









参考论文:S. J. Pan and Q. Yang, “A Survey on Transfer Learning,” in IEEE Transactions on Knowledge and Data Engineering, vol. 22, no. 10, pp. 1345-1359, Oct. 2010, doi: 10.1109/TKDE.2009.191.
笔者注:本文是迁移学习领域的一篇Survey,学习目标为通过论文阅读初步了解迁移学习的原理以及具体应用的场合。并寻找与跨场景轨迹预测相应的方法。
论文理解阅读
0. Abstract
a.机器学习和挖掘技术成立的假设前提为训练与测试的数据在相同的特征空间中,并且具有相同的数据分布;
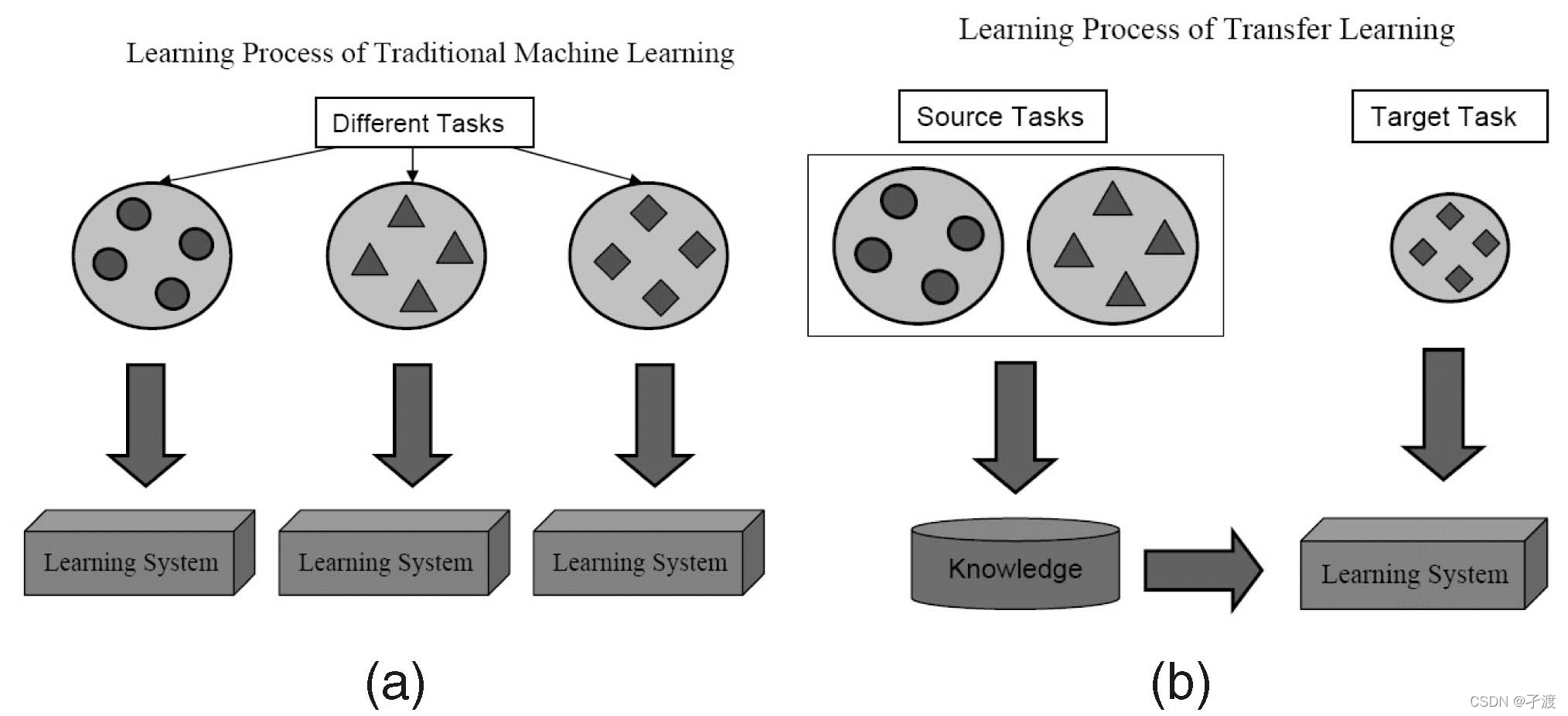
b.知识迁移可以避免大量的数据标注工作,极大地提高学习效率(这也是跨场景轨迹预测选择使用迁移学习方法的重要原因),下图为传统学习与迁移学习的差异
1. Introduction
a.当分布发生改变时,绝大多数统计模型需要从头开始使用新收集的训练数据进行重建;
b.全文编写顺序为总体回顾,定义符号,简要回顾历史,给出统一定义,将迁移学习分为三类,对每一类给出不同的方法;第六节回顾负迁移;第七节介绍成功应用
2. Overview
2.1 A Brief History of Transfer Learning
a.演变过程中的不同名称:learning to learn, life-long learning, knowledge transfer, inductive transfer, multitask learning, knowledge consolidation, context-sensitive learning, knowledge-based inductive bias, metalearning, and incremental/cumulative learning;
b.multitask learning本质:在多个同时学习的任务中找有利于每个单独任务的共同特征;
c.现代意义上的transfer learning定义:一个系统识别并应用之前任务中学习到的知识以及技能在新的任务中的能力;
现代意义上的transfer learning与multitask learning的区别在于;multitask强调任务的同时性,即意味着任务之间关系是平等的;而transfer则是在源任务中提取知识,应用于目标任务,source和target之间作用不对称。
2.2 Notations and Definitions
(此处由于描述复杂,直接贴原文)


a.transfer learning定义:

其中Ds与Dt不相等表示两个领域存在不同,或者两者的边际分布不同。以文档分类为例,这种情况相当于源文档与目标文档使用的语言不同;或者是专业领域不同导致词向量的分布不同;Ts与Tt不相等表示目标任务中的标签空间不同(如原任务是二分类问题,而目标任务是三分类问题)或者用户定义类中源领域和目标领域分布及其不平衡(这个不平衡可能指的是原领域中以中文为主,目标领域以日文为主)。
PS:若两个域的特征空间存在显式或隐式关系时,我们称原领域和目标领域是相关的。
2.3 A Categorization of Transfer Learning Tech-niques
a.关注三个问题: What to transfer; How to transfer; When to transfer;
b.When to transfer问的是在哪一种情况下,应该使用迁移学习。在某些情况下,当源域和目标域彼此不相关时,暴力转移可能失败(负迁移);
c.根据原域任务和目标域任务的不同情况,划分为如下表格:
d.inductive transfer learning setting:源任务和目标任务存在差异,需要目标域中提供一些标签数据来生成一个用于目标域的预测模型; 此时根据源数据域中的标签分为两类:
(1)在源数据域中存在大量的标签数据,此时问题类似于multitask;
(2)在源数据域中没有标签数据(或是两者数据标记不同),此时问题类似于self-taught learning;
e.transductive transfer learning setting:源任务与目标任务相同,但是源域和目标域存在差异; 这种情况下,源域中存在大量标注了的数据,而目标域则没有,根据两者之间的情况分为以下两类:
(1)两域之间的特征空间不同;
(2)两域特征空间相同,但是边际分布概率不同,这种情况可以使用域适应,样本选择偏差和Covariate Shift;
f.unsupervised transfer learning setting:侧重于解决目标域中的无监督学习任务,如聚类、降维和密度估计;
g.不同的迁移学习方法及相关领域总结如下表:

h.根据what to transfer还可以分为四类:
i. instance-based transfer-learning:假设源域中的某些数据可以通过重新加权在目标域中被重用用于学习, 实例重加权和重要性抽样是这一背景下的两种主要技术;
j.feature-representation-transfer:学习目标领域的好的特征表示, 跨域迁移的知识会被编码到学习的特征表示中(好的特征指能降低两域差异以及模型误差的特征);
k.parameter-transfer:假设源任务和目标任务共享模型的某些参数或超参数的先验分布, 传递的知识被编码到共享参数或先验中;
l.relational-knowledge-transfer:基本假设是源域和目标域中的数据之间的某些关系是相似的, 要传递的知识就是数据之间的关系;
j.when to transfer & what to transfer: 
3. Inductive Transfer Learning
大多数使用迁移学习的方法其源域标记数据都是可以使用的,Inductive transfer需要目标域内的少量标记数据作为训练数据来诱导目标预测函数。
3.1 Transferring Knowledge of Instances
a.TryAdaBoost方法:假设两域特征与标签相同,但是数据分布不同, 则有些源域数据能够提供帮助,有些是“坏”数据,通过迭代重加权的方法提高“好”数据的权重。每一轮迭代过程中,模型在两域数据上训练基础分类器,在目标数据上计算误差。该模型在两域上更新错误实例的方法也存在不同;
b.其余机器学习方法……
3.2 Transferring Knowledge of Feature Representations
根据在源域中是否有大量可用的标记数据,来选择监督学习或者无监督学习等方法。
3.2.1 Supervised Feature Construction
a.与multitask类似,基本思想是在相关任务之间提供一个共享的低维表示。
b. sparse feature learning method:共同的特征可以通过解决一个优化问题来学习, 
该优化问题表达式还有进一步等价凸优化公式等变形;
c.一种凸优化算法, 能够相关预测任务中同时学习元量和特征权值。元粒子可以在不同的任务之间转移。
3.2.2 Unsupervised Feature Construction
a.sparse coding稀疏编码
b.其他方法……
3.3 Transferring Knowledge of Parameters
a.大多数针对归纳迁移学习设置的参数迁移方法都假设相关任务的单个模型应该共享一些参数或超参数的先验分布;
b.迁移学习中,不同领域的损失函数中的权重可能是不同的 (多任务学习下两域的损失函数权重是平等的,而迁移学习中相对来说目标任务的损失函数占比);
c.Gaussian Processes (GP);
d.SVM;
……
大致总结
该论文为近十年较为重要的一篇迁移学习的综述,从源头上定义了迁移学习,并且根据技术手段以及适用场景对迁移学习进行了分类。重点讲述了what to transfer和when to transfer 两个问题,至于how to transfer 的问题,在大致翻阅了文章的引文之后发现与笔者索要寻找的能够应用于计算机视觉方向深度学习的方法并不是很多,在粗略看过之后不再记录。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









