







简单来讲,双回归分析是ICA的一个延伸分析,旨在将ICA的组成分结果映射回单个样本中,从而计算其组差异。许多针对大脑的功能影像数据研究的文章采用过这种方法,在此不赘述。下面进入实现部分:
一. 软件准备
1.Linux系统
2.FSL:https://fsl.fmrib.ox.ac.uk/fsl/fslwiki/FslInstallation
二.数据准备
1. 数据转格式dicom >> nii(fMRI / T1)
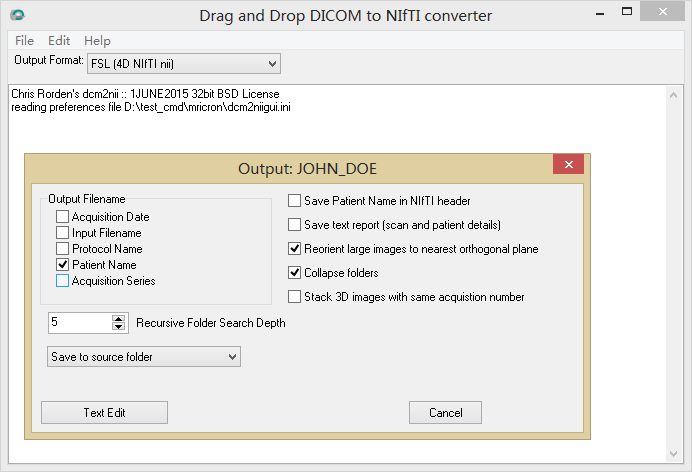
首先,在转格式之前,在 dcm2niigui--help--Preferences 设置转化文件名
Figure 1 设置转化文件名
注意:
Dcm2nii:rfmri_dicom >> 1 个 4D 文件
Dcm2nii:T1>>3 个 4D 文件:*.nii,o*.nii,co*.nii(保留co后续BET)
2. 保留需要文件
将 rfmri 的 4D 文件存放到一个文件夹,将 coT1存放到一个文件夹。便于进一步 分析
3. BET—co_T1
Bet co*.nii >> co*_brain.nii.gz
详细步骤另一篇文章再介绍
https://blog.csdn.net/machinelearning_er/article/details/82703176
4. 检查
使用Fslview 查看个体 coT1 的 bet 结果,若脑壳基本剥干净,则认为 bet 结果好。否则,需要重新 bet。
5. 获取数据路径 txt文件
T1_path.txt : 所有个体 bet 后 coT1 的文件路径
rfmri_path.txt :所有个体静息态数据的 4D 文件路径
注意:两个 txt 中个体序号一致
这里可以使用shell:
! bin/sh
for i in /.../*.nii.gz
do echo $i >>/.../t1_input.txt
done
三. 独立成分分析(FSL:MELODIC ICA)
1.准备
所有被试的 4Drfmri 数据路径,bet 后的 coT1 路径:T1_path.txt、rfmri_path.txt
新建文件夹作为 ICA 输出位置: ic25
2.设置(未声明则为默认)
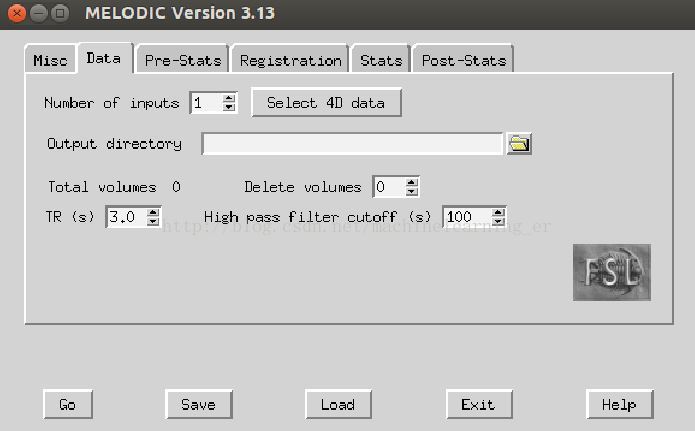
》Data:
Inputs:所有人 rfmri 数据(rfmri_path.txt 内容粘贴)
Outputs:输出路径(自定义)
Delete:4-10 个初始 volumes
TR:2.0 (取决于机器扫描)
Highpass cutoff:150 s = 1/150hz≈0.007Hz(低通滤波器)
》Pre-stats
Slice timing correction:interleaved(根据扫描方式决定,故与数据有关)
Bet:选择,对功能数据 bet
FWHM:6
Highpass:不选
注:头动校正设定默认算法(MCFLIRT)。
》Registration
选择 main structural image
输入:所有人 bet 后的 coT1 数据(T1_path.txt 内容粘贴)
Linear:normal search 6DOF Standard space:
Mask:MNI152_T1_2mm_brain.nii.gz
Lineal:full search 12 DOF
Resampling resolution:2mm
》stats
设定 output components:25(希望产生的成分数量)
选择 multi-session temporal/concatenation
3.运行
点击“GO”,则开始 ICA。
会在大路径》ica》ic25 产生 ic25.gica
rfmri 数据路径下,产生个体的 subject_ic25.ica,包含预处理后的结果。
浏览器跳出 report,显示 运行状态。
四.挑选成分
1.初步筛选
所有成分与模板成分做空间相关,相关值越大,则空间重合度越 高,认为该成分对应模板成分。(可不做,只人眼分辨)
2.fslview
人眼核实筛选成分
打开 fslview:对于每个 PNAS 成分,滑动 melodic_IC 不同 volumes,记录哪个 volume
成分与模板对应。
3.整理
根据两次筛选结果,确定每个 PNAS 模板,对应成分。
注:查看关注的网络,若成分与之对应情况不好,则跑一些别的成分个数。
五. 双回归(Dual Regression)
1.设计矩阵:
终端输入Glm,或fsl -> Misc -> GLM Setup
选择 High level/non-timeseries design,two-sample unpaired (配对人数也可选该项), 第一组输入为单组人数。
Group Group1 Group2
1 1 0
1 1 0
1 1 0
2 0 1
2 0 1
2 0 1
Contrast 部分如下表:
contrast
g1>g2 1 -1
g1<g2 -1 1
“g1>g2”为第一组被试大于第二组被试,“g1<g2”为第一组被试小于第二组被
试。
新建文件夹 DUAL 作为双回归结果存放位置。将矩阵存放到 DUAL,并以 glm 命名:DUAL/glm。理论上,该矩阵可用于本组数据的每次 ica 的双回归,使用时修改好路径就可以啦。
注:设计矩阵时,分组以及数据排列顺序 要与 txt 中功能数据,要保持一致。
2.产生data_all.txt
将 rfmri 路径下每个人的 ic25.gica 下 reg_standard 下 filtered_func_data.nii.gz 功能数据路径写入data_all.txt。
shell如下:
#! bin/sh
for i in /home/dell2/Desktop/gene_new/run3/*25.ica
do echo $i/reg_standard/filtered_func_data.nii.gz >> /.../data_all2.txt
done
3.运行双回归
在 DUAL 下打开终端(或终端 cd 到矩阵路径) 输入:
dual_regression /.../*.gica/groupmelodic.ica/melodic_IC.nii.gz 1 glm.mat glm.con 5000 dual_results `cat /.../data_all.txt`
注:在终端中输入dual_regression查看具体释义,产生结果每个成分的双回归结果,stage3*IC*corrp*stats*
六.查看双回归结果
1.结合挑选出的网络,整理对应双回归结果
mask 》 复制挑选出的 10 个成分
g1_g2》 10 个成分对应的*corrp*stats1
g2_g1》 10 个成分对应的*corrp*stats2
2.将挑选出的[2.33,10]为阈值的网络,作为模板,得到有用区域的双回归结果dual_mask_corr.mat
3.查看双回归结果
mask 》复制挑选出的 10 个成分
g1_g2》10 个成分对应的 stats1
g2_g1》10 个成分对应的 stats2
after 》g1_g2、g2_g1》十个双回归结果,顺序与 mask 对应。
使用 fslview查看每个mask,add after下两个对应成分的双回归结果,阈值 0.95-1


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









