







 本文介绍了正则表达式的概念及其在网页数据处理中的作用,详细讲解了常用元字符、量词、贪婪匹配和惰性匹配的区别,以及PythonRe模块的findall、finditer、search和match方法的用法,以及预加载优化。通过实例演示了如何在实际项目中提取和解析数据。
本文介绍了正则表达式的概念及其在网页数据处理中的作用,详细讲解了常用元字符、量词、贪婪匹配和惰性匹配的区别,以及PythonRe模块的findall、finditer、search和match方法的用法,以及预加载优化。通过实例演示了如何在实际项目中提取和解析数据。
一,概念
正则表达式(Regular Expression)是计算机科学中用于处理字符串的强大工具,它提供了一种强大且灵活的方式来描述、查找、匹配或替换文本中的模式或字符组合。正则表达式是由一系列特殊字符和普通字符组成的字符串,它们遵循一套预定义的规则来指定搜索模式。说白了,就是当我们通过爬虫爬取到了网页数据(网页数据本身也是字符串),但这些网页数据杂乱不堪,想要提取我们想要的信息极为不易,这时正则表达式都有了作用。简单来说,正则表达式就是用一些蕴含某种含义的字符来排列组合形成的一种面向字符串的筛选规则,满足条件的字符串留下,不满足的剔除。
我们可以通过这个网站对以下的元字符和量词进行检验。
二,常用元字符
| . | 匹配除换行符的任意字符 |
| \w | 匹配字母或数字或下划线 |
| \s | 匹配任意空白符 |
| \d | 匹配数字 |
| \n | 匹配一个换行符 |
| \t | 匹配一个制表符 |
| ^ | 匹配字符串的开始 |
| $ | 匹配字符串的结尾 |
| \W | 匹配非字母,数字,下划线 |
| \D | 匹配非数字 |
| \S | 匹配非空白符 |
| a|b | 匹配字符a或字符b |
| () | 匹配括号内的表达式,也表示一个组 |
| […] | 匹配字符组中的字符 |
| [^…] | 匹配除了字符组中字符的所有字符 |
三,量词
| * | 重复零次或更多次 |
| + | 重复一次或更多次 |
| ? | 重复零次或一次 |
| {n} | 重复n次 |
| {n,} | 重复n次或更多次 |
| {n,m} | 重复n到m次 |
四,贪婪匹配和惰性匹配
贪婪匹配和惰性匹配是正则表达式中的两种不同匹配模式,它们主要影响量词(如*、+、?)在进行匹配时的行为。
-
贪婪匹配: 在贪婪匹配模式下,正则表达式会尽可能多地匹配字符,即尽可能让量词匹配的次数达到最大。例如,对于字符串 "aabbcc" 和正则表达式 "a+b+",贪婪匹配将匹配整个字符串 "aabb",因为 "+" 符号表示前面的 "a" 或 "b" 可以出现一次或多次,它会尽可能多地匹配字符。
-
惰性匹配或非贪婪匹配: 惰性匹配则是尽可能少地匹配字符,只要满足匹配条件就停止匹配。同样以上述例子,在惰性匹配模式下,对于正则表达式 "a+?b+?",它会在第一个 "a" 后面匹配尽可能少的 "b",因此它会匹配 "aab",而不是整个 "aabb"。
| 贪婪匹配:尽可能多的匹配结果 | .* |
| 惰性匹配:尽可能少的匹配结果 | .*? |
五,Re模块
1.findall方法
import re
res = re.findall(r"\d+","我的电话号码是134551515212")
print(res)输出结果: ['134551515212']
re.findall方法是最普通的方法之一,即应用正则表达式对字符串进行筛选。
2.finditer方法
import re
res_iter = re.finditer(r"\d+","我的电话号码是11111111,ID是11515515121215")
print(res_iter)#返回了一个迭代器
for i in res_iter:
print(i)#得到re.Match对象
print(i.group())#得到数据
re.finditer方法会返回一个迭代器,实际使用中被经常使用,我们可以用for循环遍历迭代器,得到re.Match对象,最后用group查看数据,group后续数据解析中用处很大。
3.search方法
import re
#search只会匹配第一次结果
res_search = re.search(r"\d+","我今年22岁,月薪8000+")
print(res_search)#返回re.Match对象
print(res_search.group())#返回结果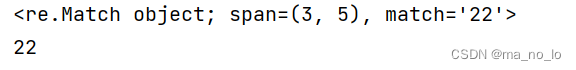
re.search方法只会匹配一次,找到就完事。同样返回一个re.Match对象,使用group查看数据。
4.match方法
import re
#match匹配时从字符串开头进行匹配,相当于^
res_match = re.match(r"\d+","我今年22岁,月薪8000+")
print(res_match)#None
返回结果为None,re.match方法会匹配字符串开头,相当于^,使用较少。
5.预加载
import re
#预加载:防止重复使用正则,消耗内存
obj = re.compile(r"\d+")
obj.match()
obj.search()
obj.findall()
obj.finditer()
预加载有点像宏定义,我们用obj代替了一串又一串相同的正则表达式,这样就不用担心太浪费内存了。
六,Re模块应用
s = """<div class='rect'><span id='10001'>庆余年</span></div>
<div class='rect'><span id='10002'>诡秘之主</span></div>"""
obj = re.compile(r"<span id='(?P<id>\d+)'>(?P<name>.*?)</span>")#提取数据时用小括号括起来,单独起名字(?P<name>正则),提取时用group(name)就可以了
res = obj.finditer(s)
for i in res:
id = i.group("id")
name = i.group("name")
print(id,name)
我们可以用(?P<name>正则)来进行数据解析,把不同种类数据进行划分,再使用迭代器遍历查看,group()这时有了大用,我们可以将命名好的类别填入,group()会返回这个类别下的数据。这样可以提升我们的效率,方便管理。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









