






2025
LIFE
趣 / 闻 / 轶 / 事
近日拿起手机,经常被霸屏的当属某红色软件,不是淘某、不是拼某某、更不是阿里某某,而是小某书。只要打开软件首页,不多会就能刷到一大批外国IP的动态,不是英语老外的个人自拍,就是举着猫猫和狗狗说来交猫税狗税的,再就是用蹩脚的机翻中文来对账、求助甚至帮忙做英语和中文作业的社交帖。

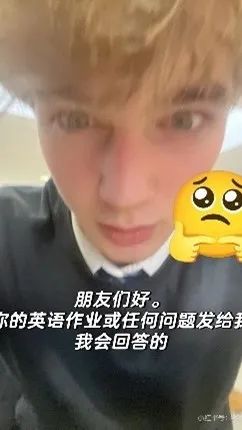

要不是自己一直有小某书的账号,并且反复确认IP,还真的怀疑这里变成了国外友人的大型认亲现场。这给我干哪来了,还是国内嘛?一眨眼,自己这app突然变得这么international了,一时之间还真有点unbelievable捏~。

为了融入原住民社区,老外们小心谨慎,操着一口生硬的中文,伴随英文双语介绍,用词之严谨、语气之诚恳,估计把小时候刚学写作文的态度都给拿出来了,生怕因为用词不当引发误会,惹到原住民的讨厌。为了防止机翻引起误会,还贴心的加上英文原文,来表现自己的诚恳。
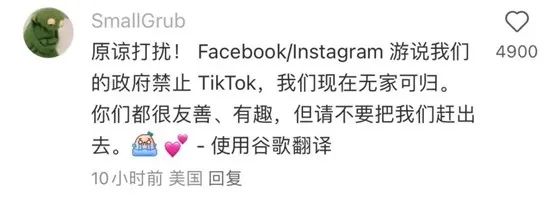

后来大家发现,表情包才是精准表达情绪的神奇。于是位于东西两个半球的两方人马,展开了表情包分享大会,蹩脚的机翻中文,和机翻英语配合着搞笑的表情包,充斥着每一个外国交友贴的下方评论区。
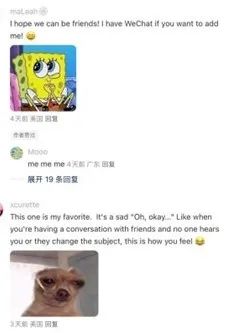


在看乐子和找乐子的同时,我也发现了一个问题。虽然评论区绞尽脑汁用英文回复和用翻译器自动翻译中文的语句很搞笑,但是也会让人摸不着头脑。像我为了能更清楚的了解问题都是直接看英文原文,但是只要点开右上角自动翻译,看到的中文和原意总是有些出入。那么为什么机翻总是词不达意呢?有没有人会好奇机翻的原理是什么?为什么基础的翻译和语气词AI都可以做到,但是稍难一些的词汇,就容易语序错乱,让人二丈摸不到头脑呢?
那么就由我来给大家好好说道说道叭~

S
N
◀
目前现有的两种机器翻译方式有:规则法和统计法。
▶
01
规 / 则 / 法 (RBMT)
依据语言规则对文本进行分析,再借助计算机程序进行翻译。它的运作需要三个连续的阶段来实现:分析,转换和生成,根据这三个阶段的复杂性分为三级。第一级,直接翻译:简单词语的直给;

直接翻译
第二级,转换翻译:翻译过程需要参考原文的词汇、语法和语义的信息,因为信息来源过于宽泛,像有的词汇有多种意思,比如cell,有细胞、单元和监狱的意思,笔者在读文献的时候,经常能看到翻译器把单胞翻译成细胞的。而且语法规则很多并且之间存在矛盾和冲突,所以转换翻译非常复杂且容易出错(别说机器了,有的语法人都读不懂,计算机真的会崩溃好嘛!!!)。
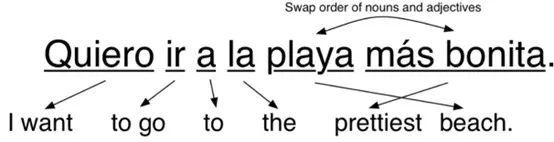
转换翻译
第三级,目前还只是个设想,国际语翻译,大概就是凭借通用的完全不依赖语言的形式,实现对语言的解码,难度相当于让计算机读懂表情包(>_<),这样是不是理解到底有多不切实际了吗?
02
统 / 计 / 法 (SMT)
通过对大量的平行语料进行统计分析,构建统计翻译模型(词汇、比对或者是语言模式),然后使用这种模型进行翻译,选取统计中出现概率最高的词条作为翻译,概率算法依据贝叶斯定理。
要想实现这种方法,我们需要拥有大量的训练数据,其中完全相同的文本要被翻译成至少两种语言,这总双重翻译的文本被称为平行语料库。18世纪的时候,科学家在罗塞塔石碑上发现了用希腊语、象形文字、古埃及文字和当时通俗体文字写的古埃及国王托勒密五世登基的诏书,根据不同语言版本内容的对照,科学家得以解读失传已久的埃及象形文字的意义和结构,这就是计算机统计法翻译的前身。
我试着解释一下,如果读者有更好的看法,也可以直接在下面写出来,统计翻译系统的原理是用概率的思维进行思考,他不是试图生成一个精确的翻译,而是生成成千上万中可能的翻译,然后按照最可能正确的来给这些翻译排名,通过与训练数据的相似性,来判断到底有多正确。
工作原理
NO.1 将原始句子分成块
首先,先把我们的句子分子简单的几块,让每一块都能够轻松的翻译,那么根据是以词为依据,还是短语为依据,SMT被分为了基于词的SMT和基于短语的SMT两种,大多数的翻译引擎都是基于短语,翻译文本会自动分为固定长度的短语。





NO.2 找到每一块的所有可能的翻译
我们寻找数据库中所有人类翻译过的相同的词块,并根据它们不同的出现概率(A)来进行罗列。在这个过程我们找到的不是字典里的直给翻译,而是真实的人在真实的句子中如何翻译这些相同的词,这有助于我们捕获到在不同语境中的所有不同表达方式。
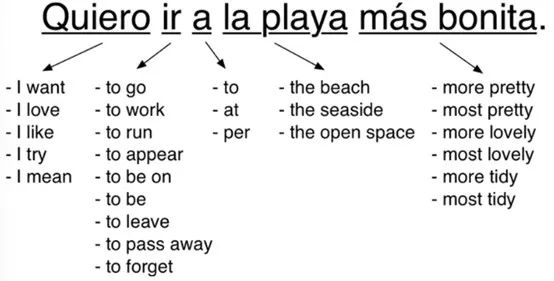
可以看到即使是短语也有很多可能的翻译。而在这些多种翻译中,一些翻译的使用频率远比其他的高,我们用使用频率来给它们赋予数值,记为概率A。比如I’m dying 在中文中大多数被翻译成“我想要”而不是“我倾向于”,那么在使用的训练库中,它被翻译成“我想要”的概率就比“我倾向于”大,就会获得更高的权重。




NO.3 生成所有可能的句子,找到最合适的一个
我们将第二步中给出的所有翻译来进行排列组合,生成了将近2500个句子,比如:
I love | to leave | at | the seaside | more tidy.
I mean | to be on | to | the open space | most lovely.
因为在真实世界中,不同语序和词块分解方式还有很多种,所以实际上的可能翻译句子会更多。接下来的一步,就是扫描这些句子,找到看起来“最像人说”的那一个。通过与新闻故事和英文书籍的各种真实句子来对比,我们给这些句子打分,记为概率B。得分最高的就是我们认为最准确的句子翻译:I try | to leave | per | the most lovely | open space.
当然也有可能没有人写过这样的句子,那么它就不会和数据库中的任何句子相近,我们给这个可能的翻译设定一个低概率的得分。经过第二步和第三步的循环检索,我们会选择那个A和B概率都高的翻译,这样它既是最可能的词块翻译,又与真实的句子最相似。最终我们得到的翻译结果就是“I want | to go | to | the prettiest | beach.”我想去最漂亮的海滩。
统计法是绝大多数在线搜索引擎所使用的翻译方法,比如百度、必应和谷歌,它们都是以自己庞大的数据库和超强的搜索能力,来进行翻译。一些其他的非开源的机器翻译也多是使用统计法模式进行的。(希望到这里大家应该还没有晕吧~)

根据两种方法的对比,我们可以发现,规则法其实就是人们翻译外语的方式,但是机器显然没有人类的灵活性,所以面对复杂的语法和冗杂的规则矛盾,机器翻译的结果往往差强人意。统计法则更偏向于概率法,这种运算方式则更适用于机器运算,因为相比较直给翻译,机器更擅长做的是数据分析和统计,这也是各大搜索引擎采用统计法的原因。
不过虽然统计机器翻译系统效果还不错,但是它们难于构建和维护。每一对需要翻译的新语言,都需要专业人士对一个全新的多步骤“翻译流水线”进行调试和修正。因为构建这些不同的流水线需要非常大的工作量,所以幕后的程序员必须权衡。如果你用Google翻译想把印度泰卢固语翻译成中文,那么作为一个中间步骤,它就可以先翻译成英语,然后再翻译成中文。因为可能人们对于印度泰卢固语对于中文的直接翻译需求没有这么高,在这一对语言上投入太多精力和财力没有太大意义。相比于英语和中文这一对,印度泰卢固这种存在于印度一个小地区的语言,可以采用一个更低级的“翻译流水线”。
基于以上的解读,我们翻译引擎基本的工作原理已经清晰的向大家阐述清楚了,这么一想,虽然有时候翻译软件翻译句子可能让两国人都看不太懂,但是人类最大的优势是什么?当时是蒙啊(bushi),当然是对于语句的联想和猜测。依靠计算机给出的大致方向,结合人类大脑的联想功能,我们就可以自己破解对方想要表达的大致意思。
就比如绿泡泡,不用我说大家也知道我说的是啥吧,还有红薯、某桃、PDD这些就是相当于先给出一个大致的方向,然后让人去联想猜测可能的结果,然后得出正确答案的过程。所以不用担心交流的问题啦,即便翻译的不准确,但其实对于交流的影响也没有辣么大啦,实在不行不是还有表情包咩~
无论形势怎么变化,中外网友对对方的好奇心都在证明,友善真诚永远是必杀技。中英混杂,东西交融,交流友好而又真诚,这或许才是地球村最原本的样子。虽说这场数字文化的“东游记”能持续多久,我们不得而知。不过有先见之明的人,已经开始找老外注册PDD新用户帮忙砍一刀了。
- END -
马上就要新年了,不如让这些外国友人见证一下中国这场盛大热闹的传统节日!!我也在这里预祝各位春节快乐,多发paper。
编辑:蓝多多

我们是谁:
MatheMagician,中文“数学魔术师”,原指用数学设计魔术的魔术师和数学家。既取其用数学来变魔术的本义,也取像魔术一样玩数学的意思。文章内容涵盖互联网,计算机,统计,算法,NLP等前沿的数学及应用领域;也包括魔术思想,流程鉴赏等魔术内容;以及结合二者的数学魔术分享,还有一些思辨性的谈天说地的随笔。希望你能和我一起,既能感性思考又保持理性思维,享受人生乐趣。欢迎扫码关注和在文末或公众号留言与我交流!


扫描二维码
关注更多精彩
完美洗牌的秘密(二十一)——milk shuffle的应用三(天天四条龙等)
2024阿里巴巴全球数学竞赛决赛中的数列题解析(分析与方程方向第4题)

点击阅读原文,往期精彩不错过!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









