtabstop=4
set shiftwidth=4
set expandtab
set autoindent
ts是tabstop的缩写,设TAB宽度为4个空格。
softtabstop 表示在编辑模式的时候按退格键的时候退回缩进的长度,当使用 expandtab 时特别有用。
shiftwidth 表示每一级缩进的长度,一般设置成跟 softtabstop 一样。 expandtab表示缩进用空格来表示,noexpandtab 则是用制表符表示一个缩进。 autoindent自动缩进
1.8.1 脚本检测
bash -n 脚本语法检测,不执行脚本文件
bash -x 跟踪脚本执行
shellcheck 脚本文件检测脚本 …
1.9 shell特性回顾
1.echo linux打印命令
选项:-n 取消输出后行末的换行符号
-e 支持反斜线控制的字符转换 \n \t !
| 控制字符 | 作 用 |
|---|---|
| \ | 输出\本身 ! |
| \a | 输出警告音 |
| \b | 退格键,也就是向左删除键 |
| \c | 取消输出行末的换行符。和“-n”选项一致 |
| \e | Esc键向右删除键 |
| \f | 换页符 |
| \n | 换行符 |
| \r | 字符替换 |
| \t | 制表符,也就是Tab键 |
| \v | 垂直制表符 |
| \0nnn | 按照八进制 ASCII 码表输出字符。其中 0 为数字 0,nnn 是三位八进制数 eg:141 这个八制数在 ASCII 码中代表小写的"a",其他的以此类推echo -e “\0141\t\0142” |
| \xhh | 按照十六进制 ASCLL 码表输出字符。其中 hh 是两位十六进制数 [root@localhost ~]# echo -e “\x61\t\x62\t\x63\n\x64\t\x65\t\x66” a b c d e f #如果按照十六进制ASCII码同样可以输出 |
[root@localhost ~]# echo -e "\e[1;31m abed \e[0m"
echo -e "\033[1;31;42m abcd \033[0m"
这条命令会把 abcd 按照红色输出。
解释一下这个命令:\e[字体控制选项;字体背景颜色;文字颜色m 字符串 \e[0m 代表颜色输出结束
文字颜色:30m=黑色,31m=红色,32m=绿色,33m=黄色,34m=蓝色,35m=洋红,36m=青色,37m=白色。
字体背景色:40m=黑色,41m=红色,42m=绿色,43m=黄色,44m=蓝色,45m=洋红,46m=青色,47m=白色。
字体控制选项:1表示高亮,4表示下划线,5颜色闪烁
2.printf
printf 命令模仿 C 程序库(library)里的 printf() 程序。
printf 由 POSIX 标准所定义,因此使用 printf 的脚本比使用 echo 移植性好。
printf 使用引用文本或空格分隔的参数,外面可以在 printf 中使用格式化字符串,还可以制定字符串的宽度、左右对齐方式等。默认 printf 不会像 echo 自动添加换行符,我们可以手动添加 \n。
printf 命令的语法:
printf format-string [arguments...]
参数说明:
- format-string: 为格式控制字符串%10s %c %d %f
- arguments: 为参数列表。
实例
$ echo "Hello, Shell"
Hello, Shell
$ printf "Hello, Shell**\n**"
Hello, Shell
$
接下来,我来用一个脚本来体现 printf 的强大功能:
实例
printf "%-10s %-8s %-4s\n" 姓名 性别 体重kg
printf "%-10s %-8s %-4.2f\n" 郭靖 男 66.1234
printf "%-10s %-8s %-4.2f\n" 杨过 男 48.6543
printf "%-10s %-8s %-4.2f\n" 郭芙 女 47.9876
执行脚本,输出结果如下所示:
姓名 性别 体重kg
郭靖 男 66.12
杨过 男 48.65
郭芙 女 47.99
%s %c %d %f 都是格式替代符,%s 输出一个字符串,%d 整型输出,%c 输出一个字符,%f 输出实数,以小数形式输出。
%-10s 指一个宽度为 10 个字符(- 表示左对齐,没有则表示右对齐),任何字符都会被显示在 10 个字符宽的字符内,如果不足则自动以空格填充,超过也会将内容全部显示出来。
%-4.2f 指格式化为小数,其中 .2 指保留2位小数,4是总长度啊
实例
printf "%d %s\n" 1 "abc"
# 单引号与双引号效果一样*
printf '%d %s\n' 1 "abc"
# 没有引号也可以输出
printf %s abcdef
# 格式只指定了一个参数,但多出的参数仍然会按照该格式输出,format-string 被重用
printf %s abc def
printf "%s\n" abc def
printf "%s %s %s\n" a b c d e f g h i j
# 如果没有 arguments,那么 %s 用NULL代替,%d 用 0 代替*
printf "%s and %d \n"
执行脚本,输出结果如下所示:
1 abc
1 abc
abcdefabcdefabc
def
a b c
d e f
g h i
j
and 0
**3、命令执行顺序 **
; --命令的顺序执行 date; ls -l /etc/passwd
&&与 --前面命令执行不成功,后面的命令不执行 id haha && userdel -r haha
||或–如果前面命令成功,后面就不执行,如果前面不成功后面就执行
! 非
4、通配符 (文件名通用匹配) 正则符 (文件内容,标准输出结果)
通配符是系统命令使用,一般用来匹配文件名或者什么的用在系统命令中。而正则表达式是操作字符串,以行尾单位来匹配字符串使用的
? 匹配一个任意字符
`*` 匹配 0 个或任意多个任意字符,也就是可以匹配任何内容
[a1b2] 匹配中括号中任意一个字符。
[a-z] 匹配中括号中任意一个字符, -代表一个范围。
[^a-z] 逻辑非,表示匹配不是中括号内的一个字符。
[a-z] [0-9] [a-zA-Z] [^0-9a-zA-Z]
{1,2,3,4}
mkdir {1,2,3,4}
[[:class:]]:匹配一个属于指定字符类中的字符,[:class:]表示一种字符类,比如数字、大小写字母等。
常用字符类:
[:alnum:] :匹配任意一个字母或者数字 ,传统UNIX写法: a-zA-Z0-9
[:alpha:] :匹配任意一个字母,传统UNIX写法: a-zA-Z [:alpha:]
[:digit:] :匹配任意一个数字,传统UNIX写法: 0-9
[:lower:] : 匹配任意一个小写字母,传统UNIX写法: a-z
[:upper:] : 匹配任意一个大写字母,传统UNIX写法:A-Z
[:space:] :空白字符
[:punct:] : 标点符号
注意事项:在使用专属字符集的时候,字符集之外还需要用 [ ] 来包含住,否则专用字符集不会生效,例
如 [[:space:]]
[root@HAHA ~]# grep '[[:upper:]]' a
AAA
BBB
CCC
通配符常用语法:
1、匹配任意长度的任意字符,就是说“什么都可以”。
ll *
2、?:与任何单个字符匹配。
ll myfile?
3、[ ]:与?相似,可以匹配一个括号内的字符,也可以用“-”进行范围指定。
myfile[12] #将与myfile1和myfile2匹配
/etc/[0-9]
#将列出 /etc 中以数字开头的所有文件。
ls /tmp/[A-Za-z] #将列出/tmp中以大写字母或小写字母开头的所有文件。
4、[!]:括号内的“!”代表非的意思,即不与括弧中的字符匹配。
rm myfile[!9] #删除除了myfile9之外的名为myfile加一个字符的所有文件
5、{}生成序列
touch file{1..9}.txt
#当前路径生成file1.txt~file9.txt。{a..f}代表a-f,不连续的使用,分 隔,比如f{1,3,5}.txt
6、使用{}备份
cp file1.txt{,.bak} #将fiel1.txt复制一份叫file1.txt.bak
cp file{2,22}.txt #复制file2.txt为file22.txt
示例:
1、列出/etc/目录中不是以字母a到n开头的,并且以.conf结尾的文件
ls /etc/[!a-n]*.conf
2、列出/etc/目录中以字母a到n开头的,并且以.conf结尾的文件
ls /etc/[a-n]*.conf
3、列出/bin/下以 c或k开头的文件名
ls /bin/[ck]*
1、创建用户haha且用户的密码同用户名,而且要求,添加密码完成后不显示passwd命令的执行结果信息;
useradd haha && echo "haha" | passwd --stdin haha > /dev/null
2、每个用户添加完成后,都要显示用户某某已经成功添加;
useradd user1 && echo "user1已经成功添加"
如果用户存在,就显示用户已存在;否则,就添加此用户;
(id user1 &>/dev/null && echo "user已存在") || useradd user1
如果用户不存在,就添加;否则,显示其已经存在;
!id user1 &>/dev/null && (useradd user1;echo user1 |passwd --stdin user1) || echo "用户已存在"
!id user1 &>/dev/null && (useradd user1 && echo user1 |passwd --stdin user1) || echo "用户已存在"
! id user1 && useradd user1 || echo "user1 exists."
如果用户不存在,添加并且给密码;否则,显示其已经存在;
练习,写一个脚本,完成以下要求:
1、添加1个用户user1;但要先判断用户是否存在,不存在而后再添加;
2、最后显示当前系统上共有多少个用户;
练习:写一个脚本
在当前主机编写脚本文件/history_max.sh显示主机执行频率最高的前5个命令.
判断主机是否存在rhel用户如果存在则设置密码为redhat,提示用户存在密码创建成功,如果不存在则创建用户并设置密码,提示用已成功创建。
id rhel &>/dev/null && (echo “redhat” | passwd --stdin rhel && echo 密码设置成功 ) || useradd rhel && (echo redhat | passwd --stdin rhel && echo 用户创建密码设置成功)
第二章、变量和引用
2.1 深入认识变量
在程序设计语言中,变量是一个非常重要的概念。也是初学者在进行Shell程序设计之前必须掌握的一个非常基础的概念。只有理解变量的使用方法,才能设计出良好的程序。本节将介绍Shell中变量的相关知识。
2.1.1 什么是变量
顾名思义,变量就是程序设计语言中的一个可以变化的量,当然,可以变化的是变量的值。变量几乎所有的程序设计语言中都有定义,并且其涵义也大同小异。从本质上讲,变量就是在程序中保存用户数据的一块内存空间而变量名就是这块内存空间的地址。
在程序的执行过程中,保存数据的内存空间的内容可能会不断地发生变化,但是,代表内存地址的变量名却保持不变。
2.1.2 变量的命名
在Shell中,变量名可以由字母、数字或者下划线组成,并且只能以字母或者下划线开头。对于变量名的长度,Shell并没有做出明确的规定。因此,用户可以使用任意长度的字符串来作为变量名。但是,为了提高程序的可读性,建议用户使用相对较短的字符串作为变量名。
在一个设计良好的程序中,变量的命名有着非常大的学问。通常情况下,用户应该尽可能选择有明确意义的英文单词作为变量名,尽量避免使用拼音或者毫无意义的字符串作为变量名。这样的话,用户通过变量名就可以了解该变量的作用。
什么是驼峰语法?
骆驼式命名法就是当变量名或函数名是由一个或多个单词连结在一起,而构成的唯一识别字时,第一个单词以小写字母开始;从第二个单词开始以后的每个单词的首字母都采用大写字母或者大驼峰法把第一个单词是大写,后面的单词首字母也大写例如:myFirstName、MYLastName,这样的变量名看上去就像骆驼峰一样此起彼伏,故得名。
除了驼峰命名法,另外还有匈牙利命名法。基本原则是:变量名=属性+类型+对象描述。匈牙利命名法关键是:标识符的名字以一个或者多个小写字母开头作为前缀;前缀之后的是首字母大写的一个单词或多个单词组合,该单词要指明变量的用途。比如m_lpszStr, 表示指向一个以0字符结尾的字符串的长指针成员变量。属性部分:
g_ 全局变量
c_ 常量
m_ c++类成员变量
s_ 静态变量
类型部分:
数组 a
指针 p
函数 fn_
另外,有些程序员喜欢用下划线。比如file_name.
例如,下面的变量名都是非常好的选择
PATH=/sbin
UID=100
JAVA_HOME="/usr/lib/jvm/jre-1.6.0-openjdk.x86_64/bin/../.."
SSHD=/usr/sbin/sshd
2.1.3 shell弱类型语言
Shell是一种动态类型语言和弱类型语言,即在Shell中,变量的数据类型毋需显示地声明,变量的数据类型会根据不同的操作有所变化。准确地讲,Shell中的变量是不分数据类型的,统一地按照字符串存储。但是根据变量的上下文环境,允许程序执行一些不同的操作,例如字符串的比较和整数的加减等等。
什么是弱类型语言、强类型语言?
强类型和弱类型主要是站在变量类型处理的角度进行分类的。
强类型是指不允许隐式变量类型转换,弱类型则允许隐式类型转换。
换句话说:
-
强类型语言,当你定义一个变量是某个类型,如果不经过代码显式转换(强制转化)过,它就永远都是这个类型,如果把它当做其他类型来用,就会报错
-
弱类型语言,你想把这个变量当做什么类型来用,就当做什么类型来用,语言的解析器会自动(隐式)转换。
比如:
C语言定义变量,int+变量名,实则前面的int就似给变量内存划分了等级,int定义整形所以空间里只能存放整形,这就是强类型
php、C#和Python等都是强类型语言。
2.1.4 变量的分类
在Shell中,通常情况下用户可以直接使用变量,而毋需先进行定义,当用户第一次使用某个变量名时,实际上就同时定义了这个变量,在变量的作用域内,用户都可以使用该变量。
变量定义示例:变量名=变量值
#!/bin/bash
#定义变量a
=1
#定义变量b
b="hello world"
#定义变量c
c="hello world"
#定义备份路径
bak_dir=/data/backup
#!/bin/bash
#定义变量x,并且赋值为123
x =123
1_a=123
#变量x加1
let "x += 1" x=x+1
#输出变量x的值
echo "x = $x"
#显示空行
echo
#替换x中的1为abc,并且将值赋给变量y
y=${x/1/abc}
#输出变量y的值
echo "y = $y"
#声明变量y
declare -i y
#输出变量y的值
echo "y = $y"
注意:
-
“=”前后不能有空格
[root@localhost ~]# a= 3 -bash: 3: 未找到命令 [root@localhost ~]# b =4 -bash: b: 未找到命令 -
字符串类型建议用引号括起来,尤其是特殊字符或有空格
stu_name="zhang san"
1.自定义变量
-
定义变量:变量名=变量值 变量名必须以字母或下划线开头,区分大小写 ip1=192.168.2.115
本地(自定义变量)变量 环境变量 export
-
引用变量:$变量名 或 ${变量名}
-
查看变量:echo $变量名 set(所有变量:包括自定义变量和环境变量)env printenv 例如env |grep back_dir2
-
取消变量:unset 变量名
-
作用范围:仅在当前shell中有效
2.环境变量 定义环境变量:
方法一 export back_dir2=/home/backup
方法二 back_dir1=/home/backup export back_dir1 将自定义变量转换成环境变量
变量作用范围: 在当前shell和子shell有效
==========================================
C语言 局部变量 vs 全局变量
SHELL 自定义变量 vs 环境变量
=========================================
示例:
TZ=Asia/Shanghai
export TZ
设置java环境变量 https://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
#配置环境变量/etc/profile
export JAVA_HOME=/usr/java/jdk1.6.0_45
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$PATH:$JAVA_HOME/bin
#使配置生效 #source /etc/profile
#检测: # java –version
java version "1.6.0_45"
Java(TM) SE Runtime Environment (build 1.6.0_45-b06)
Java HotSpot(TM) 64-Bit Server VM (build 20.45-b01, mixed mode
#也可以脚本形式(比如java.sh)定义在/etc/profile.d/下面
让环境变量的修改在退出shell再次登陆时仍然有效,需要在相关配置文件中修改。
bash的初始化文件有:/etc/profile、/bash_profile、/.bash_login、/profile、/.bashrc、/etc/bashrc

实现的方向是主线流程,虚线的方向则是被调用的配置文件su root
1)/etc/profile存放一些全局(共有)变量,不管哪一个用户,登录时都会读取该文件。通常设置一些shell变量PATH,USER,HOSTNAME和HISTSIZE
2)~/.bash_profile:每个用户都可使用该文件输入专用于自己使用的shell信息,当用户登录时,该文件仅仅执行一次!默认情况下,他设置一些环境变量,执行用户的.bashrc文件。
3)~/.bashrc:该文件包含专用于你的bash shell的bash信息,当登录时以及每次打开新的shell时,该文件被读取。
4)/etc/bashrc:为每一个运行bash shell的用户执行此文件,当bashshell被打开时该文件被读取。
区别:bash_profile只会在会话开始(登陆)时读取一次,bashrc文件每次打开终端都会读取。
定义环境变量,配置文件读取顺序
(会继承上一个shell的全部变量)
1)配置文件的执行顺序 su - root
/etc/profile.d/test.sh
/etc/profile
/root/.bashrc
/etc/profile
~/.bash_profile
2)登录式shell的配置文件执行顺序
(清除所有变量,通过文件重新读入)
a.直接通过终端输入账号密码进行登陆
b.使用su - USERNAME切换用户
执行顺序:(影响该shell的配置文件)
/etc/profile-->/etc/profile.d/*.sh-->/etc/bashrc-->~./.bashrc-->~/.bash_profile
3)非登录式shell配置胚子文件执行顺序
a. su UserName
b.图形界面打开终端
c.执行脚本(进入子shell) ./
d.任何其他的bash实例
执行顺序(影响该shell的配置文件)
~/.bashrc-->/etc/bashrc--->/etc/profile.d/*.sh
交互式shell和非交互式shell
交互式:正常的命令行
非交互式shell:shell脚本
bash内置环境变量
shell程序在运行时,会接受一组变量来确定登录用户名、命令路径、终端类型、登录目录等等,这些变量就是环境变量。shell内置的环境变量是所有的shell程序都可以使用的变量,环境变量会影响所有的脚本的执行结果。
| 变量 | 说明 |
|---|---|
| PATH | 命令的搜索路径,以冒号作为分隔符 |
| HOME | 用户的家目录的路径,是cd命令的默认参数 |
| COLUMNS | 命令行编辑模式下可使用命令的长度 |
| HISTFILE | 命令历史的文件路径 |
| HISTFILESIZE | 命令历史中包含的最大行数 |
| HISTSIZE | history命令输出的记录数 |
| LOGNAME | 当前用户的名字 |
| SHELL | 当前使用的shell |
| PWD | 当前的工作目录 |
3.位置变量
$1 $2 $3 $4 $5 $6 $7 $8 $9 ${10}
编写一个shell脚本,当命令行或者从其他shell脚本中调用它的时候,这个脚本接受若干参数。这些选项是通过linux作为位置参数提供给shell程序的。在shell脚本中应有变量,接受实参,这类变量的名称很特别分别为1,2,3…这类变量称为位置变量,位置参数1存放在位置变量1中,位置参数2存放在位置变量2中,…来访问。
4.预定义变量
$0 脚本名 echo “显示脚本文件名” $0 || echo “显示脚本文件名” basename $0 dirname
$* 所有的参数
$@ 所有的参数
$# 参数的个数
$$ 当前进程的PID
$! 上一个后台进程的PID
$? 上一个命令的返回值 0表示成功 [0-255]
$_ 匹配上一个命令的最后一参数
(注:127找不到命令 2没有文件或目录 )
示例1:位置参数和预定义变量
vim test.sh
echo "第2个位置参数是$2"
echo "第1个位置参数是$1"
echo "第4个位置参数是$4"
echo "所有参数是: $*"
echo "所有参数是: $@"
echo "参数的个数是: $#"
echo "当前进程的PID是: $$"
echo '$1='$1
echo '$2='$2
echo '$3='$3
echo '$*='$*
echo '$@='$@
echo '$#='$#
echo '$$='$$
示例2:$?和位置变量
# vim ping.sh
#!/bin/bash
ping -c2 $1 &>/dev/null
if [ $? = 0 ];then
echo "host $1 is ok"
else
echo "host $1 is fail"
fi
# chmod a+x ping.sh
# ./ping.sh 192.168.2.25
shift命令: 剔除
当Shell程序不知道其个数时,可以把所有参数一起赋值给变量$*。若用户要求Shell在不知道位置变量个数的情况下,还能逐个的把参数一一处理。在 shift命令执行前变量的值在,shift命令执行后就不可用了。
示例如下:
echo "参数个数$#“
echo "所有参数$*"
shift
echo "参数个数$#“
echo "所有参数$*"
shift 3
echo "参数个数$#“
echo "所有参数$*"
for i in 1 3 4;do
useradd $1
shift
done
5.只读变量
只读变量
将变量配置成为 readonly 类型,该变量不可被更改内容,也不能 unset -
定义方法:
方法一: readonly [-fap] [变量定义] -f 定义只读函数 -a 定义只读数组变量 -p 显示系统中全部的只读变量列表
方法二: declare –r 变量定义
取消变量 unset
选项:-f 取消的是函数
-v 取消的是变量
如果没有指选项,首先尝试取消变量,如果失败尝试取消函数。
unset name
注意:Some variables cannot be unset; also see `readonly'.
只读变量不能取消。
只读变量:值不能被修改;不能取消
declare命令
declare为shell指令,在第一种语法中可用来声明变量并设置变量的属性([rix]即为变量的属性),在第二种语法中可用来显示shell函数。若不加上任何参数,则会显示全部的shell变量与函数(与执行set指令的效果相同)。
语法:declare [+/-][rxi][变量名称=设置值] 或 declare -f
- +/- "-“可用来指定变量的属性,”+"则是取消变量所设的属性。
- -f 仅显示函数。
- r 将变量设置为只读。
- x 指定的变量会成为环境变量,可供shell以外的程序来使用。
- i [设置值]可以是数值,字符串或运算式。
声明整数型变量
# declare -i ab //声明整数型变量
# ab=56 //改变变量内容
# echo $ab //显示变量内容
56
改变变量属性
# declare -i ef //声明整数型变量
# ef=1 //变量赋值(整数值)
# echo $ef //显示变量内容
1
# ef="wer" //变量赋值(文本值)
# echo $ef
0
# declare +i ef //取消变量属性
# ef="wer"
# echo $ef
wer
设置变量只读
# declare -r ab //设置变量为只读
# ab=88 //改变变量内容
-bash: ab: 只读变量
# echo $ab //显示变量内容
56
声明数组变量
# declare -a cd='([0]="a" [1]="b" [2]="c")' //声明数组变量
# echo ${cd[1]}
b //显示变量内容
# echo ${cd[@]} //显示整个数组变量内容
a b c
显示函数
# declare -f
command_not_found_handle ()
{
if [ -x /usr/lib/command-not-found ]; then
/usr/bin/python /usr/lib/command-not-found -- $1;
return $?;
else
if [ -x /usr/share/command-not-found ]; then
/usr/bin/python /usr/share/command-not-found -- $1;
return $?;
else
return 127;
fi;
fi
}
面试重点:history
1、让history命令显示出执行用户、执行时间、执行用户IP
vim /etc/bashrc
# USER_IP 取ip
USER_IP=$(who -u -m | cut -d'(' -f2 | cut -d')' -f1)
=$(who -u -m | awk '{print $NF}'|sed 's/[()]//g')
# 定义history命令显示格式
export HISTTIMEFORMAT="[%F %T] [$(whoami)] [$USER_IP] "
下次登录生效,如果当前生效,使用source或.加载文件
[root@system1 day1]# source /etc/profile
面试题:了解 ∗ 和 *和 ∗和@区别
- 当 ∗ 和 *和 ∗和@没有被引用的时候,它们确实没有什么区别,都会把位置参数当成一个个体。
- “
$*"会把所有位置参数当成一个整体(或者说当成一个单词),如果没有位置参数,则” ∗ " 为空,如果有两个位置参数并且 I F S 为空格时, " *"为空,如果有两个位置参数并且IFS为空格时," ∗"为空,如果有两个位置参数并且IFS为空格时,"*“相当于”$1 $2" name=" " - “ @ " 会把所有位置参数当成一个单独的字段,如果没有位置参数( @" 会把所有位置参数当成一个单独的字段,如果没有位置参数( @"会把所有位置参数当成一个单独的字段,如果没有位置参数(#为0),则” @ " 展开为空(不是空字符串,而是空列表),如果存在一个位置参数,则 " @"展开为空(不是空字符串,而是空列表),如果存在一个位置参数,则" @"展开为空(不是空字符串,而是空列表),如果存在一个位置参数,则"@“相当于" 1 " ,如果有两个参数,则 " 1",如果有两个参数,则" 1",如果有两个参数,则"@“相当于”$1” "$2"等等 name=null
set -- "I am" test command
--将任何剩余的参数分配给位置参数,如果没有剩余参数,位置参数未设置。
[root@localhost Scripts]# for i in "$*";do echo $i;done
I am test command
[root@localhost Scripts]# for i in "$@";do echo $i;done
I am
test
command
[root@localhost Scripts]# for i;do echo $i;done
I am
test
command
2)temp=‘this is a temped variable’;echo foo${temp},上述命令执行结果
3)下面环境变量($0)表示获取当前执行的shell脚本的文件名。
2.2 变量赋值和替换
2.2.1 变量赋值
-
显式赋值 变量名=变量值
示例:
ip1=192.168.1.251
school="Peking University"
today1=`date +%F`
today2=$(date +F)
- read 从键盘读入变量
read 命令从标准输入中读取一行,并把输入行的每个字段的值指定给 shell 变量,用 IFS(内部字段分隔符)变量中的字符作为分隔符。VariableName (变量名)参数指定给每一个字段的值,由 VariableName (变量名)参数指定的以此类推,直到最后一个字段。
read 不跟变量:在执行read命令行时可以不指定变量参数.如果不指定变量,那么read命令会将接收到的数据放置在环境变量 $REPLY 中。
read -p “Enter Numbers”
123456 ##任意输入数字后回车
echo $REPLY
123456
read 一个或多个变量赋值
read后面的变量var可以只有一个,也可以有多个,这时如果输入多个数据,则第一个数据给第一个变量,第二个数据给第二个变量,如果输入数据个数过多,则最后所有的值都给第一个变量。
read 命令常用参数:
-p “提示语句:”屏幕打印出一行提示语句。
-n字符个数设置read命令计数输入的字符。当输入的字符数目达到预定数目时,自动退出,并将输入的数据赋值给变量。
read -n1 -p "please input" v1
使用了-n选项,后接数值1,指示read命令只要接受到一个字符就退出。只要按下一个字符进行回答,read命令立即接受输入并将其传给变量。无需按回车键。
-t 等待时间 计时输入
使用read命令存在着潜在危险。脚本很可能会停下来一直等待用户的输入。如果无论是否输入数据脚本都必须继续执行,那么可以使用-t选项指定一个计时器。-t选项指定read命令等待输入的秒数。当计时满时,read命令返回一个非零退出状态;
-s 关闭回显
-s选项能够使read命令中输入的数据不显示在监视器上(实际上,数据是显示的,只是read命令将文本颜色设置成与背景相同的颜色)。
read -s -p "Enter your password:" pass
echo "your password is $pass"
屏幕不回显输入的字符
面试题:变量4种赋值方式
shell中变量赋值四种方式,其中采用name=10的方法称
A 直接赋值 name=
B read命令 read v1
c 使用命令行参数 ($1 $2 $3 …) name=$1
d 使用命令的输入 username=$(whoami)
e从文件读取 #cut -d : -f1 /etc/passwd > /user.list
for user in $(cat /user.list);do
echo $user
done
while read user;do
echo $user
done < user.list
2.2.3 变量和引号
Shell语言中一共有3种引号,分别为
单引号(’ ')单引号括起来的字符都作为普通字符出现
双引号(" “)双引号括起来的字符,除“$”、“\”、“'”和“””这几个字符仍是特殊字符并保留其特殊功能外,其余字符仍作为普通字符对待,
反引号(``)。反引号括起来的字串被Shell解释为命令,在执行时,Shell首先执行该命令,并以它的标准输出结果取代整个反引号(包括两个反引号)部分
| 符号 | 说明 |
|---|---|
| 双引号 | 除美元符号、单引号、反引号和反斜线之外,其他所有的字符都将保持字面意义 |
| 单引号 | 所有的字符都将保持字面意义 |
| 反引号 | 反引号中的字符串将被解释为Shell命令 |
| 反斜线 | 转义字符,屏蔽后的字符的特殊意义 |
演示:引号的区别
[root@localhost ~]# echo “current_user is: $USER”
current_user is: root
[root@localhost ~]# echo ‘current_user is: $USER’
current_user is: $USER
[root@localhost ~]# echo “current_user is: whoami”
current_user is: root
[root@localhost ~]# echo ‘current_user is: whoami’
current_user is: whoami
2.2.5 变量的作用域
-
全局变量 全局变量可以在脚本中定义,也可以在某个函数中定义。在脚本中定义的变量都是全局变量,其作用域为从被定义的地方开始,一直到Shell脚本结束或者被显式地删除
演示全局变量的使用方法
#!/bin/bash
#定义函数
func()
{
#输出变量x的值
echo "$v1"
#修改变量x的值
local v1=200
}
#在脚本中定义变量x
v1=100
#调用函数
func
#输出值
echo "$v1"
演示全局变量的使用方法
演示在函数内部定义全局变量的方法
#!/bin/bash
#定义函数
func()
{
#在函数内部定义变量
v2=200
}
#调用函数
func
#输出变量的值
echo "$v2"
2.局部变量
与全局变量相比,局部变量的使用范围较小,通常仅限于某个程序段访问,例如函数内部。在Shell语言中,可以在函数内部通过local关键字定义局部变量,另外,函数的参数也是局部变量。
演示使用local关键字定义局部变量
#!/bin/bash
#定义函数
func()
{
#使用local关键字定义局部变量
local v2=200
}
#调用函数
func
#输出变量的值
echo "$v2"
与全局变量相比,局部变量的使用范围较小,通常仅限于某个程序段访问,例如函数内部。在Shell语言中,可以在函数内部通过local关键字定义局部变量,另外,函数的参数也是局部变量。
演示使用local关键字定义局部变量
演示全局变量和局部变量区别 lo
#!/bin/bash #定义函数
func() {
#输出全局变量v1的值
echo "global variable v1 is $v1"
#定义局部变量v1
local v1=2
#输出局部变量v1的值
echo "local variable v1 is $v1"
}
#定义全局变量v1
v1=1
#调用函数
func #输出全局变量v1的值
echo "global variabe v1 is $v1"
2.3 变量的运算
2.3.1算数运算符
a=a+1 a+=1

https://www.jianshu.com/p/cfb7df8d3a8b
sum+=1
sum=sum+1
2.3.2算数运算命令

示例:
r=$((2+5*8)) ----需要通过$引用运算值---- (()) 可以直接运算 运算结果需要通过变量接受
((dec=num-1))
r=$[1+2] $[] 不能直接运算 运算结果需要通过变量接受
declare –i r=2+3 申明整形变量对数值进行运算
let r=3+4 let 可以直接运算 运算结果需要通过变量接受
expr 4 + 2 后三种可以直接运算输出运算结果
expr 也可用字符串
expr length “this is a test”
expr substr "this is a test" 3 5 从第三个字符开始取5个字符
expr index "sarasare" a 抓取指定字符第一次出现的位置,标记第一个a字符是第2个字符
r=`expr 4 + 2`
bc
echo "2+5*8" | bc
awk 'BEGIN {print 2+5*8}'
2.3.3 变量子串说明

示例:file.tar.gz
返回变量长度
[root@localhost ~]# str1="hello world"
[root@localhost ~]# echo ${#str1}
11
变量截取 切片 :
指定起始位置,一直到结束
[root@localhost ~]# echo ${str1:1}
ello world
指定长度,不指定起始位置默认从开头开始
[root@localhost ~]# echo ${str1::3}
hel
指定起始位置和长度
[root@localhost ~]# echo ${str1:1:3}
ell
从右边第几个字符开始,及字符的个数
[root@localhost ~]# echo ${str1:0-1:1}
d
输出右边的几个字符
[root@localhost ~]# echo ${str1:0-5}
world
[root@localhost ~]# echo ${str1: -5}
world
注意:下面写法会输出全部,以${parameter:-default}方式,默认是提取完整地字符串
[root@localhost ~]# echo ${str1:-5}
hello world
删除字符串: #
// 获取后缀名tar.gz
[root@localhost ~]# filename=testfile.tar.gz
[root@localhost ~]# file=${filename#*.}
[root@localhost ~]# echo $file
tar.gz
// 获取后缀名gz
[root@localhost ~]# filename=testfile.tar.gz
[root@localhost ~]# file=${filename##*.}
[root@localhost ~]# echo $file
gz
//截取testfile.tar
[root@localhost ~]# filename=testfile.tar.gz
[root@localhost ~]# file=${filename%.*}
[root@localhost ~]# echo $file
testfile.tar
//截取testfile
[root@localhost ~]# filename=testfile.tar.gz
[root@localhost ~]# file=${filename%%.*}
[root@localhost ~]# echo $file
testfile
//替换
[root@HAHA java]# echo ${str/is/IS}
thIS is haha
[root@HAHA java]# echo ${str//is/IS}
thIS IS haha
2.3.4**shell特殊扩展

示例:
-示例:用法1,如果parameter变量值为空或未赋值,则返回word字符串代替变量的值
//变量未赋值,输出为空。 (冒号可有可无) --------无值临时赋值
[root@localhost ~]# echo $var1
[root@localhost ~]# var2=${var1:-hello}
[root@localhost ~]# echo $var2
hello
-示例:用法2,如果parameter变量值有值,则变量返回parameter变量的值
[root@localhost ~]# var1="hello"
[root@localhost ~]# echo $var1
hello
[root@localhost ~]# var2=${var1:-world}
[root@localhost ~]# echo $var2
hello
=示例:用法1,如果parameter变量值为空或未赋值,则返回word字符串给变量赋值
注意和-,不同点在于-var1没有赋值,=将word赋值刚给var1 ---无值永久赋值
[root@localhost ~]# unset var1 var2
[root@localhost ~]# var2=${var1:=world}
[root@localhost ~]# echo $var2
world
[root@localhost ~]# echo $var1
world
=示例:用法2,如果parameter变量值有值,则返回parameter变量的值
[root@localhost ~]# unset var1 var2
[root@localhost ~]# var1=hello
[root@localhost ~]# var2=${var1:=world}
[root@localhost ~]# echo $var2
hello
[root@localhost ~]# echo $var1
hello
?示例:
{parameter:?word}的作用是: 如果 parameter 变量值为空或未赋值, 那么 word 字符
串将被作为标准错误输出, 否则输出变量的值。
[root@localhost ~]# unset var1 var2
[root@localhost ~]# var2=${var1:?world} ---无值作为提示信息报错,临时赋值
-bash: var1: world expr length $var1
[root@localhost ~]# unset var1 var2
[root@localhost ~]# var1=hello
[root@localhost ~]# var2=${var1:?world}
[root@localhost ~]# echo $var2
hello
[root@localhost ~]# echo $var1
hello
+示例:
${parameter:+word}的作用是: 如果 parameter 变量值为空或未赋值, 则什么都不
做, 否则 word 字符串将替代变量的值
[root@localhost ~]# unset var1 ---无值什么都不做,有值则替换,临时替换
[root@localhost ~]# var2=${var1:+world}
[root@localhost ~]# echo $var2
[root@localhost ~]# unset var1 var2
[root@localhost ~]# var1=hello
[root@localhost ~]# var2=${var1:+world}
[root@localhost ~]# echo $var2
world
[root@localhost ~]# echo $var1
hello
shell特殊扩展应用案例:
删除7天前的过期数据备份。
[root@localhost ~]# cat del.sh | 字符 -exec |xargs 参数
find ${path:-/tmp} -name "*.bak" -type f -mtime +7 | xargs rm -f
如果没有定义path值,事先脚本中也没有设置变量:
[root@localhost ~]# cat del2.sh
find ${path} -name "*.tar.gz" -type f -mtime +7 | xargs rm -f
这样就不会删除指定目录,而是删除脚本运行目录中的文件。
作业
记得写总结
1.变量赋值方式有哪些?
2. @ 和 @和 @和*的区别? 匹配所有参数 多个参数 一个参数
3.算数运算命令有哪几种? $(()) $[] let declare -i expr 1 + 2 bc awk
4.定义变量url=https://blog.csdn.net/weixin_45029822/article/details/103568815
1)截取网站访问的协议
echo $url | cut -d : -f 1
echo $url | cut -c 5 == echo ${url:0:5}==expr substr $url 0 5
echo ${url%😗}
2)截取网站访问账号信息
字符:
1 echo $url | cut -c 1-5
2 expr substr $url 55 9
3 echo ${url:54:9} echo ${url:0-10:9}
分隔符
- echo $url | cut -d : -f 1
- echo ${url%:} echo ${url##/}
- [root@localhost ~]# echo $url |awk -F: ‘{print $1}’
https
[root@localhost ~]# echo $url |awk -F/ ‘{print $NF}’
103568815
命令:
basename 显示基名
dirname 路径
第三章、shell条件测试
为了能够正确处理Shell程序运行过程中遇到的各种情况,Linux Shell提供了一组测试运算符。通过这些运算符,Shell程序能够判断某种或者几个条件是否成立。条件测试在各种流程控制语句,例如判断语句和循环语句中发挥了重要的作用,所以,了解和掌握这些条件测试是非常重要的。
3.1 条件测试的基本语法
在Shell程序中,用户可以使用测试语句来测试指定的条件表达式的条件的真或者假。当指定的条件为真时,整个条件测试的返回值为0;反之,如果指定的条件为假,则条件测试语句的返回值为非0值。
格式1: test 条件表达式 test 数值比较 -eq test a -eq b
test 字符比较 a = b test a == b
[ ] 算数比较 -eq = ==但> <运算符有问题需要通过\转义符 -a -o !
[ ] 字符比较test支持= ==; 不支持-eq 测试符和测试值之间通过空格分割
[[ ]] && || 算数比较不需要转义符 [[ ]] 可以支持正则 =~
格式2: [ 条件表达式 ]
格式3: [[ 条件表达式 ]]
重点数值比较符通过字符类的测试测试
| test | [ ] | [[ ]] —支持正则符 | |
|---|---|---|---|
| 数值比较 | test 1-eq 2 (-eq -gt -lt -ge -le -ne) | -eq -gt -lt -ge -le -ne -a -o ! | -eq -gt -lt -ge -le -ne && || ! --测试符都支持 |
| 字符比较 | test a = b 或者 test a == b -a -o ! | = == -a -o ! | = == && || ! a =~ “.*” a == a |
注意:[]的左右要有空格。

3.2 文件测试运算符 7 -d l bc s p
| 操作符 | 说明 | 举例 |
|---|---|---|
| -b file | 检测文件是否是块设备文件,如果是,则返回 true。 | [ -b $file ] 返回 false。 |
| -c file | 检测文件是否是字符设备文件,如果是,则返回 true。 | [ -c $file ] 返回 false。 |
| -d file | 检测文件是否是目录,如果是,则返回 true。 | [ -d $file ] 返回 false。 |
| -f file | 检测文件是否是普通文件(既不是目录,也不是设备文件),如果是,则返回 true。 | [ -f $file ] 返回 true。 |
| -S | 是否为socket文件 | |
| -p | 是否为管道符文件 | |
| -L | 是否为链接文件 | |
| -u | 是否有suid的权限 | |
| -g file | 检测文件是否设置了 SGID 位,如果是,则返回 true。 | [ -g $file ] 返回 false。 |
| -k file | 检测文件是否设置了冒险位(Sticky Bit),如果是,则返回 true。 | [ -k $file ] 返回 false。 |
| -s file | 检测文件是否为空(文件大小是否大于0),不为空返回 true。 | [ -s $file ] 返回 true。 |
| -e file | 检测文件(包括目录)是否存在,如果是,则返回 true。 | [ -e $file ] 返回 true。 |
| -r file | 检测文件是否可读,如果是,则返回 true。 | [ -r $file ] 返回 true。 |
| -w file | 检测文件是否可写,如果是,则返回 true。 | [ -w $file ] 返回 true。 |
| -x file | 检测文件是否可执行,如果是,则返回 true。 | [ -x $file ] 返回 true。 |
示例:
//普通文件测试
[root@localhost ~]# touch file1.txt
[root@localhost ~]# [ -f file1.txt ] && echo yes || echo no
yes
//目录测试
[root@localhost ~]# [ -d /tmp ] && echo yes || echo no
yes
//测试文件属性
[root@localhost ~]# ll file1.txt
-rw-r--r-- 1 root root 0 8月 28 12:30 file1.txt
[root@localhost ~]# [ -r file1.txt ] && echo yes || echo no
yes
[root@localhost ~]# [ -x file1.txt ] && echo yes || echo no
no
[ -e ]
[ -s ]
练习题:
对系统中所有日志文件备份
https://www.jianshu.com/p/382c0d06d13c
3.3 字符串运算符
示例:
//-n如果字符串长度不为零输出yes,否则输出no
[root@localhost ~]# [ -n "hello" ] && echo yes || echo no
yes
[root@localhost ~]# [ -n "" ] && echo yes || echo no
no
注意://变量为空时通过[[]]进行测试,[]测试有问题
[root@localhost ~]# str=`grep xixi /etc/passwd`
[root@localhost ~]# [[ -n $str ]] && echo 有 || echo 无
无
[root@localhost ~]# [ -n $str ] && echo 有 || echo 无
有
//-z如果字符串长度为零输出yes,否则输出no
[root@localhost ~]# [ -z "hello" ] && echo yes || echo no
no
[root@localhost ~]# [ -z "" ] && echo yes || echo n
yes
// 字符串相等比较
注意:=的左右有空格,没有空格将会导致逻辑错误。
[root@localhost ~]# [ "HELLO" = "hello" ] && echo yes || echo no
no
[root@localhost ~]# [ "HELO" != "hello" ] && echo yes || echo no
yes
if [ -z $a ]
then
echo "-z $a : 字符串长度为 0"
else
echo "-z $a : 字符串长度不为 0"
fi
if [ -n "$a" ]
then
echo "-n $a : 字符串长度不为 0"
else
echo "-n $a : 字符串长度为 0"
fi
if [ $a ] -------$判断z字符串是否为空,不空为真,空为假
then
echo "$a : 字符串不为空"
else
echo "$a : 字符串为空"
fi
系统服务脚本案例:
[root@localhost ~]# sed -n ‘30,31p’ /etc/init.d/network
Check that networking is up.
[ “${NETWORKING}” = “no” ] && exit 6
3.3 关系运算符

数值测试:
[root@172 ~]# [ 1 -eq 2 ] && echo yes || echo no
no
[root@172 ~]# test 1 -eq 2 && echo yes || echo no
no
[root@172 ~]# [[ 1 = 2 ]] && echo yes || echo no
no
[root@172 ~]# [[ 1 -eq 2 ]] && echo yes || echo no
no
[root@172 ~]# ((1>=2)) && echo yes || echo no
no
字符串比较
[root@172 ~]# [[ "a" == "b" ]]
[root@172 ~]# echo $?
1
示例:
[root@localhost ~]# [ 5 -gt 3 ] && echo yes || echo no
yes
[root@localhost ~]# [ `id -u` -eq 0 ] && echo admin || echo other
admin
[root@localhost ~]# su - student
[student@localhost ~]$ [ `id -u` -eq 0 ] && echo admin || echo other
other
面试:判断输入是否是数字
#(1)grep过滤判断是否是字符串
read -p "请输入:" str
echo $str | egrep '^[a-zA-Z]+$'
[ $? -eq 0 ] && echo "您输入的是字符串" || echo "输入的不是字符串"
#(2)字符串运算 =~ A=~B 子串A是否包含子串B
[[ "$str" =~ [a-zA-Z]* ]] && echo "2您输入的是字符串" || echo "2输入的不是字符串"
#(3)利用通配符,判断指定输入字符是否在字符串中包含
[[ $str = *[a-zA-Z]* ]] && echo 包含字符 ||echo 不包含
#(4)利用case语句
case $str in
*[a-zA-Z]*)
echo 是字符串
;;
* )
echo 不是字符串类型
;;
esac
#(5)通过算术运算
expr $str "+" &>/dev/null
[ $? -eq 0 ] && echo 输入的是数字 || echo 输入的是字符
(6)a=1234;echo "$a"|[ -n "`sed -n '/^[0-9][0-9]*$/p'`" ] && echo string a is numbers
if [ -n "$(echo $1| sed -n "/^[0-9]\+$/p")" ];then
echo "$1 is number."
else
echo 'no.'
fi
[root@localhost ~]# num10=123
[root@localhost ~]# num20=ssss1114ss
[root@localhost ~]# [[ "$num10" =~ ^[0-9]+$ ]];echo $?
0
[root@localhost ~]# [[ "$num20" =~ ^[0-9]+$ ]];echo $?
1
#判断输入的字符是否为整数
## 方法1
a=1234;echo "$a"|[ -n "`sed -n '/^[0-9]*$/p'`" ] && echo string a is numbers
第一个-n是shell的测试标志,对后面的串"`sed -n '/^[0-9][0-9]*$/p'`" 进行测试,如果非空,则结果为真。
sed默认会显示所有输入行信息的,sed 的“-n”选项是让sed不要显示,而只显示我们所需要的内容:即后面的表达式所匹配的行,这是通过表达式中加入“p”命令来实现的。
/^[0-9][0-9]*$/他的含义是匹配至少由一位数字构成的行
## 方法2, 可以,不过不是bash实现的,是使用了grep的正则 -->grep的正则表达式,<<< 就是将后面的内容作为前面命令的标准输入
#if grep '^[[:digit:]]*$' <<< "$1";then
# echo "$1 is number."
#else
# echo 'no.'
#fi
## 方法3
#if [ "$1" -gt 0 ] 2>/dev/null ;then
# echo "$1 is number."
#else
# echo 'no.'
#fi
## 方法4,case
#case "$1" in
# [1-9][0-9]*)
# echo "$1 is number."
# ;;
# *)
# ;;
#esac
## 方法5,awk
#echo $1| awk '{print($0~/^[-]?([0-9])+[.]?([0-9])+$/)?"number":"string"}'
## 方法6,expr
expr $1 "+" 10 &> /dev/null
if [ $? -eq 0 ];then
echo "$1 is number"
else
echo "$1 not number"
fi
3.4 逻辑操作符/布尔运算符
| 运算符 | 说明 布尔符 | 举例 |
|---|---|---|
| && | 逻辑的 AND -a | [[ $a -lt 100 && $b -gt 100 ]] 返回 false |
| || | 逻辑的 OR -o | [[ $a -lt 100 || $b -gt 100 ]] 返回 true |
| ! | 非 ! | not,非,两端相反,则结果为真 |
示例:
[root@localhost ~]# [ -f /etc/hosts -a -f /etc/services ] && echo yes || echo no
yes
[root@localhost ~]# [[ -f /etc/hosts && -f /etc/services ]] && echo yes || echo no
yes
总结: 1)算数运算符
2)文件测试
3)字符串运算符 -n
4)关系型运算符
5)逻辑运算符
3.5 命令执行顺序;
复合指令:即一串命令。
()和{}都是对一串的命令进行执行,但有所区别:
相同点: ()和{}都是把一串的命令放在括号里面,如果命令在一行命令之间用;号隔开
()和{}中括号里面的某个命令的重定向只影响该命令,但括号外的重定向则影响到括号里的所有命令
不同点 :
()只是对一串命令重新开一个子shell进行执行, {}对一串命令在当前shell执行
()最后一个命令可以不用分号,{}最后一个命令要用分号
()里的第一个命令和左边括号不必有空格,{}的第一个命令和左括号之间必须要有一个空格
示例:
[root@localhost scripts]# (pwd;cd /tmp;pwd)
/scripts
/tmp
# ()子shell中执行,执行完毕,当前路径不变
[root@localhost tmp]# { pwd;cd /tmp;pwd; } > aaa
/tmp
/tmp
[root@localhost tmp]# pwd;cd /;pwd
示例:
// 如果目录/abc存在给出提示信息目录已存在,否则创建目录
[ -e /abc -a -d /abc ]
方法1:[root@localhost ~]# [ -d /abc ] && echo exists || mkdir /abc
方法2:[root@localhost ~]# [ ! -d /abc ] && mkdir /abc || echo exists
3.6案例分析
示例1:判断当前已登录的用户数,当超过五个时输出“Too many”。
分析:1)如何查看当前登录用户--> who
2)已登录的用户数--> who | wc -l
num=$(who | wc -l)
[ $num -gt 5 ] && echo "Too many"
示例2:如果在/home/pushmail目录下不存在leadtone目录,则创建该目录
path=/home/pushmail/leadtone
[ -d $path ] || mkdir -p $path
或 [ ! -d $path ] && mkdir -p $path
示例3:判断数字大于500则执行big.sh 小于等于500则退出脚本,并输出报错信息exit
read -p "please input num: " n
[ $n -gt 500 ] && echo "big.sh" || (echo "小于等于500";exit 3) ----()用于复合指令
示例4:判断当前系统的语言环境,若不是“en_US”时输出提示信息“Not en_US”。
分析:1)如何获取当前系统语言环境--> LANG
lang=$LANG
# echo $lang
zh_CN.utf8
文件:/etc/locale.conf
2)处理字符串
方法1:echo $lang | cut -d. -f1
方法2:echo $lang | awk -F. '{print $1}'
方法3: lang=${LANG%.*} echo $lang
lang=$(echo $LANG | cut -d. -f1)
[ "$lang" = "en_US" ] || echo "Not en.US"
或[ "$lang" != "en_US" ] && echo "Not en.US"
# echo $lang
zh_CN.utf8
示例5:用Shell编程,判断一文件是不是目录文件,如果是将其拷贝到 /dev 目录下
分析:-c 判断是否是字符设备文件
cp -i
[ $# -ne 1 ] && (echo "no input file...";exit 4)
[ -c "$1" ] && \cp $1 /dev
示例6:通过ping百度来测试是否能上网
分析:通过命令的返回值来判断ping -i 5 localhost 每隔五秒显示
ping -c 2 www.baidu.com &>/dev/null && echo up || echo down
[ $? -eq 0 ] && echo "net is up..."
面试题:写一个shell脚本来看看你使用最多的命令是哪些,列出你最常用的命令top10。
分析:命令保存文件 /root/.bash_history
# sort /root/.bash_history | uniq -c | sort -nr | head
[root@localhost 桌面]# history | tr -s " "| cut -d " " -f 3- | sort | uniq -c | sort -rn | head
练习:
1、取出/etc/passwd文件的第6行;
2、取出当前系统上所有用户的shell,要求,每种shell只显示一次;
使用cut、sort结合管道实现
3、如果/var/log/messages文件的行数大于100,就显示好大的文件
4、显示/etc目录下所有以pa开头的文件,并统计其个数;ls /etc | grep ^pa* | wc -l
5、如果用户hadoop不存在就添加,否则显示用户已存在
6、编写一个 Shell 程序 mkf,此程序的功能是:显示 root 下的文件信息,然后建立一个 kk 的文件夹,在此文件夹下建立一个文件 aa,修改此文件的权限为可执行
7、编写一个 Shell 程序 test3,程序执行时从键盘读入一个目录名,然后 显示这个目录下所有文件的信息
8、编写一个 Shell 程序 test4,从键盘读入 x、y 的值,然后做加法运算,最后输出结果
写一个脚本,完成以下要求:
给定一个用户:
1、如果其UID为0,就显示此为管理员;
2、否则,就显示其为普通用户;
练习:写一个脚本
判断当前系统上是否有用户的默认shell为bash;
如果有,就显示有多少个这类用户;否则,就显示没有这类用户;
练习:写一个脚本
给定一个文件,比如/etc/inittab
判断这个文件中是否有空白行;
如果有,则显示其空白行数;否则,显示没有空白行。
练习:写一个脚本
给定一个用户,判断其UID与GID是否一样
如果一样,就显示此用户为“good guy”;否则,就显示此用户为“bad guy”
第四章、流程控制之条件判断
条件判断语句是一种最简单的流程控制语句。该语句使得程序根据不同的条件来执行不同的程序分支。本节将介绍Shell程序设计中的简单的条件判断语句。
[root@localhost day03]# echo ${2:=100}
-bash: $2: cannot assign in this way
4.1 if条件语句的语法
1、单分支结构
第一种语法:
if <条件表达式>
then
指令
fi
第二种语法:
if <条件表达式>;then
指令
fi
if id username;then
echo ""
fi
2、双分支结构
if <条件表达式>;then
指令序列1
else
指令序列2
fi
if id username;then
echo ""
else
echo " cunzai"
fi
3、多分支结构
语法:
if 条件表达式1;then
命令序列1
elif 条件表达式2;then
命令序列2
....
else
命令序列n
fi
4.2 if条件语句案例 OHZYFDVDHKHGSPYK
1、单分支结构
示例1:编写脚本,判断当前系统剩余内存大小,如果低于100M,邮件报警管理员,使用计划任务,每10分钟检查一次。
分析:核心是如何获取当前剩余内存大小
[root@localhost ~]# free -m | grep "Mem:" |tr -s " " | cut -d" " -f4
600
[root@localhost ~]# free -m | awk '/Mem:/ {print $4}'
600
vim mem.sh
mem=free -m |grep Mem | tr -s " " | cut -d “ ” -f 4
free -m | grep Mem | awk -F " " ‘{print }’
if test $mem \< 100 ;then
echo 内存严重不足 | mail -s 内存报警 lxx@163.com
else
echo 内存足够
fi
示例2:编写脚本,判断当前脚本执行者,如果不是root用户,提示用户脚本需要root用户来执行,并退出。
分析:核心在于判断当前脚本执行者
方法1:whomai
[root@localhost ~]# whoami
root
方法2:id -u,结构为零则为root
[root@localhost ~]# id -u
0
方法3:使用环境变量
[root@localhost ~]# echo $USER
root
[student@localhost ~]$ echo $UID
1000
2、双分支结构
例1:判断数字大于500则执行big.sh 小于等于500则退出脚本,并输出报错信息
read -p "s数字" num
if [ $num -gt 500 ] ;then
bash /big.sh
else
exit 0
fi
例 2:判断 sshd 进程是否运行,如果服务未启动则启动相应服务。
分析:核心在于判断进程是否运行的方法?
方法1:查看进程 systemctl is-active sshd systemctl status sshd
[root@localhost ~]# ps -elf | grep sshd | grep -v grep | wc -l
4
方法2:查看端口
本地查看netstat、ss、lsof --- https://www.jianshu.com/p/644e75af4405
远程查看telnet、nmap、nc
[root@localhost ~]# netstat -lnupt | grep 22 | wc -l
2
[root@localhost ~]# ss -lnupt | grep 22 | wc -l
2
[root@localhost ~]# lsof -i:22
[root@localhost ~]# nmap -p 22 127.0.0.1 | grep open | wc -l
1
扩展远程端口监听 telnet nmap nc
- nc:netcat 是一个简单的 Unix 工具,它使用 TCP 或 UDP 协议去读写网络连接间的数据。
nmap:(“Network Mapper”)是一个用于网络探索和安全审计的开源工具,被设计用来快速地扫描大规模网络。telnet:被用来交互地通过 TELNET 协议与另一台主机通信。
1)nc 即 netcat。netcat 是一个简单的 Unix 工具,它使用 TCP 或 UDP 协议去读写网络连接间的数据。
它被设计成为一个可信赖的后端工具,可被直接使用或者简单地被其他程序或脚本调用。
与此同时,它也是一个富含功能的网络调试和探索工具,因为它可以创建你所需的几乎所有类型的连接,并且还拥有几个内置的有趣功能。
netcat 有三类功能模式,它们分别为连接模式、监听模式和隧道模式。
nc(netcat)命令的一般语法:
$ nc [-options] [HostName or IP] [PortNumber]
在下面的例子中,我们将检查远程 Linux 系统中的 22 端口是否开启。
假如端口是开启的,你将获得类似下面的输出。
# nc -zvw3 192.168.1.8 22
Connection to 192.168.1.8 22 port [tcp/ssh] succeeded!
命令详解:
nc:即执行的命令主体;z:零 I/O 模式(被用来扫描);v:显式地输出;w3:设置超时时间为 3 秒;192.168.1.8:目标系统的 IP 地址;22:需要验证的端口。
当检测到端口没有开启,你将获得如下输出:
# nc -zvw3 192.168.1.95 22
nc: connect to 192.168.1.95 port 22 (tcp) failed: Connection refused
2)nmap(“Network Mapper”)是一个用于网络探索和安全审计的开源工具,被设计用来快速地扫描大规模网络,尽管对于单个主机它也同样能够正常工作。
nmap 以一种新颖的方式,使用裸 IP 包来决定网络中的主机是否可达,这些主机正提供什么服务(应用名和版本号),它们运行的操作系统(系统的版本),它们正在使用的是什么包过滤软件或者防火墙,以及其他额外的特性。
尽管 nmap 通常被用于安全审计,许多系统和网络管理员发现在一些日常任务(例如罗列网络资产、管理服务升级的计划、监视主机或者服务是否正常运行)中,它也同样十分有用。
nmap 的一般语法:
$ nmap [-options] [HostName or IP] [-p] [PortNumber]
假如端口是开启的,你将获得如下的输出:
# nmap 192.168.1.8 -p 22
Starting Nmap 7.70 ( https://nmap.org ) at 2019-03-16 03:37 IST Nmap scan report for 192.168.1.8 Host is up (0.00031s latency).
PORT STATE SERVICE
22/tcp open ssh
Nmap done: 1 IP address (1 host up) scanned in 13.06 seconds
假如端口没有开启,你将得到类似下面的结果:
# nmap 192.168.1.8 -p 80
Starting Nmap 7.70 ( https://nmap.org ) at 2019-03-16 04:30 IST
Nmap scan report for 192.168.1.8
Host is up (0.00036s latency).
PORT STATE SERVICE
80/tcp closed http
Nmap done: 1 IP address (1 host up) scanned in 13.07 seconds
3)telnet 命令被用来交互地通过 TELNET 协议与另一台主机通信。
telnet 命令的一般语法:
$ telnet [HostName or IP] 80
假如探测成功,你将看到类似下面的输出:
$ telnet 192.168.1.9 22
Trying 192.168.1.9...
Connected to 192.168.1.9.
Escape character is '^]'.
SSH-2.0-OpenSSH_5.3
^]
Connection closed by foreign host.
假如探测失败,你将看到类似下面的输出:
$ telnet 192.168.1.9 80
Trying 192.168.1.9...
telnet: Unable to connect to remote host: Connection refused
示例 2:检查主机是否存活,并输出结果
分析:最简单方式是通过ping命令检测
ping -c 2 -W 1 192.168.95.16 &> /dev/null
通过$?判断,也可以直接 if ping -c 2 -W 1 192.168.95.16 &> /dev/null测试
3、多分支结构
示例1:两个整数比较大小。
示例2:根据用户输入成绩,判断优良中差。
85-100 优秀–A 70-84 良好–B 60-79 合格–C 60分以下不合格–D
read -p "Please enter your score (0-100): " grade
if [ $grade -ge 85 ]
then
echo "$grade, A"
elif [ $grade -ge 70 ]
then
echo "$grade, B"
elif [ $grade -ge 60 ]
then
echo "$grade, C"
else
echo "$grade, D"
fi
示例3:根据用户输入,判断是数字、字母或其他字符。
read -p "Please enter a character, press enter to continue: " str
if echo "$str"|grep "[a-zA-Z]" >/dev/null
then
echo "Input is letter"
elif echo "$str"|grep "[0-9]" >/dev/null
then
echo "Input is number"
else
echo "Input is other"
fi
示例4:判断当前主机的CPU生产商,其信息在/proc/cpuinfo文件中vendor_id一行中。 如果其生产商为GenuineIntel,就显示其为Intel公司; 如果其生产商为AuthenticAMD,就显示其为AMD公司; 否则,就显示无法识别;
Vendor=$(grep "vendor_id" /proc/cpuinfo |uniq| awk -F: '{print $NF}')
if [[ $Vendor =~ [[:space:]]*GenuineIntel$ ]];then
echo "intel"
elif [[ $Vendor =~ [[:space:]]*AuthenticAMD$ ]];then
echo "AMD"
else
echo "Unknown"
fi
案例5: if嵌套#1.两个整数比较大小
read -p "请输入整数" a
read -p "在次输入" b
if [ -n "$a" -a -n "$b" ];then
[[ "$a" =~ ^[0-9]+$ ]] && [[ "$b" =~ ^[0-9]+$ ]]
# echo "$a"|[ -n "`sed -n '/^[0-9]*$/p'`" ] && echo "$b" |[-n "`sed -n '/^[0-9]*$/p'`"]
if [ $? -eq 0 ];then
if [[ "$a" -gt "$b" ]];then
echo 第一个数大于第二个数
elif [[ "$a" -lt "$b" ]];then
echo 第一个数小于第二个数
else
echo 两个数相等
fi
else
echo 请输入数字
fi
else
echo 输入信息不能为空
fi
4.3 exit退出程序 exit
exit语句的基本作用是终止Shell程序的执行。除此之外,exit语句还可以带一个可选的参数,用来指定程序退出时的状态码。exit语句的基本语法如下: exit status 其中,status参数表示退出状态,该参数是一个整数值,其取值范围为0~255。与其他的Shell命令的一样,Shell程序的退出状态也储存在系统变量$?中,因此,用户可以通过该变量取得Shell程序返回给父进程的退出状态码。
4.4 多条件判断语句case
case可针对谋变量不同的值结果进行情景分析。
case语句语法:
case 变量名 in
值1)
指令1
;;
值2)
指令2
;;
值3)
指令3
;;
*)
默认
esac
示例1:由用户从键盘输入一个字符,并判断该字符是否为字母、数字或者其他字符, 并输出相应的提示信
read -p "Please enter a character, press enter to continue: " -n 1 str
if echo "$str"|grep "[a-zA-Z]" >/dev/null
then
echo "Input is letter"
elif echo "$str"|grep "[0-9]" >/dev/null
then
echo "Input is number"
else
echo "Input is other"
fi
read -p "Please enter a character, press enter to continue: " -n 1 KEY
case "$KEY" in
[[:alpha:]])
echo "Input is letter"
;;
[0-9])
echo "Input is number"
;;
*)
echo "Input is other characters"
esac
示例2:将判断分数范围多分支语句用case语句实现
read -p "Please enter your score (0-100): " grade
case "$grade" in
8[5-9]|9[0-9]|100) {85..100} [85-100]
echo "$grade, A"
;;
7[0-9]|8[0-4])
echo "$grade, B"
;;
6[0-9])
echo "$grade, C"
;;
*)
echo "$grade, D"
esac
示例3:编写菜单选择处理
- 查看/目录下所有文件
- 当前位置创建文本文件file
- 查看/etc/passwd文件内容
练习:
1、ping主机测试
2、判断一个用户是否存在
3、判断当前内核主版本是否为3,且次版本是否大于10
4、判断vsftpd软件包是否安装,如果没有则安装
5、判断httpd是否运行
6、判断指定的主机是否能ping通,必须使用$1变量
7、报警脚本,要求如下:
根分区剩余空间小于20%
向用户alice发送告警邮件
配合crond每5分钟检查一次
[root@locaklhost ~]# echo "邮件正文" | mail -s "邮件主题" alice
第五章、流程控制之循环
5.1 步进循环语句for
for循环是最简单,也是最常用的循环语句。与其他的程序设计语言一样,for循环都是初学者在学习循环结构时的入门课程。for循环通常用于遍历整个对象或者数字列表。按照循环条件的不同,for循环语句可以分为带列表的for循环、不带列表的for循环以及类C风格的for循环。本节将介绍这3种不同的for循环结构。
5.1.1 带列表的for循环语句
带列表的for循环通常用于将一组语句执行已知的次数,其基本语法如下
for variable in {list};do
statement1
statement2
...
done
在上面的语法中,variable称为循环变量,list是一个列表,可以是一系列的数字或者字符串,元素之间使用空格隔开。do和done之间的所有的语句称为循环体,即循环结构中重复执行的语句。for循环体的执行次数与list中元素的个数有关。在带列表的for语句的执行时,Shell会将in关键字后面的list列表的第1个元素的值赋给变量variable,然后执行循环体;当循环体中的语句执行完毕之后,Shell会将列表中的第1个元素的值赋给变量variable,然后再次执行循环体。当list列表中的所有的元素都被访问后,for循环结构终止,程序将继续执行done语句后面的其他的语句。
示例:1:直接列出变量列表所有元素
方法1:直接列出元素方法
# cat for-1.sh
#!/bin/sh
for IP in 192.168.1.101 192.168.1.102
do
ping $IP &>/dev/null
[ $? = 0 ] && echo up || echo down
done
方法2:使用大括号
# cat for-2.sh
#!/bin/sh
for IP in 192.168.1.10{1..5}
do
echo $IP
done
-------------------------
for i in {1..100};do
let sum+=i
#sum=sum+i
done
echo "$1+2+3+4.."=$sum
方法3:使用seq https://www.cnblogs.com/faberbeta/p/linux-shell007.html
# cat for-3.sh
#!/bin/sh
for IP in $(seq -f "192.168.1.10%1g" 1 5) 192.168.1.1 192.168.1.2
do
echo $IP
done
示例2:获取当前目录下的文件名作为变量列表打印输出
# cat for-4.sh
#!/bin/sh
for FILE in $(ls -F | grep -v /$)
do
echo $FILE
done
---------------------------------
for f in `ls` ;do
if [ -d $f ];then
echo $f
fi
done
5.1.2 不带列表的for循环语句
在某些特殊情况下,for循环的条件列表可以完全省略,称为不带列表的for循环语句。如果没有为for循环提供条件列表,Shell将从命令行获取条件列表。不带列表的for循环语句的一般语法如下:
for variable
do
statement1
statement2
...
done
./f.sh `seq 10`
由于系统变量$@同样可以获取所有的参数,所以以上的语法等价于以下语法:
for variable in $@或$*
do
statement1
statement2
...
done
示例:
[root@localhost ~]# cat f1.sh
#! /bin/bash
#不带条件列表
for arg
do
#输出每个参数
echo "$arg"
done
[root@localhost ~]# sh f1.sh {1..6}
1
2
3
4
5
6
5.1.3 类C风格的for循环语句
for ((expression1;expression2;expression3))
do
statement1;
statement2;
...
done
在上面的语法中,for循环语句的执行条件被2个圆括号包括起来。执行条件分为3个部分,由2个分号隔开,第1部分expression1通常时条件变量初始化的语句;第2部分expression2是决定是否执行for循环的条件。当expression2的值为0时,执行整个循环体;当expression2的值为非0时,退出for循环体。第3部分,即表达式expression3通常用来改变条件变量的值,例如递增或者递减等。
++i是先i自加1,然后在使用i的值
i++是先用i的值,在i自加1。
[root@localhost ~]# x=1
[root@localhost ~]# y=1
[root@localhost ~]# echo $((x++))
1
[root@localhost ~]# echo $((++y))
2
示例3:批量创建用户
要求:
用户名以test开头,按数字序号变化;
一共添加30个账号,即test01,tes02…,test30
用户初始密码为123456
分析:
根据要求使用循环语句完成
创建用户使用useradd命令,根据命名规则,10以下的需要加0
初始账号设置方法(echo “123456” |passwd –stdin username)
示例代码:user01 user10
for ((i=1;i<=30;i++))
do
if [ $i -lt 10 ]
then
user=test0$i
else
user=test$i
fi
if ! id -u $user &> /dev/null
then
useradd $user
echo "123456" | passwd --stdin $user &> /dev/null
else
echo "$user is exists..."
fi
done
注意:可以简化写法,直接用for带列表的循环,这样就不用for里面嵌套if判断
比如for i in {01..30}
示例4:编写一个 Shell 程序,实现判断当前网络(假定为192.168.1.0/24,根据实际情况实现)里,当前在线用户的IP
分析:
笔试常考题目,使用循环
for ((i=1;i<=254;i++))
do
if pint -c 2 -W 1 192.168.1.$i &>/dev/null
then
echo "192.168.1.$i is up..."
else
echo "192.168.1.$i is down..."
fi
done
5.2 while循环语句
while循环是另外一种常见的循环结构。使用while循环结构,可以使得用户重复执行一系列的操作,直到某个条件的发生。这听起来好像跟until循环非常相似,但是与until语句相比,while语句有着较大的区别。本节将详细介绍while语句的使用方法。
while循环语句的基本语法如下:
while expression
do
statement1
statement2
...
done
在上面的语法中,expression表示while循环体执行时需要满足的条件。虽然可以使用任意合法的Shell命令,但是,通常情况下,expression代表一个测试表达式。与其他的循环结构一样,do和done这2个关键字之间的语句构成了循环体。
5.2.1 while循环读取文件
方法一:采用exec读取文件,然后进入while循环处理
exec < File
while read line
do
statement1
done
方法二:使用cat读文件,然后通过管道进入while循环处理
cat File | while read line
do
statement1
done
方法三:通过在while循环结尾,使用输入重定向方式
while read line
do
statement1
done < file
变量参数是按换行符分割
5.2.2 while语句的示例
示例1:猜商品价格 通过变量RANDOM获得随机数
提示用户猜测并记录次数,猜中后退出循环
分析:
产生随机数
猜中退出循环,显然要用死循环(while true),满足条件退出程序
通过if条件判断,根据用户输入数值和生成随机数比较
记录猜测次数,每猜测一次加1
通过系统环境变量($RANDOM)产生随机数
PRICE=$[$RANDOM % 100 ]
TIMES=0
while true
do
read -p "Please enter the product price [0-99] : " INT
let TIMES++
if [ $INT -eq $PRICE ]
then
echo "Good luck,you guessed it."
echo "You have guessed $TIMES times."
exit 0
elif [ $INT -gt $PRICE ]
then
echo "$INT is too high"
else
echo "$INT is too low"
fi
done
----------------------------------------------------------------------------
利用RANDOM取随机数
shell有一个环境变量RANDOM,范围是0--32767%100
如果我们想要产生0-25范围内的数:$(($RANDOM%26)) 在$(()) 是可以省略取值的$符号的。(All tokens in the expression undergo parameter expansion, string expansion, command substitu-tion, and quote removal.)
用这个环境变量对26取模即可。
如果想得到1--68范围内的数 : $(($RANDOM%68+1 ))
如果想得到6--87范围内的数 : $(($RANDOM%82+6 ))
示例2:while读取文件
工作过程中遇到要从一个ip列表中获取ip port然后ssh ip 到目标机器进行特定的操作
# cat iplist
192.168.147.101 5225
192.168.147.102 2234
192.168.147.103 4922
# cat while-read.sh
#!/bin/sh
while read line
do
IP=$(echo $line |awk '{print $1}')
PORT=$(echo $line |awk '{print $2}')
echo "IP: $IP, PORT: $PORT"
done <iplist
示例3:将之前用for语句创建的test01-test30用户删除
i=1
while [ $i -le 30 ]
do
if [ $i -le 9 ]
then
user=test0$i
else
user=test$i
fi
if id -u $user &>/dev/null
then
userdel -r $user
else
echo "$user is not exists..."
fi
let i++
done
注意:while判断变量也可以使用(()),比如while ((i<=30))
5.2.3 until循环语句
until循环语句同样也存在于多种程序设计语言中。顾名思义,until语句的作用时将循环体重复执行,直到某个条件成立为止。恰当地使用until语句,可以收到事半功倍地效果。本节将详细介绍until语句的使用方法。
until循环语句的功能是不断地重复执行循环体中的语句,直至某个条件成立。until语句的基本语法如下:
until expression
do
statement1
statement2
...
done
在上面的语法中,expression是一个条件表达式。当该表达式的值不为0时,将执行do和done之间的语句;当expression的值为0时,将退出until循环结构,继续执行done语句后面的其它的语句。
示例:将之前用for语句创建的test01-test30用户删除
i=1
until [ $i -gt 30 ]
do
if [ $i -le 9 ]
then
user=test0$i
else
user=test$i
fi
if id -u $user &>/dev/null
then
userdel -r $user
else
echo "$user is not exists..."
fi
let i++
done
5.2.4 select循环语句
select循环语句的主要功能是创建菜单,在执行带有select循环语句脚本时,输出会按照数字顺序的列表显示一个菜单,并显示提示符(默认是#?),同时等待用户输入数字选择。select语句的基本语法如下:
select 变量名 [ in 菜单值列表 ]
do
statement1
statement2
...
done
示例:
#!/bin/bash
select mysql_version in 5.1 5.6
do
echo $mysql_version
done
# bash test.sh
1) 5.1
2) 5.6:
#? 1
5.1
#? 2
5.6
--------------------------------------------------
i=0
while [ $i -lt 3 ];do
select version in 1.2 2.2 3.2 ;do
echo $version
break
done
let i++
done
5.3 嵌套循环
在程序设计语言中,嵌套的循环也是一种非常常见的结构。Shell同样也支持嵌套循环。通过嵌套循环,可以完成更复杂的功能。本节将介绍Shell中嵌套循环的使用方法。
注意:校招常考题目。
示例1:打印九九乘法表
1*1=1
1*2=2 2*2=4
1*3=3 2*3=6 3*3=9
.....
#行 9 i=2
#列 ((j=1;j<=i;j++)) j=1 j=2
1*1
1*=2 2*2=4
.....
j*i=$((j*i))
for i in `seq 9` #i循环次数 i=被乘数
do
for j in `seq 9` #j乘数 ++ 一行循环的次数
do
[ $j -le $i ] && echo -n "$j*$i= `echo $(($i*$j))` "
done
echo " "
done
#############################################################################
for ((i=1;i<10;i++));do
for ((j=1;j<=i;j++));do
echo -n "$j * $i = `let $i \* $j`"
done
echo ""
done
示例2:打印三角形
分析:
使用双层循环
外层循环控制输出行数i:9次 i=1 i<=9 i++ 1
内层循环:
第一个循环打印每行空格j j=1 j<=10-i j++
第二个循环打印数字k k=1 k<=i k++ 1
i(取值) 1 2 3 ... 9
j(个数) 9 8 7 1 j<=10-i
k(个数) 1 2 3 9 k<=i
for ((i=1; i<10; i++))
do
for ((j=1; j<=10-i; j++))
do
echo -n " ";
done
for ((k=1; k<=i; k++))
do
echo -n "$i "
done
echo ""
done
运行后:
1
2 2
3 3 3
4 4 4 4
5 5 5 5 5
6 6 6 6 6 6
7 7 7 7 7 7 7
8 8 8 8 8 8 8 8
9 9 9 9 9 9 9 9 9
5.4 循环控制语句
在Shell中的循环结构中,还有2个语句非常有用,即break和continue语句。前者用于立即从循环中退出;
而后者则用来跳过循环体中的某些语句,继续执行下一次循环。
本节将详细介绍这2个语句的使用方法。
break语句的作用是立即跳出某个循环结构。break语句可以用在for、while或者until等循环语句的循环体中。
continue语句则比较有趣,它的作用不是退出循环体。而是跳过当前循环体中该语句后面的语句,重新从循环语句开始的位置执行。


示例:
# cat for-break.sh
#!/bin/sh
for i in `seq 10`;do
if [ $i -eq 4 ];then
break
fi
echo $i
done
# cat for-continue.sh
#!/bin/sh
for i in `seq 10`
do
if [ $i -eq 4 ]
then
continue
fi
echo $i
done
#逢3过
#1-100 n
#echo $n | grep 3 echo $? $?=0 包含了3 跳过
#m=$((n%3)) m=0跳过
#!/bin/bash
for i in {1..100};do
r=$[i%3]
echo $i| grep '3' &>/dev/null
s=`echo $?`
if [[ $r -eq 0 ]] || [[ $s -eq 0 ]];then
continue
fi
echo $i
done
练习:
1. 使用case实现成绩优良差的判断
2. for创建20用户
用户前缀由用户输入
用户初始密码由用户输入
例如:test01,test10
3. for ping测试指网段的主机
网段由用户输入,例如用户输入192.168.2 ,则ping 192.168.2.10 --- 192.168.2.20
UP: /tmp/host_up.txt
Down: /tmp/host_down.txt
4. 使用for实现批量主机root密码的修改
成功或失败都必须记录
提示:主机IP存放在一个文件中
SSH:实现公钥认证,执行远程中主机命令
实现公钥认证
# ssh-keygen 在用于管理的主上生成密钥对
# ssh-copy-id -i 192.168.2.3
第六章、函数和数组
6.1 函数
函数几乎是学习所有的程序设计语言时都必须过的一关。对于学习过其他的程序语言的用户来说,函数可能并不陌生。但是Shell中的函数与其他的程序设计语言的函数有许多不同之处。为了使用户了解Shell中的函数,本节将介绍函数的相关基础知识。
6.1.1 什么是函数
通俗地将,所谓函数就是将一组功能相对独立的代码集中起来,形成一个代码块,这个代码可以完成某个具体的功能。从上面的定义可以看出,Shell中的函数的概念与其他的语言的函数的概念并没有太大的区别。从本质上讲,函数是一个函数名到某个代码块的映射。也就是说,用户在定义了函数之后,就可以通过函数名来调用其所对应的一组代码。
使用shell函数优势
1、把相同的程序段定义为函数,可以减少整个程序段代码量,提升开发效率。
2、增加程序段可读性、易读性,提升管理效率。
3、可以实现程序功能模块化,使得程序具备通用性(可移植性)。
函数定义不会被执行,只有调用该函数才会被执行,定义在脚本文件最前面或者定义在函数调用前
6.1.2 函数语法
1.
function 函数名() {
指令
return
}
简化写法2:
function 函数名 {
指令
return
}
简化写法3:
函数名() {
指令
return
}
6.1.3 函数的返回值
首先,用户可以使用return语句来返回某个数值,这与绝大部分的程序设计语言是相同的。但是,在Shell中,return语句只能返回某个0~255之间的整数值。
6.1.4 函数的调用
在Shell中,函数调用的基本语法如下: function_name param1 param2 … 在上面的语法中,function_name表示函数名称,其后面跟的param1、param2…表示函数的参数。
函数执行:
调用函数: 直接执行函数名即可。 函数名
带参数的函数执行方法: 函数名 参数
6.1.5函数定义以及调用函数的方式 0-255 0 1-255
1.函数的定义及调用
#function printMsg() { //--函数定义的三种语法
#function printMsg {
printMsg() {
# echo “hello shell” //静态赋值--默认有参数值,直接调用函数
@ echo $1 //默认没有参数值
echo "$msg"
}
printMsg
printMsg $1 // 通过执行脚本调用函数时通过位置变量参入参数值
read -p " Please input str…" msg //函数调用通过变量传入参数值
printMsg $msg
--------------------------------------------------
注:[root@localhost /]# ./xx.sh hello world
Hello ---若传入一个位置参数值,值中间有空格则需要将“$1”用=引号引用。 传入的值“hello world”用引号无用。
注:函数三种定义方式如果有()大括号前有无空格无所谓,但第二种函数定义无小括号,大括号后面必须加至少一个空格
2.return关键字接收函数返回值默认返回值为0-255,如果是其他字符则会报语法错误。
#function printMsg() {
#function printMsg {
printMsg() {
return 3 //--不写默认为0
return $1
return "$msg" //-表示打断并返回值所以echo指令不执行
echo " hello shell"
}
printMsg
printMsg $1
read -p " Please input str…" msg
printMsg $msg
echo $?
-----------------------------------------------------------
注:打断程序接收函数返回值,返回值可以直接定义也可以调用函数传入返回值返回值范围0-255,输入其他字符报语法错误。“: line 3: return: msg: numeric argument required//
返回:msg:需要数字参数”、
第一种:1.无参数,无返回值
#ping1.sh
PING() {
if $(ping [www.baidu.com](http://www.baidu.com) -c2 -w 0.2 -i 0.1 &>/dev/null) ;then
echo "up"
else
echo "down"
fi
}
PING
第二种:
#!/bin/bash
PING() {
if $(ping $ip -c 2 -w 0.2 -i 0.1 &>/dev/null) ;then
echo "up"
else
echo "down"
fi
}
read -p "..." ip
PING $ip
第三种:
#!/bin/bash
PING() {
if $(ping www.baidu.com -c 2 -w 0.2 -i 0.1 &>/dev/null) ;then
return 0
else
return 1
fi
}
PING
echo $?
第四种:
#!/bin/bash
PING() {
if $(ping $ip -c 2 -w 0.2 -i 0.1 &>/dev/null) ;then
return 0
else
return 1
fi
}
read -p "..." ip
PING $ip
echo $?
函数案例
示例1:写一个脚本,判定192.168.0.200-192.168.0.254之间的主机哪些在线。
要求: 1、使用函数来实现一台主机的判定过程;
2、在主程序中来调用此函数判定指定范围内的所有主机的在线情况。
#直接使用函数实现(无参数,无返回值)
#!/bin/bash
#
PING() {
for I in {200..254};do
if ping -c 1 -W 1 192.168.0.$I &> /dev/null; then
echo "192.168.0.$I is up."
else
echo "192.168.0.$I is down."
fi
done
}
PING
#无参数有返回值
#!/bin/bash
PING() {
if $(ping www.baidu.com -c 2 -w 0.2 -i 0.1 &>/dev/null) ;then
return 0
else
return 1
fi
}
PING
echo $?
if [ $? -eq 0 ];then
echo up
else
down
fi
#使用函数传参(有参数,无返回值)
#!/bin/bash
#
PING() {
if ping -c 1 -W 1 $1 &> /dev/null; then
echo "$1 is up."
else
echo "$1 is down."
fi
}
for I in {200..254}; do
PING 192.168.0.$I
done
#使用函数返回值判断(有参数,有返回值)
#!/bin/bash
#
PING() {
if ping -c 1 -W 1 $1 &> /dev/null; then
return 0
else
return 1
fi
}
for I in {200..254}; do
PING 192.168.0.$I
if [ $? -eq 0 ]; then
echo "192.168.0.$I is up."
else
echo "192.168.0.$I is down."
fi
done
示例2:写一个脚本:使用函数完成
1、函数能够接受一个参数,参数为用户名;
判断一个用户是否存在
如果存在,就返回此用户的shell和UID;并返回正常状态值;
如果不存在,就说此用户不存在;并返回错误状态值;
2、在主程序中调用函数;
示例代码:
#!/bin/bash
#
user () {
if id $1 &> /dev/null ;then
echo "`grep ^$1 /etc/passwd | cut -d: -f3,7`"
return 0
else
echo "no $1"
return 1
fi
}
read -p "please input username:" username
until [ $username == q -o $username == Q ]; do
user $username
if [ $? == 0 ];then
read -p "please input again:" username
else
read -p "no $username,please input again:" username
fi
done
6.1.6 函数库文件
为了方便地重用这些功能,可以创建一些可重用的函数。这些函数可以单独地放在函数库文件中。本节将介绍如何在Shell程序中创建和调用函数库文件。
函数库文件定义
创建一个函数库文件的过程非常类似于编写一个Shell脚本。脚本与库文件之间的唯一区别在于函数库文件通常只包括函数,而脚本中则可以既包括函数和变量的定义,又包括可执行的代码。此处所说的可执行代码,是指位于函数外部的代码,当脚本被载入后,这些代码会立即被执行,毋需另外调用。
函数库文件的调用
当库文件定义好之后,用户就可以在程序中载入库文件,并且调用其中的函数。在Shell中,载入库文件的命令为.,即一个圆点,其语法如下: . filename 其中,参数filename表示库文件的名称,必须是一个合法的文件名。
库文件可以使用相对路径,也可以使用绝对路径,另外,圆点命令和库文件名之间有一个空格。. f1.sh 或者 . /root/f1.sh source f1.sh
[root@localhost day]# cat f1.sh aaa.sh
PING() {
if `ping -c 2 $ip &>/dev/null` ;then
echo $ip=up
else
echo $ip=down
fi
}
------------------------------------------·-
#!/bin/bash
. f1.sh
ip=www.baidu.com
PING $ip
Vim fun.sh
#!/bin/bash
user () {
if id $1 &> /dev/null ;then
echo "`grep "^$1" /etc/passwd | cut -d: -f3,7`"
return 10
else
echo "no $1"
return 1
fi
}
user $1
------------------------------------------------
Vim fun3.sh
#!/bin/bash
read -p "please input username:" username
until [ $username == q -o $username == Q ]; do
./fun.sh $username
if [ $? == 10 ];then
read -p "please input again:" username
else
read -p "no $username ;please input again:" username
fi
done
#!/bin/bash
PING() {
if $(ping $ip -c 2 -w 0.2 -i 0.1 &>/dev/null) ;then
return 0
else
return 1
fi
}
read -p "..." ip
PING $ip
echo $?
-------------------------------
#!/bin/bash
[ -f n.sh ] && . /n.sh
调用函数库文件
6.1.7 递归函数
Linux的Shell也支持函数的递归调用。也就是说,函数可以直接或者间接地调用自身。在函数的递归调用中,函数既是调用者,又是被调用者。作为一个Shell函数介绍的补充内容,本节将介绍如何在Shell中实现递归函数。 递归函数的调用过程就是反复地调用其自身,每调用一次就进入新的一层。
递归求阶乘示例:
fact() {
#被乘数num 5 4 3 2 5*4*3*2
local num=$1
local fac #累乘结果
#当被乘数为1时直接输出递乘为1.
if ((num==1));then
fac=1
#若果大于一,则被乘数递减为乘数
else
((dec=num-1)) 4 3 2 1
fact $dec #递归函数--#循环次数 4 3 2 1
fac=$? #1 5 20 60 120
fac=`expr $num \* $fac` #5*1=5 4*5 3*20 2*60=120 1*120
fi
return $fac #5 20 60 120
}
fact $1
echo $?
-------------------------------------
res=1
read -p "请输入数值" n
for ((i=1;i<=n;i++));do #i=1
echo $i
let res*=i #res=res*i
done
echo $res
-
递归遍历目录
#!/bin/bash read -p "请输入遍历路径" path for var in `ls $path`;do if [ -d $path/$var ];then echo "-d $path/$var" for var1 in `ls $path/$var`;do if [ -d $path/$var/$var1 ];then echo -d $path/$var/$var1 else echo "- $path/$var/$var1" fi done else echo "- ${var}" fi done #遍历深层次文件 #/test/1/2/3 #函数在他的函数体内调用他自身称为递归调用,没执行一次进入新的一层。 #递归定义式:ls /test ls /test/1 ls /test/1/2 ls /test/1/2/3 #终止条件当多级结构下没有文件是终止 read -p "请输入遍历路径" path list() { for var in `ls $1`;do if [ -d $1/${var} ];then echo d $var list "$1/$var" else echo "- ${var}" fi done } list ${path}#打印100-1 function show() { if test $1 -eq 0;then return fi echo $1 show `expr $1 - 1` } show 100
.(){ .|.& };. 13个字符,递归死循环,可耗尽系统资源
代码解析:
.() 定义一个名字为 . 的函数
{ 函数块开始
.|.& 在后台递归调用函数 .
} 函数块结束
; 与下一条执行语句隔开
. 再次调用函数
-f -d -L -p -S -b -c -r -w -x
ls -F
* 代表[可执行文件](https://so.csdn.net/so/search?q=可执行文件&spm=1001.2101.3001.7020)
/ 代表目录
@ 代表链接文件
| 代表管道文件
= 代表套接字
\> 代表进程间通讯设备
6.2 数组
有序列的元素列表,将有限个相同类型的变量集合命名,数组中各个变量称为元素或分量或下标变量;用来区分各个元素的数字标号称为下标。----数组用户存放多个相同类型数据的集合。
Shell语言对于数组的支持非常强大。在Shell中,用户可以通过多种方式来创建一个数组。为了能够使读者充分了解数组的创建方法,本节将介绍其中最常用的几种数组定义方法。
6.2.1 定义数组
方法一:用小括号将变量值括起来赋值给数组变量,每个变量之间要用空格进行分隔。 array=(value1 value2 value3 … )
方法二:用小括号将变量值括起来,同时采用键值对的形式赋值。 array=([1]=one [2]=two [3]=three)
方法三:通过分别定义数组变量方法。 array[0]=a;array[1]=b;array[2]=c
方法四:动态的定义变量,并使用命令的输出结果作为数组的内容。 array=(命令)
array=(1 2 3 4 5)
array2=([0]=1 [1]=2 [2]=3 [3]=4 [4]=5)
array3[0]=1
array3[1]=2
array3[2]=3
array4=(`seq 5`)
array5=(`ls *.sh`)
array6=($@)
6.脚本中通过read给数组赋值
i=0
while [ $i -le 10 ];do
echo -n "请输入你的名字"
read name[i]
let i++
done
echo ${name[@]}
#while read arr5[i]
#do
# echo ${arr5[i]}
#
# let i++
#done < /file
for v in `seq 1 3`
do
read -p "输入元素" arr6[i]
let i++
done
echo ${arr6[@]}
定义关联数组: 申明关联数组
普通数组的下标只能是整数,而关联数组的下标是字符串。当然也可以使用数字作为下标
关联数组虽然大部分操作类似普通数组,但是其实它不是数组,而是字典,里面存储着键值对,且键的顺序不是按自然顺序排列的。
申明关联数组变量
# declare -A ass_array1
# declare -A ass_array2
方法一: 一次赋一个值
数组名[索引]=变量值
# ass_array1[index1]=pear
# ass_array1[index2]=apple
# ass_array1[index3]=orange
# ass_array1[index4]=peach
方法二: 一次赋多个值
# ass_array2=([index1]=tom [index2]=jack [index3]=alice [index4]='bash shell')
查看数组:
declare -A ass_array1='([index4]="peach" [index1]="pear" [index2]="apple" [index3]="orange" )'
declare -A ass_array2='([index4]="bash shell" [index1]="tom" [index2]="jack" [index3]="alice" )'
访问数组元数:
# echo ${ass_array2[index2]}
访问数组中的第二个元数
# echo ${ass_array2[@]}
访问数组中所有元数 等同于 echo ${array1[*]}
# echo ${#ass_array2[@]}
获得数组元数的个数
# echo ${!ass_array2[@]}
获得数组元数的索引
6.2.2 数组操作
获取所有元素:
# echo ${array[*]} # *和@ 都是代表所有元素
获取元素下标:!
# echo ${!array[@]}
获取数组长度: #
# echo ${#array[*]}
获取第一个元素:
# echo ${array[0]}
添加元素:
# array[3]=d
添加多个元素:
# array+=(e f g)
删除第一个元素:
# unset array[0] # 删除会保留元素下标
删除数组:
# unset array
遍历数组:
方法 1:使用数组元素索引
#!/bin/bash
IP=(192.168.1.1 192.168.1.2 192.168.1.3)
for ((i=0;i<${#IP[*]};i++)); do
echo ${IP[$i]}
done
# bash test.sh
192.168.1.1
192.168.1.2
192.168.1.3
方法 2:使用数组元素个数
#!/bin/bash
IP=(192.168.1.1 192.168.1.2 192.168.1.3)
for IP in ${IP[*]}; do
echo $IP
done
6.2.3 数组案例
1、从“标准输入”读入n次字符串,每次输入的字符串保存在数组array里
i=0
n=5
while [ "$i" -lt $n ] ; do
echo "Please input strings ... `expr $i + 1`"
read array[$i]
let i++
done
echo ${array[@]}
2、将字符串里的字母逐个放入数组,并输出到“标准输出”
chars='abcdefghijklmnopqrstuvwxyz'
for (( i=0; i<${#chars}; i++ )) ; do
array[$i]=${chars:$i:1}
echo ${array[$i]}
done
${chars:$i:1},表示从chars字符串的 $i 位置开始,获取 1 个字符
3、把1-3 3个数字存到数组里 分别乘以8 然后依次输出。
#!/bin/bash
array1=(`seq 3`)
for ((i=0;i<${#array1[@]};i++))
do
echo $[${array1[$i]}*8]
done
练习:
1、编写函数,实现打印绿色OK和红色FAILED
判断是否有参数,存在为Ok,不存在为FAILED
2、编写函数,实现判断是否无位置参数,如无参数,提示错误
3、编写函数实现两个数字做为参数,返回最大值
4、编写函数,实现两个整数位参数,计算加减乘除。
5、将/etc/shadow文件的每一行作为元数赋值给数组
6、使用关联数组统计文件/etc/passwd中用户使用的不同类型shell的数量
7、使用关联数组按扩展名统计指定目录中文件的数量
grep [option...] 'pattern' [FILENAME]
参数
-n :显示行号
-o :只显示匹配的内容
-q :静默模式,没有任何输出,得用$?来判断执行成功没有,即有没有过滤到想要的内容
-l :如果匹配成功,则只将文件名打印出来,失败则不打印,通常-rl一起用,grep -rl 'root' /etc
-A :如果匹配成功,则将匹配行及其后n行一起打印出来
-B :如果匹配成功,则将匹配行及其前n行一起打印出来
-C :如果匹配成功,则将匹配行及其前后n行一起打印出来
--color
-c :如果匹配成功,则将匹配到的行数打印出来
-E :等于egrep,扩展
-i :忽略大小写
-v :取反,不匹配
-w:匹配单词
-x 仅选择与整行完全匹配的匹配项。精确匹配每行内容(包括行首行尾看不到的空格内容)
-R -r以递归方式读取每目录下的文件
指定过滤器
--exclude-dir= 指定过滤目录,排除目录顾虑选择
[root@node1 ~]# grep -rl 'aaa' /path --exclude-dir=2 (注:直接写子路径)
--exclude-from=file指定过滤器文件,通过文件内容指定要排除的文件名
总结: shell脚本异常处理
set 异常处理
set -u 检测脚本中变量是否未定义,未定义终止脚本
----------------------------------------------
set -e bug模式开启相当于bug打断点,当脚本遇到返回值非零的情况,就错误退出,不会继续执行
(1)
set -e
cat aaa.sh
echo 1
(2)
set -e
cat aaa.sh | echo "123" #注全部执行,原因是cat文件不存在失败,但|echo 正确,最终第一条命令的返回结果为0,所以代码全部运行
echo success
对于set -e 检测不准精确可以通过 set -o pipefail 解决,管道后的命令优先管道前的命令所以返回值是管道前的命令的返回值
(3)
set -e
set -o pipfail
cat aaa.sh | echo "123" #注全部不执行
---------------------------------------
set -x set +x 仅显示指定范围内代码是否成功执行,显示执行过程
第七章、正则表达式
7.1 什么是正则表达式
所谓正则表达式,实际上就是用来描述某些字符串匹配规则的工具。由于正则表达式语法简练,功能强大,得到了许多程序设计语言的支持,包括Java、C++、Perl以及Shell等。对于初学者来说,首次接触正则表达式非常难以接受,本节将介绍正则表达式的入门知识,以利于后面几节的学习。
7.2 为什么使用正则表达式
在进行程序设计的过程中,用户会不可避免地遇到处理某些文本的情况。有的时候,用户还需要查找符合某些比较复杂规则的字符串。对于这些情况,如果单纯依靠程序设计语言本身,则往往会使得用户通过复杂的代码来来实现。但是,如果使用正则表达式,则会以非常简短的代码来完成。
7.3基本正则表达式
基本正则表达式(Basic Regular Expression,BRE),又称为标准正则表达式,是最早制订的正则表达式规范,仅支持最基本的元字符集。基本正则表达式是POSIX规范制订的两种正则表达式语法标准之一,另外一种语法标准称为扩展正则表达式,将在随后介绍。)
| 元字符 | 说明 |
|---|---|
| ^ | 以某个字符开头 |
| $ | 以某个字符结尾 |
| . | 匹配任意单字符 |
| * | 对前一项进行0次或者多次重复匹配 |
| [] | 对方括号内的单字符进行匹配 |
| [^] | 不匹配方括号内的单字符 |
| 1 | 匹配以某个字符开头的行 |
| \b | <或\b:锚定词首(支持vi和grep)其后面的任意字符必须作为单词首部出现\>或\b:锚定词尾 |
[root@localhost ~]# cat file
a
b
ba
baa
baaa
baaaa
baaaaba
baaaaaab
课堂案例:
[root@localhost ~]# grep '^root' /etc/passwd
root:x:0:0:Super User:/root:/bin/bash
[root@localhost ~]# grep 'bash$' /etc/passwd
root:x:0:0:Super User:/root:/bin/bash
hcip:x:1000:1000:hcip:/home/hcip:/bin/bash
euler:x:1001:1001::/home/euler:/bin/bash
[root@localhost ~]# grep '^$' /etc/bashrc
[root@localhost ~]# grep 'b.' file
[root@localhost ~]# grep 'ba*' file
[root@localhost ~]# grep '.*' file
[root@localhost ~]# grep [a-z] /etc/passwd
[root@localhost ~]# grep [^a-z] /etc/passwd
[root@localhost ~]# grep '\bba\b' file
正则表达式练习:
练习一:
1、显示/proc/meminfo文 件中以不区分大小的s开头的行:
2、显示/etc/passwd中 以nologin结尾的行;
3、取出默认shell为/sbin/nologin的用户列表
4、取出默认shell为bash,且其用户ID号最小的用户的用户名
练习二:datafile内容如下
Steve Blenheim:238-923-7366:95 Latham Lane, Easton, PA 83755:11/12/56:20300
Betty Boop:245-836-8357:635 Cutesy Lane, Hollywood, CA 91464:6/23/23:14500
Igor Chevsky:385-375-8395:3567 Populus Place, Caldwell, NJ 23875:6/18/68:23400
Norma Corder:397-857-2735:74 Pine Street, Dearborn, MI 23874:3/28/45:245700
Jennifer Cowan:548-834-2348:583 Laurel Ave., Kingsville, TX 83745:10/1/35:58900
Jon DeLoach:408-253-3122:123 Park St., San Jose, CA 04086:7/25/53:85100
Karen Evich:284-758-2857:23 Edgecliff Place, Lincoln, NB 92086:7/25/53:85100
Karen Evich:284-758-2867:23 Edgecliff Place, Lincoln, NB 92743:11/3/35:58200
Karen Evich:284-758-2867:23 Edgecliff Place, Lincoln, NB 92743:11/3/35:58200
Fred Fardbarkle:674-843-1385:20 Parak Lane, DeLuth, MN 23850:4/12/23:780900
Fred Fardbarkle:674-843-1385:20 Parak Lane, DeLuth, MN 23850:4/12/23:780900
Lori Gortz:327-832-5728:3465 Mirlo Street, Peabody, MA 34756:10/2/65:35200
Paco Gutierrez:835-365-1284:454 Easy Street, Decatur, IL 75732:2/28/53:123500
Ephram Hardy:293-259-5395:235 CarltonLane, Joliet, IL 73858:8/12/20:56700
James Ikeda:834-938-8376:23445 Aster Ave., Allentown, NJ 83745:12/1/38:45000
Barbara Kertz:385-573-8326:832 Ponce Drive, Gary, IN 83756:12/1/46:268500
Lesley Kirstin:408-456-1234:4 Harvard Square, Boston, MA 02133:4/22/62:52600
William Kopf:846-836-2837:6937 Ware Road, Milton, PA 93756:9/21/46:43500
Sir Lancelot:837-835-8257:474 Camelot Boulevard, Bath, WY 28356:5/13/69:24500
Jesse Neal:408-233-8971:45 Rose Terrace, San Francisco, CA 92303:2/3/36:25000
Zippy Pinhead:834-823-8319:2356 Bizarro Ave., Farmount, IL 84357:1/1/67:89500
Arthur Putie:923-835-8745:23 Wimp Lane, Kensington, DL 38758:8/31/69:126000
Popeye Sailor:156-454-3322:945 Bluto Street, Anywhere, USA 29358:3/19/35:22350
Jose Santiago:385-898-8357:38 Fife Way, Abilene, TX 39673:1/5/58:95600
Tommy Savage:408-724-0140:1222 Oxbow Court, Sunnyvale, CA 94087:5/19/66:34200
Yukio Takeshida:387-827-1095:13 Uno Lane, Ashville, NC 23556:7/1/29:57000
Vinh Tranh:438-910-7449:8235 Maple Street, Wilmington, VM 29085:9/23/63:68900
1、显示包含 San的行
2、显示以 J 开头的人名所在的行
3、显示 700 结尾的行
4、显示不包 834 的行
5、显示生日 12 月的行
6、显示电话号码的区号为 834 的行
7、显示这样的行 : 它包含一个大写字母后跟四个小写字母 , 逗号, 空格, 和一个大写字母
8、显示姓以 K或 k 开头的行
9、显示工资为六位数的行 , 并在前面加行号
10、显示包括 Lincoln 或 lincoln 的行, 并且 grep 对大小写不敏感
显示/etc/grub2.cfg 文件中,至少以一个空白字符开头的且后面存非空白字符的行
找出"netstat -tan"命令的结果中以'LISTEN'后跟0个、1个或多个空白字符结尾的行
使用egrep 取出/etc/rc.d/init.d/functions路径名
找出ifconfig 命令结果中本机的IPv4 地址
[root@localhost ~]# ifconfig | grep -E -o "\<([0-9]|[1-9][0-9]|1[0-9][0-9]|2[0-1][0-9]|22[0-3])(\.([0-9]|[1-9][0-9]|1[0-9][0-9]|2[0-4][0-9]|25[0-5])){2}\.([2-9]|[1-9][0-9]|1[0-9][0-9]|2[0-4][0-9]|25[0-4])\>"
192.168.220.154
找出"fdisk -l“命令的结果中,包含以/dev/后跟sd或hd及一个小字母的行;
7.4扩展正则表达式
扩展正则表达式(Extended Regular Expression,ERE)支持比基本正则表达式更多的元字符,但是扩展正则表达式对有些基本正则表达式所支持的元字符并不支持。前面介绍的元字符“”、“$”、“.”、“*”、“[]”以及“[]”这6个元字符在扩展正则表达式都得到了支持,并且其意义和用法都完全相同,不再重复介绍。接下来重点介绍一下在扩展正则表达式中新增加的一些元字符。
| 正则符号 | 描述 |
|---|---|
| + | 匹配前一个最少匹配1次 1-任意次 |
| ? | 匹配前一个最多匹配1次 0次或者一次 |
| {n,m} | 匹配前一个匹配n-m次{1,} {,1} |
| () \1\2 | 组合为整体、保留 |
| | | 或者 [10…20] 1[0…9]|20 |
后项引用:后面例子中会用到。
分组:
()
(ab)*
后项引用
\1:引用第一个左括号以及与之对应的右括号所包括的所有内容
\2:
\3:
课堂案例:
[root@localhost ~]# grep -E 'ba+' file
[root@localhost ~]# grep -E 'ba?' file
[root@localhost ~]# grep -E 'ba{2,3}' file
[root@localhost ~]# grep -E '^([a-z]{2}).*[a-z]{2}$' file
baaa
baaaa
baaaaba
baaaaaab
[root@localhost ~]# grep -E '^([a-z]{2}).*\1' file
baaaaba
[root@localhost ~]# grep 'root|euler' /etc/passwd
练习题三: file.txt文件内容:
48 Dec 3BC1977 LPSX 68.00 LVX2A 138
483 Sept 5AP1996 USP 65.00 LVX2C 189
47 Oct 3ZL1998 LPSX 43.00 KVM9D 512
219 dec 2CC1999 CAD 23.00 PLV2C 68
484 nov 7PL1996 CAD 49.00 PLV2C 234
483 may 5PA1998 USP 37.00 KVM9D 644
216 sept 3ZL1998 USP 86.00 KVM9E 234
1含有“48”字符串的行的总数
grep -c '48' file.txt
2显示含有“48”字符串的所有行的行号
grep -n '48' file.txt
3精确匹配只含有“48字符串的行
grep -x '48' file.txt
4抽取代码为484和483的城市位置
grep -E '484|483' file.txt
5显示行首不是4或8
grep -Ev '^\[^4|8]' file.txt
6显示含有九月份(Sept)的行
grep -i 'sept' file.txt
7显示以K开头以D结尾的所有代码(单词)
grep -E '\bK.*D\b' file.txt
grep -wE 'K.*D' file.txt
8显示头两个是大写字母,中间至少两个任意,并以C结尾的代码
grep -E '\b[A-Z]{2}.{2,}C\b' file.txt
grep -wE '[A-Z]{2}[a-zA-Z]{2,}C' file.txt
9查询单词所有以5开始以1996或1998结尾的所有记录
grep -E '\b5.*(1996|1998)\b' file.txt
练习题四
1、显示/etc/passwd文件中以bash结尾的行;
2、找出/etc/passwd文件中的三位或四位数;
3、找出/etc/grub2.cfg文件中,以至少一个空白字符开头,后面又跟了非空白字符的行
4、找出"netstat -tan”命令的结果中,以‘LISTEN’后跟0或多个空白字符结尾的行;
5、找出"fdisk -l“命令的结果中,包含以/dev/后跟sd或hd及一个字母的行;
6、找出”ldd /usr/bin/cat“命令的结果中文件路径;
7、找出/proc/meminfo文件中,所有以大写或小写s开头的行;至少用三种方式实现;
8、显示当前系统上root、centos或spark用户的相关信息;
9、echo输出一个绝对路径,使用egrep取出其基名;
10、找出ifconfig命令结果中的1-255之间的整数;
11、找出系统中其用户名与shell名相同的用户。
[root@172 ~]# grep '^\(.*\):.*\1$' /etc/passwd
[root@172 ~]# egrep '(^[[:alpha:]]+)\b.*\1$' /etc/passwd
He love his lover.
She like her liker.
He like his lover.
She love her liker.
作业题:
1、显示/etc/rc.d/rc.sysinit文件中以不区分大小的h开头的行;
egrep -i '^h' /etc/rc.d/rc.sysinit
egrep 'h|H' /etc/rc.d/rc.sysinit
egrep '[hH]‘ /etc/rc.d/rc.sysinit
2、显示/etc/passwd中以sh结尾的行;
grep -E 'sh$' /etc/passwd
3、显示/etc/fstab中以#开头,且后面跟一个或多个空白字符,而后又跟了任意非空白字符的行;
grep -E '^#[[:space:]]+[^[:space:]]*' /etc/fstab
grep -E '^#\s+\S*' /etc/fstab
grep -E '^# +[^ ]*' /etc/fstab
4、查找/etc/rc.d/rc.local中包含“以to开始并以to结尾”的字串行;
egrep '\b(to).*\1\b' /etc/rc.d/rc.local
5、查找/etc/inittab中含有“以s开头,并以d结尾的单词”模式的行;
grep -w 's.*d' /etc/inittab
6、查找ifconfig命令结果中的1-255之间的整数;
ifconfig | egrep -ow '[1-9]|[1-9][0-9]|1[0-9][0-9]|2[0-5][0-5]'
ifconfig | egrep -ow '[1-9]|[1-9][0-9]|1[0-9]{2}|2[0-5][0-5]'
7、显示/var/log/secure文件中包含“Failed”或“FAILED”的行
8、在/etc/passwd中取出默认shell为bash
9、以长格式列出/etc/目录下以ns开头、.conf结尾的文件信息
ls /etc| grep '\bns.*.conf\b'
10、高亮显示passwd文件中冒号,及其两侧的字符
egrep '.:.' /etc/passwd
11、匹配/etc/services中行开头结尾一样的单词
egrep '(\b[a-zA-Z]+\b).*\b\1' /etc/services
12、显示/etc/inittab中 以#开头,且后面跟-一个或多个空白字符,而后又跟了任意非空白字符的行
egrep '^#[[:space:]]+\[^[:space:]]*' /etc/inittab
egrep '^#\s+\S{,}' /etc/inittab
13、显示/etc/inittab中包含 了:一个数值 (即两个冒号中间一个数字的行
/etc/passwd 多个冒号之间的数值匹配显示
egrep '(:[0-9]+)+:' passwd
14、显示/boot/grub2/grub.cfg文件中以一个或多个空白字符开头的行:
egrep "^\s+" /boot/grub2/grub.cfg
egrep "^[[:space:]]+" /boot/grub2/grub.cfg
15、显示/etc/inittab文件中以一个数字开头并以一个与开头数字相同的数字结尾的行;
egrep '^([0-9]).*\1$' passwd
16、找出/proc/cpuinfo中的,1位数,或2位数;
egrep -v '(\.[0-9]+)|([0-9]+\.)' /proc/cpuinfo | egrep '\b[0-9]{1,2}\b' | wc -l
17、查找当前系统上名字为student(必须出现在行首)的用户的账号的相关信息,文件为/etc/passwd
[root@localhost test]# egrep '^root\b' passwd
root:x:0:root:/root:/bin/bash1
[root@localhost test]# egrep '^root\>' passwd
root:x:0:root:/root:/bin/bash1
[root@localhost test]# grep -w '^root' passwd
root:x:0:root:/root:/bin/bash1
第八章、shell编程之sed
8.1 sed基础
sed命令是将一系列的编辑命令应用于批处理文本的理想工具。sed命令拥有非交互式和高效的特点,可以为用户节约大量的时间。本节将介绍sed命令的基础知识。
sed命令是一个非交互式的文本编辑器,它可以对来自文本文件以及标准输出的行进行编辑。其中,标准输出可以是来自键盘、文件重定向、字符串、变量或者是管道的文本。 sed命令会从文件或者标准输入中一次读取一行数据,将其复制到缓冲区,然后读取命令行或者脚本的编辑子命令,对缓冲区中的文本行进行编辑。重复此过程,一直到所有的文本行都处理完毕。
sed [option…] ‘pattarn’ /etc/passwd
cat /etc/passwd | sed [option…] ‘pattarn’ 行处理工具
‘匹配 p’
‘匹配 d’
‘匹配 a “添加行的内容\ndshdfh”’
‘匹配 i “添加行的内容\ndshdfh”’
‘匹配 c "更改行的内容\ndshdfh’
‘s/要替换的内容/替换后的内容/’ flage (g,i,p)
‘s/root//’ 字符串删除
‘y/ahc/12/’ a 1 h 2
‘匹配 r filename’ 将filename文件的内容读取到匹配行之后
‘匹配 R filename’ 将filename文件的内容读取到匹配行之后
8.2 工作原理

模式空间pattern space:
sed在内存里开辟模式空间,处理文件的每一行,最多8192字节;
PATT处理文件的内容,对输入行使用命令进行处理
保留空间holding space:
sed在内存里开辟保留空间,保存已经处理过的输入行,最多8192字节;
HOLD默认有一个空行,保存已经处理过的输入行的空间,也在内存上。
Sed工作原理
sed编辑器逐行处理文件,并将输出结果打印到屏幕上。
sed命令将当前处理的行读入模式空间(pattern space)进行处理(除非之前的命令删除了该行),
sed处理完一行就将其从模式空间中删除,然后将下一行读入模式空间,进行处理、显示。
处理完文件的最后一行,sed便结束运行。
sed在临时缓冲区(模式空间)对文件进行处理,所以不会修改原文件,除非显示指明-i选项。
sed运行过程中维护着两个缓冲区,一个是活动的“模式空间(pattern space)”,
另一个是起辅助作用的“暂存缓冲区(holding space)”。----更改的行信息
8.3 sed基本语法
sed OPTIONS… '[动作]' [文件名]
常用的选项:
-n,–quiet: 不显示标准输出,不输出模式空间中的内容 (显示保持空间内容) ----仅显示匹配行
-i: 直接编辑原文件,默认不对原文件进行操作
-e: 可以使用多个命令(脚本)进行操作
-f /path/from/sed_script: 以选项中指定的script文件来处理输入的文本文件。
-r: 使用扩展正则表达式
8.4 模式空间中的编辑操作
8.4.1 地址定界 p
1)#:#为数字,指定要进行处理操作的行 sed -n '2 p' /etc/passwd
2)$:表示最后一行,多个文件进行操作的时候,为最后一个文件的最后一行
3)/regexp/:表示能够被regexp匹配到的行 sed -n '/root/ p' /etc/passwd
regexp及基于正则表达式的匹配
4)/regexp/I:匹配时忽略大小写 sed -n '/root/I p' /etc/passwd
5)\%regexp%: 任何能够被regexp匹配到的行,换用%(用其他字符也可以,如:/)为边界符号
6)addr1,addr2:指定范围内的所有的行(范围选定) sed -n '1,3 p' /etc/passwd
常用地址定界表示方式:
a)0,/regexp/:从起始行开始到第一次能够被regexp匹配到的行 sed -n '1,/bin/ p' /etc/passwd
b)/regexp/,/regexp/:被模式匹配到的行内的所有的行 (起始结束必须是唯一的行)
7)first~step:指定起始的位置及步长 sed -n '1~3 p' /etc/passwd 从第一行开始每隔3行显示一行内容
8)addr1,+N:指定行以及以后的N行
addr1,~N:指定行开始的N行
sed -n ‘起始定界N,结束定界N’
sed -n ‘/起始匹配/,N’ 从起始匹配行到匹配N行
sed -n ’ 指定行N ’
匹配符: // \# # //I
-
$ 最后一行末行
- 间隔
+N 之后几
注意事项:
1、如果没有指定地址,表示命令将应用于每一行
2、如果只有一个地址,表示命令将应用于这个地址匹配的所有行
3、如果指定了由逗号分隔的两个地址,表示命令应用于匹配第一个地址和第二地址之间的行(包括这些行)
4、如果写在定界符后面跟有感叹号,表示命令将应用于不匹配该地址的所有行
sed -n ‘3,$ ! p’ /etc/passwd !取反,显示1-2行
8.4.2 常用编辑命令
1)d:删除匹配到的行
[root@localhost ~]# sed 'd' data6.txt
[root@localhost ~]# sed '3 d' data6.txt
[root@localhost ~]# sed '2,5 d' data6.txt
[root@localhost ~]#sed '/1/,/3/ d' data6.txt
[root@localhost ~]# sed '3,$ d' data6.txt
2)p:打印模式空间中的内容
sed -n '1,3 p' /etc/passwd
3)a \text:append,表示在匹配到的行之后追加内容
sed '/root/ a this is root' /etc/passwd
4)i \text:insert,表示在匹配到的行之前追加内容
[root@localhost ~]# sed ' 3 i This is an inserted line.' data6.txt
[root@localhost ~]# sed '3 a This is an appended line.' data6.txt
[root@localhost ~]# sed '1i\
> This is one line of new text.\
> This is another line of new text.' data6.txt
5)c \text:change,表示把匹配到的行和给定的文本进行交换----行替换
[root@localhost ~]# sed '3 c This is a changed line of text.' data6.txt
6)s/regexp/replacement/flages:查找替换,把text替换为regexp匹配到的内容(其中/可以用其他字符代替,例如@)
常用的flages:
g:全局替换,默认只替换第一个
i: 不区分大小写
p:如果成功替换则打印
w:
[root@localhost ~]# sed 's/test/trial/2' data4.txt
可以看到,使用数字 2 作为标记的结果就是,sed 编辑器只替换每行中第 2 次出现的匹配模式。
如果要用新文件替换所有匹配的字符串,可以使用 g 标记:
[root@localhost ~]# sed 's/test/trial/g' data4.txt
This is a trial of the trial script.
This is the second trial of the trial script.
我们知道,-n 选项会禁止 sed 输出,但 p 标记会输出修改过的行,将二者匹配使用的效果就是只输出被替换命令修改过的行,例如:
[root@localhost ~]# cat data5.txt
[root@localhost ~]# sed -n 's/test/trial/p' data5.txt
7)w 标记会将匹配后的结果保存到指定文件中
[root@localhost ~]# sed 's/test/trial/w test.txt' data5.txt
[root@localhost ~]#cat test.txt
This is a trial line.
8)y 转换脚本命令,y 转换命令是唯一可以处理单个字符的 tr
[root@localhost ~]# sed 'y/123/789/' data8.txt
[root@localhost ~]# echo "This 1 is a test of 1 try." | sed 'y/123/456/'
This 4 is a test of 4 try.
其他编辑命令:
r 读入文件内容追加到匹配行后面
R 读入文件一行内容追加到匹配行后面
sed 's/north/hello/' datafile --替换每行第一个north
sed 's/north/hello/g' datafile --全部替换
sed '1 s/north/hello/g' datafile --替换第一行所有的north
sed '1 s/north/hello/' datafile --替换第一行第一个north
sed '1 s/north/hello/ 2' datafile --只替换第一行第二个north
巧用替换删除内容(不是删除行)
sed 's/north//' datafile --删除所有行的第一个north
sed 's/north//g' datafile --删除全部的north
sed '1 s/north//2' datafile --删除第一行第二个
sed 's/^.//' datafile --删除每行第一个字母
sed -r 's/^\(..\)./\1/' datafile --删除第3个字母
sed 's/^\<[a-Z]*[a-Z]\>//' datafile --删除每行第一个单词
7)y :y/source/dest/ 固定长度替换,要求替换的字符串长度相等
sed -n 'y/root/ROOT/' /etc/passwd
8)w /path/to/somefile:将匹配到的文件另存到指定的文件中
sed -n '/root/ w test' /etc/passwd
改写文件i在后
[root@172 ~]# sed -ir '/I/ s#([0-9]{,2}/){2}[0-9]{,2}#21/09/09#' a.sh
[root@172 ~]# cat a.sh
#!/bin/bash
I am a girl 21/08/08
[root@172 ~]# sed -ri '/I/ s#([0-9]{,2}/){2}[0-9]{,2}#21/09/09#' a.sh
[root@172 ~]# cat a.sh
#!/bin/bash
I am a girl 21/09/09、
8.5 sed扩展
特殊符号 介绍说明
! 对指定行意外的所有行应用命令(取反) sed '3,$ ! d' /etc/passwd
= 打印当前行行号 sed -n '=' a.sh
& 代表被替换的内容
; 实现一行命令语句可以执行多条sed命令 1p;2p;5p
{} 对单个地址或范围执行批量操作 {将多个规则,或者多个命令放在大括号通过;隔开}
+ 地址访问内用到的符号,做加法运算
[root@localhost ~]# sed -n '1 s/root/ROOT/p;2,3 p' /etc/passwd
'3,6 {p;=}' '3,6p;='
扩展命令
-e 可以指定多个表达式 [root@localhost ~]# sed -n -e '1 s/root/ROOT/p' -e '2,3 p' /etc/passwd
n **打印当前模式空间内容,然后读取下一行并替代当前模式空间的内容。如果读取不到下一行sed则会不运行之后的命令 **(读取指定行通过下一行覆盖该内容只对下一行进行处理)
N **读取下一行并且附加到当前模式空间内,如果读取不到下一行sed则会不运行之后的命令**(可以在模式空间同时读取两行内容进行处理)
cat >person.txt<<KOF
> 101,chensiqi,CEO
>102,zhangyang,CTO
>103,Alex,COO
>104,yy,CFO
>105,
>feixue,CIO
KOF
sed如何取不连续的行
sed -n '1p;3p;5p' person.txt
特殊符号=
sed -n '=' /etc/passwd 只显示指定文件的行号
特殊符号{}和;的使用
sed -n '2,4p;=' person.txt //-n去掉默认输出,2,4p,输出2到4行内容,=输出全部的行的行号
sed -n '2,4{p;=}' person.txt //命令说明:‘2,4{p;=}’代表统一输出2,4行的行号和内容
sed -n '2,+4{p;=}' person.txt //命令说明:‘2,4{p;=}’代表统一输出2,+4(6)行的行号和内容
sed N的用法
echo -e "1\n2\n3\n4" | sed -n 'N;s/\n/ /;p'
sed先读入第一行到pattern space,然后执行N命令,将第二行追加进pattern space
这时pattern space里面就是1\n2,然后执行s/\n/ /,将换行符替换成空格,最后打印。
echo -e "1\n2\n3\n4" | sed -n 'n;s/\n/ /p'
sed先读入第一行到pattern space,然后执行n命令,用第二行覆盖pattern space
这时pattern space里面就是2,然后执行s/\n/ /,因为pattern space里没有\n,所以不做任何替换,直接打印
[root@Mylinux tmp]# echo -e "1\n2" |sed -n 'n;p'
2
[root@Mylinux tmp]# echo -e "1\n2" |sed -n 'N;p'
1
2
seq 1 100|sed -n 'p;n' 奇数
seq 1 100|sed -n 'n;p' 偶数
seq 1 2 100
注:用shell来比喻的话
N是: echo 下一行内容>>模式空间
n是: echo 下一行内容>模式空间
下一个:n命令换行
[root@localhost /]# sed -n '1,6 {p;n}' /etc/passwd
sed '/test/{n; s/aa/bb/;}' 如果test被匹配,则移动到匹配行的下一行,替换这一行的aa,变为bb,并打 印该行,然后继续。
&的使用,& 符号在sed命令中代表上次匹配的结果
s/my/&/ 符号&代表查找串。my将被替换为my
-e是编辑命令,用于多个编辑任务
删除1到5行后,替换reboot为shutdown
sed -e '1,5d' -e '=' -e 's/reboot/shutdown/g' yum.log
!非
sed -n '2,43 ! p' /etc/passwd 打印非2,43行的信息
以选项中指定的script文件来处理输入的文本文件。
[root@localhost /]# sed -f aaa ccc
this is TEST
this is TEST
this is TEST
this is TEST
[root@localhost /]# cat aaa
1,4 s/test/TEST/
shell之sed
练习一:
创建文件datafile
datafile内容如下:
northwest NW Charles Main 3.0 .98 3 34
western WE Sharon Gray 5.3 .97 5 23
southwest SW Lewis Dalsass 2.7 .8 2 18
southern SO Suan Chin 5.1 .95 4 15
southeast SE Patricia Hemenway 4.0 .7 4 17
eastern EA TB Savage 4.4 .84 5 20
northeast NE AM Main Jr. 5.1 .94 3 13
north NO Margot Weber 4.5 .89 5 9
central CT Ann Stephens 5.7 .94 5 13
1、只打印找到north的行
2、删除第三行,其余行输出到屏幕
从第3行到最后一行都删除,将剩余部分输出到屏幕
3、找到datafile中的所有west并替换成north,将替换后的内容输出到屏幕。
4、所有的Hemenway所在的位置都用Jones来取代,而且只有改变的行被打印
5、打印在west和east之间的模式范围内所有行
6、把指定的行north写入到一个文件newfile中
7、在north行后添加“central CT Ann Stephens 5.7 .94 5
练习二:
datafile内容如下
Steve Blenheim:238-923-7366:95 Latham Lane, Easton, PA 83755:11/12/56:20300
Betty Boop:245-836-8357:635 Cutesy Lane, Hollywood, CA 91464:6/23/23:14500
Igor Chevsky:385-375-8395:3567 Populus Place, Caldwell, NJ 23875:6/18/68:23400
Norma Corder:397-857-2735:74 Pine Street, Dearborn, MI 23874:3/28/45:245700
Jennifer Cowan:548-834-2348:583 Laurel Ave., Kingsville, TX 83745:10/1/35:58900
Jon DeLoach:408-253-3122:123 Park St., San Jose, CA 04086:7/25/53:85100
Karen Evich:284-758-2857:23 Edgecliff Place, Lincoln, NB 92086:7/25/53:85100
Karen Evich:284-758-2867:23 Edgecliff Place, Lincoln, NB 92743:11/3/35:58200
Karen Evich:284-758-2867:23 Edgecliff Place, Lincoln, NB 92743:11/3/35:58200
Fred Fardbarkle:674-843-1385:20 Parak Lane, DeLuth, MN 23850:4/12/23:780900
Fred Fardbarkle:674-843-1385:20 Parak Lane, DeLuth, MN 23850:4/12/23:780900
Lori Gortz:327-832-5728:3465 Mirlo Street, Peabody, MA 34756:10/2/65:35200
Paco Gutierrez:835-365-1284:454 Easy Street, Decatur, IL 75732:2/28/53:123500
Ephram Hardy:293-259-5395:235 CarltonLane, Joliet, IL 73858:8/12/20:56700
James Ikeda:834-938-8376:23445 Aster Ave., Allentown, NJ 83745:12/1/38:45000
Barbara Kertz:385-573-8326:832 Ponce Drive, Gary, IN 83756:12/1/46:268500
Lesley Kirstin:408-456-1234:4 Harvard Square, Boston, MA 02133:4/22/62:52600
William Kopf:846-836-2837:6937 Ware Road, Milton, PA 93756:9/21/46:43500
Sir Lancelot:837-835-8257:474 Camelot Boulevard, Bath, WY 28356:5/13/69:24500
Jesse Neal:408-233-8971:45 Rose Terrace, San Francisco, CA 92303:2/3/36:25000
Zippy Pinhead:834-823-8319:2356 Bizarro Ave., Farmount, IL 84357:1/1/67:89500
Arthur Putie:923-835-8745:23 Wimp Lane, Kensington, DL 38758:8/31/69:126000
Popeye Sailor:156-454-3322:945 Bluto Street, Anywhere, USA 29358:3/19/35:22350
Jose Santiago:385-898-8357:38 Fife Way, Abilene, TX 39673:1/5/58:95600
Tommy Savage:408-724-0140:1222 Oxbow Court, Sunnyvale, CA 94087:5/19/66:34200
Yukio Takeshida:387-827-1095:13 Uno Lane, Ashville, NC 23556:7/1/29:57000
Vinh Tranh:438-910-7449:8235 Maple Street, Wilmington, VM 29085:9/23/63:68900
sed练习:
1.把Jon的名字改成Jonathan.
2.删除头三行
3.显示5-10行
4.删除包含Lane的行.
5.显示所有生日在November December的行
6.把三个星号(***)添加到以Fred开头的行
7.用JOSE HAS RETIRED取代包含Jose的行
8.把Popeye的生日改成11/14/46
9.删除所有空白行
===============================================================
sed实际应用场景示例:
===============================================================
假如你在51cto或其他技术论坛看到别人写的脚本,复制下来借鉴修改用作自己公司生产环境脚本。
但是从网上复制脚本代码后是类似如下结果:
001 #!/bin/sh
002
003 # source function library
004 . /etc/rc.d/init.d/functions
005
006 # Source networking configuration.
007 . /etc/sysconfig/network
...
每行开始都是以数字开头后面有n个空格,本例是5个空格,直接从论坛或技术博客上复制的代码大多是这种类似情况。
或者1.空格开头,处理的思路是一致的,触类旁通。
那么作为高级运维的你如何将行首编号和空格删除并能保证保持脚本缩进。
方法1:逐行去删除
显然这种方法太low了,没有技术含量,假设代码共有2万行,手工删到何年何月
方法2:使用sed实现
第一种方法:使用-e多点编辑
即先去掉编号,然后删除空格
sed -i -r -e 's@^[0-9]+@@' -e 's@^[[:space:]]{5}@@' 脚本名称
或者:
sed -i -r -e 's@^[0-9]+@@' -e 's@^[ ]{5}@@' 脚本名称
第二种方法:方法一的改进,一次实现
sed -i -r 's@^[0-9]+[[:space:]]{,5}@@' 脚本名称
sed -rn 's/[0-9][0-9][0-9]\s+(.*)/\1/g'
======================================================================
sed给文本文件加行号
======================================================================
1、用cat很简单就可以实现
# cat -n test
1 one
2 two
3 three
4 four
# cat -n test | sed -n -r 's/^[[:space:]]+//p'
1 one
2 two
3 three
4 four
2、 grep处理
# grep -n ".*" test | sed -n 's/:/\t/p'
1 one
2 two
3 three
4 four
3、sed处理
# sed = test | sed -n 'N;s/\n/\t/p'
1 one
2 two
3 three
4 four
= Print the current line number. h H g G
N命令:将下一行添加到pattern space中。将当前读入行和用N命令添加的下一行看成“一行”。
\n是表示换行,\t表示一个制表符
https://www.cnblogs.com/fhefh/archive/2011/11/22/2259097.html
4、awk处理
# awk '{print NR,$0}' test
8.6 sed案例
1、把/etc/passwd 复制到/root/test.txt,用sed打印所有行;
cp /etc/passwd /root/test.txt | sed -n 'p'
2、打印test.txt的3到10行;
sed -n '3,10 p' /root/test.txt
3、打印test.txt 中包含’root’的行;
sed -n '/root/ p' test.txt
4、删除test.txt 的15行以及以后所有行;
sed '15,$ d' test.txt
5、删除test.txt中包含’bash’的行;
6、替换test.txt 中’root’为’toor’;
7、替换test.txt中’/sbin/nologin’为’/bin/login’
sed -n 's%/sbin/nologin%/bin/login%p' test.txt
8、删除test.txt中5到10行中所有的数字;
sed -rn '5,10 s/[0-9]+//gp' test.txt
9、删除test.txt 中所有特殊字符(除了数字以及大小写字母);
sed -nr '/[^[:alnum:]]//p'
10、在test.txt 20行到末行最前面加’aaa:’
sed -n '20,$ i aaa;p' test.txt |sed '20,$ N;s/\n/ /'
11、删除centos7系统/etc/grub2.cfg文件中所有以空白开头的行行首的空白字符
sed -rn 's/^ +//p'
12、删除/etc/fstab文件中所有以#开头,后面至少跟一个空白字符的行的行首的#和空白字符
sed -nr 's/^# +//p'
13、在centos6系统/root/install.log每一行行首增加#号
sed -n 's/^/aaa/p'
14、在/etc/fstab文件中不以#开头的行的行首增加#号
sed -n '/^#/ ! s/^/#/p' /etc/fstab
15、处理/etc/sysconfig/network-scripts/file路径,使用grep 取出其目录名 sed命令取出其基名
echo /etc/sysconfig/network-scripts/file | grep -o '/.*/'
/etc/sysconfig/network-scripts/
echo /etc/sysconfig/network-scripts/file |sed -n 's@/.*/@@p'
file
echo ${aaa##.*/}
echo ${aaa%/*}
16、利用sed 取出ifconfig命令中本机的IPv4地址
17、统计centos安装光盘中Package目录下的所有rpm文件的以.分隔倒数第二个字段的重复次数
练习:
1、删除/etc/grub2.conf文件中所有以空白开头的行行首的空白字符
2、删除/etc/fstab文件中所有以#开头,后面至少跟一个空白字符的行的行首的#和空白字符
3、在/root/install.log每一行行首增加#号
4、在/etc/fstab文件中不以#开头的行的行首增加#号
5、利用sed 取出ifconfig命令中本机的IPv4地址
6、关闭本机SELinux的功能
7、在/etc/hosts配置文件中添加内容
第九章、shell编程之awk
9.1 什么是awk
Pattern scanning and text processing language awk模式扫描文本处理语言,没有一个动听的名字,但它是一种很棒的语言。 awk适合于文本处理和报表生成。 awk是一种一旦学会了就会称为您战略编码库的主要部分的语言。
awk是一种非常强大的数据处理工具,其本身可以称为是一种程序设计语言,因而具有其他程序设计语言所共同拥有的一些特征,例如变量、函数以及表达式等。通过awk,用户可以编写一些非常实用的文本处理工具。本节将介绍awk的基础知识。
9.2 awk的功能
awk是Linux以及UNIX环境中现有的功能最强大的数据处理工具。简单地讲,awk是一种处理文本数据的编程语言。awk的设计使得它非常适合于处理由行和列组成的文本数据。而在Linux或者UNIX环境中,这种类型的数据是非常普遍的。 除此之外,awk还是一种编程语言环境,它提供了正则表达式的匹配,流程控制,运算符,表达式,变量以及函数等一系列的程序设计语言所具备的特性。它从C语言等中获取了一些优秀的思想。awk程序可以读取文本文件,对数据进行排序,对其中的数值执行计算已经生成报表等。
9.3 awk的工作流程 print printf

aaa bbb ccc print $1
对于初学者来说,搞清楚awk的工作流程非常重要。只有在掌握了awk的工作流程之后,才有可能用好awk来处理数据。在awk处理数据时,它会反复执行以下4个步骤:
(1)自动从指定的数据文件中顺序读取一行信息
(2)匹配内置变量默认行的切割字符为空格字符,将该行切割为多个字段
(3)根据模式中的打印操作显示所需要的字段
(4)当执行完程序中所有的匹配模式及其操作之后,如果数据文件中仍然还有为读取的数据行,则返回到第(1)步,重复执行(1)~(4)的操作。
9.4 awk程序执行方式
1.通过命令行执行awk程序,语法如下:
awk [option...] 'program-text' [datafile]
2.执行awk脚本
在awk程序语句比较多的情况下,用户可以将所有的语句写在一个脚本文件中,然后通过awk命令来解释并执行其中的语句。awk调用脚本的语法如下:
awk -f program-file file ..
在上面的语法中,-f选项表示从脚本文件中读取awk程序语句,program-file表示awk脚本文件名称,file表示要处理的数据文件。
3.可执行脚本文件
在上面介绍的两种方式中,用户都需要输入awk命令才能执行程序。除此之外,用户还可以通过类似于Shell脚本的方式来执行awk程序。在这种方式中,需要在awk程序中指定命令解释器,并且赋予脚本文件的可执行权限。其中指定命令解释器的语法如下:
#!/bin/awk -f
以上语句必须位于脚本文件的第一行。然后用户就可以通过以下命令执行awk程序:
awk-script file
其中,awk-script为awk脚本文件名称,file为要处理的文本数据文件。
[root@172 ~]# cat a.awk
#!/bin/awk -f
{print $1,$2} -------注:脚本只能写主体,命令代码块
[root@172 ~]# awk -F: -f a.awk /etc/passwd
#!/bin/awk -f
BEGIN{a=1;b=2;print a+b}
[root@172 ~]# awk -f a.sh
3
[root@172 ~]# ./a.sh
3
9.5 awk基本语法
awk [-F|-f|-v] ‘BEGIN{} //{command1; command2} END{}’ file
[-F|-f|-v] 大参数,-F指定分隔符,-f调用脚本,-v定义变量 var=value
’ ’ 引用代码块
BEGIN 初始化代码块,在对每一行进行处理之前,初始化代码,主要是引用全局变量,设置FS分隔符
// 匹配代码块,可以是字符串或正则表达式
{} 命令代码块,包含一条或多条命令
; 多条命令使用分号分隔
END 结尾代码块,在对每一行进行处理之后再执行的代码块,主要是进行最终计算或输出结尾摘要信息
[root@172 ~]# awk -F: 'BEGIN{print "======BEGIN======"}{print $1$7}END{print "=====END======"}' /etc/passwd
[root@172 ~]# awk 'BEGIN{a=1;b=2;sum}{sum=a+b}END{print sum}' /etc/passwd
注:后面必须跟文件名。并且确保文件存在不为空。
9.5.1 awk输出
1)print的使用格式:
print item1, item2, ...
要点:
1. 各项目之间使用逗号隔开,而输出时则以空白字符分隔; awk -F : '{print "user:",$1,$3}' /etc/passwd 注意按指定参数输出user: 需要加引号,不加引号会识别为变量。
2. 输出的item可以为字符串或数值、当前记录的字段(如$1)、变量或awk的表达式;数值会先转换为字符串,而后再输出; awk -F : '{print "user:",$1,$3, 4+3}' /etc/passwd
3. print命令后面的item可以省略,此时其功能相当于print $0, 因此,如果想输出空白行,则需要使用print “”;
示例:
[root@localhost ~]# awk 'BEGIN { print "line one\nline two\nline three"}'
line one
line two
line three
[root@localhost ~]# awk -F: '{print $1" "$3}' /etc/passwd | head -n 3
root 0
bin 1
daemon 2
2)printf命令的使用格式:
1、其与print命令的最大不同是,printf需要指定format;
2、format用于指定后面的每个item的输出格式;
3、printf语句不会自动打印换行符;\n
format格式的指示符都以%开头,后跟一个字符;如下:
%c: 显示字符的ASCII码;
%d, %i:十进制整数;
%e, %E:科学计数法显示数值;
%f: 显示浮点数;
%g, %G: 以科学计数法的格式或浮点数的格式显示数值;
%s: 显示字符串;
%u: 无符号整数;
%%: 显示%自身;
修饰符:%-Ns
N: 显示宽度;
-: 左对齐;
+:显示数值符号;
示例:
[root@localhost ~]# awk -F: '{printf "%-15s %i\n",$1,$3}' /etc/passwd |head -n 3
root 0
bin 1
daemon 2
3)输出重定向
print items > output-file
print items >> output-file
print items | command ****
特殊文件描述符:
/dev/stdin:标准输入
/dev/sdtout: 标准输出
/dev/stderr: 错误输出
/dev/fd/N: 某特定文件描述符,如/dev/stdin就相当于/dev/fd/0;
示例:
[root@localhost ~]# awk -F: '{printf "%-15s %i\n",$1,$3 > test1}' /etc/passwd
[root@localhost ~]# awk -F ':' '{print $1 | "sort"}' passwd
9.5.2 awk变量
1) awk内置变量之记录变量
FS: field separator,读取文件本

















 1212
1212

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









