







虚拟数字人驱动技术是讯飞智作 AI 配音平台的核心功能之一,它将先进的 AI 配音技术与虚拟数字人技术深度融合,为用户提供高度逼真、互动性强的虚拟人物语音播报和视频生成服务。
一、基本原理
虚拟数字人驱动技术的核心目标是将文本转化为具有自然语音和生动形象的虚拟人物视频。其主要流程包括以下几个步骤:
1.虚拟人形象创建与管理:用户可以选择或定制虚拟人物的形象,包括面部特征、身体特征、服装等。
2.文本处理与语音合成:对输入的文本进行预处理,并利用 AI 配音技术生成自然流畅的语音。
3.语音驱动动画生成:根据生成的语音,实时生成虚拟人物的口型和动作。
4.视频合成与渲染:将虚拟人物的动作、口型与语音进行同步,并进行渲染,生成最终的虚拟人视频。
二、具体实现步骤
1. 虚拟人形象创建与管理
1.1 虚拟人形象库
讯飞智作提供丰富的虚拟人形象库,用户可以从以下几类中选择:
-
预定义形象:包括不同性别、年龄、职业、风格的虚拟人物,例如:
- 新闻主播:庄重、专业的形象。
- 卡通人物:可爱、活泼的形象。
- 虚拟助手:简洁、现代的形象。
-
自定义形象:
- 用户上传:用户可以上传自定义的 3D 模型或 2D 形象。
- 参数化定制:用户可以通过调整参数(如面部特征、身体比例、发型、服装等)来创建独特的虚拟人物。
模型公式:

1.2 虚拟人形象参数调整
用户可以对虚拟人形象进行精细调整,包括:
- 面部特征:眼睛大小、形状;鼻子形状;嘴巴形状;眉毛形状等。
- 身体特征:身高、体重;体型(瘦、匀称、壮);发型(短发、中长发、长发);发色等。
- 服装与配饰:选择不同的服装风格和配饰,如眼镜、帽子、项链等。
模型公式:

2. 文本处理与语音合成
2.1 文本预处理
- 文本规范化:将输入文本转换为标准格式,包括数字、缩写、特殊符号的处理。
- 分词与词性标注:将文本拆分为词语,并标注每个词语的词性。
- 语义理解与情感分析:理解文本的语义和情感倾向,为语音合成提供指导。
模型公式:

2.2 AI 配音
-
语音合成:利用深度学习模型(如 Tacotron、FastSpeech)将预处理后的文本转换为语音频谱。

-
声码器生成:使用声码器(如 WaveNet、HiFi-GAN)将语音频谱转换为语音波形。

-
情感调整:根据情感标签,调整语音的语调、语速和音量,以增强情感表达。

2.3 语音处理
- 去噪处理:去除语音信号中的背景噪音。
-
音量均衡:调整语音的音量,使其更加自然。

3. 语音驱动动画生成
3.1 口型同步(Lip Synchronization)
-
语音特征提取:从语音信号中提取出关键的语音特征,如音素、音节、语调、语速等。

-
口型预测模型:利用深度学习模型(如 LSTM、Transformer)根据语音特征预测口型变化。

-
口型动画生成:根据预测的口型参数,生成虚拟人物的口型动画。
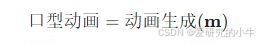
3.2 动作同步
-
文本语义分析:分析文本的语义,识别出需要虚拟人物做出相应动作的关键词或短语。

-
动作库匹配:根据动作标签,从预定义的动作库中选择合适的动作。

-
动作动画生成:根据选择的动作序列,生成虚拟人物的动作动画。

4. 视频合成与渲染
-
虚拟人物渲染:将虚拟人物的形象、动作动画和口型动画进行渲染,生成虚拟人物的动态视频。

-
语音与视频同步:将生成的语音与虚拟人物的动态视频进行合成,生成最终的视频输出。

三、关键技术实现
1. 深度学习模型
- 语音合成模型:使用 Tacotron、FastSpeech 等模型,将文本转换为语音频谱。
- 声码器:使用 WaveNet、HiFi-GAN 等模型,将语音频谱转换为语音波形。
- 口型预测模型:使用 LSTM、Transformer 等模型,根据语音特征预测口型变化。
- 动作预测模型:使用 NLP 技术,分析文本语义,识别动作标签。
2. 动画生成技术
- 关键帧动画:根据预测的口型和动作参数,生成关键帧动画,再通过插值生成连续的动画序列。
- 物理模拟:模拟虚拟人物的物理运动,如惯性、重力等,使动作更加自然。
3. 同步技术
- 时间对齐:确保语音与虚拟人物的动作和口型在时间上保持一致。
- 实时渲染:实现虚拟人物的实时渲染和视频输出。
4. 虚拟人物建模
- 3D 建模:构建虚拟人物的 3D 模型,包括面部、身体、服装等。
- 材质与纹理:为虚拟人物添加逼真的材质和纹理,使其更加生动。
5. 语音驱动技术
- 语音驱动动画:根据语音信号的变化,实时驱动虚拟人物的口型和动作。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











