







"额外功能"对应的英文单词是Extras,算是直译。但是部分版本中的翻译是“后期处理”或者“高清化”,这都是意译,因为它的主要功能是放大图片、去噪、修脸等对图片的后期处理。注意这里边对图片的处理不是 Stable Diffusion 本身的能力,都是额外扩展的。
下面正式开始介绍“额外功能”的相关能力。
图片放大
先看最基本的图片放大能力。对于分辨率比较小的图片,如果强制用较大的分辨率展示,会出现图片模糊的情况,这时候就可以使用SD WebUI的图片放大功能。所谓图片放大就是在保持图片清晰度的前提下增加图片的分辨率,它还有个专业点的名词:超分辨率技术,简称为“超分”。
具体操作方式请参考下图:
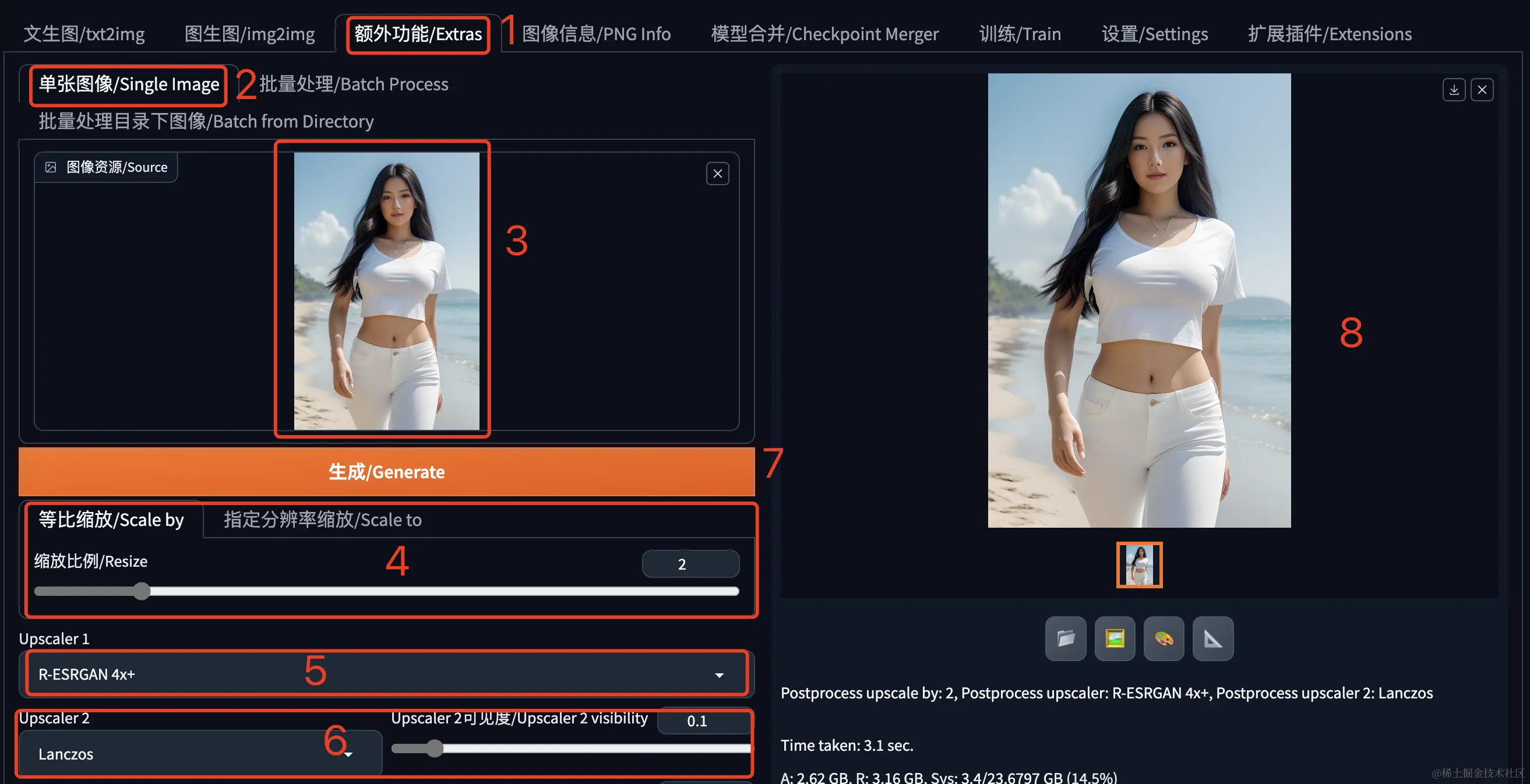
1、主菜单中点击进入“额外功能”。
2、点击“单张图像”,也就是一次只处理一张图片。后边的“批量处理”可以上传多张图片进行处理,“批量处理目录下图像”可以指定处理一个目录下的所有图片。
3、点击上传一张要处理的图片。
4、选择缩放比例。这里有两种方式:按照比例缩放和指定分辨率缩放,指定分辨率时可以设置是否自动裁剪,都很好理解,试试就明白了。
5、Upscaler1用来指定放大算法,常见的放大算法有下面几个:
- 无/None:单纯的放大,不做任何优化处理。
- Lanczos:使用加权平均插值方法,利用原始图像自身的像素信息,增加图像的细节,从而提高图像的分辨率。传统的纯数学算法,效果一般。
- Nearest:使用简单的插值方法,基于最近邻像素的值进行插值,从而增加图像的细节和提高分辨率。传统的纯数学算法,效果一般,还不如 Lanczos 的效果好。
- LDSR:基于深度学习,通过使用轻量级的网络结构和残差学习,实现较高的超分性能和计算效率。适用于各种需要快速且准确地提高图像分辨率的应用场景,如实时视频处理、移动设备图像处理等。
- ESRGAN:全称Enhanced Super-Resolution Generativ
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 5765
5765

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









