






本文档用于记录自学 prometheus 过程,如果有需要可以参考使用,也欢迎各位大佬指正
prometheus 几大组件:
prometheus:数据抓取。用于抓取各exporter,分析数据后判断是否告警
node_exporter:主机层面的监控。用于获取主机状态
blackbox_exporter:服务层面的监控。用于代码没有接入Prometheus监控依赖的黑盒探测
altermanage:告警通知。这里将定义告警转发的路由和告警通知的规则
官网
https://prometheus.io/download/
部署目录结构
/home/prometheus
├── alertmanager-0.28.1.linux-amd64
│ ├── ...
│ ├── alertmanager
│ ├── alertmanager.yml
│ └── amtool
│ └── ...
├── prometheus-3.2.1.linux-amd64/
│ ├── prometheus.yml
│ ├── alertmanager.yml
│ ├── ...
│ └── rules/ # rules 引用配置文件所在地
│ │ ├── alerts.rules.yml
│ │ └── recording.rules.yml
│ └── exporter_config/ # exporter 引用配置文件所在地
│ │ ├── *.yml
│ └── blackbox_config/ # blackjob 引用配置文件所在地
│ ├── *.yml
├1. 部署prometheus
1. 下载压缩包
建议开个加速器 下载本地后 rz 上去,其他的服务器需要再scp 过去
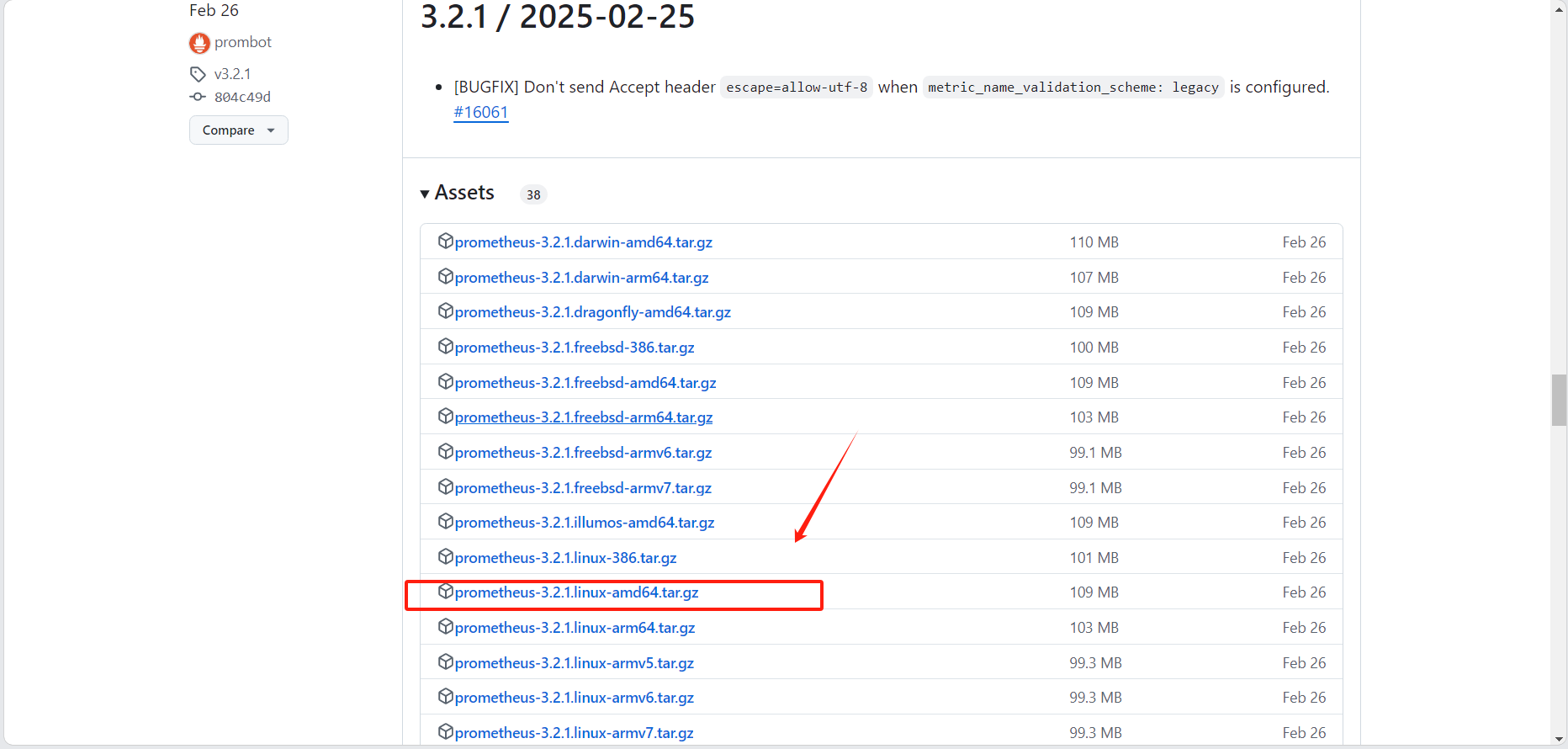
wget https://github.com/prometheus/prometheus/releases/download/v3.2.1/prometheus-3.2.1.linux-amd64.tar.gz在这里我们可以找到历史版本

2. 创建用户
给 prometheus 创建一个系统用户,并且不允许登录
useradd -r -m -s /bin/nologin prometheus
3. 解压和部署
给压缩包赋权后切换到 prometheus 用户操作
# 赋权后切换用户
chown prometheus:prometheus prometheus-3.3.1.linux-amd64.tar.gz
sudo -u prometheus bash
# 解压
tar xf prometheus-3.3.1.linux-amd64.tar.gz -C ~/
# 创建数据存储目录并赋权
mkdir -p /var/lib/prometheus
chown -R prometheus:prometheus /var/lib/prometheus4. 编写system 管理文件
Prometheus 的配置文件(prometheus.yml)不能直接指定数据存储目录,因为数据目录是通过 命令行参数 配置的,而不是在配置文件中定义的。这是 Prometheus 的设计选择,目的是将 运行时配置(如数据目录、监听地址等)与 监控配置(如抓取目标、告警规则等)分离。
所以我们通过systemd 管理的方式指定数据目录
# /etc/systemd/system/prometheus.service
[Unit]
Description=Prometheus
After=network.target
[Service]
User=prometheus
Group=prometheus
ExecStart=/home/prometheus/prometheus-3.2.1.linux-amd64/prometheus \
--config.file=/home/prometheus/prometheus-3.2.1.linux-amd64/prometheus.yml \
--storage.tsdb.path=/var/lib/prometheus \
--web.listen-address=:9090
Restart=always
[Install]
WantedBy=multi-user.target
5. prometheus.yml
global:
scrape_interval: 15s
evaluation_interval: 15s
alerting:
alertmanagers:
- static_configs:
- targets:
- "127.0.0.1:9093" # alertmanager 默认端口
rule_files:
- "./rules/*.yml" # 这个目录需要自己创建
# —— 只有 ONE 个 scrape_configs ——
scrape_configs:
# 1. 抓 Prometheus 自己
- job_name: "prometheus"
static_configs:
- targets: ["localhost:9090"]
# 2. 抓 node_exporter(示例)
- job_name: "devops-01"
file_sd_configs:
- files:
- ./exporter_config/node_127.yml
refresh_interval: 5s
# 3. 抓 mysql_exporter(示例)
- job_name: "mysql5.3"
file_sd_configs:
- files:
- ./exporter_config/mysql5.3.yml
refresh_interval: 5s
# 4. 黑盒探测 Job
- job_name: "blackbox"
metrics_path: /probe
params:
module: [http_2xx]
file_sd_configs:
- files:
- /home/prometheus/prometheus-3.2.1.linux-amd64/blackbox_config/*.yml
refresh_interval: 5s
relabel_configs:
- source_labels: [__address__]
target_label: __param_target
- source_labels: [__param_target]
target_label: instance
- target_label: __address__
replacement: 127.0.0.1:9115 # Blackbox Exporter 地址
6. 启动运行
主配置文件已经修改完成,接下来我们启动即可
# 重载配置文件
systemctl daemon-reload
# 启动
systemctl start prometheus
# 查看状态
systemctl status prometheus
# 也可以提前创建 prometheus.yml 引用的配置文件目录 避免启动报错
# 在 prometheus.yml 文件同级目录创建
mkdir -p {blackbox_config,exporter_config,rules}2. 部署node_exporter
1. 下载压缩包
wget https://github.com/prometheus/node_exporter/releases/download/v1.9.0/node_exporter-1.9.0.linux-amd64.tar.gz2. 创建用户
# 创建用户
useradd -r -m -s /bin/nologin node_exporter3. 解压和部署
# 赋权
chown node_exporter:node_exporter node_exporter-1.9.0.linux-amd64.tar.gz
# 切换用户
sudo -u node_exporter bash
# 解压
tar xf /mnt/package/node_exporter-1.9.0.linux-amd64.tar.gz -C /opt/custom_install3. 编写system 管理文件
# /etc/systemd/system/node.service
[Unit]
Description=Node Exporter
After=network.target
[Service]
User=node_exporter
Group=node_exporter
ExecStart=/opt/custom_install/node_exporter-1.9.0.linux-amd64/node_exporter
StandardOutput=append:/var/lib/node_exporter/node_exporter.log
StandardError=inherit
Restart=always
[Install]
WantedBy=multi-user.target
创建数据目录
# 创建
mkdir -p /var/lib/node_exporter/
# 赋权
chown -R node_exporter:node_exporter /var/lib/node_exporter/4. 启动运行
# 重载配置文件
systemctl daemon-reload
# 启动
systemctl start node
# 查看状态
systemctl status node
# 默认会开放 9100 端口
netstat -lnpt | grep 91005. 配置prometheus 抓取node
# 切换用户
sudo -u prometheus bash
# 创建配置文件
cat >> ~/prometheus-3.2.1.linux-amd64/exporter_config/node_127.yml << EOF
- targets:
- 127.0.0.1:9100 # 你实际运行 node_exporter 的地址
labels:
job: "devops_01_node"
EOF# 热重载生效
curl -X POST http://127.0.0.1:9090/-/reload3. 部署mysql_exporter
1. 下载压缩包
wget https://github.com/prometheus/mysqld_exporter/releases/download/v0.14.0/mysqld_exporter-0.14.0.linux-amd64.tar.gz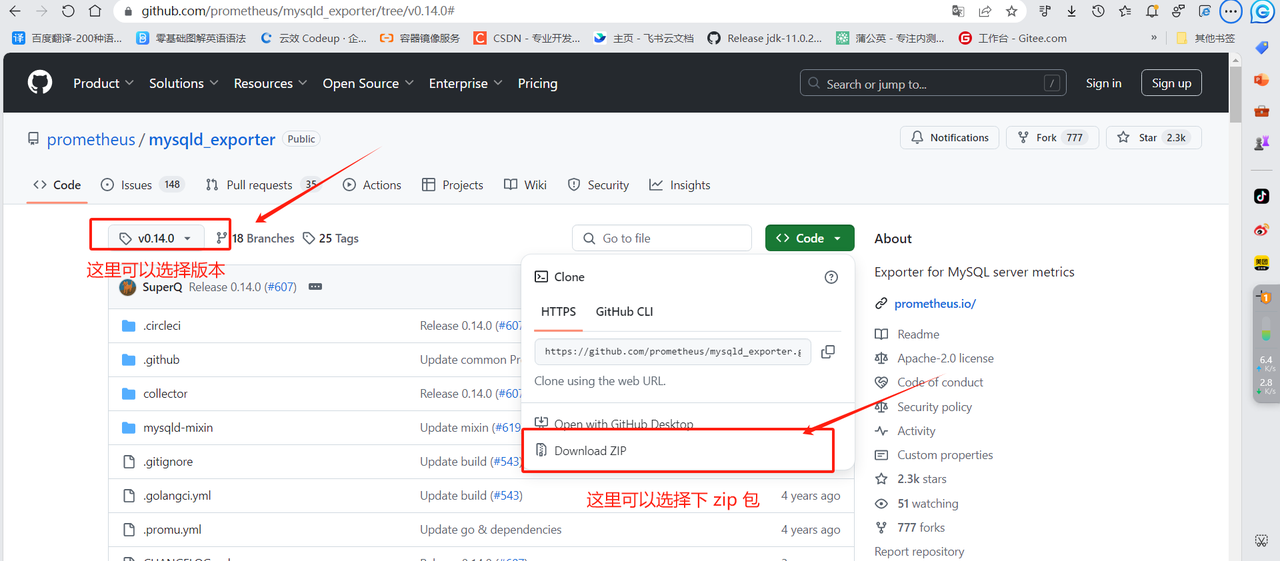
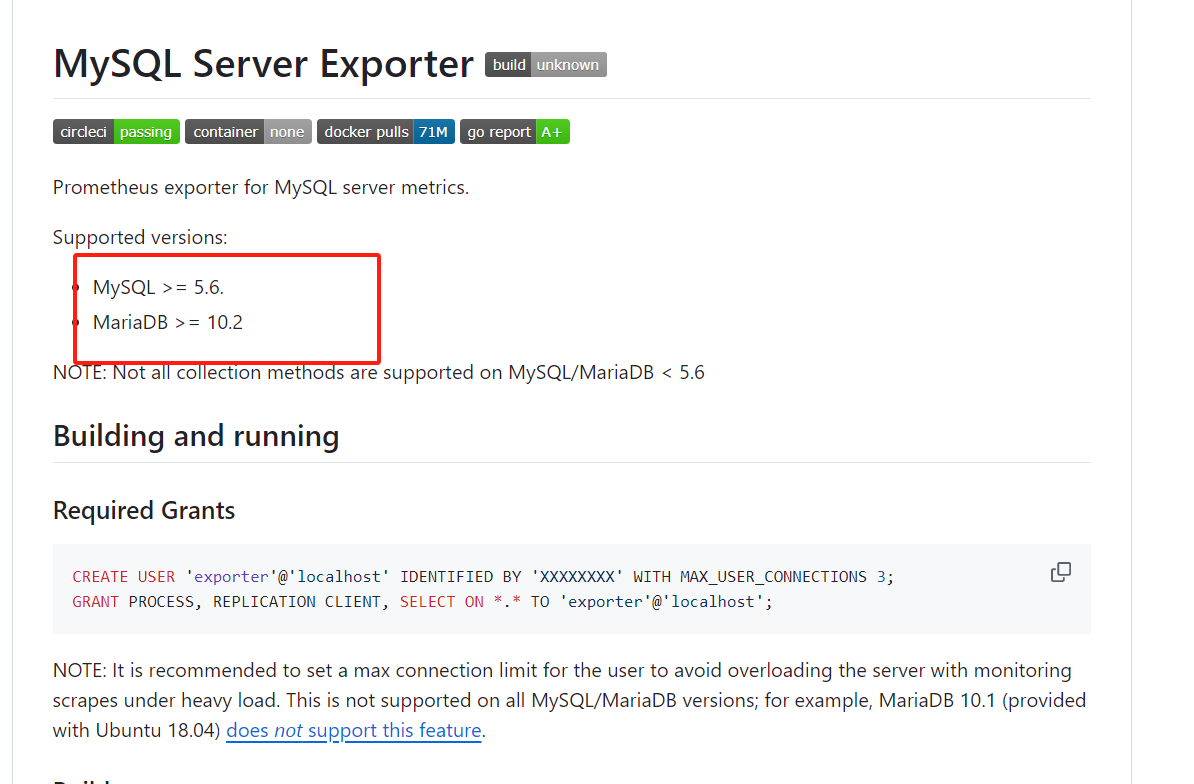
往下滑可以看到 适配的数据库版本 和部署文档
2. 创建系统用户
# 创建用户
sudo useradd -r -m -s /bin/false mysqld_exporter3. 解压和安装
# 授权
chown -R mysqld_exporter:mysqld_exporter mysqld_exporter-0.14.0/
# 切换用户
sudo -u mysqld_exporter bash
# 解压
tar xf /mnt/package/mysqld_exporter-0.14.0.linux-amd64.tar.gz -C /opt/custom_install4. 创建数据库用户
# 连接mysql 数据库
mysql -u root -p
# 创建数据库用户
CREATE USER 'exporter'@'%' IDENTIFIED BY '123123' WITH MAX_USER_CONNECTIONS 3;
GRANT PROCESS, REPLICATION CLIENT, SELECT ON *.* TO 'exporter'@'%';5. 创建配置文件
# 创建mysqld_exporter 连接数据库的配置文件
cat >> ~/.my.cnf << EOF
[client]
user=exporter
password=123123
host=127.0.0.1
port=3306
EOF
6. 启动运行
# 前台运行,测试没问题在后台运行
./mysqld_exporter --config.my-cnf=/home/mysqld_exporter/.my.cnf --collect.auto_increment.columns
# 后台运行
nohup ./mysqld_exporter --config.my-cnf=/home/mysqld_exporter/.my.cnf --collect.auto_increment.columns &
# 启动后会开放 9104端口
netstat -lnpt | grep 91047. 配置prometheus 抓取mysql_exporter
# 切换用户
sudo -u prometheus bash
# 创建配置文件
cat >> ~/prometheus-3.2.1.linux-amd64/exporter_config/mysql5.3.yml << EOF
- targets:
- 127.0.0.1:9104 # 你实际运行 mysql_exporter 的地址
labels:
job: mysql5.3
EOF4. 部署black_exporter
1. docker部署
由于博主没有代码基础无法在若依打包的时候把prometheus 依赖打包进去所以选择blackbox方式
部署方式没有什么区别为了省时间直接上docker
# 如果拉不下来检查镜像加速,或者直接”科技“
docker run -d --name=blackbox-exporter -p 9115:9115 prom/blackbox-exporter
# 查看容器是否 running
docker ps
# running后检查 9115端口
netstat -lnpt | grep 91152. 配置prometheus 抓取blackbox
# 切换用户
sudo -u prometheus /bash
# 创建抓取配置文件
cat >> ~/prometheus-3.2.1.linux-amd64/blackbox_config/ruoyi_127_8081.yml << EOF
- targets:
- 192.168.5.30:8081 # 值得注意的是,因为blackbox 是docker 运行的,直接写 127是black 容器自己的地址,而不是服务器的
labels:
job: "127"
env: test
team: java-services
hostname: "127.0.0.1"
EOF
cat >> ~/prometheus-3.2.1.linux-amd64/blackbox_config/ruoyi_47_8081.yml << EOF
- targets:
- 47.115.147.206:8081
labels:
job: "47"
env: prod
team: java-services
hostname: "47.115.147.206"
EOF# 热重载生效
curl -X POST http://127.0.0.1:9090/-/reload到此为止已经实现了监控的部分
但是博主观察 prometheus 的ui 界面发现 blackbox 获取的目标即使 down了ui 还是显示up
具体的抓取流程 【prometheus】>【blackbox组件】> 【监控目标】
在【prometheus】的web 界面 如果正常从【blackbox组件】拉取返回数据,他就会显示 up,不会管【blackbox组件】> 【监控目标】这一条链路是否正常,所以会造成一个状况
根本原因:Prometheus 的 “UP” 是抓取 exporter 的状态,不是业务的探测结果
服务是down 的但是 prom web界面是 up 的,我们手动测试也证实了抓取指标是失败的。
curl http://47.115.147.206:8081
curl 'http://127.0.0.1:9115/probe?module=http_2xx&target=47.115.147.206:8081'
...
probe_http_status_code=0
...
probe_http_content_length=0
...
probe_success=0
从GPT那里了解到 目前黑盒没办法探测失败自动显示DOWN 因为从【blackbox组件】是正常拉取的,只是指标是0(失败)prom没办法区分这些数值 只能通过只能写Alert规则或者Grafana处理
5. 部署alertmanager
告警产生流程
┌──────────────┐ ┌────────────────────┐ ┌──────────────────┐
│ Blackbox │ │ │ │ │
│ Exporter ├────────►│ Prometheus ├────────►│ Alertmanager │
│ (探测目标) │ Metrics │ (rules规则判断) │ Alerts │ (报警通知) │
└──────────────┘ └────────────────────┘ └──────────────────┘
│
▼
邮件、钉钉、Webhook、本地脚本等1. 下载压缩包
wget https://github.com/prometheus/alertmanager/releases/download/v0.28.1/alertmanager-0.28.1.linux-amd64.tar.gz2. 解压和安装
# 授权
chown prometheus:prometheus alertmanager-0.28.1.linux-amd64.tar.gz
# 切换用户
sudo -u prometheus bash
# 解压
tar xf /mnt/package/alertmanager-0.28.1.linux-amd64.tar.gz -C ~3. alertmanager.yml
配置文件结构
alertmanager.yml
├── global: # 全局配置(如SMTP服务器、认证等)
├── route: # 通用路由规则(重要!决定 alert 发给谁)
│ ├── receiver: "默认接收者" # 默认的 receiver 名字
│ ├── matchers: {} # 匹配条件(例如 alertname="HighCPU")
│ ├── routes: # 子路由:针对不同类型的告警分发给不同的人
│ │ ├── match:
│ │ │ alertname: "BlackboxDown" # 告警名字匹配 关联
│ │ ├── receiver: "ops-email" # 匹配上了就发给这个 receiver
│ │ ├── group_by: ['instance']
│ │ └── ...
│ └── ...
├── receivers: # 所有可选的接收人定义
│ ├── - name: "ops-email"
│ │ email_configs:
│ │ - to: "ops@example.com"
│ ├── - name: "devs-dingtalk"
│ │ webhook_configs:
│ │ - url: "http://localhost:5001"
│ └── ...
└── inhibit_rules: # 抑制规则(可选)
检查语法
amtool check-config alertmanager.yml完整的配置文件
# ========== 邮件配置 =============
global:
smtp_smarthost: 'smtp.qq.com:587'
smtp_from: '*********@qq.com'
smtp_auth_username: '*********@qq.com' # 需要和 smtp_from 一致
smtp_auth_password: '*********'
smtp_require_tls: true
# ========== 全局路由配置 ==========
route:
# 告警分组依据:按告警名称(alertname)进行分组,相同名称的告警会被合并为一条通知
group_by: ['alertname']
# 新告警组的等待时间:当新告警组首次触发时,等待 30 秒以聚合可能同时触发的其他告警
group_wait: 10s
# 告警组更新间隔:如果同一组告警持续活跃,每 5 分钟发送一次更新通知
group_interval: 10s
# 一小时以内没恢复再发一封
repeat_interval: 10s
# 默认接收器:所有未匹配其他路由规则的告警将发送到此接收器
receiver: 'default'
# my_config
routes:
- match:
alertname: TestEmailAlert
receiver: 'TestEmailAlert'
- match:
# 这里的 job 由rules 配置文件定义
job: "127"
alertname: blackbox_127
receiver: 'route_123'
- match:
job: "47"
alertname: blackbox_47
receiver: 'route_xxx'
# ========== 接收器配置 ==========
receivers:
- name: 'web.hook'
webhook_configs:
- url: 'http://127.0.0.1:5001/' # Webhook 接收地址(例如对接内部系统或钉钉/企业微信机器人)
- name: 'default'
email_configs:
- to: "xxxxx@qq.com"
send_resolved: true #告警恢复后也发一个恢复邮件
headers:
Subject: '{{ template "email.subject" . }}' # 引用告警模板
html: '{{ template "email.body" . }}'
- name: 'route_123'
email_configs:
- to: "*********@qq.com"
send_resolved: true
headers:
Subject: '{{ template "email.subject" . }}'
html: '{{ template "email.body" . }}'
- name: 'TestEmailAlert'
email_configs:
- to: "*********@qq.com"
send_resolved: true
headers:
Subject: '{{ template "email.subject" . }}'
html: '{{ template "email.body" . }}'
# ========== 抑制规则配置 ==========
inhibit_rules:
# 规则 1:当存在严重性为 critical 的告警时,抑制(静默)相同标签的 warning 告警
- source_match:
# 源告警匹配条件:严重性为 critical 的告警
severity: 'critical'
target_match:
# 目标告警匹配条件:严重性为 warning 的告警
severity: 'warning'
# 需要匹配的标签:只有当这些标签的值相同时,抑制规则才会生效
equal: ['alertname', 'dev', 'instance'] # 例如:同一服务(instance)、同一环境(dev)的相同告警(alertname)
在alertmanager 同级目录创建 email.tmpl
cat >> email.tmpl << EOF
{{ define "email.subject" }}[{{ .Status | toUpper }}] 告警: {{ .CommonLabels.alertname }}{{ end }}
{{ define "email.body" }}
<html>
<body>
<h2>[{{ .Status | toUpper }}] 告警: {{ .CommonLabels.alertname }}</h2>
<p><strong>告警等级:</strong> {{ .CommonLabels.severity }}</p>
<p><strong>实例:</strong> {{ .CommonLabels.instance }}</p>
<p><strong>开始时间:</strong> {{ (index .Alerts 0).StartsAt }}</p>
<p><strong>结束时间:</strong> {{ (index .Alerts 0).EndsAt }}</p>
<h3>摘要信息:</h3>
<ul>
{{ range .Alerts }}
<li>{{ .Annotations.summary }}<br/>描述: {{ .Annotations.description }}</li>
{{ end }}
</ul>
<hr/>
<p>详情请查看 <a href="http://你的prometheus地址">Prometheus Web</a></p>
</body>
</html>
{{ end }}
EOF4. 编写system 管理文件
# /etc/systemd/system/alertmanager.service
[Unit]
# 服务说明,内容自定义
Description=My Alertmanager Service
# 用于设置依赖启动项, network.target 表示该服务在网络服务启动后启动。
After=network.target
[Service]
User=prometheus
Group=prometheus
ExecStart=/home/prometheus/alertmanager-0.28.1.linux-amd64/alertmanager --config.file=/home/prometheus/alertmanager-0.28.1.linux-amd64/alertmanager.yml
# 如果官网没有提供停止命令;可以直接写kill
# $MAINPID 是系统提供用于存储由本 .service 文件启动的PID
# -SIGTERM 是告诉alertmanager 优雅的停止,如果感觉半天杀不掉可以取消这个参数
ExecStop=/bin/kill -SIGTERM $MAINPID
# 指定服务失败时的行为。on-failure 表示服务失败时自动重启。下面是间隔时间
Restart=on-failure
RestartSec=5s
[Install]
# 指定启动级别
WantedBy=multi-user.target
5. 启动运行
# 重载配置文件
systemctl daemon-reload
# 启动
systemctl start alertmanager
# 查看状态
systemctl status alertmanager
# 默认会开放 9093 端口
netstat -lnpt | grep 90936. 修改Prometheus 配置文件,配置 alertmanager
其实前面的 prometheus.yml 已经添加了这里提一下让不熟悉的朋友了解一下
alerting:
alertmanagers:
- static_configs:
- targets:
- "127.0.0.1:9093" # 这是 alertmanager 默认端口 然后在 rule_files 中加上你的报警规则文件,比如:
rule_files:
- "./rules/*.yml" # 这个 rules 目录需要自己创建7. alert.rules.yml
重头戏来了牢底们,配置 alert.rules.yml 怎么根据 blackbox 探测结果触发告警,这将解决我们一直讨论的,blackbox 探测结果probe_success=0,但是web界面却显示 up用户无法察觉的问题
# 切换用户
sudo -u prometheus bash
# 切换到 prometheus.yml 同级别目录下创建 rules 目录
cd ~/prometheus-3.2.1.linux-amd64/
# 创建目录
mkdir rules
# 创建文件
touch alert.rules.ymlgroups:
- name: blackbox
rules:
- alert: blackbox_127
# 纯数字是不可以用 ==,字符串才可以
#expr: probe_success == 0 and job == "127"
expr: probe_success{job="127"} == 0
for: 1s
labels:
severity: Critical
job: "127"
team: ops
way: email
#hostname: "127.0.0.1" # 区分主机
annotations:
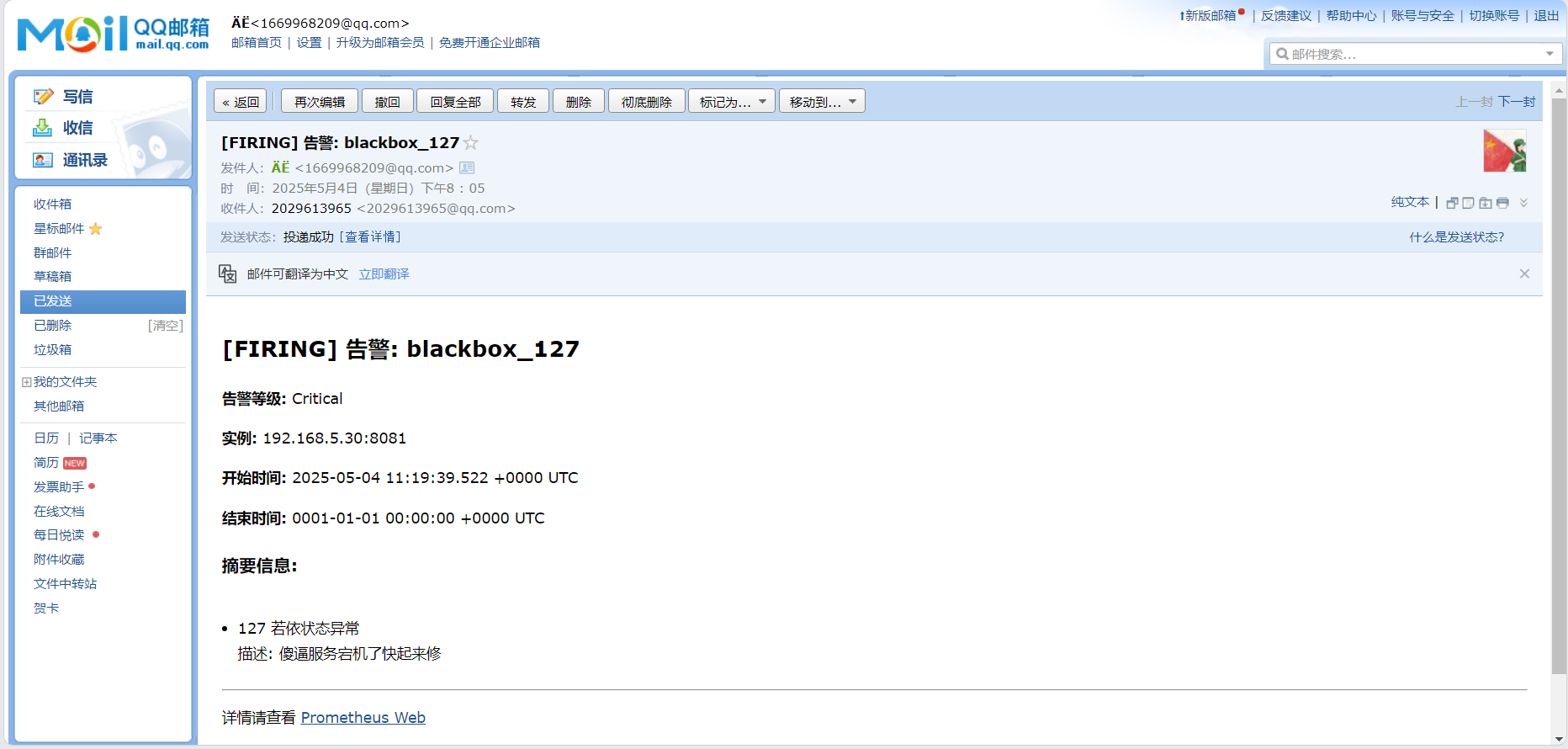
summary: "127 若依状态异常"
description: "马楼服务宕机了快起来修"
- alert: blackbox_47
expr: probe_success{job="47"} == 0
for: 1s
labels:
severity: Critical
job: "47"
team: ops
way: email
#hostname: "47.115.147.206" # 区分另一台主机
annotations:
summary: "47 若依状态异常"
description: "马楼服务宕机了快起来修"
最后讲一下 它是怎么判断的,有助于理解
prometheus 会通过各种exporter 获取监控数据但是他本身不会去区分这些数据是否有问题,拿到数据后跟 rules里的规则进行判断,如果匹配了某一个alert规则就确认是产生告警,就把这个规则里定义的一些数据转发给 alertmanager,altermanger会根据收到的 alertname 和里面的字段匹配alertmanager.yml 里route 段里routes 的路由,匹配路由后会根据receivers:里的路由配置转发到具体的目标,发送的内容 templates字段定义
告警成功
后面再补充 grafana 吧,目前正在学习解决告警结束了但是不发恢复邮件的问题

















 6万+
6万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









