






 EnhanceNet算法是一种单图像超分辨率方法,通过自动化纹理合成提升图像质量。网络结构采用全卷积设计,利用VGG-19进行特征提取。损失函数包括像素级损失、感知损失、纹理匹配损失和对抗性训练。实验表明,结合多种损失函数的模型能生成更清晰且纹理丰富的图像。
EnhanceNet算法是一种单图像超分辨率方法,通过自动化纹理合成提升图像质量。网络结构采用全卷积设计,利用VGG-19进行特征提取。损失函数包括像素级损失、感知损失、纹理匹配损失和对抗性训练。实验表明,结合多种损失函数的模型能生成更清晰且纹理丰富的图像。
EnhanceNet算法介绍
一、论文
EnhanceNet:Single ImageSuper-Resolution through Automated Texture Synthesis[1]
二、算法介绍
2.1网络结构
网络结构采用全卷积的方式,使得输入图像可以是任意尺寸。受到VGG网络的启发,卷积核全部采用3*3的尺寸,在保持一定量参数的情况下构建更深的网络。网络的输入是低分辨率图像,在网络末端采用最近邻的方法上采样达到高分辨率图像的尺寸,这样有利于降低计算复杂度,参数的初始化采用Xavier,网络的学习目标是超分辨率图像与输入的低分辨率图像线性插值的差,整个网络架构如下图所示:
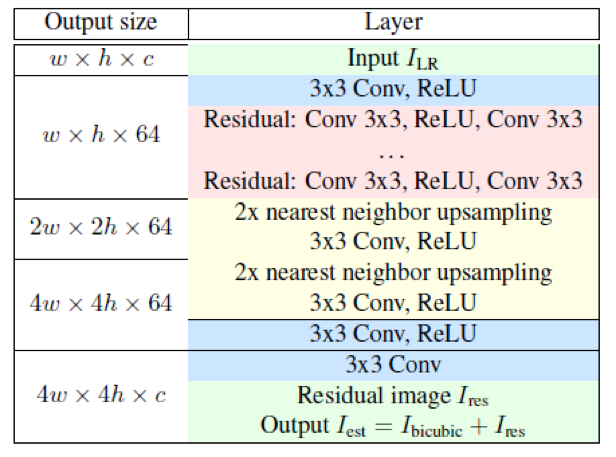
图一:EnhanceNet网络结构
2.2损失函数
在神经网络的训练过程中,选择不同的loss会对参数的训练结果产生很大的影响。因而loss的选择显得至关重要。
2.2.1 pixel-wise loss
Iest是网络的输出结果,IHR是图像的原始高分辨率图像。那么pixel-wise MSE定义为:
|
|
pixel-wise loss强调的是两幅图像之间每个对应像素的匹配,这与人眼的感知结果有所区别。通过pixel-wise loss训练的图片通常会较为平滑,缺少高频信息。即使输出图片具有较高的PSNR,视觉效果也并没有很突出。
2.2.2 perceptual loss
将Iest,IHR分别输入到一个可微分的函数Φ中,通过计算如下公式:
|
|
我们避免了要求网络输出图像与原始高分辨率图像pixel-wise上的一致,而是鼓励两幅图具有相似的特征。
对于函数Φ,这篇论文采用了预训练好的VGG-19网络,通过VGG-19网络来提取出图像的有效特征。为了提取出图像的高层和低层特征,我们使用VGG-19的第二和第五pooling层来获取图像的有效特征,在这基础上计算它们的MSE。
2.2.3 texture matching loss
texture matching loss 可以促进产生的图像具有更丰富的纹理信息。通过计算如下公式来计算texture matching loss:
|
|
其中G(F)=FFT,Φ是用于特征提取的函数(论文中采用了VGG-19网络)。
在具体的操作层面,基于patch来计算texture matching loss以此来保证纹理信息在局部上的一致。实验表明,patch大小选为16*16的像素时,效果最好。如果在整幅图上计算texture matching loss,由于纹理信息的多样性,必将导致平均化,效果会相应地变差。
2.2.4 Adversarial training
2.2.4.1GAN网络介绍:
生成对抗网络包含两个网络,其中一个是生成网络G,另一个是判别网络D。G用于接收噪声Z并通过G(Z;Θg)产生数据分布Pg,判别网络D(x;Θd)则是用来判断x来自于真实的数据分布Pdata还是Pg。两个网络通过不断地对抗学习,最终达到G网络产生的数据分布Pg=Pdata,此时判别网络D已无法分辨x来自于哪一个数据集。
D和G两者相互对抗,优化如下的最小最大公式:
|
|
其中的max指寻找最优的判别器D,min则是在此基础上优化生成器G,使得G产生的数据分布更接近Pdata,以致于迷惑D。
在具体的训练过程中,通常是优化判别器K次,才会优化生成器D一次。这样可以保证判别器D始终处于或接近最优。
在训练初期,由于Pg与Pdata相差太大,D可以很轻松地分辨出数据来自哪个数据集,导致不能够提供足够的梯度来训练G。通过将最小化log(1-D(G(Z)))改为最大化log(D(G(Z))),便可以获得足够的梯度来训练G网络。
2.2.4.2 Adversarial loss
利用GAN网络来实现超分辨率,首先把图一中的网络结构用于GAN网络中的生成网络G,G的目标是最小化:
|
|
对应的判别网络则是最小化:
|
|
将 作为adversarial loss来训练EnhanceNet有助于获得较好的训练效果。
其中,判别网络结构如下图所示:

图二:判别网络结构图
2.2.4.3训练细节
具体的训练方面,对于判别网络,采用leaky ReLU作为激活函数,strided convolutions来逐渐减少图像的空间维度。在整个判别网络的训练过程中,不采用dropout。当判别网络对IHR以及Iest的判别结果低于一定阈值的时候,才开始训练判别网络。
2.3不同损失函数组合的效果
将不同的loss计算方式结合在一起,训练结果也会相应地不同。图三中展示了不同的loss组合方式所展现的不同的超分辨率效果,其中E指MSE,P指perceptual loss,A指Adversarial loss,T指texture loss。
相比ENet-E(仅采用MSE作为loss),Perceptual loss的训练结果具有较为锐化的细节,但是它在纹理区域会产生较多的噪声。ENet-PA(采用perceptual loss和adversarialloss)所获得的图像具有很多的高频信息,也显得更为锐化。但是有时会在平滑区域误生成很多高频噪声。ENet-PAT(采用perceptual loss,adversarial loss和texture loss)的效果最好,能够产生合理有意义的纹理,极大减少artifact,许多时候甚至可以达到原图的效果。


图三:loss不同组合方式效果图
三、参考文献
[1]Sajjadi M S M, Schölkopf B, Hirsch M. EnhanceNet: Single Image Super-Resolutionthrough Automated Texture Synthesis[J]. 2016.















 1084
1084

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









