








几个方面改进工作:
(一)改变代价函数,或输出函数,使用cross-entropy作为代价函数
(二)四种规格化方法 regularization(L1 and L2 regularization, dropout, and artificial expansion of the training data)
(三)更好的神经网络权值w初始化方法
(四)一系列启发式参数选择方法
1.cross-entropy代价函数
原来使用 最小二乘距离quadratic cost作为代价函数,有一个缺陷:其学习率受到 delta函数导数的影响(delta函数为sigmoid函数)
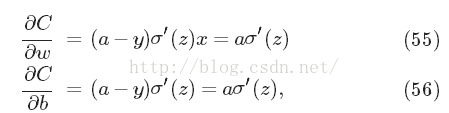
sigmoid 函数导数的图像是中间高,两头低,因此,如果z靠近0,或1,那么学习率很慢。
于是引入了cross-entropy代价函数

首先它符合代价函数的要求:(1)永远都是非负的,每一项的值都是0-1之间 (2)如果实际输出接近所要的输出,那么熵值为0. 比如 a=y=1或者 a=y=0,熵值都为0.
接下来就要说为什么要引入cross-entropy代价函数,它的好处?先看它的偏导(涉及学习率问题)
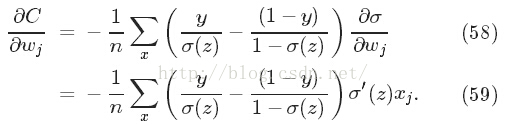
简化之后发现:
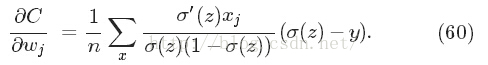
而delta函数为sigmoid函数,其导数为

与式(55)对比,这里的学习率不受偏导影响。
而事实也证明了cross-entropy的好
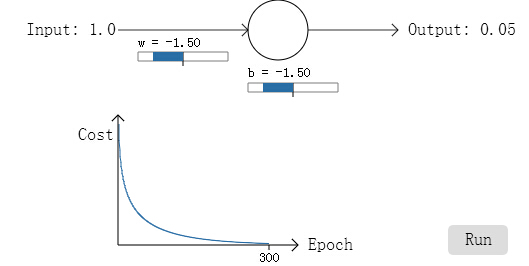
代价下降的很快。
如果将quadratic cost拿来对比的话:(下图)
好坏一看就很明显了。
下面介绍另外一个输出函数Softmax (之前是sigmoid),每一个activation定义为

因此,所有activation之和一定为1.
为什么叫Softmax?因为本来exp指数上面是可以乘以一个常数C,但是C如果无穷大,会有什么结果呢?所以取C=1,作为它的一个退化Softened形式,由此得名。
为什么引入Softmax函数呢? 首先softmax函数是关于z单调的,然后每个activation结果是受到全局w影响,也就是知道了aj虽然大,如果另外一个更大,那么它就变小了。相对大小。 这样,进行分类(以数字识别为例),概率最大的那一项j就识别为J.
同样,为避免学习率下降,这里用了另外一个代价函数 C=-ln a. 概率大的代价接近于0.
2.过拟合和正则化
神经网络要学习的参数太多,这样通常就会碰到过拟合问题。 一个办法就是:增加学习的样本。另外一个方法就是正则化
正则化
过拟合出现的原因是学习参数过多,能不能在建立神经网络时少设定一点呢?比如隐含层设定为10以内?答案当然是不可以,神经网络之所以有如此强大能力,就在于其大的网络。那么怎么办? 正则化!!!
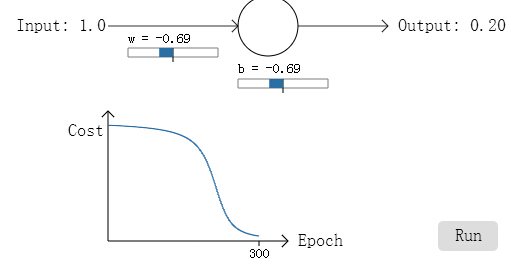
首先想到的是将L2范式加到原代价后面,称之为L2正则化。限定w的大小,在代价函数和 w大小之间取个平衡。(lambda称之为平衡因子或 正则化参数)
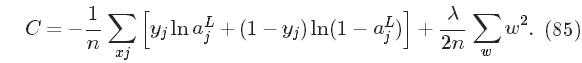
虽然感觉假如L2正则只能让w尽量取小,并不能达到减少参数的目的。但实验证实,L2确实可以降低过拟合,【博主自己猜测:大概是w尽可能小,所以很多w约等于0吧。】
我们先看看加入正则化项后,其如何学习的吧,首先仍然是偏微分(w部分多了一项,b仍然与之前相同)
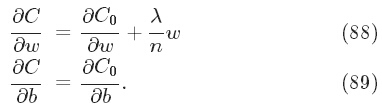
那就学习吧,不断更新w(如下)


实验结果证实了测试数据并没有产生过拟合现象(达到饱和又下降)。

神经网络的参数非常巨大,而通常训练样本并不比所要学习的参数多,那么为什么神经网络还是可以发挥功效呢?
很难回答,只有这样的猜测:多层神经网络的梯度下降学习方法拥有“自规则化”的作用。
还有其它一些规则化方法:L1规则化,
Dropout: 在隐藏层中随机 屏蔽部分神经元,计算梯度,更新权值;然后不断重复这个过程。
为什么它能规则化,防止过拟合? 其作用相当于多个神经网络,然后结果进行投票或取平均。这样就可以减少过拟合(不同神经网络以不同方式过拟合,平均可减少过 拟合)
人工合成训练数据:既然训练数据扩大可降低过拟合,那么就合成训练数据。
通过旋转一定角度,缩放等elastic distortions。
3.权重初始化方法
之前使用高斯随机初始化权重w 和偏置b,这样的初始化有一个问题,即 z=w*x+b的值 形成一个方差很大的正态分布,这意味着很可能z>>1或者z<<-1,那么它从一个很远的起点开始学习,学习的进程会比较慢。如何改变呢?
这里使用均值为0,方差为1/sqrt(n_m)的高斯分布随机w权值。那么z 的方差为sqrt(3/2),是比较尖锐的高斯分布了,意味着z一般并不大,这样学习的起点就比较好了。

事实也证明了,学习的起点设置相对之前要好很多。
4.怎样学习神经网络的超参数?
学习率elta,规则化参数lambda等等。
(1)Broad strategy: 设定的参数,实验结果不对劲,那么先简化(比如原来识别10个数字,现在只识别2个,训练数据,验证数据等简化,可以提高实验速度)
然后根据数据规模重新设定参数;如果识别率一直很低,改变学习率(变快,或变小);然后再慢慢不断调整
(2)学习率:运行不同学习率下的结果,理想的学习率应该 先降低然后保持平稳。
(3)Use early stopping to determine the number of training epochs提前终止:利用validate data在哪个epoch停止变化,就在哪个epoch作为number of training。
(4)Learning rate schedule学习率规则:类似(3)等到学习率使得结果变得更坏的时候,终止
(5)The regularization parameter规则化参数:建议先从0开始,然后 1,然后 以10的倍数变大或变小。
(4)Mini-batch size小块
(5)Automated techniques自动技术: 其中一个grid search
5.其他技术
(1)随机梯度下降的变种: a)Hessian技术 b)基于动量的梯度下降 c)其它
(2)人工神经网络的其它模型: a)tanh函数代替sigmoid. b)线性修改神经元 max(0,w⋅x+b).















 543
543

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









