







 本文探讨了超分辨率技术在图像细节恢复上的挑战与进展,分析了MSE损失函数的局限性和对抗损失的优势。介绍了全卷积网络架构如何通过学习残差图像来提升图像质量,避免模糊效果,同时讨论了感知损失在保持图像清晰度方面的作用。
本文探讨了超分辨率技术在图像细节恢复上的挑战与进展,分析了MSE损失函数的局限性和对抗损失的优势。介绍了全卷积网络架构如何通过学习残差图像来提升图像质量,避免模糊效果,同时讨论了感知损失在保持图像清晰度方面的作用。
https://blog.csdn.net/Cyiano/article/details/78612522
在降采样得到LR时,HR的细节信息已经丢失了,如果用MSE作为损失函数,只会估计出所有可能的平均值。而单纯使用对抗损失虽然不是像素级的精确,但可以生成更加真实的细节。
CNN这些方法都局限于单一网络学习的设置,只能生成单一的纹理,并且到目前为止都是如此。
由于这些模型是通过MSE最小化进行训练的,由于上述的回归到均值问题,结果往往是模糊的,缺乏高频纹理。对于CNNs[10,24],已经有人提出了替代感知损失的概念,其思想是将损失从图像空间转移到像VGG[49]这样的对象识别系统的更高级别的特征空间,尽管PSNR值较低,但结果更清晰。
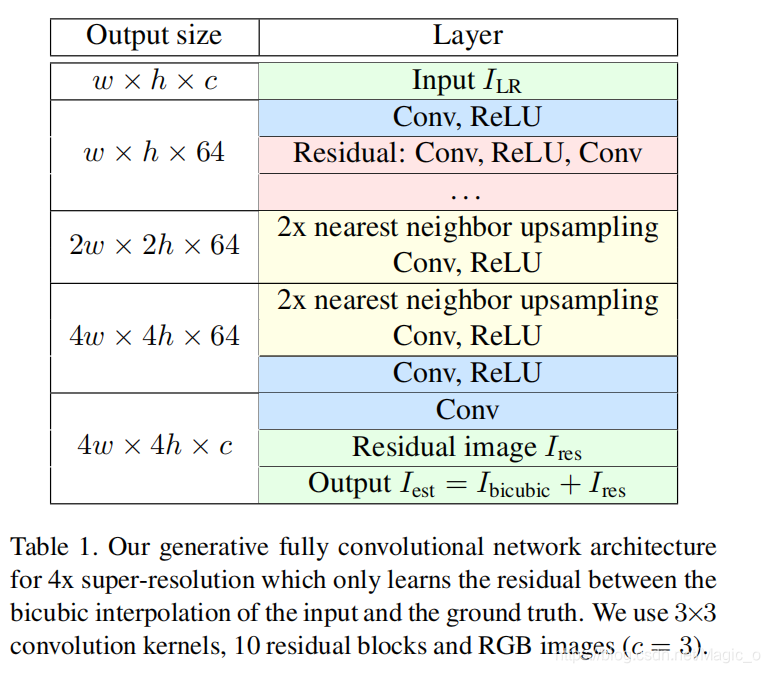
4x超分辨率的全卷积网络架构它只学习输入和ground truth之间的双三次插值的残差。我们使用3×3个卷积核,10个残差块和RGB图像(c = 3)。
通过将输入的双三次插值加入到模型的输出中,只学习残差图像,这样就不需要学习ILR的恒等函数。虽然构成我们网络的主要部分的残差块已经只添加残差信息,但我们发现,应用这一思想有助于稳定训练并减少训练过程中输出的颜色变化。
1.
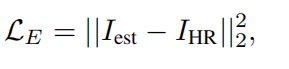
2.
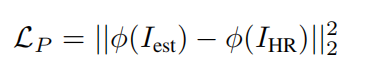
这允许模型生成可能与像素级精度的地面真实图像不匹配的输出,但鼓励网络生成具有类似特征表示的图像。映射φ的特性,我们使用流行的VGG-19 pre-trained实现网络[1,49]。它由叠加卷积和池化层组成,以逐渐减小图像的空间维度,并在更高的层中提取更高层次的特征。为了同时捕获低级和高级特性,我们使用第二层和第五层池的组合,并在它们的特性激活时计算MSE。
3.

















评论

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言
查看更多评论
添加红包








