







进程级别的逗号处理,直接top就可以了.但是线程级别的CPU load飙升处理起来相对而已比较麻烦.
好, 直接上脚本:
#!/bin/ksh
typeset top=${1:-10}
typeset pid=${2:-$(pgrep -u $USER java)}
typeset tmp_file=/tmp/java_${pid}_$$.trace
$JAVA_HOME/bin/jstack $pid > $tmp_file
ps H -eo user,pid,ppid,tid,time,%cpu --sort=%cpu --no-headers\
| tail -$top\
| awk -v "pid=$pid" '$2==pid{print $4"\t"$6}'\
| while read line;
do
typeset nid=$(echo "$line"|awk '{printf("0x%x",$1)}')
typeset cpu=$(echo "$line"|awk '{print $2}')
awk -v "cpu=$cpu" '/nid='"$nid"'/,/^$/{print $0"\t"(isF++?"":"cpu="cpu"%");}' $tmp_file
done
rm -f $tmp_file现在我们就来拆解其中的原理,以及说明下类似脚本的适用范围。
1.使用top命令查看飙高的java进程,记录pid
2.通过jstack命令将java的线程栈输出,保留现场 jstack -l 30142 > 30142.stack
3.找到当前CPU使用占比高的线程,通过 ps H -eo user,pid,ppid,tid,time,%cpu –sort=%cpu
USER:进程归属用户,PID:进程号,PPID:父进程号,TID:线程号
%CPU:线程使用CPU占比(这里要提醒下各位,这个CPU占比是通过/proc计算得到,存在时间差)
4.合并相关信息,通过PS拿到了TID,可以通过进制换算10-16得到jstack出来的JVM线程号
typeset nid=”0x”
(echo"
line”|awk ‘{print $1}’|xargs -I{} echo “obase=16;{}”|bc|tr ‘A-Z’ ‘a-z’)
5.最后再将ps和jstack出来的信息进行一个匹配与合并。终于,得到我们最想要的信息
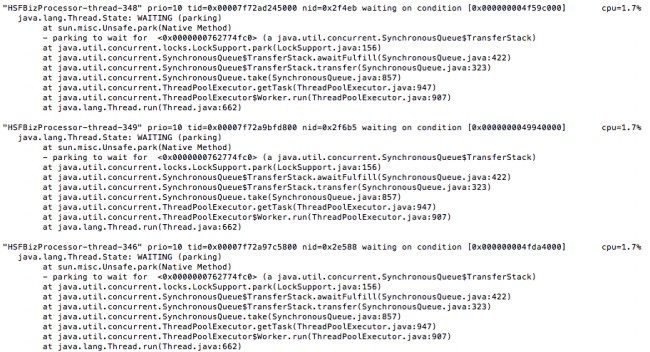















 2768
2768

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









