






一、多维特征(multidimensional features)
首先我们先从符号开始认识
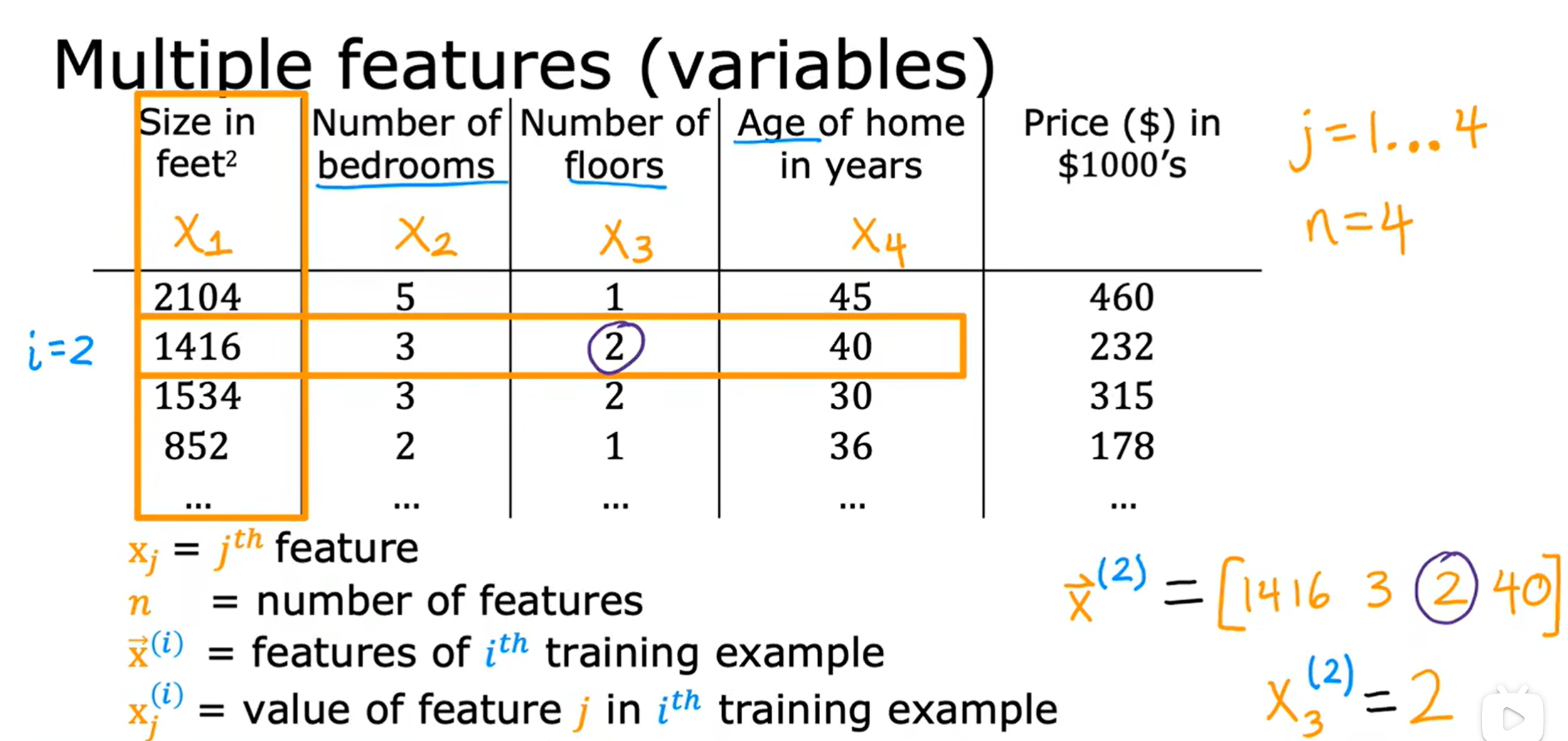
:代表第j个特征变量 n:代表特征变量的总个数
:代表第i个训练示例或包含第i个训练示例的所有的特征的向量
: 第j个特征变量的第i个训练示例
多变量线性回归模型(multiple linear regression model) :
对于有n个特征的模型其表达式为:
再引入w的行向量
由此行向量和b即为函数
的参数
此时x也可以写为行向量
通过向量的替换,我们可以得到简化的函数表达式:
注意:这里的·代表向量点积,结果就为
,不是矩阵运算,可以不转置
矢量化:
当我们编写代码时,通过矢量化既可以缩短代码,又可以提高运行效率

图中展示了三种编写代码方式:穷举法,for循环法,使用NymPy数值线性代数库函数法。这三种方式的效率依次提高,且随着n的增大,效率和编写速度会逐渐形成很大的差距。这里我们主推使用第三种方法。
NymPy数值线性代数库中的NumPy.dot能够实现两个向量之间的点积运算。 NymPy数值线性代数库中的函数使用计算机的并行硬件(通过内部机制和通用函数实现并行计算),从而大幅提升计算效率,节省时间。
2025.4.26
多变量线性回归的梯度下降算法:
我们统一使用矢量化的方法,模型函数和代价函数如下
然后重复下列过程
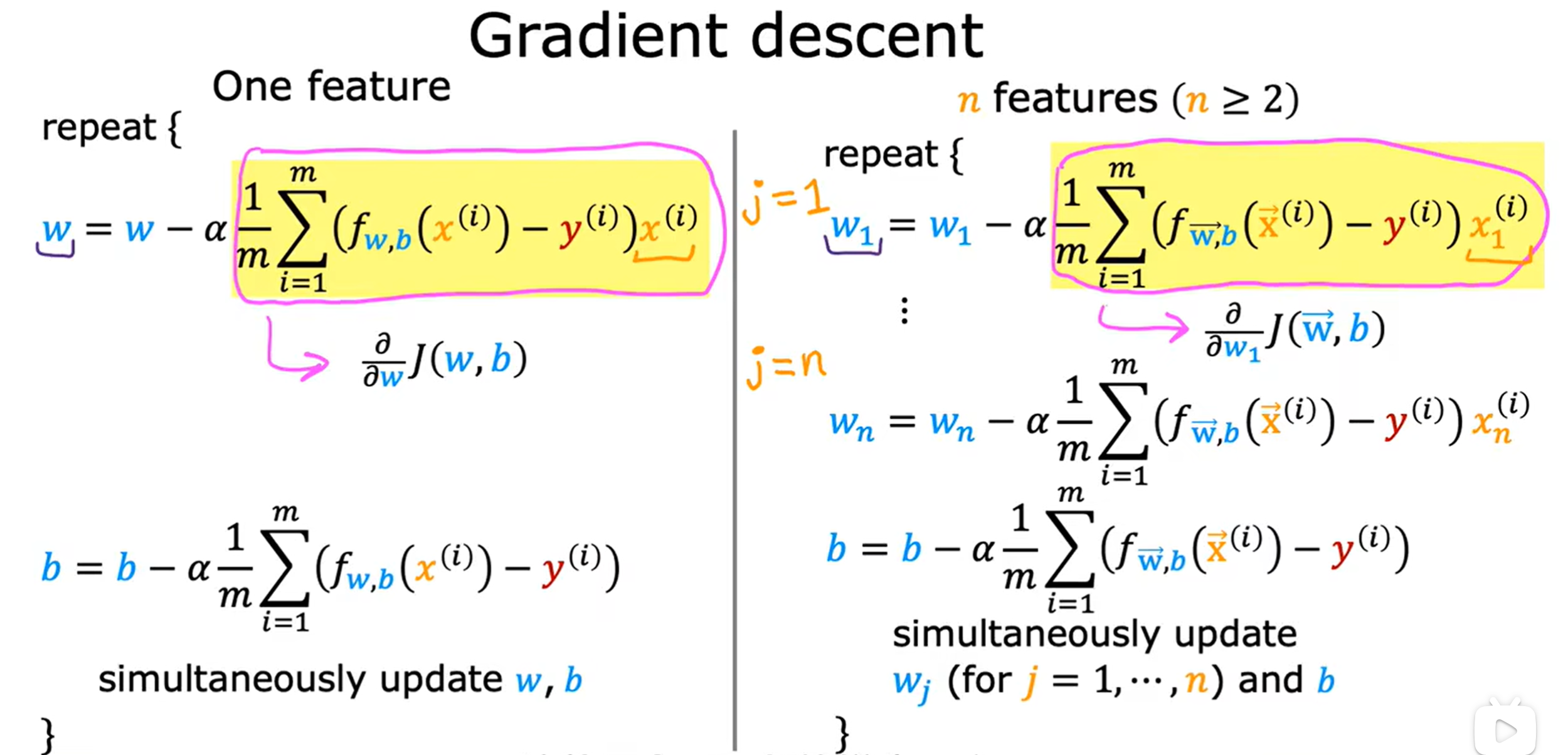
这里给出了导数项的推导过程,得到我们最终的多变量线性回归的梯度下降算法
repeat{
,为正整数
}
现在再简单介绍一种只适用于线性回归的算法:正规方程算法(Normal Equation)

这种方法能够不需要迭代运算就能解出我们在梯度下降算法中所需要的w、b参数的值,它通过使用高级线性代数库及其相关公式一次性求得最优解时对应的模型参数。
正规方程算法的数学推导:
假设我们的线性回归模型是:
对于给定的训练数据集 ,目标是找到参数
,使得成本函数(代价函数)最小化,我们需要解下列方程:
其中
是训练数据矩阵,包含每个训练样本的特征值(包括1的偏置项)
是
的转置矩阵
是
的逆矩阵
是目标值(标签)矩阵,即给出的训练示例中的结果值所组成的列矩阵
特别说明:
需要包含一列全为1的偏置项
举例:
1 2 2 3 6 7 对于上述表格,我们所创建的
然后就利用线性代数的方法,进行矩阵间的运算,最后我们将之间得到参数的矩阵,这个矩阵中的值,就是代价函数取得最小值时的
的一系列参数值。
基于ChatGPT对于两种算法的比较
| 特性 | 正规方程法 | 梯度下降法 |
|---|---|---|
| 计算复杂度 | O(n3)O(n^3)O(n3)(求解矩阵的逆) | O(n)O(n)O(n) 每次迭代,O(mn)O(mn)O(mn) 总复杂度 |
| 内存需求 | 高,需要存储矩阵和逆矩阵 | 较低,只需要存储参数和梯度 |
| 适用数据规模 | 适用于小规模数据集(小 nnn 和 mmm) | 适用于大规模数据集(大 mmm 或 nnn) |
| 精度 | 精确解(前提是 XTXX^T XXTX 可逆) | 近似解,可能会因为学习率或收敛问题有所误差 |
| 是否需要学习率 | 否 | 是,需要选择合适的学习率 |
| 适用范围 | 只适用于线性回归模型 | 适用于广泛的机器学习问题,包括线性回归、逻辑回归、神经网络等 |
2025.4.27
二、特征缩放(feature scaling)
具体示例:
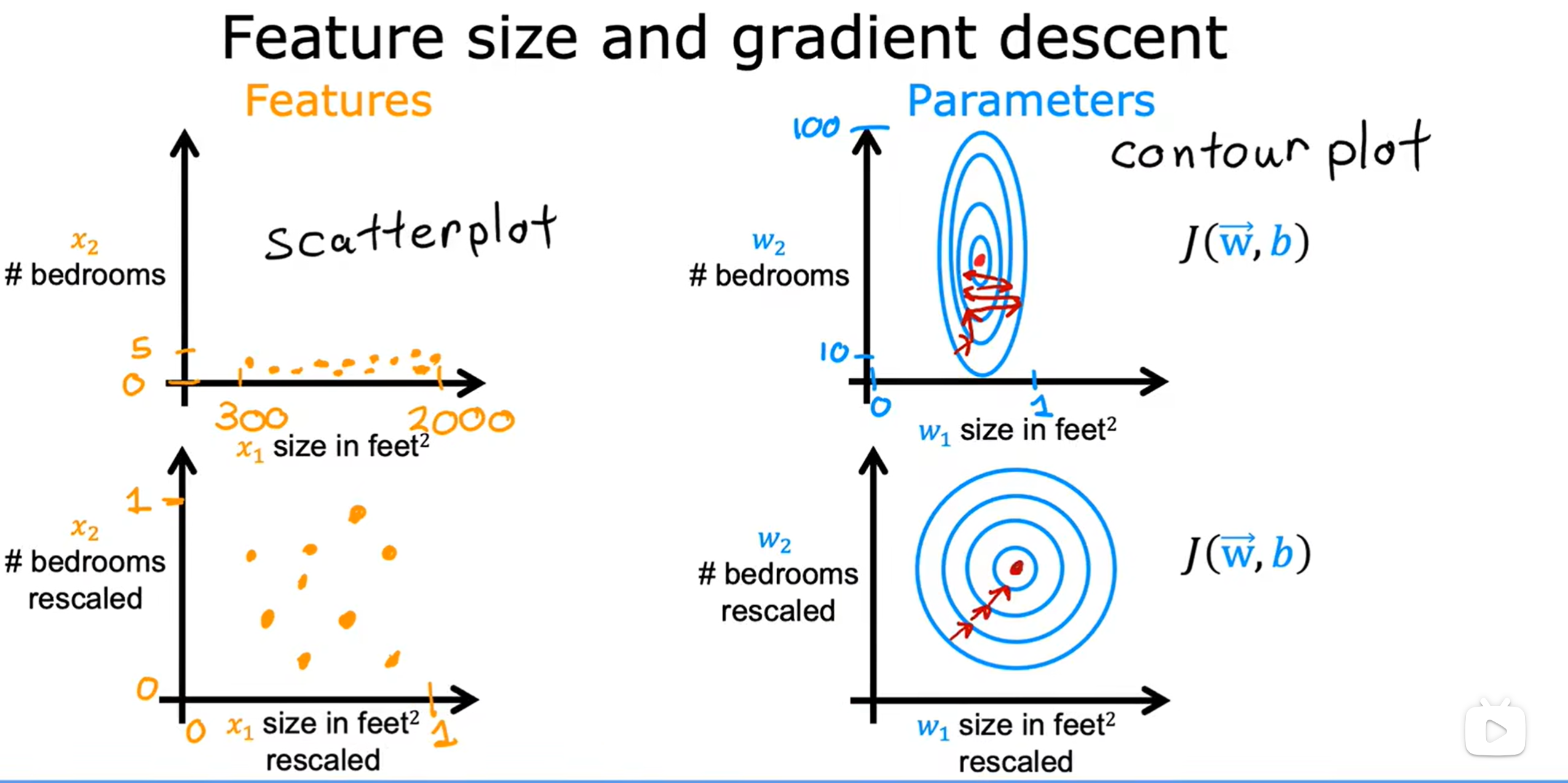
上述例子体现了如果一个特征变量变化范围很大,而另一个很小,就极有可能造成代价函数等高线图成为细长的椭圆形,因为变化小的特征变量需要较小的参量,反之亦然,这样才能符合最终的目标值,这也会造成梯度下降法在取得最小值时来回弹跳无法取得。
如果我们进行特征缩放(这里可以体现为将特征变量都进行归一化处理),目标值分布的较为平均,使得代价函数等高线图将更像一连串的同心圆,每次下降的步长都较为一致,梯度下降可以找到一条更直接的通往全局最小值的路径。
特征缩放的具体方法:
1.除以特征变量的最大值
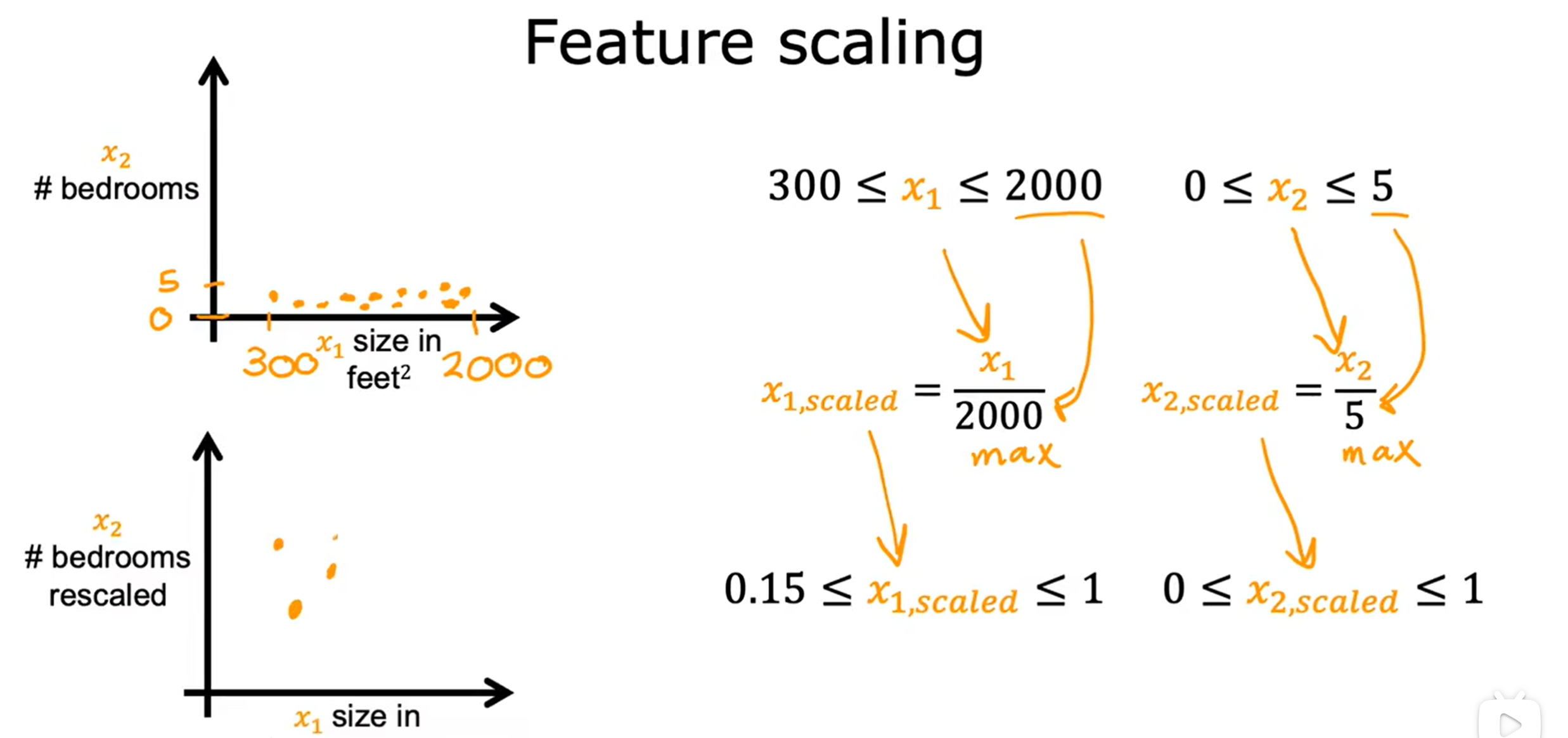
将两个特征变量分别除以各自的最大值即可使得其范围在[0,1]内。
2.均值归一化

首先对所有的特征变量的取值求其平均值,然后利用
分别再带入特征变量x的最小值和最大值,得出的取值范围,
3.Z-score归一化
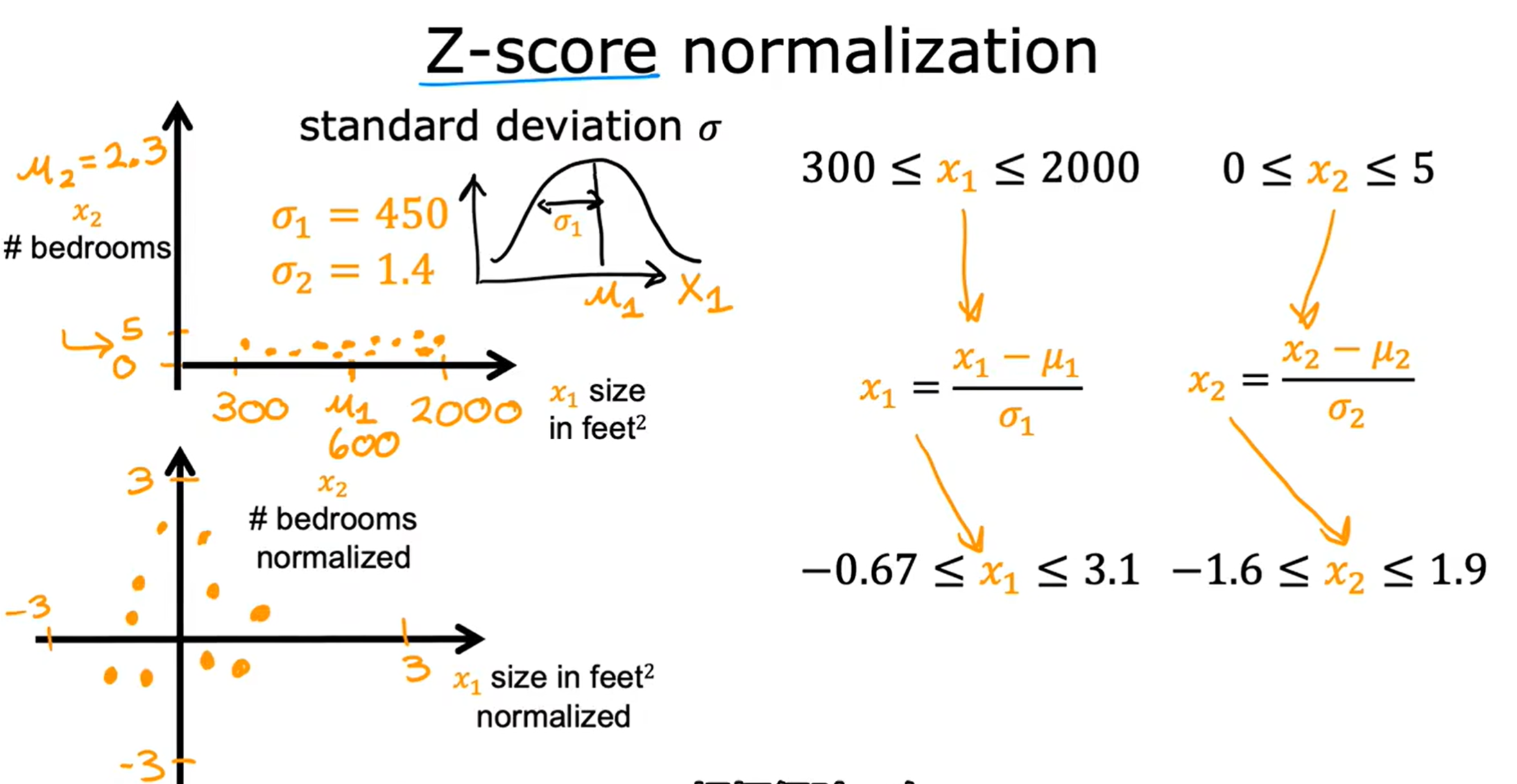
这里我们首先介绍一下(标准差)该如何计算:
N:为特征变量的个数 :为特征变量的平均值
然后利用
带入特征变量的最小值和最大值求出范围即可
一般情况下,尽量使特征变量的取值范围在
之间,同时也不能太小。如果在有多个特征变量的情况下无法进行缩减,也应尽量使各个特征变量的取值范围尽可能相近,方便计算和绘图。数值范围的缩小也有利于减小底层代码的精度压力。
三、优化梯度下降算法(Optimization of gradient descent algorithms)
对于我们之前提到梯度下降算法,这里不在赘述,我们现在要关心,我们如何才能判断一个梯度下降算法是否真正是有效、合适的。
1.如何判断梯度下降是否收敛:

方法一:绘制学习曲线
通过简单绘制一个横坐标为学习次数(迭代次数),纵坐标为代价函数值的坐标系,我们可以由学习曲线判断,梯度下降算法在无限次迭代后是否会趋于一个固定值,即收敛。
正常情况下的梯度下降算法的学习曲线应该总是一条单调减函数,如果函数呈现出递增趋势或者其他复杂形势,我们就需要注意可能出现的问题,通常我们都应该优先减小学习率,看学习曲线是否会单调递减,如果仍没有单调递减,再检测其他问题。
1. 学习率设置太大(大概率都是这个导致的)
问题原因:步子太大,模型每次更新就跳过了最优点,导致损失越来越大。
解决方法:减小学习率(比如原来是0.1,改成0.01)。
2. 过拟合(如果是训练集下降但验证集上升)
问题原因:模型在训练集学得很好,但在验证集越来越差,说明记住了训练集噪声,而不是学到了规律。
解决方法:加强正则化(比如加L2正则项),使用Early Stopping(提前终止训练),收集更多数据,或者简化模型(减小神经网络的规模)
3. 数据本身问题
问题原因:数据中可能有错误、噪声、标签错标,或者分布突然变化。
解决方法:检查数据质量,修正异常点。
4. 算法设计错误
问题原因:模型公式错了、损失函数写错了、梯度计算有问题等。
解决方法:检查模型结构、损失定义和反向传播公式。
方法二:自动收敛判定
简单来讲就是进行多次比较大小,通过每次迭代后比较当前代价函数值和上一次代价函数值,得出变化量,如果变化量小于一个设定阈值(比如 ),就认为收敛。
数学表达:
设定收敛阈值为,如果满足:
就停止训练
2.设置学习率
关于学习率的问题,在第二章 梯度下降(gradient descent)部分就已经进行了详细的讨论,详情请查看第二章 梯度下降(gradient descent)或该链接第二章 单变量线性回归
四、多项式回归(polynomial regression)
我们都知道直线虽然简单但是太过单调,当训练集较为复杂时,我们就可以通过多项式拟合来提高准确性,这就是多项式回归(polynomial regression)。
在回归过程中,除了初始的特征变量,我们也可以按照需求自己添加新的特征变量(要跟原来的特征变量有一定的联系)。
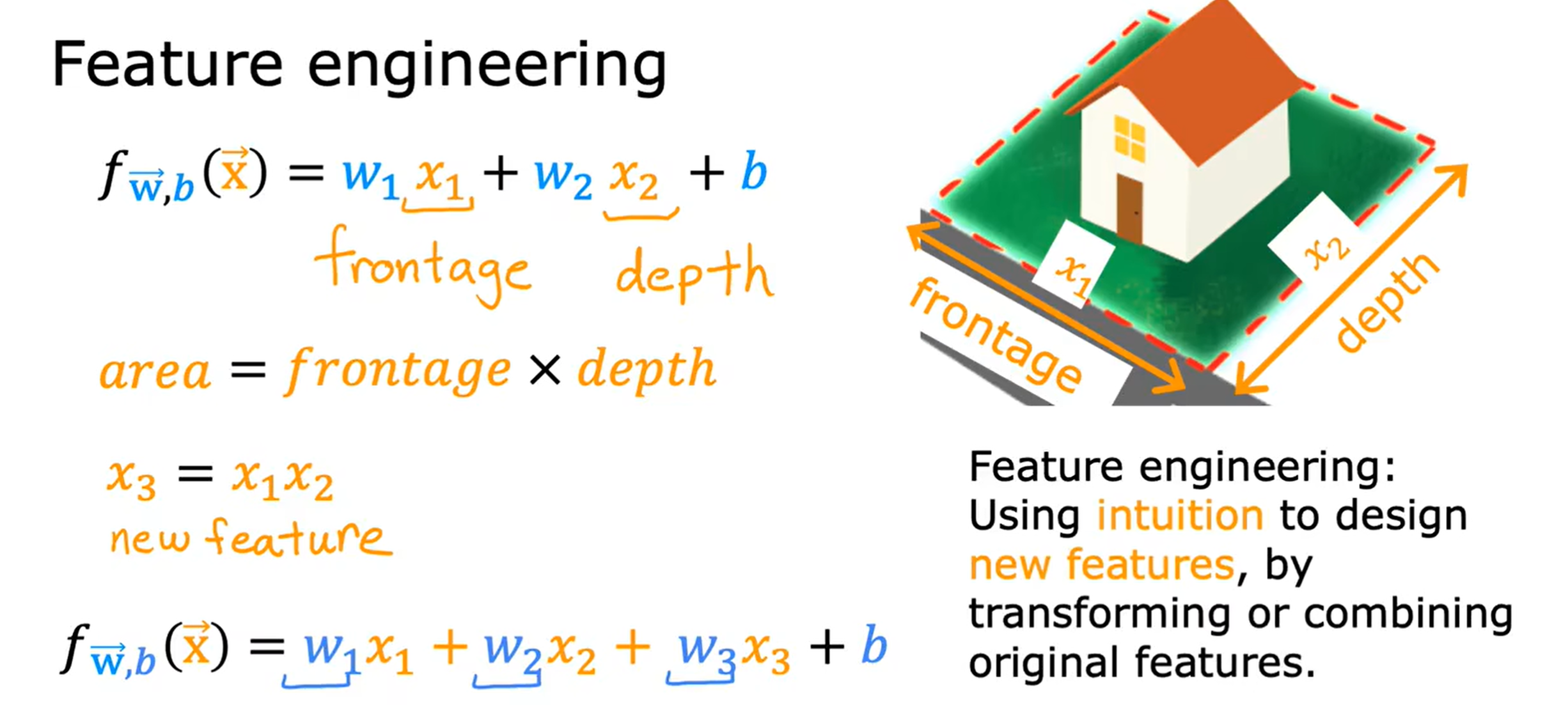
例如,在这个例子中,对于房屋来说,长宽时基本参数,而它们的乘积——房屋面积也是比较重要的参数,当我们在拟合过程中,就可以添加新的特征变量——房屋面积,来更好的进行数据拟合。这个过程就是特征工程(feature engineering)
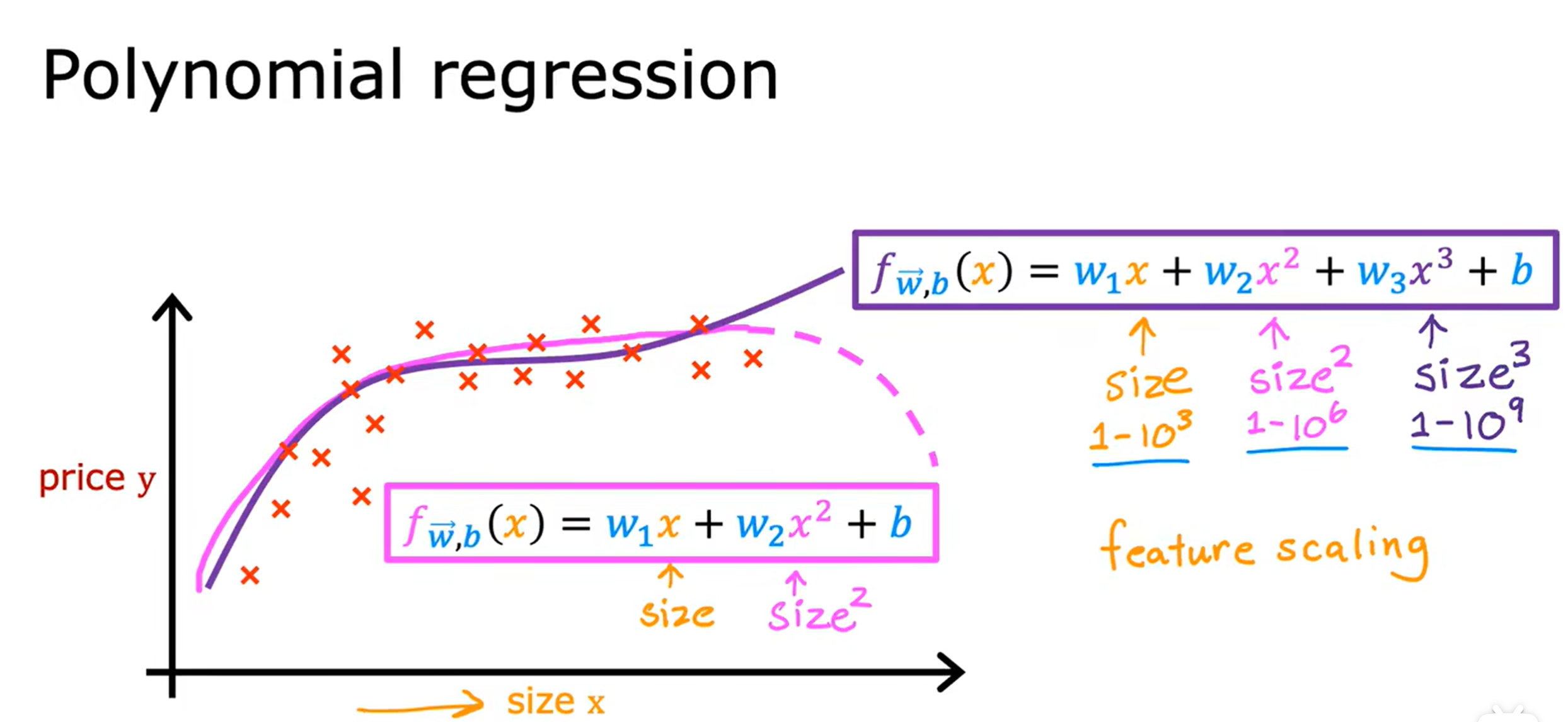
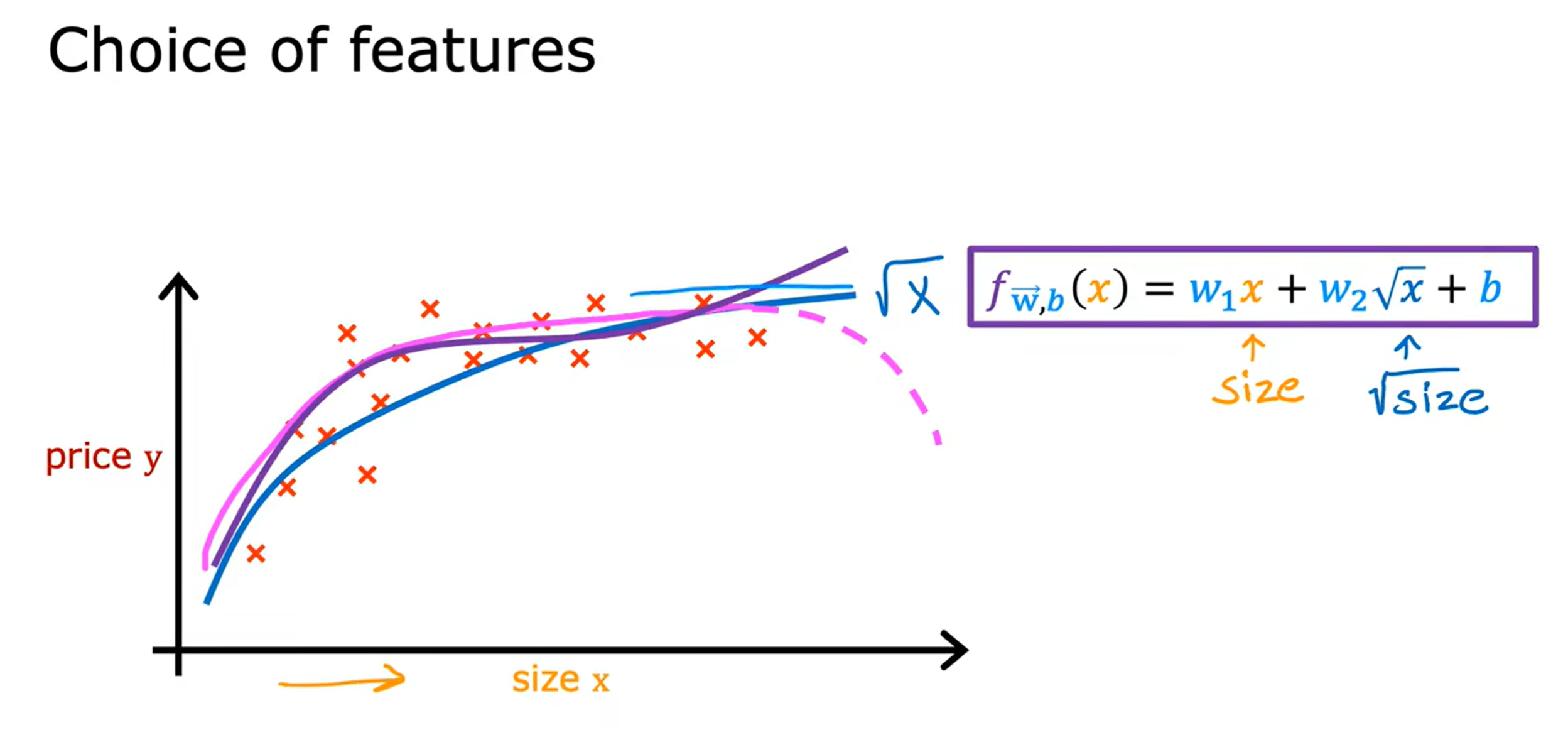
这两个示例,简单的展示了多项式曲线拟合的结果,它不再像线性回归有固定的单调性,而是呈现复杂的变化趋势,这样才能更加具有一般性。这里我们只是简单地进行引入,在之后的学习我们将继续了解如何选择不同的特征和不同的模型。
特别指出:在使用多项式回归时,我们的拟合函数一定要注意特征缩放的合理性,否则简单的变化,在经过平方、立方等放大或者开平方、开立方等缩小后,将产生极大的影响,所以要控制特征变量取值的合理性。
第一课 第二周 完
2025.4.28


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









