







目录
7.1.1 Linux信号
Linux利用信号与运行在系统中的进程进行通信。可以通过对脚本进行编程,使其在收到特定信号时执行某些命令,从而控制shell脚本的操作。Linux系统和应用程序可以生成超过30个信号。下表列出了在Linux编程时会遇到的最常见的Linux系统信号。
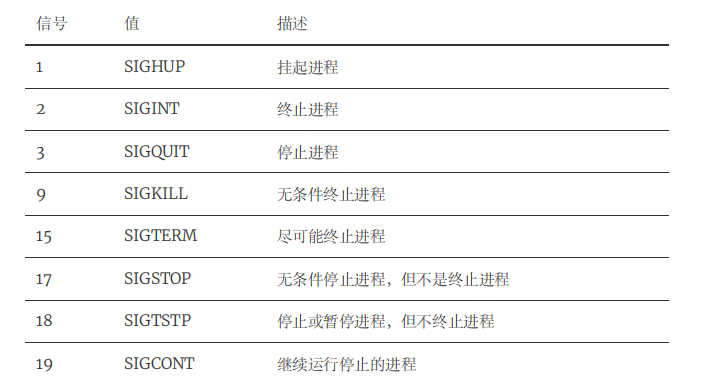
默认情况下, bash shell会忽略收到的任何SIGQUIT (3)和SIGTERM (5)信号(正因为这样,交互式shell才不会被意外终止)。但是bash shell会处理收到的SIGHUP (1)和SIGINT (2)信号。如果bash shell收到了SIGHUP信号,比如当你要离开一个交互式shell,它就会退出。但在退出之前,它会将SIGHUP信号传给所有由该shell所启动的进程(包括正在运行的shell脚本)。通过SIGINT信号,可以中断shell。 Linux内核会停止为shell分配CPU处理时间。这种情况发生时, shell会将SIGINT信号传给所有由它所启动的进程,以此告知出现的状况。你可能也注意到了, shell会将这些信号传给shell脚本程序来处理。而shell脚本的默认行为是忽略这些信号。它们可能会不利于脚本的运行。要避免这种情况,你可以脚本中加入识别信号的代码,并执行命令来处理信号。
7.1.2生成信号
bash shell允许用键盘上的组合键生成两种基本的Linux信号。这个特性在需要停止或暂停失控程序时非常方便。1、中断进程Ctrl+C组合键会生成SIGINT信号,并将其发送给当前在shell中运行的所有进程。可以运行一条需要很长时间才能完成的命令,然后按下Ctrl+C组合键来测试它。
[root@kittod ~] #sleep 100
^C2、暂停进程你可以在进程运行期间暂停进程,而无需终止它。尽管有时这可能会比较危险,(比如,脚本打开了一个关键的系统文件的文件锁),但通常它可以在不终止进程的情况下使你能够深入脚本内部一窥究竟。
Ctrl+Z组合键会生成一个SIGTSTP信号,停止shell中运行的任何进程。停止 ( stopping)进程跟终止 ( terminating)进程不同:停止进程会让程序继续保留在内存中,并能从上次停止的位置继续运行。在后面的内容,你会了解如何重启一个已经停止的进程。
当用Ctrl+Z组合键时, shell会通知你进程已经被停止了。
[root@kittod ~]# sleep 100
^Z
[1]+stopped sleep 100方括号中的数字是shell分配的作业号( job number)。shell将shell中运行的每个进程称为作业,并为每个作业分配唯一的作业号。它会给第一个作业分配作业号1,第二个作业号2,以此类推。如果你的shell会话中有一个已停止的作业,在退出shell时, bash会提醒你。
[ root@kittod ~]# sleep 100^Z
[ 1]+stopped sleep 100
[ root@kittod ~] # exit
logout
There are stopped jobs.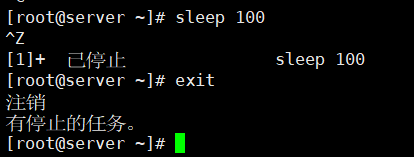
可以用ps命令来查看已停止的作业。
[root@kittod ~]# ps -l
F S UID PID PPID C PRI NI ADDR SZ WCHAN TTY TIME
CMD
0 S 0 1703 1702 0 80 0 - 6798 - pts/0 00:00:00
bash
0 T 0 2368 1703 0 80 0 - 1821 - pts/0 00:00:00
sleep
0 R 0 2369 1703 0 80 0 - 11361 - pts/0 00:00:00
ps
在S列中(进程状态), ps命令将已停止作业的状态为显示为T。这说明命令要么被跟踪,要么被停止了。如果在有已停止作业存在的情况下,你仍旧想退出shell,只要再输入一遍exit命令就行了。shell会退出,终止已停止作业。或者,既然你已经知道了已停止作业的PID,就可以用kill命令来发送一个SIGKILL信号来终止它。
[root@kittod ~]# ps -l
F S UID PID PPID C PRI NI ADDR SZ WCHAN TTY TIME
CMD
0 S 0 1703 1702 0 80 0 - 6798 - pts/0 00:00:00
bash
0 T 0 2368 1703 0 80 0 - 1821 - pts/0 00:00:00
sleep
0 R 0 2370 1703 0 80 0 - 11361 - pts/0 00:00:00
ps
[root@kittod ~]# kill -9 2368
[root@kittod ~]# ps -l
F S UID PID PPID C PRI NI ADDR SZ WCHAN TTY TIME
CMD
0 S 0 1703 1702 0 80 0 - 6798 - pts/0 00:00:00
bash
0 R 0 2375 1703 0 80 0 - 11361 - pts/0 00:00:00
ps
[1]+ Killed sleep 100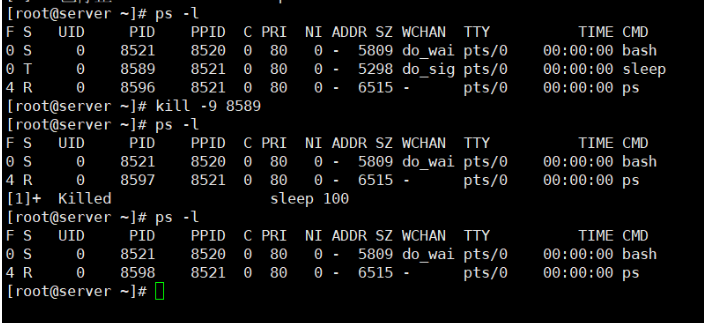
在终止作业时,最开始你不会得到任何回应。但下次如果你做了能够产生shell提示符的操作(比如按回车键),你就会看到一条消息,显示作业已经被终止了。每当shell产生一个提示符时,它就会显示shell中状态发生改变的作业的状态。在你终止一个作业后,下次强制shell生成一个提示符时, shell会显示一条消息,说明作业在运行时被终止了。
7.1.3捕获信号
也可以不忽略信号,在信号出现时捕获它们并执行其他命令。 trap命令允许你来指定shell脚本要监看并从shell中拦截的Linux信号。如果脚本收到了trap命令中列出的信号,该信号不再由shell处理,而是交由本地处理。
trap命令的格式是:
trap commands signals 1
在trap命令行上,你只要列出想要shell执行的命令,以及一组用空格分开的待捕获的信号。你可以用数值或Linux信号名来指定信号。
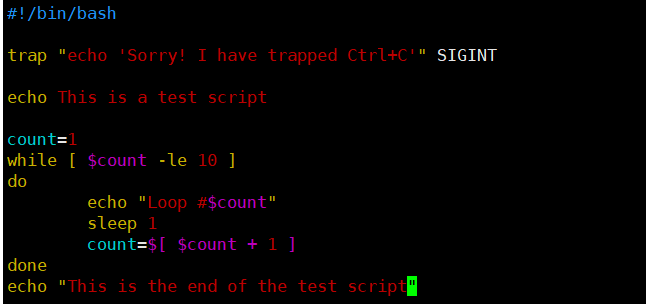
这里有个简单例子,展示了如何使用trap命令来忽略SIGINT信号,并控制脚本的行为。
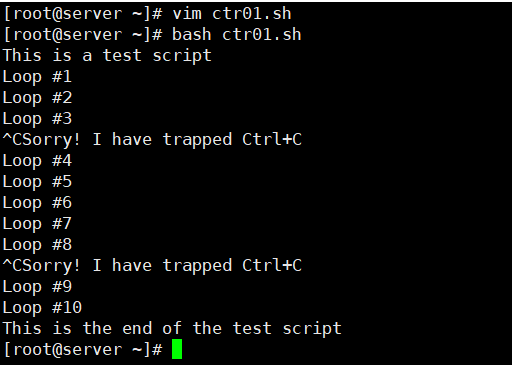
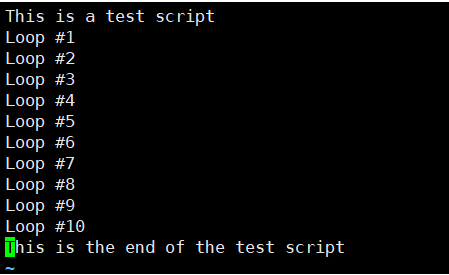
[root@kittod ~]# cat ctr01.sh
#!/bin/bash
trap "echo ' Sorry! I have trapped Ctrl+C'" SIGINT #SIGINT表示捕获ctrl+C
echo This is a test script
count=1
while [ $count -le 10 ]
do
echo "Loop #$count"
sleep 1
count=$[ $count + 1 ]
done
echo "This is the end of the test script"
本例中用到的trap命令会在每次检测到SIGINT信号时显示一行简单的文本消息。捕获这些
信号会阻止用户用bash shell组合键Ctrl+C来停止程序。
[root@kittod ~]# bash ctr01.sh
This is a test script
Loop #1
Loop #2
Loop #3
^C Sorry! I have trapped Ctrl+C
Loop #4
Loop #5
^C Sorry! I have trapped Ctrl+C
Loop #6
^C Sorry! I have trapped Ctrl+C
Loop #7
^C Sorry! I have trapped Ctrl+C
Loop #8
Loop #9
Loop #10
This is the end of the test script每次使用Ctrl+C组合键,脚本都会执行trap命令中指定的echo语句,而不是处理该信号并允许shell停止该脚本。
7.1.4捕获脚本退出
除了在shell脚本中捕获信号,你也可以在shell脚本退出时进行捕获。这是在shell完成任务时执行命令的一种简便方法。
要捕获shell脚本的退出,只要在trap命令后加上EXIT信号就行。
[root@kittod ~]# cat ctr02.sh
#!/bin/bash
trap "echo Googbye..." EXIT
count=1
while [ $count -le 5 ]
do
echo "loop #$count"
sleep 1
count=$[ $count + 1 ]
done
[root@kittod ~]# bash ctr02.sh
loop #1
loop #2
loop #3
loop #4
loop #5
Googbye...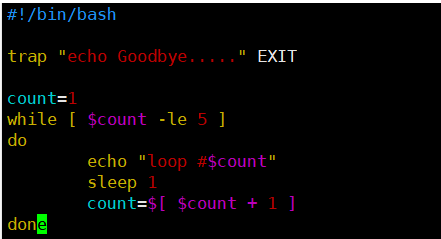
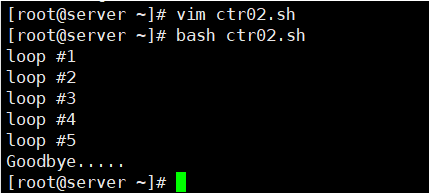
当脚本运行到正常的退出位置时,捕获就被触发了, shell会执行在trap命令行指定的命令。如果提前退出脚本,同样能够捕获到EXIT。
7.1.5修改或移除捕获
要想在脚本中的不同位置进行不同的捕获处理,只需重新使用带有新选项的trap命令。
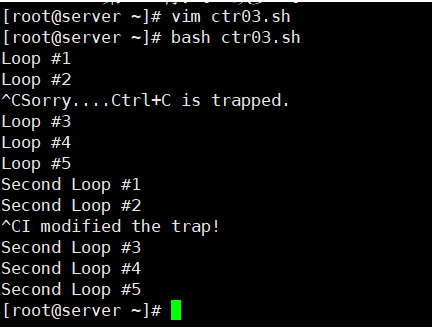
[root@kittod ~]# cat ctr03.sh
#!/bin/bash
trap "echo ' Sorry... Ctrl+C is trapped.'" SIGINT
count=1
while [ $count -le 5 ]
do
echo "Loop #$count"
sleep 1
count=$[ $count + 1 ]
done
trap "echo ' I modified the trap!'" SIGINT
count=1
while [ $count -le 5 ]
do
echo "Second Loop #$count"
sleep 1
count=$[ $count + 1 ]
done
修改了信号捕获之后,脚本处理信号的方式就会发生变化。但如果一个信号是在捕获被修改前接
收到的,那么脚本仍然会根据最初的trap命令进行处理。
[root@kittod ~]# bash ctr03.sh
Loop #1
Loop #2
^C Sorry... Ctrl+C is trapped.
Loop #3
^C Sorry... Ctrl+C is trapped.
Loop #4
Loop #5
Second Loop #1
Second Loop #2
^C I modified the trap!
Second Loop #3
^C I modified the trap!
Second Loop #4
Second Loop #5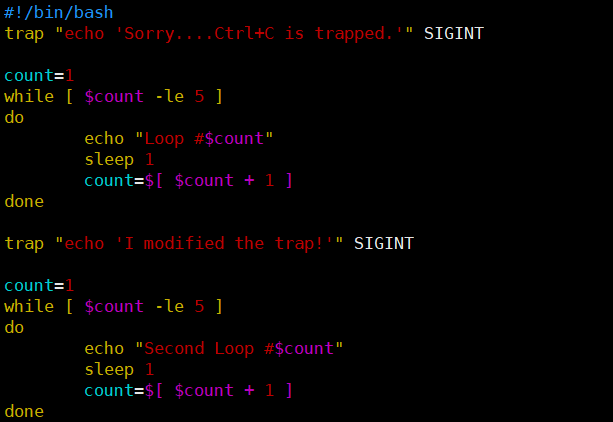
也可以删除已设置好的捕获。只需要在trap命令与希望恢复默认行为的信号列表之间加上两个破折号就行了。
[root@kittod ~]# cat ctr0301.sh
#!/bin/bash
trap "echo ' Sorry... Ctrl+C is trapped.'" SIGINT
count=1
while [ $count -le 5 ]
do
echo "Loop #$count"
sleep 1
count=$[ $count + 1 ]
done
trap -- SIGINT #删除已经设置好的捕获
echo "I just removed the trap"
count=1
while [ $count -le 5 ]
do
echo "Second Loop #$count"
sleep 1
count=$[ $count + 1 ]
done
[root@kittod ~]# bash ctr0301.sh
Loop #1
Loop #2
^C Sorry... Ctrl+C is trapped.
Loop #3
^C Sorry... Ctrl+C is trapped.
Loop #4
Loop #5
I just removed the trap
Second Loop #1
^C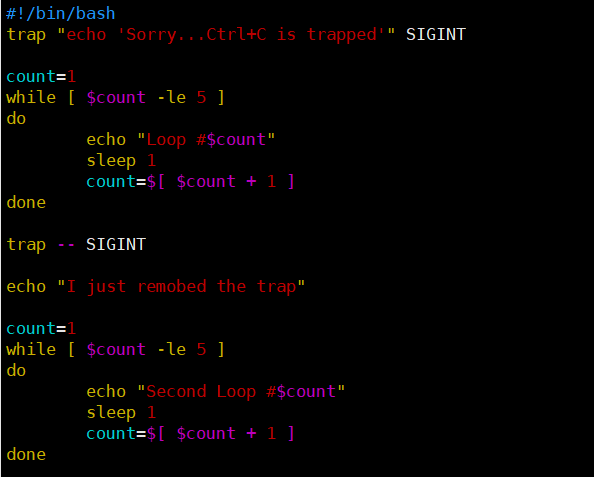
移除信号捕获后,脚本按照默认行为来处理SIGINT信号,也就是终止脚本运行。但如果信号是在捕获被移除前接收到的,那么脚本会按照原先trap命令中的设置进行处理。
在本例中, 第一个Ctrl+C组合键用于提前终止脚本。因为信号在捕获被移除前已经接收到了,脚本会照旧执行trap中指定的命令。捕获随后被移除,再按Ctrl+C就能够提前终止脚本了。
7.2后台模式运行
直接在命令行界面运行shell脚本有时不怎么方便。一些脚本可能要执行很长一段时间,而你可能不想在命令行界面一直干等着。当脚本在运行时,你没法在终端会话里做别的事情。幸好有个简单的方法可以解决。
在用ps命令时,会看到运行在Linux系统上的一系列不同进程。显然,所有这些进程都不是运行在你的终端显示器上的。这样的现象被称为在后台( background)运行进程。在后台模式中,进程运行时不会和终端会话上的STDIN、 STDOUT以及STDERR关联。也可以在shell脚本中试试这个特性,允许它们在后台运行而不用占用终端会话。
以后台模式运行shell脚本非常简单。只要在命令后加个&符就行了。
[root@kittod ~]# cat ctr04.sh
#!/bin/bash
count=1
while [ $count -le 10 ]
do
sleep 1
count=$[ $count + 1 ]
done
[root@kittod ~]# bash ctr04.sh &
[1] 2908 #[1]是作业号,2908是PID
![]()
当&符放到命令后时,它会将命令和bash shell分离开来,将命令作为系统中的一个独立的后台进程运行。
方括号中的数字是shell分配给后台进程的作业号。下一个数是Linux系统分配给进程的进程ID(PID)。 Linux系统上运行的每个进程都必须有一个唯一的PID。
一旦系统显示了这些内容,新的命令行界面提示符就出现了。你可以回到shell,而你所执行的命令正在以后台模式安全的运行。这时,你可以在提示符输入新的命令当后台进程结束时,它会在终端上显示出一条消息:
[root@kittod ~]# chmod +rx ctr04.sh
[1]+ Done bash ctr04.sh
这表明了作业的作业号以及作业状态( Done),还有用于启动作业的命令。
注意,当后台进程运行时,它仍然会使用终端显示器来显示STDOUT和STDERR消息。
[root@kittod ~]# cat ctr05.sh
#!/bin/bash
echo "Start the test script"
count=1
while [ $count -le 5 ]
do
echo "loop #$count"
sleep 5
count=$[ $count +1 ]
done
echo "Test script is complete"
[root@kittod ~]# bash ctr05.sh &
[1] 3254
[root@kittod ~]# Start the test script
loop #1
loop #2
loop #3
loop #4
loop #5
Test script is complete
[1]+ Done bash ctr05.sh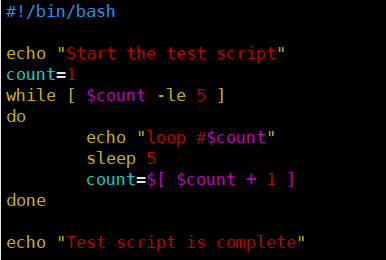
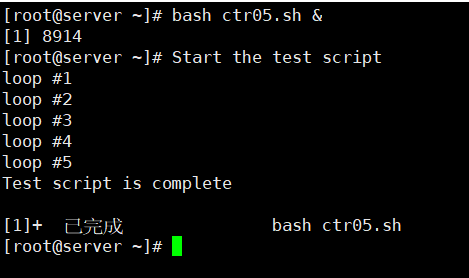
你会注意到在上面的例子中,脚本ctr05.sh的输出与shell提示符混杂在了一起,这也是为什么Start the test script会出现在提示符旁边的原因。
在显示输出的同时,你仍然可以运行命令。
[root@kittod ~]# bash ctr05.sh &
[1] 3278
[root@kittod ~]# Start the test script
loop #1
ls testfile
testfile
[root@kittod ~]# loop #2
loop #3
loop #4
loop #5
Test script is complete
[1]+ Done bash ctr05.sh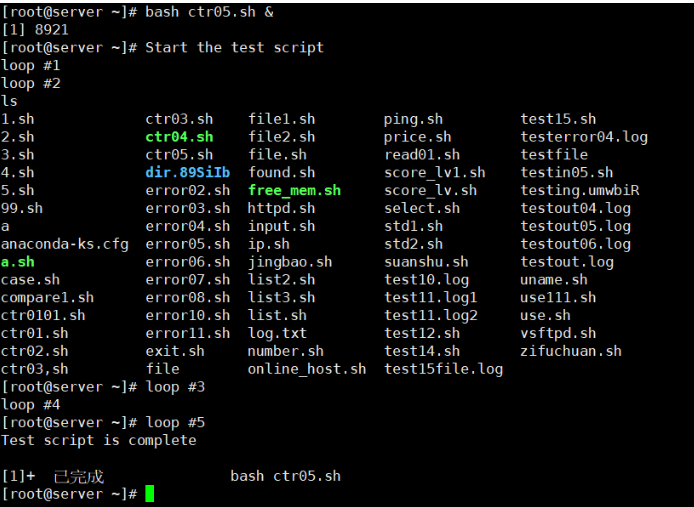
当脚本运行在后台模式时,我们输入了命令ls testfile。脚本输出、输入的命令以及命令输出全都混在了一起。真是让人头昏脑胀!最好是将后台运行的脚本的STDOUT和STDERR进行重定向,避免这种杂乱的输出。
可以在命令行提示符下同时启动多个后台作业。
[root@kittod ~]# cat ctr06.sh
#!/bin/bash
echo "Test script is complete #4"
sleep 15
[root@kittod ~]# bash ctr06.sh &
[1] 3470
[root@kittod ~]# Test script is complete #1
[root@kittod ~]# bash ctr07.sh &
[2] 3472
[root@kittod ~]# Test script is complete #2
[root@kittod ~]# bash ctr08.sh &
[3] 3474
[root@kittod ~]# Test script is complete #3
[root@kittod ~]# bash ctr09.sh &
[4] 3478
[root@kittod ~]# Test script is complete #4
[root@kittod ~]# ps
PID TTY TIME CMD
2571 pts/1 00:00:00 bash
3470 pts/1 00:00:00 bash
3471 pts/1 00:00:00 sleep
3472 pts/1 00:00:00 bash
3473 pts/1 00:00:00 sleep
3474 pts/1 00:00:00 bash
3475 pts/1 00:00:00 sleep
3478 pts/1 00:00:00 bash
3479 pts/1 00:00:00 sleep
3480 pts/1 00:00:00 ps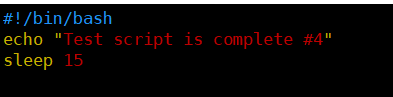
在终端会话中使用后台进程时一定要小心。注意,在ps命令的输出中,每一个后台进程都和终端会话( pts/1)终端联系在一起。如果终端会话退出,那么后台进程也会随之退出。
本章之前曾经提到过当你要退出终端会话时,要是存在被停止的进程,会出现警告信息。但如果使用了后台进程,只有某些终端仿真器会在你退出终端会话前提醒你还有后台作业在运行。如果希望运行在后台模式的脚本在登出控制台后能够继续运行,需要借助于别的手段。screen
7.3非控制台模式
有时你会想在终端会话中启动shell脚本,然后让脚本一直以后台模式运行到结束,即使你退出了终端会话。这可以用nohup命令来实现。
nohup命令运行了另外一个命令来阻断所有发送给该进程的SIGHUP信号。这会在退出终端会话时阻止进程退出。
nohup命令的格式如下:
[root@kittod ~]# nohup ./ctr01.sh &
[1] 3627
[root@kittod ~]# nohup: ignoring input and appending output to
'nohup.out'
[1]+ Done nohup ./ctr01.sh
和普通后台进程一样, shell会给命令分配一个作业号, Linux系统会为其分配一个PID号。区别在于,当你使用nohup命令时,如果关闭该会话,脚本会忽略终端会话发过来的SIGHUP信号。
由于nohup命令会解除终端与进程的关联,进程也就不再同STDOUT和STDERR联系在一起。为了保存该命令产生的输出, nohup命令会自动将STDOUT和STDERR的消息重定向到一个名为nohup.out的文件中。
如果使用nohup运行了另一个命令,该命令的输出会被追加到已有的nohup.out文件中。当运行位于同一个目录中的多个命令时一定要当心,因为所有的输出都会被发送到同一个nohup.out文件中,结果会让人摸不清头脑。
![]()
7.4作业控制
在本章的前面部分,你已经知道了如何用组合键停止shell中正在运行的作业。在作业停止后,Linux系统会让你选择是终止还是重启。你可以用kill命令终止该进程。要重启停止的进程需要向其发送一个SIGCONT信号。启动、停止、终止以及恢复作业的这些功能统称为作业控制。通过作业控制,就能完全控制shell环境中所有进程的运行方式了。
7.4.1查看作业
作业控制中的关键命令是jobs命令。 jobs命令允许查看shell当前正在处理的作业。
[root@kittod ~]# cat ctr10.sh
#!/bin/bash
echo "Script Process ID: $$" #$$当前进程的PID
count=1
while [ $count -le 10 ]
do
echo "loop #$count"
sleep 10
count=$[ $count + 1 ]
done
echo "End of script..."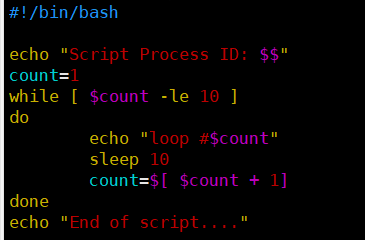
脚本用$$变量来显示Linux系统分配给该脚本的PID,然后进入循环,每次迭代都休眠10秒。可以从命令行中启动脚本,然后使用Ctrl+Z组合键来停止脚本。
[root@kittod ~]# bash ctr10.sh
Script Process ID: 3830
loop #1
^Z
[1]+ Stopped bash ctr10.sh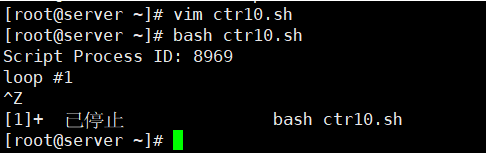
还是使用同样的脚本,利用&将另外一个作业作为后台进程启动。出于简化的目的,脚本的输出被重定向到文件中,避免出现在屏幕上。
[root@kittod ~]# bash ctr10.sh > test10.out &
[2] 3836
jobs命令可以查看分配给shell的作业。 jobs命令会显示这两个已停止/运行中的作业,以及它们的作业号和作业中使用的命令。
[root@kittod ~]# jobs
[1]+ Stopped bash ctr10.sh
[2]- Running bash ctr10.sh > test10.out &
要想查看作业的PID,可以在jobs命令中加入-l选项(小写的L)
[root@kittod ~]# jobs -l
[1]+ 3830 Stopped bash ctr10.sh
[2]- 3836 Done bash ctr10.sh > test10.out
jobs命令使用一些不同的命令行参数,见表:

你可能注意到了jobs命令输出中的加号和减号。带加号的作业会被当做默认作业。在使用作业控制命令时,如果未在命令行指定任何作业号,该作业会被当成作业控制命令的操作对象。当前的默认作业完成处理后,带减号的作业成为下一个默认作业。任何时候都只有一个带加号的作业和一个带减号的作业,不管shell中有多少个正在运行的作业。
下面例子说明了队列中的下一个作业在默认作业移除时是如何成为默认作业的。有3个独立的进程在后台被启动。 jobs命令显示出了这些进程、进程的PID及其状态。注意,默认进程(带有加号的那个)是最后启动的那个进程,也就是3号作业。
[root@kittod ~]# bash ctr10.sh > test10a.out &
[1] 3980
[root@kittod ~]# bash ctr10.sh > test10b.out &
[2] 3982
[root@kittod ~]# bash ctr10.sh > test10c.out &
[3] 3984
[root@kittod ~]# jobs -l
[1] 3980 Running bash ctr10.sh > test10a.out &
[2]- 3982 Running bash ctr10.sh > test10b.out &
[3]+ 3984 Running bash ctr10.sh > test10c.out &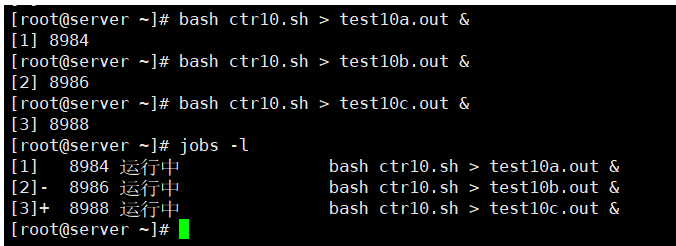
我们调用了kill命令向默认进程发送了一个SIGHUP信号,终止了该作业。在接下来的jobs命令输出中,先前带有减号的作业成了现在的默认作业,减号也变成了加号。
[root@kittod ~]# kill 3984
[root@kittod ~]# jobs -l
[1] 3980 Running bash ctr10.sh > test10a.out &
[2]- 3982 Running bash ctr10.sh > test10b.out &
[3]+ 3984 Terminated bash ctr10.sh > test10c.out
[root@kittod ~]# jobs -l
[1]- 3980 Running bash ctr10.sh > test10a.out &
[2]+ 3982 Running bash ctr10.sh > test10b.out &
[root@kittod ~]# kill 3982
[root@kittod ~]# jobs -l
[1]- 3980 Running bash ctr10.sh > test10a.out &
[2]+ 3982 Terminated bash ctr10.sh > test10b.out
[root@kittod ~]# jobs -l
[1]+ 3980 Running bash ctr10.sh > test10a.out &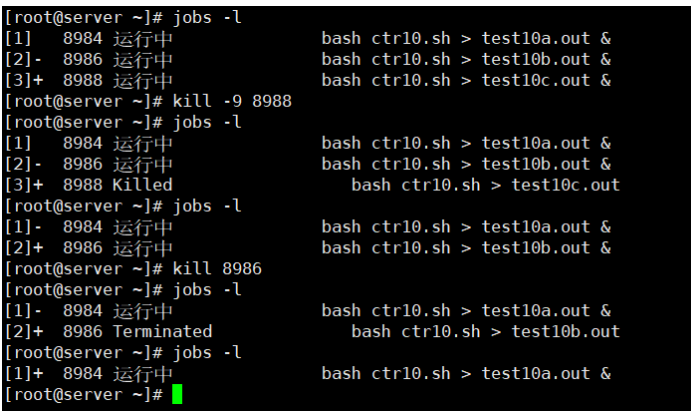
7.4.2重启停止的作业
在bash作业控制中,可以将已停止的作业作为后台进程或前台进程重启。前台进程会接管你当前工作的终端,所以在使用该功能时要小心了。要以后台模式重启一个作业,可用bg命令加上作业号。
[root@kittod ~]# ./ctr11.sh #ctr11.sh的内容和10一样
Script Process ID: 4054
loop #1
^Z
[1]+ Stopped ./ctr11.sh
[root@kittod ~]# bg
[1]+ ./ctr11.sh &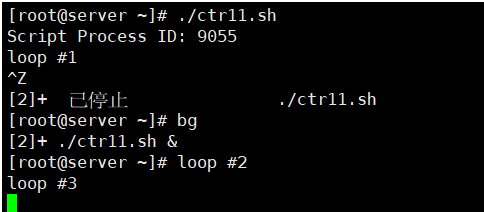
因为该作业是默认作业(从加号可以看出),只需要使用bg命令就可以将其以后台模式重启。
注意,当作业被转入后台模式时,并不会列出其PID。
如果有多个作业,你得在bg命令后加上作业号。
[root@kittod ~]# ./ctr11.sh
Script Process ID: 4073
loop #1
^Z
[1]+ Stopped ./ctr11.sh
[root@kittod ~]# ./ctr12.sh
Script Process ID: 4075
loop #1
^Z
[2]+ Stopped ./ctr12.sh
[root@kittod ~]# bg 2
[2]+ ./ctr12.sh &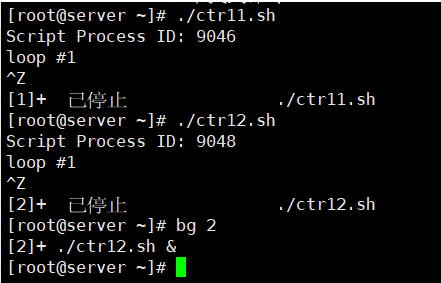
命令bg 2用于将第二个作业置于后台模式。注意,当使用jobs命令时,它列出了作业及其状态,即便是默认作业当前并未处于后台模式。
要以前台模式重启作业,可用带有作业号的fg命令。
[root@kittod ~]# fg 2
./ctr12.sh
^C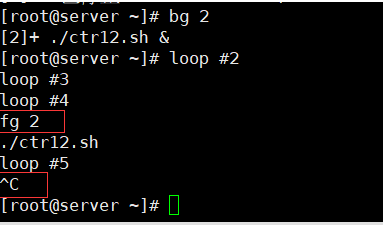
由于作业是以前台模式运行的,直到该作业完成后,命令行界面的提示符才会出现。
7.5进程优先级
NICE值反应一个进程“优先级”状态的值,其取值范围是-20至19,一共40个级别。这个值越小,表示进程”优先级”越高,而值越大“优先级”越低。
[root@kittod ~]# ps -l
F S UID PID PPID C PRI NI ADDR SZ WCHAN TTY TIME CMD
0 S 0 56652 56643 0 80 0 - 59329 - pts/3 00:00:00 bash
0 R 0 56712 56652 0 80 0 - 63809 - pts/3 00:00:00 ps指定一个nice值来启动一个新的bash shell
[root@kittod ~]# nice -n 10 bash #修改进程优先级
[root@kittod ~]# ps -l
F S UID PID PPID C PRI NI ADDR SZ WCHAN TTY TIME CMD
0 S 0 56652 56643 0 80 0 - 59329 - pts/3 00:00:00 bash
0 S 0 56743 56652 0 90 10 - 59334 - pts/3 00:00:00 bash
0 R 0 56765 56743 0 90 10 - 63809 - pts/3 00:00:00 ps
[root@kittod ~]# nice
10
[root@kittod ~]# exit
exit
[root@kittod ~]# nice
0通过renice命令可以调整正在运行的进程的“优先级”
[root@kittod ~]# echo $$ #当前进程的PID
59028
[root@kittod ~]# renice +1 59028 #设置为+1
59028 (process ID) old priority 10, new priority 1
[root@kittod ~]# nice
1nice值不是优先级,但却可以影响优先级,我们用谦让度来解释nice值。两者关系如图所示:
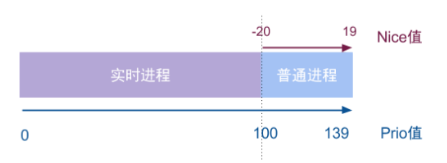
优先级值越小表示进程优先级越高,3个进程优先级的概念:
静态优先级: 不会时间而改变,内核也不会修改,只能通过系统调用改变nice值的方法区修改。优先级映射公式: static_prio = MAX_RT_PRIO + nice + 20,其中MAX_RT_PRIO = 100,那么取值区间为[100, 139];对应普通进程;
实时优先级:只对实时进程有意义,取值区间为[0, MAX_RT_PRIO -1],其中MAX_RT_PRIO = 100,那么取值区间为[0, 99];对应实时进程;
动态优先级: 调度程序通过增加或减少进程静态优先级的值,来达到奖励IO消耗型或惩罚cpu消耗型的进程,调整后的进程称为动态优先级。区间范围[0, MX_PRIO-1],其中MX_PRIO = 140,那么取值区间为[0,139];
在内核中,进程优先级的取值范围是通过一个宏定义的,这个宏的名称是MAX_PRIO,它的值为140。
而这个值又是由另外两个值相加组成的,一个是代表nice值取值范围的NICE_WIDTH宏,另
一个是代表实时进程(realtime)优先级范围的MAX_RT_PRIO宏。
说白了就是,Linux实际上实现了140个优先级范围,取值范围是从0-139,这个值越小,优先级越高。nice值的-20到19,映射到实际的优先级范围是100-139。
新产生进程的默认优先级被定义为:
#define DEFAULT_PRIO (MAX_RT_PRIO + NICE_WIDTH / 2)
实际上对应的就是nice值的0。
正常情况下,任何一个进程的优先级都是这个值,即使我们通过nice和renice命令调整了进程的优先级,它的取值范围也不会超出100-139的范围,除非这个进程是一个实时进程,那么它的优先级取值才会变成0-99这个范围中的一个。
什么是实时操作系统?
简单来说,实时操作系统需要保证相关的实时进程在较短的时间内响应,不会有较长的延时,并且要求最小的中断延时和进程切换延时.
对于这样的需求,一般的进程调度算法,无论是O1还是CFS都是无法满足的,所以内核在设计的时候,将实时进程单独映射了100个优先级,这些优先级都要高于正常进程的优先级(nice值),而实时进程的调度算法也不同,它们采用更简单的调度算法来减少调度开销。
总的来说,Linux系统中运行的进程可以分成两类:
- 实时进程
- 非实时进程
它们的主要区别就是通过优先级来区分的。
所有优先级值在0-99范围内的,都是实时进程,所以这个优先级范围也可以叫做实时进程优先级,而100-139范围内的是非实时进程。
在系统中可以使用chrt命令来查看、设置一个进程的实时优先级状态。我们可以先来看一下
chrt命令的使用:
[root@kittod ~]# chrt --help
Show or change the real-time scheduling attributes of a process.
Set policy:
chrt [options] <priority> <command> [<arg>...]
chrt [options] --pid <priority> <pid>
Get policy:
chrt [options] -p <pid>
Policy options:
-b, --batch set policy to SCHED_BATCH
-d, --deadline set policy to SCHED_DEADLINE
-f, --fifo set policy to SCHED_FIFO
-i, --idle set policy to SCHED_IDLE
-o, --other set policy to SCHED_OTHER
-r, --rr set policy to SCHED_RR (default)
Scheduling options:
-R, --reset-on-fork set SCHED_RESET_ON_FORK for FIFO or RR
-T, --sched-runtime <ns> runtime parameter for DEADLINE
-P, --sched-period <ns> period parameter for DEADLINE
-D, --sched-deadline <ns> deadline parameter for DEADLINE
Other options:
-a, --all-tasks operate on all the tasks (threads) for a given
pid
-m, --max show min and max valid priorities
-p, --pid operate on existing given pid
-v, --verbose display status information
-h, --help display this help
-V, --version display version
For more details see chrt(1).通过查看帮助发现,系统提供了六种调度策略,但是这六种调度策略分别是给两种进程使用的,具体如下:
实时进程:
SCHED_FIFO
SCHED_RR
SCHED_DEADLINE
非实时进程
SCHED_BATCH
SCHED_OTHER
SCHED_IDLE
实时进程可以指定的优先级范围为1-99,将一个要执行的程序以实时方式执行的方法为:
[root@kittod ~]# chrt 10 bash
[root@kittod ~]# chrt -p $$
pid 60749's current scheduling policy: SCHED_RR
pid 60749's current scheduling priority: 10修改调度策略和优先级
[root@kittod ~]# chrt -f -p 20 $$
[root@kittod ~]# chrt -p $$
pid 61673's current scheduling policy: SCHED_FIFO
pid 61673's current scheduling priority: 20只修改调度策略
[root@kittod ~]# chrt -r -p 20 $$
[root@kittod ~]# chrt -p $$
pid 61673's current scheduling policy: SCHED_RR
pid 61673's current scheduling priority: 20而相对更麻烦的是非实时进程,它们才是Linux上进程的主要分类。对于非实时进程优先级的处理,我们首先还是要来介绍一下它们相关的调度算法:O1和CFS。
什么是O1调度?
O1调度算法是在Linux 2.6开始引入的,到Linux 2.6.23之后内核将调度算法替换成了CFS。虽然O1算法已经不是当前内核所默认使用的调度算法了,但是由于大量线上的服务器可能使用的Linux版本还是老版本,所以我相信很多服务器还是在使用着O1调度器,那么费一点口舌简单交代一下这个调度器也是有意义的。
这个调度器的名字之所以叫做O1,主要是因为其算法的时间复杂度是O1。
O1调度器仍然是根据经典的时间片分配的思路来进行整体设计的。
简单来说,时间片的思路就是将CPU的执行时间分成一小段一小段的,假如是5ms一段。于是多个进程如果要“同时”执行,实际上就是每个进程轮流占用5ms的cpu时间,而从1s的时间尺度上看,这些进程就是在“同时”执行的。
当然,对于多核系统来说,就是把每个核心都这样做就行了。而在这种情况下,如何支持优先级呢?
实际上就是将时间片分配成大小不等的若干种,优先级高的进程使用大的时间片,优先级小的进程使用小的时间片。这样在一个周期结速后,优先级大的进程就会占用更多的时间而因此得到特殊待遇。
O1算法还有一个比较特殊的地方是,即使是相同的nice值的进程,也会再根据其CPU的占用情况将其分成两种类型:CPU消耗型和IO消耗性。
典型的CPU消耗型的进程的特点是,它总是要一直占用CPU进行运算,分给它的时间片总是会被耗尽之后,程序才可能发生调度。比如常见的各种算数运算程序。
而IO消耗型的特点是,它经常时间片没有耗尽就自己主动先释放CPU了。
比如vi,emacs这样的编辑器就是典型的IO消耗型进程。
为什么要这样区分呢?因为IO消耗型的进程经常是跟人交互的进程,比如shell、编辑器等。
当系统中既有这种进程,又有CPU消耗型进程存在,并且其nice值一样时,假设给它们分的时间片长度是一样的,都是500ms,那么人的操作可能会因为CPU消耗型的进程一直占用CPU而变的卡顿。
可以想象,当bash在等待人输入的时候,是不占CPU的,此时CPU消耗的程序会一直运算,假设每次都分到500ms的时间片,此时人在bash上敲入一个字符的时候,那么bash很可能要等个几百ms才能给出响应,因为在人敲入字符的时候,别的进程的时间片很可能并没有耗尽,所以系统不会调度bash程度进行处理。
为了提高IO消耗型进程的响应速度,系统将区分这两类进程,并动态调整CPU消耗的进程将其优先级降低,而IO消耗型的将其优先级变高,以降低CPU消耗进程的时间片的实际长度。
已知nice值的范围是-20-19,其对应priority值的范围是100-139,对于一个默认nice值为0的进程来说,其初始priority值应该是120,随着其不断执行,内核会观察进程的CPU消耗状态,并动态调整priority值,可调整的范围是+-5。
就是说,最高优先级可以被自动调整到115,最低到125。这也是为什么nice值叫做静态优先级,而priority值叫做动态优先级的原因。不过这个动态调整的功能在调度器换成CFS之后就不需要了,因为CFS换了另外一种CPU时间分配方式,这个我们后面再说。
什么是CFS完全公平调度?
O1已经是上一代调度器了,由于其对多核、多CPU系统的支持性能并不好,并且内核功能上要加入cgroup等因素,Linux在2.6.23之后开始启用CFS作为对一般优先级(SCHED_OTHER)进程调度方法。
在这个重新设计的调度器中,时间片,动态、静态优先级以及IO消耗,CPU消耗的概念都不再重要。CFS采用了一种全新的方式,对上述功能进行了比较完善的支持。
其设计的基本思路是:我们想要实现一个对所有进程完全公平的调度器。
又是那个老问题:如何做到完全公平?
答案跟上一篇IO调度中CFQ的思路类似:
如果当前有n个进程需要调度执行,那么调度器应该在一个比较小的时间范围内,把这n个进程全都调度执行一遍,并且它们平分cpu时间,这样就可以做到所有进程的公平调度。
那么这个比较小的时间就是任意一个R状态进程被调度的最大延时时间,即:任意一个R状态进程,都一定会在这个时间范围内被调度响应。这个时间也可以叫做调度周期,其英文名字叫做:sched_latency_ns。
CFS的优先级
当然,CFS中还需要支持优先级。在新的体系中,优先级是以时间消耗(vruntime增长)的快慢来决定的。
就是说,对于CFS来说,衡量的时间累积的绝对值都是一样纪录在vruntime中的,但是不同优先级的进程时间增长的比率是不同的,高优先级进程时间增长的慢,低优先级时间增长的快。
比如,优先级为19的进程,实际占用cpu为1秒,那么在vruntime中就记录1s。但是如果是-20优先级的进程,那么它很可能实际占CPU用10s,在vruntime中才会纪录1s。
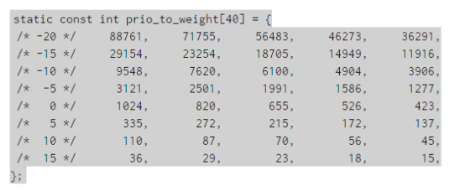
CFS真实实现的不同nice值的cpu消耗时间比例在内核中是按照“每差一级cpu占用时间差10%左右”这个原则来设定的。
这里的大概意思是说,如果有两个nice值为0的进程同时占用cpu,那么它们应该每人占50%的cpu,如果将其中一个进程的nice值调整为1的话,那么此时应保证优先级高的进程比低的多占用10%的cpu,就是nice值为0的占55%,nice值为1的占45%。那么它们占用cpu时间的比例为55:45。
这个值的比例约为1.25。就是说,相邻的两个nice值之间的cpu占用时间比例的差别应该大约为1.25。根据这个原则,内核对40个nice值做了时间计算比例的对应关系,它在内核中以一个数组存在:
多CPU的CFS调度是怎样的?
在上面的叙述中,我们可以认为系统中只有一个CPU,那么相关的调度队列只有一个。
实际情况是系统是有多核甚至多个CPU的,CFS从一开始就考虑了这种情况,它对每个CPU核心都维护一个调度队列,这样每个CPU都对自己的队列进程调度即可。
这也是CFS比O1调度算法更高效的根本原因:每个CPU一个队列,就可以避免对全局队列使用大内核锁,从而提高了并行效率。
当然,这样最直接的影响就是CPU之间的负载可能不均,为了维持CPU之间的负载均衡,CFS要定期对所有CPU进行load balance操作,于是就有可能发生进程在不同CPU的调度队列上切换的行为。
这种操作的过程也需要对相关的CPU队列进行锁操作,从而降低了多个运行队列带来的并行性。
不过总的来说,CFS的并行队列方式还是要比O1的全局队列方式要高效。尤其是在CPU核心越来越多的情况下,全局锁的效率下降显著增加。
7.6定时任务
当你开始使用脚本时,可能会想要在某个预设时间运行脚本,这通常是在你不在场的时候。
Linux系统提供了多个在预选时间运行脚本的方法: at命令和cron周期计划任务。每个方法都使用不同的技术来安排脚本的运行时间和频率。
7.6.1用at命令来计划执行作业
at命令允许指定Linux系统何时运行脚本。 at命令会将作业提交到队列中,指定shell何时运行该作业。 at的守护进程atd会以后台模式运行,检查作业队列来运行作业。大多数Linux发行版会在启动时运行此守护进程。
atd守护进程会检查系统上的一个特殊目录(通常位于/var/spool/at)来获取用at命令提交的作业。默认情况下, atd守护进程会每60秒检查一下这个目录。
有作业时, atd守护进程会检查作业设置运行的时间。如果时间跟当前时间匹配, atd守护进程就会运行此作业。
1、at命令格式
at [-f filename] time 1
默认情况下, at命令会将STDIN的输入放到队列中。你可以用-f参数来指定用于读取命令(脚本文件)的文件名。
time参数指定了Linux系统何时运行该作业。如果你指定的时间已经错过, at命令会在第二天的那个时间运行指定的作业。
在如何指定时间这个问题上,你可以非常灵活。 at命令能识别多种不同的时间格式。
- 标准的小时和分钟格式,比如10:15。
- AM/PM指示符,比如10:15 PM。
- 特定可命名时间,比如now、 noon、 midnight,teatime。
除了指定运行作业的时间,也可以通过不同的日期格式指定特定的日期。
- 标准日期格式,比如MMDDYY、 MM/DD/YY或DD.MM.YY。
- 文本日期,比如Jul 4或Dec 25,加不加年份均可。
你也可以指定时间增量。
- 当前时间+25 min
- 明天10:15 PM
- 10:15+7天
在你使用at命令时,该作业会被提交到作业队列( job queue)。作业队列会保存通过at命令提交的待处理的作业。针对不同优先级,存在26种不同的作业队列。
作业队列通常用小写字母a~z和大写字母A~Z来指代。
作业队列的字母排序越高,作业运行的优先级就越低(更高的nice值)。默认情况下, at的作业会被提交到a作业队列。 如果想以更高优先级运行作业, 可以用-q参数指定不同的队列字母。
2、获取作业的输出
当作业在Linux系统上运行时,显示器并不会关联到该作业。取而代之的是, Linux系统会将提交该作业的用户的电子邮件地址作为STDOUT和STDERR。任何发到STDOUT或STDERR的输出都会通过邮件系统发送给该用户。
[root@kittod ~]# cat at01.sh
#!/bin/bash
echo "This script run at $(date +%B%d,%T)"
echo
sleep 5
echo "This is the script's end..."
[root@kittod ~]# at -f at01.sh now
warning: commands will be executed using /bin/sh
job 1 at Tue May 18 11:00:00 2021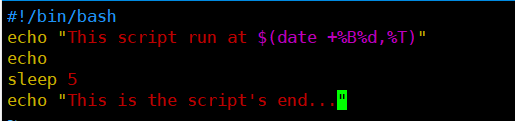
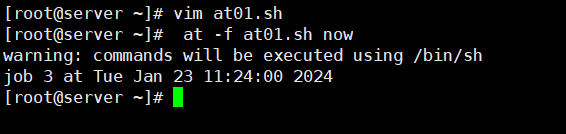
at命令会显示分配给作业的作业号以及为作业安排的运行时间。 -f选项指明使用哪个脚本文件, now指示at命令立刻执行该脚本。
该任务执行后,默认会发送到邮件,并不会在屏幕上输出信息,所以我们可以通过mail命令查看相关输出结果:
[root@kittod ~]# mail
Heirloom Mail version 12.5 7/5/10. Type ? for help.
"/var/spool/mail/root": 1 message 1 new
>N 1 root Tue May 18 13:22 16/539 "Output from
your job "
& 1
Message 1:
From root@kittod.localdomain Tue May 18 13:22:09 2021
Return-Path: <root@kittod.localdomain>
X-Original-To: root
Delivered-To: root@kittod.localdomain
Subject: Output from your job 4
To: root@kittod.localdomain
Date: Tue, 18 May 2021 13:22:09 +0800 (CST)
From: root <root@kittod.localdomain>
Status: R
This script run at May18,13:22:04
This is the script's end...
&当然你可以在脚本中使用重定向将需要的信息输出到指定文件。如果不需要发送到邮件,你可以使用-M选项来指定:
[root@kittod ~]# at -M -f at01.sh now
3、列出等待的作业
[root@kittod ~]# at -M -f at01.sh tomorrow
warning: commands will be executed using /bin/sh
job 6 at Wed May 19 13:27:00 2021
[root@kittod ~]# at -M -f at01.sh 13:30
warning: commands will be executed using /bin/sh
job 7 at Tue May 18 13:30:00 2021
[root@kittod ~]# atq
6 Wed May 19 13:27:00 2021 a root
7 Tue May 18 13:30:00 2021 a root4、删除作业
[root@kittod ~]# atq
5 Tue May 18 16:00:00 2021 a root
6 Wed May 19 13:27:00 2021 a root
7 Tue May 18 13:30:00 2021 a root
[root@kittod ~]# atrm 7
[root@kittod ~]# atq
5 Tue May 18 16:00:00 2021 a root
6 Wed May 19 13:27:00 2021 a root7.6.2安排需要定期执行的脚本
用at命令在预设时间安排脚本执行非常好用,但如果你需要脚本在每天的同一时间运行或是每周一次、每月一次呢 ?我们可以使用cron计划任务。
Linux系统使用cron程序来安排要定期执行的作业。 cron程序会在后台运行并检查一个特殊的表(被称作cron时间表) ,以获知已安排执行的作业。
1、时间表
cron时间表采用一种特别的格式来指定作业何时运行。其格式如下:
min hour dayofmonth month dayofweek command
具体可参考文件:
[root@kittod ~]# cat /etc/crontab
SHELL=/bin/bash
PATH=/sbin:/bin:/usr/sbin:/usr/bin
MAILTO=root
# For details see man 4 crontabs
# Example of job definition:
# .---------------- minute (0 - 59)
# | .------------- hour (0 - 23)
# | | .---------- day of month (1 - 31)
# | | | .------- month (1 - 12) OR jan,feb,mar,apr ...
# | | | | .---- day of week (0 - 6) (Sunday=0 or 7) OR
sun,mon,tue,wed,thu,fri,sat
# | | | | |
# * * * * * user-name command to be executedcron时间表允许你用特定值、取值范围(比如1~5)或者是通配符(星号)来指定条目。例如,如果想在每天的10:15运行一个命令,可以用cron时间表条目:
15 10 * * * command
在dayofmonth、 month以及dayofweek字段中使用了通配符,表明cron会在每个月每天的10:15执行该命令。要指定在每周一4:15 PM运行的命令,可以用下面的条目:
15 16 * * 1 command
可以用三字符的文本值( mon、 tue、 wed、 thu、 fri、 sat、 sun)或数值( 0为周日, 6为周六)来指定dayofweek表项。
这里还有另外一个例子:在每个月的第一天中午12点执行命令。可以用下面的格式:
00 12 1 * * command
dayofmonth表项指定月份中的日期值( 1~31)。
指定每个月最后一天:
00 12 * * * if [`date +%d -d tomorrow` = 01 ] ; then ; command
命令列表必须指定要运行的命令或脚本的全路径名。你可以像在普通的命令行中那样,添加任何想要的命令行参数和重定向符号。
15 10 * * * /home/rich/test4.sh > test4out
cron程序会用提交作业的用户账户运行该脚本。因此,你必须有访问该命令和命令中指定的输出文件的权限。
2、构建cron时间表
每个系统用户(包括root用户)都可以用自己的cron时间表来运行安排好的任务。 Linux提供了crontab命令来处理cron时间表。要列出已有的cron时间表,可以用-l选项。
[root@kittod ~]# crontab -l
no crontab for root
[root@kittod ~]#默认情况下,用户的cron时间表文件并不存在。要为cron时间表添加条目,可以用-e选项。在添加条目时, crontab命令会启用一个文本编辑器,使用已有的cron时间表作为文件内容(或者是一个空文件,如果时间表不存在的话)。创建计划任务后,在指定用户的对应目录下:
[root@kittod ~]# ll /var/spool/cron/
total 4
-rw-------. 1 root root 20 May 18 14:04 root
[root@kittod ~]# cat /var/spool/cron/root
* * * * * echo hehe3、浏览cron目录
如果你创建的脚本对精确的执行时间要求不高,用预配置的cron脚本目录会更方便。有4个基本目录: hourly、 daily、 monthly和weekly。
[root@kittod ~]# ll /etc/cron.*ly
/etc/cron.daily:
total 4
-rwxr-xr-x. 1 root root 189 Jan 4 2018 logrotate
/etc/cron.hourly:
total 4
-rwxr-xr-x. 1 root root 575 Jun 13 2019 0anacron
/etc/cron.monthly:
total 0
/etc/cron.weekly:
total 0因此,如果脚本需要每天运行一次,只要将脚本复制到daily目录, cron就会每天执行它。















 160
160











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









