







 本文深入介绍了YOLO(You Only Look Once)目标检测和分类算法,包括YOLO的工作原理、优势,以及与其他算法如RCNN、Faster R-CNN的对比。YOLO以其快速、端到端的特性在实时应用中表现出色,尽管在准确性上可能略逊于某些其他模型。
本文深入介绍了YOLO(You Only Look Once)目标检测和分类算法,包括YOLO的工作原理、优势,以及与其他算法如RCNN、Faster R-CNN的对比。YOLO以其快速、端到端的特性在实时应用中表现出色,尽管在准确性上可能略逊于某些其他模型。
介绍
计算机视觉是人工智能的领先领域之一,它使计算机和系统能够从数码照片、电影和其他视觉输入中提取有用的信息。它使用基于机器学习的模型算法和基于深度学习的神经网络来实现。计算机视觉实现包括面部识别、手势识别、人类情绪检测分析、颜色检测、对象检测和分类以及其他值得注意的应用。在本文中,我们将讨论 YOLO(You Only Look Once),一种最高级的目标检测和分类算法。在潜水之前,了解这些术语以及检测和分类之间的区别非常重要。

(来源:YOLO V1 的原始论文)
什么是对象检测和分类:
目标检测和分类技术是计算机视觉领域广泛使用的方法。使用图像/视频/相机源作为输入使系统能够实时识别和分类帧中的对象。
对象检测简单地说就是检测帧中的对象。检测是为了验证或确认帧中对象的存在。对象检测方法应该能够返回对象在帧中的位置。
另一方面,对象分类是对对象进行分类。分类就是预测对象的类别。即,它返回检测到的物体是汽车、动物还是像我们这样的人。卷积神经网络是最流行的对象分类模型神经网络。
什么是YOLO?
You Only Look Once (YOLO) 是一种(实时)检测和识别图片中的各种对象的算法。2015 年,对象检测、对象检测、对象检测和对象检测自豪地向对象检测算法领域展示了一种新方法。提供了物体检测论文链接。该模型将一幅图像或一系列图像(视频帧)作为输入,并返回重要特征,如 x 坐标、y 坐标、类名称和置信度分数(概率)。与其他算法相比,YOLO 承诺出色的学习能力、更快的速度(高达 45 FPS)和高精度。它的尺寸也很小。YOLO V6-s 是 YOLO 系列的最新成员,使用 TensorRT FP16 进行 bs32 推理,在 COCO val2017 数据集上实现了 43.1 mAP,在 T4 上实现了 520 FPS。
为什么是YOLO?(YOLO 与其他算法)
YOLO 是一种单阶段算法,由 24 个 CNN 层和后面的两个全连接层组成。这意味着整个帧的预测是在单个算法运行中进行的。CNN 用于同时预测各种类别概率和边界框。它比其他两阶段算法(检测和分类)的 RCNN、Fast RCNN、masks RCNN 等对象检测算法更快地回答对象的“WHAT”和“WHERE”。端到端对象检测的单次迭代同时预测边界框和类概率。从而提高结果的准确性。
如果我们看一下多阶段 R-CNN 模型,它利用选择性搜索来提取帧中的多个部分,称为区域(~2000 个区域)。这些是我们在下图中看到的黄色框。接下来,对于每个区域提案,我们使用 CNN 网络,该网络经过图像分类训练来创建特征向量。最后,我们通过传递特征向量并对每个类别使用线性 SVM 模型来对每个区域进行分类。
每个区域提案都独立地馈送到 CNN 进行特征提取。这使得 R-CNN 无法实时运行。

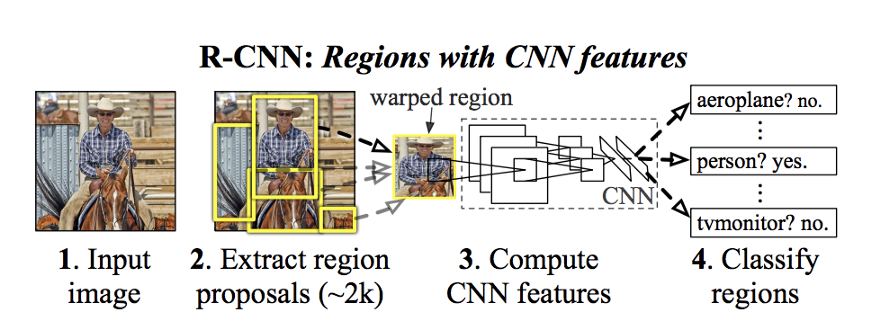
(来源:https://arxiv.org/pdf/1311.2524.pdf)
Faster R-CNN 模型使用区域提案网络(RPN)来生成区域提案。然后快速 R-CNN 模型对其进行处理以检测区域中的对象。这比 R-CNN 快得多,但 YOLO 以其单次迭代算法击败了它们。下面是R-CNN和YOLO算法的比较。

(来源:IEEE 2020 会议)
是什么让 YOLO 这么快?
YOLO 在框架上的单次迭代中,遵循3 个步骤来识别和分类对象。

(来源:YOLO第一篇论文)
1. 残差框:图像/帧被划分为固定尺寸的网格,例如 n*n。每个细胞都试图检测其内部的物体。我们可以在上图中看到残差框是如何生成的。
2. 边界框回归:它是突出图像中对象的轮廓。它的属性是高度、宽度、(对象的)类和框中心(bx,by)。在上图的第二步中,边界框以黄色突出显示。
3. Intersection over union:描述了盒子如何重叠。如果预测的边界框与真实的边界框相同,则 IOU 等于 1。这种机制消除了不等于真实框的边界框。IOU 计算为“重叠面积”与“联合面积”的比率。最后,通过非极大值抑制,YOLO抑制所有概率分数较低的边界框,以获得最终的边界框。
YOLO架构

它由三部分组成:
-
Backbone:Yolov5 将跨阶段部分网络(CSPNet)合并到 Darknet 中,创建 CSPDarknet 作为其主干,用于从图像中提取关键特征。CSPDarknet 采用 DarkNet 进行对象检测。使用 CSPNet 技术将基础层的特征图分为两部分,然后使用跨阶段层次结构将这两部分组合起来。
-
颈部:Yolov5 采用路径聚合网络(PANet)作为颈部,用于创建特征金字塔网络。FPN 以完全卷积的方式从任意大小的单尺度图像生成多个级别的按比例缩放的特征图。底层的卷积设计与此过程无关。这有助于模型识别不同尺寸和比例的同一物体。
-
Head:Yolov5的头部,即Yolo层,负责最终的检测步骤,即执行密集预测。它使用锚框来构建具有类别、置信度分数和边界框的最终输出向量。
YOLO实现


我们在视频上的 2 个数据集:COCO(81 类)和 Object365(365 类)上实现了 YOLO v5,下面是一帧的输出快照。我们可以看到标有类名称和概率分数的边界框作为输出。这是对象检测实施的官方指南。


结论
YOLO家族自诞生以来一直是目标检测和分类算法的最高领导者。尽管 YOLO 比其他目标检测器模型具有较高的计算速度并且花费的时间更少,但它在准确性方面落后于 Faster R-CNN。


















 3087
3087

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











