






js逆向之瑞数通杀 ck及后缀获取方案
前言:技术分享,侵权联删
一、目的
使用最简单的方式获取瑞数的cooki和后缀实现并发请求目标网站
二、环境准备
rpa框架(python–>playwright…,nodejs–>puppeteer…)我这里使用的puppeteer。
三、案列分析
使用瑞数的网站很多,这里随便选了一个网站(**重大税收违法失信主体公布栏** 北京税务总局)进行分析,网站如下
aHR0cDovL2JlaWppbmcuY2hpbmF0YXguZ292LmNuL2Jqc2F0L29mZmljZS9qc3AvemRzc3dmYWovd3dxdWVyeS5qc3A=
3.1 了解瑞数反爬原理
动态内容生成是通过脚本在客户端(通常是浏览器)侧生成页面内容,而不是直接在服务器端生成完整的页面。当一个爬虫访问页面时,如果它不支持或执行JavaScript脚本,就无法获取到完整的数据。其实就是cookie反爬,首先请求网站首页获取到一个状态为412的响应,这个响应里包含了html和瑞数服务端返回的一个cookie值,这个html还有一段js代码配合meta标签里content中的密钥加上外链js生成第二段cookie。拿着两个cookie重新请求就可以拿到正确的响应了。其实大多的cookie反爬都是类似的操作。使用我分享的这种方式基本可以通杀cookie反爬。
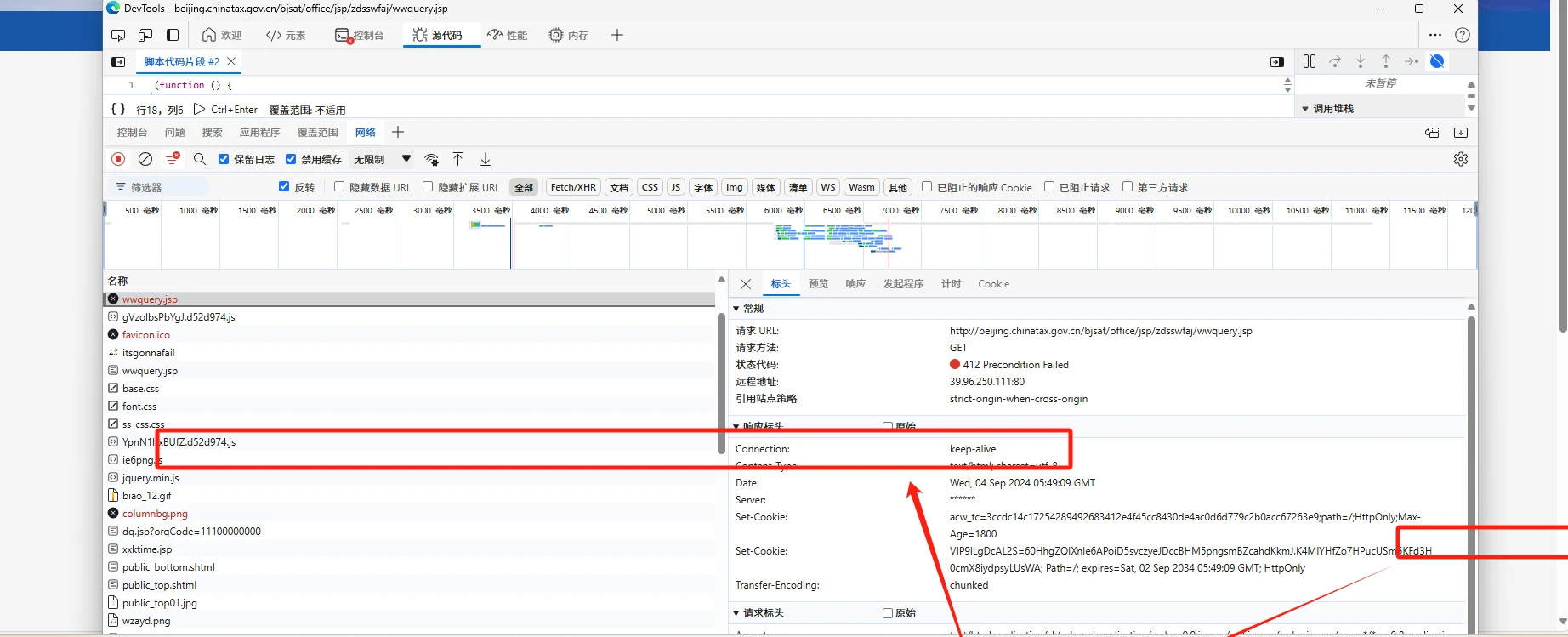
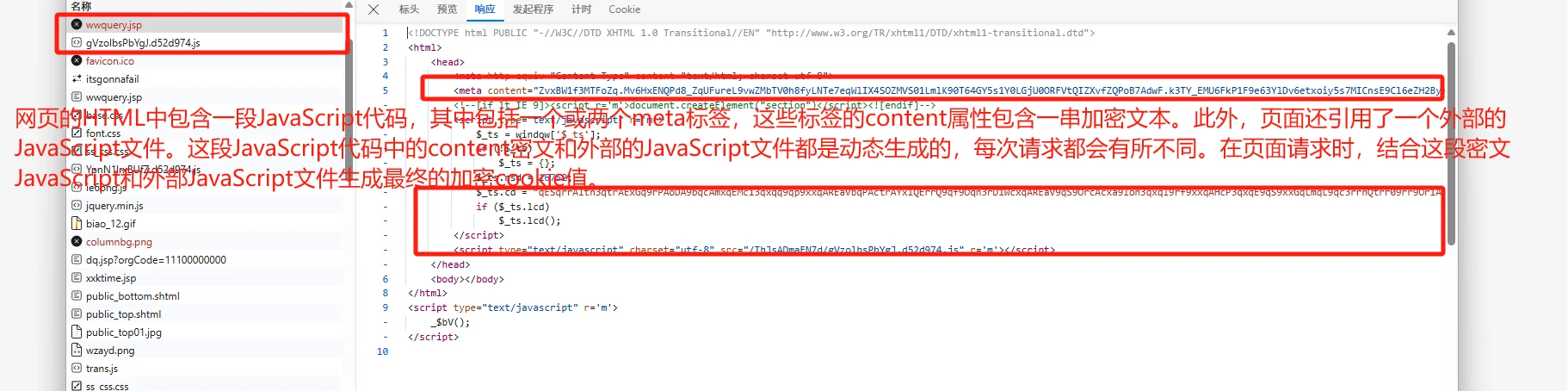
3.2处理方式
知道了瑞数的反爬原理,现在就是思考解决的方法了。按照它的套路,我们只要能拿到服务端返回的第一段cookie1以及后续js生成的cookie2就能解决。目前主流的解决的方法主要分为三种。
第一种 分析js 还原cookie2生成逻辑。这种方式需要对于不了解瑞数的人来说难度很大,现在的瑞数基本都是jsvmp 调试难度大,时间成本高。我们暂时不考虑。
第二种 补环境执行js 获取cookie。这种方式相对纯算简单很多,但是也需要一定的逆向经验 随意补的话容易陷入假值陷阱,深度研究的话不如还原纯算。我们也暂时不考虑这种方式,现在网上很多补环境的思路 感兴趣的朋友可以自己去搜搜看。
第三种 使用rpa框架跑页面 这种方式简单很多,但是比较笨重 在多接口请求时达不到我们的并发要求。我们这里采用的也是rpa,但是不是跑页面,而是基于rpa提供的浏览器环境进行cookie获取。俗称刷cookie


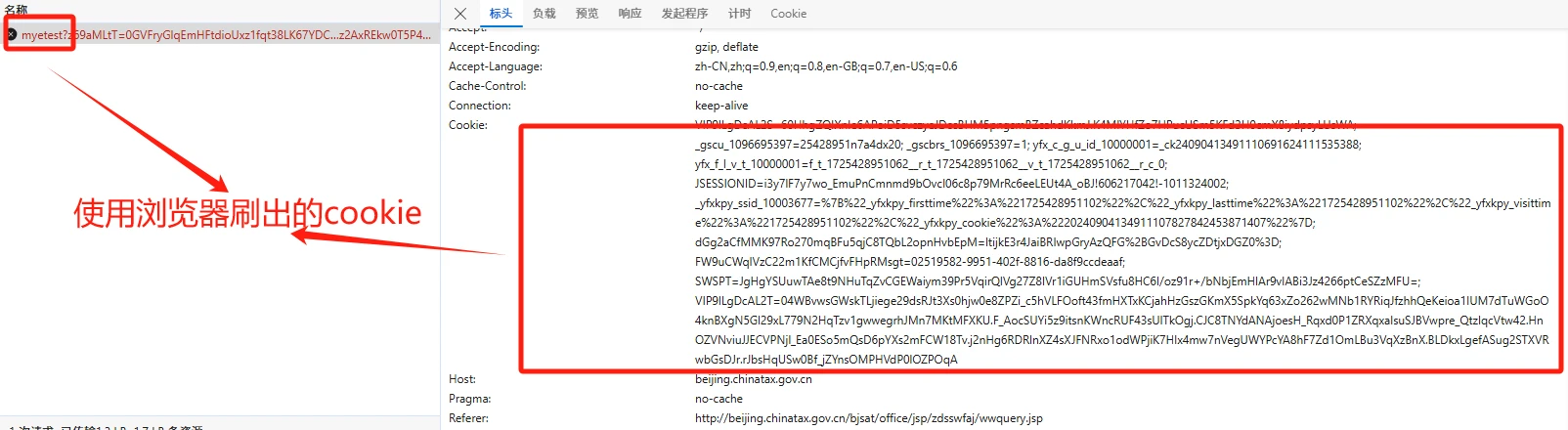
3.3解决思路
上面说了三种方式可以解决,我们这使用的是rpa刷cookie的方式去做的。具体怎么去实现的,需要理解一下cookie反爬的原理 主要是服务端校验客户端js生成的cookie值,只要确保值是正确的 带着去请求就能通过检测。客户端js检测了很多浏览器特征 ,我们使用的是真实的浏览器就不存在缺环境的问题了。只要不是纯算 那都是通过执行目标网站js方法来获取参数,现在环境我们有了,直接执行相关方法就能获取到cookie了。
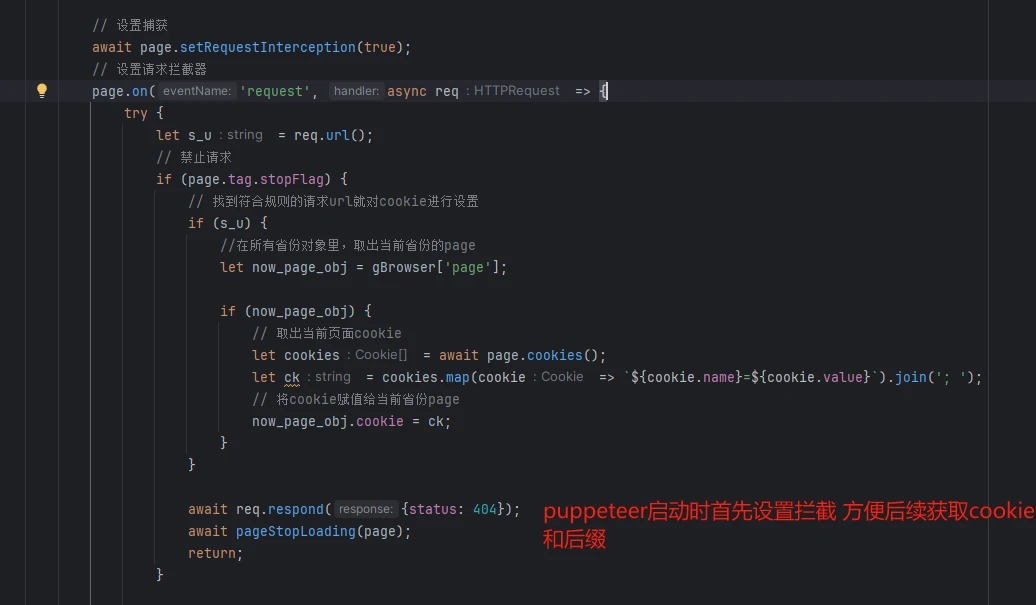
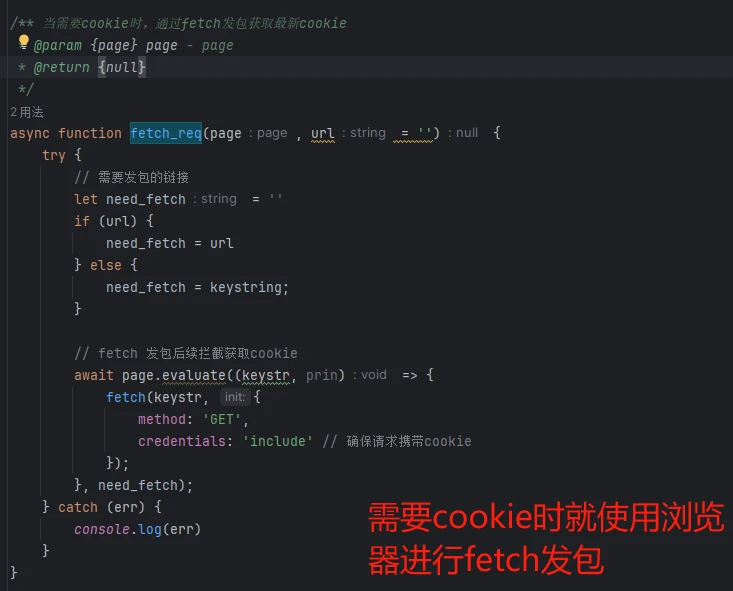
四、结果验证

目前只要是cookie反爬都可以采用这种思路 整个过程都很简单















 1490
1490

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









