






1. 问题背景
信号的稀疏表示并不是新的东西。我们很早就一直在利用这一特性。例如,最简单的JPEG图像压缩算法。原始的图像信号经过DCT变换之后,只有极少数元素是非零的,而大部分元素都等于零或者说接近于零。这就是信号的稀疏性。
任何模型都有建模的假设条件。压缩感知,正是利用的信号的稀疏性这个假设。对于我们处理的信号,时域上本身就具有稀疏性的信号是很少的。但是,我们总能找到某种变换,使得在某个变换域之后信号具有稀疏性。这种变换是很多的,最常见的就是DCT变换,小波变换,gabor变换等。
然而,这种正交变换是传统视频图像处理采用的方法。目前所采用的一般不是正交变换。它是基于样本采样的。或者说是通过大量图像数据学习得到的,其结果称作字典,字典中的每一个元素称作原子。相关的学习算法称作字典学习。常见的算法例如K-SVD算法。学习的目标函数是找到所有样本在这些原子的线性组合表示下是稀疏的,即同时估计字典和稀疏表示的系数这两个目标。
压缩感知和稀疏表示其实是有些不同的。压缩感知的字典是固定的,在压缩感知的术语里面其字典叫做测量矩阵。但压缩感知的恢复算法和稀疏表示是同一个问题。他们都可以归结为带约束条件的L1范数最小化问题。求解这类泛函的优化有很多种方法。早在80年代,统计学中Lasso问题,其实和稀疏分解的优化目标泛函是等价的。而求解统计学中lasso 问题的LARS算法很早就被提出了,故我们还可以通过统计学的LARS算法求解稀疏表示问题。目前很多统计学软件包都自带LARS算法的求解器。
2. 基于稀疏表示的分类 SRC
人脸的稀疏表示是基于光照模型。即一张人脸图像,可以用数据库中同一个人所有的人脸图像的线性组合表示。而对于数据库中其它人的脸,其线性组合的系数理论上为零。由于数据库中一般有很多个不同的人脸的多张图像,如果把数据库中所有的图像的线性组合来表示这张给定的测试人脸,其系数向量是稀疏的。因为除了这张和同一个人的人脸的图像组合系数不为零外,其它的系数都为零。
上述模型导出了基于稀疏表示的另外一个很强的假设条件:所有的人脸图像必须是事先严格对齐的。否则,稀疏性很难满足。换言之,对于表情变化,姿态角度变化的人脸都不满足稀疏性这个假设。所以,经典的稀疏脸方法很难用于真实的应用场景。
稀疏脸很强的地方在于对噪声相当鲁棒,相关文献表明,即使人脸图像被80%的随机噪声干扰,仍然能够得到很高的识别率。稀疏脸另外一个很强的地方在于对于部分遮挡的情况,例如戴围巾,戴眼镜等,仍然能够保持较高的识别性能。上述两点,是其它任何传统的人脸识别方法所不具有的。
3. 稀疏人脸识别的实现问题
一谈到识别问题,大家都会想到要用机器学习的方法。先进行训练,把训练的结果以模板的形式存储到数据库上;真实应用环境的时候,把测试样本经过特征提取之后,和数据库中的模板进行比对,查询得到一个最相似的类别作为识别结果。往往,机器训练的时间都超级长,几天,几个礼拜乃至几个月,那是常见的事情;识别的时间一般是很小的。典型的例如人脸检测问题。这是可以接受的,因为训练一般都是离线的。
然而,基于稀疏分解的人脸识别是不需要训练的,或者说训练及其简单。基于稀疏表示的人脸识别,其稀疏表示用的字典直接由训练所用的全部图像构成,而不需要经过字典学习【也有一些改进算法,针对字典进行学习的】。当然,一般是经过简单的特征提取。由于稀疏表示的方法对使用什么特征并不敏感。故而,其训练过程只需要把原始图像数据经过简单的处理之后排列成一个很大的三维矩阵存储到数据库里面就可以了。
关键的问题在于,当实际环境中来了一张人脸图像之后,去求解这张人脸图像在数据库所有图像上的稀疏表示,这个求解算法,一般比较耗时。尽管有很多的方法被提出,但是对于实时应用问题,依然没法满足。所以,问题的关键还是归结于L1范数最小化问题上来。
L1范数最小化问题已经有很多种快速求解方法,这里主要包括有梯度投影Gradient Projection,同伦算法,迭代阈值收缩,领域梯度Proximal Gradient,增广拉格朗日方法,这几种方法都比正交匹配追踪算法OMP要高效的多。上述几种快速算法中,采用增广拉格朗日的对偶实现相比其它的快速算法要更好。最近流行的Spit Bregman算法也是不错的选择。
4. 稀疏表示人脸识别的改进算法
4.1 CRC-RLS算法


4.2 RSC算法
CVPR2011 Meng Yang,Robost Sparse Coding for Face Recognition. 鲁棒的稀疏编码算法。该文作者没有直接求解稀疏编码问题,而是求解Lasso问题,因为Lasso问题的解和稀疏编码的解是等价的。在传统的SRC框架下,编码误差使用L2范数来度量的,这也就意味着编码误差满足高斯分布,然而,当人脸图像出现遮挡和噪声污染的情况下,并非如此。在字典学习框架下,这样的字典是有噪声的。该文作者对原始Lasso问题进行改进,求解加权L1范数约束的线性回归问题。Lasso问题描述如下:

加权Lasso问题的目标函数描述如下:
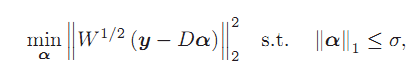
此算法的关键还在于权重系数的确定,文中采用的是logistic函数,而具体的实现则是通过迭代估计学习得到。该方法基于这样一个事实:被遮挡或噪声干扰的像素点赋予较小的权重,而其它像素点的权重相对较大。具体迭代算法采用经典的迭代重加权算法框架,当然内部嵌入的稀疏编码的求解过程。此算法在50%遮挡面积的情况下取得的更好更满意的结果。但是文中没有比较计算时间上的优略而直说和SRC框架差不多。

















 1416
1416

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









