






set使用

set在我们就是我们前面学习的k模型,它可以用来比对数据,增删查的时间复杂度都是O(logn)效率非常高,由于它底层的原因,它也可以实现排序,通过中序遍历可以输出我们的有序的数据;又因为它的T值在插入的时候具有唯一性的原因,set还有去重的作用;
set的接口
参数:
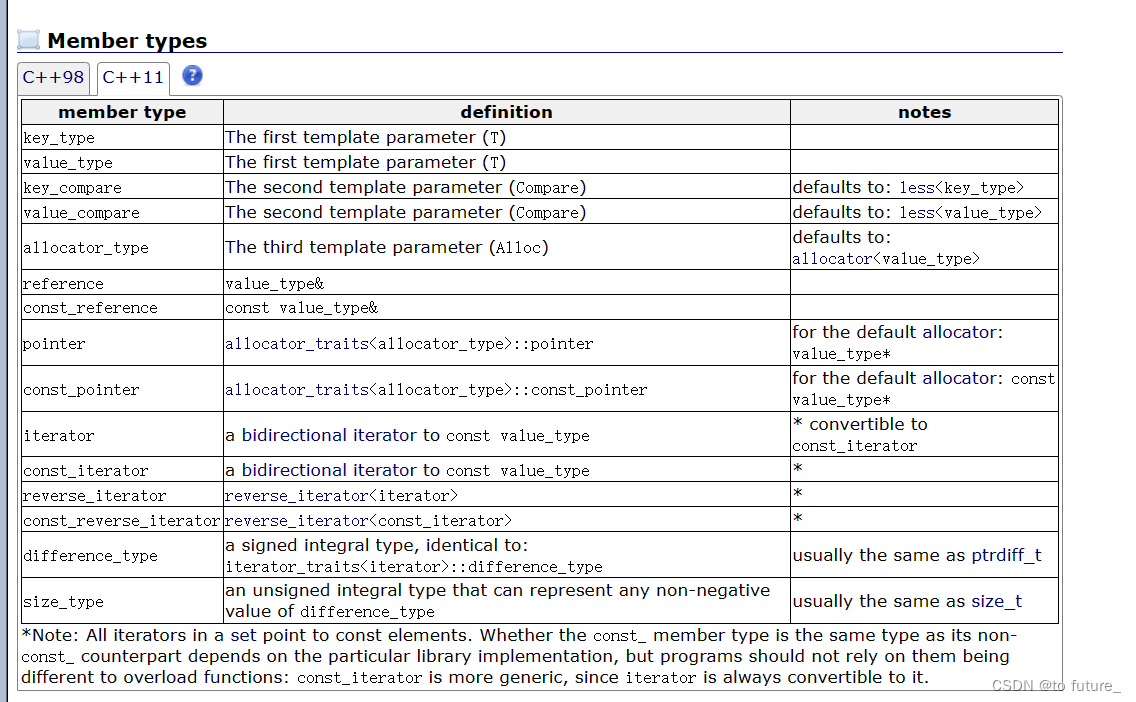
set的构造函数
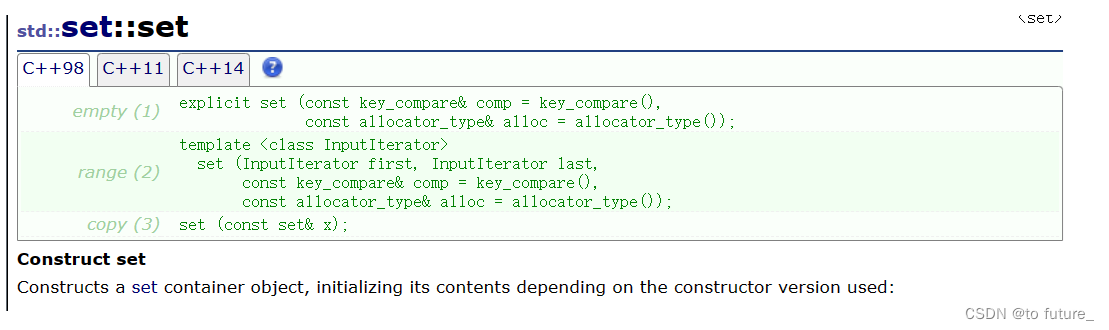
set有无参的,迭代器区间的,拷贝构造函数;
set的迭代器

set的迭代器都是双端迭代器
接下来,我们使用一些代码来试验一下set的这些接口:
int main()
{
int arr[] = { 8,6,2,4,5,3,1,7,9 };
set<int> s_range(arr, arr + 9);
cout << "s_range: ";
for (auto x : s_range)
{
cout << x << " ";
}
cout << endl;
set<int> s_empty;
s_empty.insert(5);
s_empty.insert(8);
s_empty.insert(4);
s_empty.insert(9);
s_empty.insert(7);
s_empty.insert(3);
set<int>::iterator ret = s_empty.begin();
cout <<"s_empty: ";
while (ret != s_empty.end())
{
cout << *ret << " ";
ret++;
}
cout << endl;
set<int> s_copy(s_empty);
cout << "s_copy: ";
for (auto x : s_copy)
{
cout << x << " ";
}
cout << endl;
}
可以看到我们可以使用三种不同的方式构造 ;
set的增删查接口
下面是set常用的接口,需要了解这些,可以到set - C++ Reference (cplusplus.com)网站上面清楚明了的查看;



我感觉set,map这些接口了解大致使用就好了,所以我不打算过多的描述;
set中还有一个multiset
multiset是允许键值冗余的,也就是说,当有相同元素插入的时候,是可以正常插入的multiset中的;其中我们如果我们使用find接口寻找这个值的时候,寻找的是中序遍历的第一个值;
实验:键值冗余时find寻找的元素
int main()
{
int arr[] = { 5,3,7,2,4,6,6,6,8 };
multiset<int> s;
for (auto x : arr)
{
s.insert(x);
}
cout << "全部元素:";
for (auto x : s)
{
cout << x << " ";
}
cout << endl;
auto ret=s.find(4);

我们可以看到如果是从中序的第一个那么就会find我们全部的6,如果非中序,那么输出的也就不是全部的6了;所以证明我们find是中序遍历的;
map使用

map存放了两个数据 ,它就是前面学的kv模型;一般我们使用map获得的返回值都是pair类型的,因为需要返回k,v两个值,所以将他们封装在了我们的一个类pair中;
map操作:
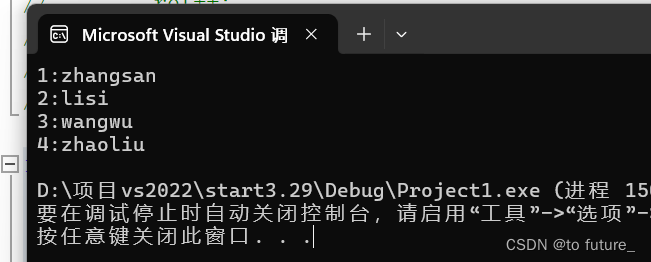
int main()
{
map<int, string>m;
m.insert(make_pair(3, "wangwu"));
m.insert(make_pair(4, "zhaoliu"));
m.insert(make_pair(1, "zhangsan"));
m.insert(make_pair(2,"lisi"));
for (auto x : m)
{
cout << x.first << ":" << x.second << endl;
}
return 0;
}
这里不再对map的接口做讲解,只放上简单的接口以及链接;因为stl的使用都是差不多的;
下面就是map常用的接口
map常用的接口



详细信息查看:map::map - C++ Reference (cplusplus.com)
[]运算符重载
map最需要了解的就是[]运算符重载;

我们可以通过第一个key值来修改第二个value,也可以通过[key]直接插入我们的key到map中;
我们可以将它的操作看成这样

我们通俗的可以翻译成这样;
这是写在map中的重载
V& operator[](const K& key)
{
pair ret=this->insert(make_pair(key, V()));
return ret.first.second;
}其实就是先通过调用insert函数插入key,再通过insert的返回值获得key对应的value的引用,从而可以直接修改我们的value;
操作:
int main()
{
map<int, string>m;
m.insert(make_pair(3, "wangwu"));
m.insert(make_pair(4, "zhaoliu"));
m.insert(make_pair(1, "zhangsan"));
m.insert(make_pair(2,"lisi"));
for (auto x : m)
{
cout << x.first << ":" << x.second << endl;
}
cout << "----------------------------"<<endl;
m[5];//插入操作,我们没有修改任何数据,但是map中没有这个元素5所以会直接插入
for (auto x : m)
{
cout << x.first << ":" << x.second << endl;
}
cout << "----------------------------"<<endl;
m[5] = "chengqi";//修改value操作
for (auto x : m)
{
cout << x.first << ":" << x.second << endl;
}
cout << "----------------------------" << endl;
return 0;
}
上面就是对map和set使用的介绍
接下来我们实现一下我们的map和set;
map与set的实现
(我们这里只是实现了map与set的插入接口和迭代遍历接口)
map与set是两个具有排序作用的高效率容器,并且map与set的底层都是红黑树,由于红黑树在进行平衡树时检查严格程度放松一些使得,红黑树的平均效率更高(不使用AVL树的原因);
并且由于map和set底层都使用的是RBTree,但是map和set分别是KV模型和K模型,它们底层的数据是不同的,所以为了让红黑树的代码可以同时适配map与set,红黑树的实现是有细节的,这也是STL大佬们的厉害之处;
想知道红黑树的实现可以看我前面的博客:
红黑树实现及原理-CSDN博客![]() https://blog.csdn.net/m0_75260318/article/details/137633090?spm=1001.2014.3001.5501
https://blog.csdn.net/m0_75260318/article/details/137633090?spm=1001.2014.3001.5501
改造后的红黑树:
模拟实现stl容器/模拟实现map与set/RBTree.hpp · future/my_road - 码云 - 开源中国 (gitee.com)
话不多说我们首先将我们map与set的实现代码拿出来:
由于使用了红黑树作为底层所以其实map和set自己实现的代码量很少都只是调用RBTree的接口而已;
map
template <class K, class V>
class myMap
{
struct mapKofT
{
const K& operator ()(const pair<const K, V>& t)
{
return t.first;
}
};
public:
typedef pair<const K, V> T;
typedef typename RBTree<const K, T, mapKofT>::iterator iterator;
typedef typename RBTree<const K, T, mapKofT>::const_iterator const_iterator;
pair<iterator, bool>insert(const T& data)
{
return _tree.insert(data);
}
void print()
{
_tree.print();
}
iterator begin()
{
return _tree.begin();
}
iterator end()
{
return _tree.end();
}
const_iterator begin()const
{
return _tree.begin();
}
const_iterator end()const
{
return _tree.end();
}
V& operator [](const K& key)
{
pair<iterator, bool> ret_insert = _tree.insert(make_pair(key, V()));
return ret_insert.first->second;
}
private:
RBTree<const K, T, mapKofT> _tree;
};set
template <class K>
class mySet
{
struct setKofT
{
const K& operator ()(const K& t)
{
return t;
}
};
public:
typedef typename RBTree<K, K, setKofT>::const_iterator iterator;
typedef typename RBTree<K, K, setKofT>::const_iterator const_iterator;
pair<iterator, bool>insert(const K& data)
{
return _tree.insert(data);
}
void print()
{
_tree.print();
}
iterator begin()
{
return _tree.begin();
}
iterator end()
{
return _tree.end();
}
const_iterator begin()const
{
return _tree.begin();
}
const_iterator end()const
{
return _tree.end();
}
private:
RBTree<K, K, setKofT> _tree;
};
讲解
下面我们先来说说map和set它们做了什么,我们可以看到set和map的成员变量都是_tree但tree传的的模板参数确是不同的;
模板参数
map
template <class K, class V> map模板参数
typedef pair<const K, V> T; map中typedef的T
RBTree<const K, T, mapKofT> _tree; map的成员变量set
template <class K> set模板参数
RBTree<K, K, setKofT> _tree; set成员变量可以看到我们set传递给RBTree的是两个K类型,而这个K类型又是set需要存储数据的类型,我们再看map,map也一样它传递给RBTree的是K和pair<K,V>类型,其中的pair<K,V>可以代表map存储的数据类型;为什么要这么传递类型呢?当然是为了使得RBTree可以同时适配map和set两种容器啦
追本溯源我们去看底层的RBTree的实现;
RBTree的底层实现是这样的:
template <class T> 红黑树的节点
struct RBTreeNode
{
typedef RBTreeNode<T> node;
node* _left;
node* _right;
T _data;
node* _parent;
Color _cor;
RBTreeNode<T>(const T& data)
:_left(nullptr)
, _right(nullptr)
, _parent(nullptr)
, _cor(Red)
, _data(data)
{}
};
template<class K, class T, class KofT> 红黑树的接收的模板参数
class RBTree
{
typedef RBTreeNode<T> node; typedef红黑树的节点
};可以看到红黑树底层统一是使用第二个模板参数T来接收map和set的数据的,因为map是KV模型是具有两个类型的,而一个参数无法传递两个类型,如果我们要传递两个参数的话,我们的set又是K模型,只有一个参数类型,所以为了使得RBTree既可以接收map数据类型又可以接收set数据类型,我们使得map传递的T参数是pair类型,这样我们就可以让红黑树可以使用一个模板参数来同时接收map和set的数据了;这样我们的RBTree的节点也可以这样形成了;
现在我们知道了map与set这样传模板参数的原因,这个KofT仿函数吧;
KofT仿函数
mapKofT
struct mapKofT
{
const K& operator ()(const pair<const K, V>& t)
{
return t.first;
}
};setKofT
struct setKofT
{
const K& operator ()(const K& t)
{
return t;
}
};我们可以看到KofT顾名思义就是在类型T中存储的我们的K类型,在我们的map中T是pair<K,V>类型的,K被包含在了T中,所以我们可以通过这个仿函数来获得map存储的第一个数据;而set中,数据类型T其实就是是K,所以KofT对于set来说就是返回T自己这个类型而已;这里我们可以看作是set为map做出的让步;
那map获得这个第一个数据有什么用呢?
我们把目光放到插入数据的接口处,在我们插入数据时,是不是每次都需要比较数据的大小之后才会插入数据;而比较数据set可以直接使用T来比较,但是map不可以,map的T是pair类型,map想用来比较的是第一个数据K所以,我们不能使用T来直接比较;我们得需要使用仿函数KofT来获得这第一个参数来比较,set底层的KofT返回的就是T所以不影响比较;
insert中寻找位置时的代码
node* cur = _root;
node* parent = cur;
KofT koft;
while (cur)
{
if (koft(data) < koft(cur->_data)) 我们这里就是使用koft来进行比较的
{
parent = cur;
cur = cur->_left;
}
else if (koft(data) > koft(cur->_data))
{
parent = cur;
cur = cur->_right;
}
else
{
return make_pair(iterator(cur), false);
}
}这也就是KofT的作用了;
compare仿函数
其实RBTree在stl的底层实现上是有四个模板参数的
template<class K, class T, class KofT, class compare>这个仿函数是用来控制比较的方式的,这样我们的排序顺序就会随着仿函数的变化而改变;一样的我们将compare加在insert接口的比较处就好了;
if(koft(data) < koft(cur->_data))
改变为
compare(koft(data) , koft(cur->_data))这样就可以控制我们的插入方式,使得大的数据插入到树的左枝小的插入到右枝;
iterator迭代器
我们map与set的迭代器是调用了RBTree的接口的;
注意:我们这里调用其他类模板中的内置类型的时候需要加上typename,因为此时我们的编译器是无法识别类型和静态变量的;
map
typedef typename RBTree<const K, T, mapKofT>::iterator iterator;
typedef typename RBTree<const K, T, mapKofT>::const_iterator const_iterator;set
typedef typename RBTree<K, K, setKofT>::const_iterator iterator;
typedef typename RBTree<K, K, setKofT>::const_iterator const_iterator;由于map与set的key值都不允许修改;所以在迭代器传参和使用上有着一些处理;map中因为key值不允许修改,所以传递给迭代器的变量都是const类型的,而set的处理就是const迭代器和普通迭代器都是const迭代器,这样set的数据都是不允许通过迭代器来修改的了;
我们现在来看迭代器的实现;
template<class T, class Ref, class Ptr>//迭代器
struct RBTree_iterator
{
typedef RBTree_iterator<T, Ref, Ptr> self;
typedef RBTree_iterator<T, T&, T*>iterator;//普通迭代器类型
typedef RBTreeNode<T> node;
RBTree_iterator (node* newnode)
:_node(newnode)
{}
//这里的iterator是普通迭代器类型
RBTree_iterator (const iterator& it)//当传过来的是普通迭代器的时候是拷贝构造(支持普通迭代器转换为const迭代器)
: _node(it._node) //穿过来的是const迭代器的时候是编译器自动形成的构造函数来构造的
{}
self &operator ++()
{
if (_node == nullptr)
return *this;
node* subr = _node->_right;
if (subr)//如果右节点不为空
{
while (subr->_left)//找最左节点
{
subr = subr->_left;
}
_node = subr;
}
else//如果右节点为空
{
node* parent = _node->_parent;
while (parent&& _node == parent->_right)//我要是我父亲的左节点才退出
{
_node = _node->_parent;
parent = parent->_parent;
}
_node = parent;//这个父亲就是我们需要的位置
}
return *this;
}
bool operator !=(const self& it)
{
return _node != it._node;
}
Ptr operator ->()
{
return &_node->_data;
}
Ref operator *()
{
return _node->_data;
}
node* _node;
};
template<class K, class T, class KofT>
class RBTree
{
红黑树中定义的迭代器
typedef RBTree_iterator<T, T&, T*> iterator;
typedef RBTree_iterator<T, const T&,const T*> const_iterator;
}我们之前早在list的容器那就实现过const迭代器与非const迭代器的的实现,所以这里迭代器的具体实现我们不做过多解释,如果不理解可以看我们前面的博客:
operator++
我们只解释一下++代码的实现++代码中,我们迭代器所在节点的下一节点要么是我们右边的最左节点,要么就是我们是父亲节点左节点的父亲,这样的++方式即可满足++,看代码实现辅助理解;
接下来我们看红黑树中对迭代器接口的实现:
iterator begin()
{
if (_root == nullptr)
return nullptr;
node* cur = _root;
while (cur->_left)
{
cur = cur->_left;
}
return iterator(cur);
}
iterator end()
{
return iterator(nullptr);
}
const_iterator begin()const
{
if (_root == nullptr)
return nullptr;
node* cur = _root;
while (cur->_left)
{
cur = cur->_left;
}
return iterator(cur);
}
const_iterator end()const
{
return iterator(nullptr);
}可以看到我们的begin()接口获得的就是我们树的最左节点,end()接口获得的就是最右节点的下一个节点(空节点);
在我们实现了这些之后,我们还需要注意的地方就是,我们set中获得的RBTree中的迭代器都是const_iterator,但是可是普通的set的set的成员变量RBTree中的iterator是普通迭代器;所以会发生这样的问题:

我们现在来看iterator是如何操作的:
template<class T, class Ref, class Ptr>//迭代器
struct RBTree_iterator
{
typedef RBTree_iterator<T, Ref, Ptr> self;
typedef RBTree_iterator<T, T&, T*>iterator;//普通迭代器类型
typedef RBTreeNode<T> node;
RBTree_iterator (node* newnode)
:_node(newnode)
{}
//这里的iterator是普通迭代器类型
RBTree_iterator (const iterator& it)//当传过来的是普通迭代器的时候是拷贝构造(支持普通迭代器转换为const迭代器)
: _node(it._node) //穿过来的是const迭代器的时候是编译器自动形成的构造函数来构造的
{}在迭代器中新增了一个支持接收普通迭代器的构造函数,使得我们在迭代器是const迭代器的时候;也可以接收普通迭代器变量作为参数来构造我们的迭代器;
map中的operator[]
V& operator [](const K& key)
{
pair<iterator, bool> ret_insert = _tree.insert(make_pair(key, V()));
return ret_insert.first->second;
}我们红黑树中的insert返回值不再是bool而是一个pair<iterator,bool>类型;这个返回值的作用在前面的使用就已经说过了,所以这里就不过多讲解了;
以上就是大致的map和set的内容;
如果需要查看完整的代码可以到这个链接处查看:
模拟实现stl容器/模拟实现map与set · future/my_road - 码云 - 开源中国 (gitee.com)














 4435
4435











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









