







Q1: 出现下面的问题怎么解决?
2011-12-26 11:44:21 worker [ERROR] Error on initialization of server mk-worker
java.lang.UnsatisfiedLinkError: /usr/local/lib/libjzmq.so.0.0.0: libzmq.so.1: cannot open shared object file: No such file or directory
at java.lang.ClassLoader$NativeLibrary.load(Native Method)
at java.lang.ClassLoader.loadLibrary0(ClassLoader.java:1767)
at java.lang.ClassLoader.loadLibrary(ClassLoader.java:1692)
at java.lang.Runtime.loadLibrary0(Runtime.java:840)
at java.lang.System.loadLibrary(System.java:1047)
at org.zeromq.ZMQ.<clinit>(ZMQ.java:34)
at java.lang.Class.forName0(Native Method)
at java.lang.Class.forName(Class.java:186)
at zilch.mq__init.load(Unknown Source)
at zilch.mq__init.<clinit>(Unknown Source)
at java.lang.Class.forName0(Native Method)
at java.lang.Class.forName(Class.java:264)
at clojure.lang.RT.loadClassForName(RT.java:1578)
at clojure.lang.RT.load(RT.java:399)
at clojure.lang.RT.load(RT.java:381)
at clojure.core$load$fn__4511.invoke(core.clj:4905)
at clojure.core$load.doInvoke(core.clj:4904)
at clojure.lang.RestFn.invoke(RestFn.java:409)
at clojure.core$load_one.invoke(core.clj:4729)
at clojure.core$load_lib.doInvoke(core.clj:4766)
at clojure.lang.RestFn.applyTo(RestFn.java:143)
at clojure.core$apply.invoke(core.clj:542)
at clojure.core$load_libs.doInvoke(core.clj:4800)
at clojure.lang.RestFn.applyTo(RestFn.java:138)
at clojure.core$apply.invoke(core.clj:542)
at clojure.core$require.doInvoke(core.clj:4869)
at clojure.lang.RestFn.invoke(RestFn.java:422)
at backtype.storm.messaging.zmq$loading__4410__auto__.invoke(zmq.clj:1)
at backtype.storm.messaging.zmq__init.load(Unknown Source)
at backtype.storm.messaging.zmq__init.<clinit>(Unknown Source)
at java.lang.Class.forName0(Native Method)
at java.lang.Class.forName(Class.java:264)
at clojure.lang.RT.loadClassForName(RT.java:1578)
at clojure.lang.RT.load(RT.java:399)
at clojure.lang.RT.load(RT.java:381)
at clojure.core$load$fn__4511.invoke(core.clj:4905)
at clojure.core$load.doInvoke(core.clj:4904)
at clojure.lang.RestFn.invoke(RestFn.java:409)
at clojure.core$load_one.invoke(core.clj:4729)
at clojure.core$load_lib.doInvoke(core.clj:4766)
at clojure.lang.RestFn.applyTo(RestFn.java:143)
at clojure.core$apply.invoke(core.clj:542)
at clojure.core$load_libs.doInvoke(core.clj:4800)
at clojure.lang.RestFn.applyTo(RestFn.java:138)
at clojure.core$apply.invoke(core.clj:542)
at clojure.core$require.doInvoke(core.clj:4869)
at clojure.lang.RestFn.invoke(RestFn.java:409)
at backtype.storm.messaging.loader$mk_zmq_context.doInvoke(loader.clj:8)
at clojure.lang.RestFn.invoke(RestFn.java:437)
at backtype.storm.daemon.worker$fn__3102$exec_fn__858__auto____3103.invoke(worker.clj:111)
at clojure.lang.AFn.applyToHelper(AFn.java:187)
at clojure.lang.AFn.applyTo(AFn.java:151)
at clojure.core$apply.invoke(core.clj:540)
at backtype.storm.daemon.worker$fn__3102$mk_worker__3244.doInvoke(worker.clj:80)
at clojure.lang.RestFn.invoke(RestFn.java:513)
at backtype.storm.daemon.worker$_main.invoke(worker.clj:257)
at clojure.lang.AFn.applyToHelper(AFn.java:174)
at clojure.lang.AFn.applyTo(AFn.java:151)
at backtype.storm.daemon.worker.main(Unknown Source)
2011-12-26 11:44:21 util [INFO] Halting process: ("Error on initialization")
A1:sudo vi /etc/ld.so.conf 在该文件添加一行“/usr/local/lib”, 保存以后,执行“sudo /sbin/ldconfig”就可以fixed这个问题。
Q2:Storm选择使用kestrel而不是zeromq的原因?
A2:ZeroMQ is basically a socket library. If you want to pass data between
topologies, you have two things you need to solve:
1. Discovering where to send the tuples (since Storm can launch the
spout tasks anywhere on the cluster, and their locations can change
over time)
2. Guaranteeing message processing on the second topology
If you use a Kestrel queue (or queues) as the intermediate broker,
that solves #1 because you're using a fixed set of machines that both
topologies know about. It solves #2 because Kestrel persists the
messages and is capable of replaying the messages.
You want to make sure that your spout source can support the out of
order acking that Storm requires for guaranteed message processing. We
use Kestrel because it has this property and is the simplest.
Q3:Storm如果避免发生拥塞?
A3:暂时Storm没有好的方法来控制这个,但是对于保证数据可靠性的topology而言,可以通过TOPOLOGY_MAX_SPOUT_PENDING来对spout进行一些控制;
另外只能靠增加处理速度慢的bolt的并行度或者是减少spout的并行度来调节数据流拥塞问题了。
Q4:关于Storm UI上spout complete latency的一些疑问
. complete latency是如何计算的?
. 对于一个topology而言,理想的complete latency是多少?
. 在实现topology的时候,如果能够保证尽可能小的latency?
A4:
1. The timer is started when the tuple is emitted from the spout and it is
stopped when the tuple is acked. So it measures the time for the entire
tuple tree to be completed.
2. There's no "ideal" time. Every topology has different characteristics.
For example, in our stream processing topologies we care more about
throughput than latency and make use of batching techniques that increase
throughput at the cost of worsened latency. In our distributed RPC
topologies however, we optimize for latency.
3. The completion time will be affected by: a) the processing latency of
the bolts, which you can improve by doing optimization b) the amount of
congestion in the topology, which you can reduce by increasing parallelism.
So if you add up the processing latencies of the bolts and they don't come
close to the complete latency, you should try adding more parallelism.
Q5:为保证数据可靠性,spout acker需要知道哪些东西?
A5:
First, you need to tell Storm whenever you're creating a new link in the tree of tuples.
Second, you need to tell Storm when you have finished processing an individual tuple.
如果你的bolt实现的是IRichBolt接口,这两件事情需要你自己亲自去做;但是如果你继承的是BasicBolt, 则它会偷偷
的帮助你去做这两件事情,所以当你需要unanchored的时候,则不要使用BasicBolt
Tuples emitted to BasicOutputCollector are automatically anchored to the input tuple, and
the input tuple is acked for you automatically when the execute method completes.
Q6:针对Storm DRPC的几个问题?
1) If the drpc server configure as follows, then i need run "./bin/storm drpc" on all of these servers?
> drpc.servers:
> - "10.13.41.104"
> - "10.13.41.64"
> - "10.13.41.98"
2)I need use storm jar summit the topology to storm first, then write a application using DRPCClient to call "execute" ?
3)If i can give more than one hosts to DRPCClient?
DRPCClient client = new DRPCClient("drpc-host", 3772);
A6:
1)Yes, you do.
2) Yes.
3)No, you can't. DRPCClient can definitely be improved (or a higher level one
can be written on top of it).
Q7:关于Storm UI(perftest)的几个问题? (基于http://groups.google.com/group/storm-user/browse_thread/thread/822be41e58fed298)
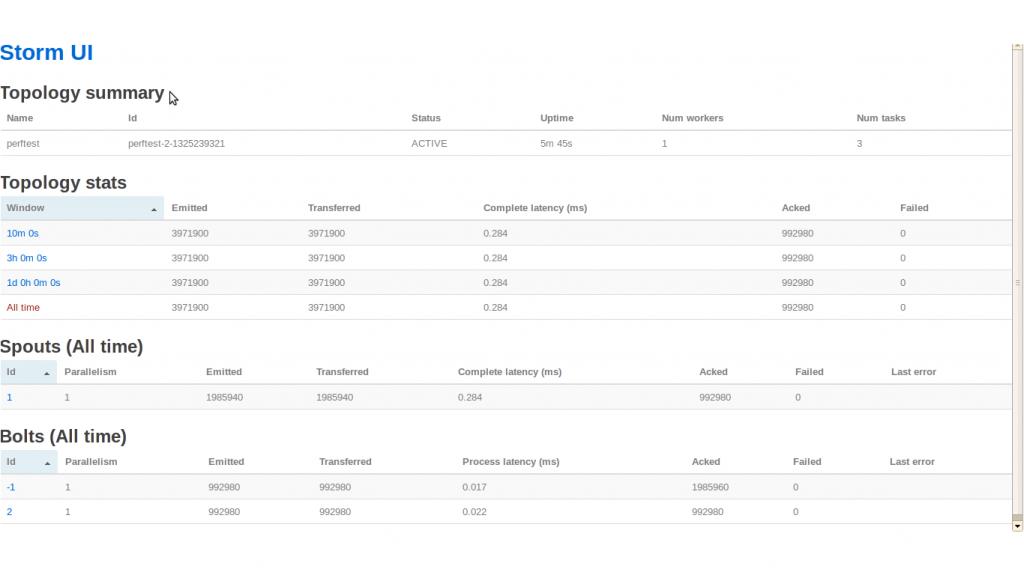
1) 为什么topology只定义了一个bolt,但是在storm UI的Bolts下面还有一个Id为-1的,代表什么意思?
2)PrinterBolt并没有调用emit,为什么还会有Emitted呢?
3)Spouts的Emitted为1985940, 而bolt Id 1的Emitted是992980,是因为bolt没有追上spout的emit速度吗?
A7:
1) That's the "acker bolt" which takes care of tracking tuple trees. It's an
integral part of guaranteeing message processing, and is described in the
wiki here:
https://github.com/nathanmarz/storm/wiki/Guaranteeing-message-processing
In 0.6.0 that bolt was renamed to "__acker"
2)It's emitting ack tuples on its "ack" stream that go to the acker bolt.
3)Notice that the emitted value of spout 1 is just about double the emitted
value of bolt 2. This is because for every tuple spout 1 emits, it sends a tuple to bolt 2
as well as a tuple to the acker bolt (to track the tuple tree). Bolt 2 only
acks tuples so it sends a single ack tuple per received tuple.
Storm Google Group是个提问题的好地方,Storm作者很nice,多上那边逛逛吧!















 2444
2444

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









