









前言
本文主要分享如何利用Python实现同期群分析。
1. 同期群简介
定义:
- 同期群分析(Cohort Analysis),是按用户初始行为的发生时间,将用户划分为群组,从而分析相似群体随着时间的变化。
作用:
- 同期群分析关注客户生命周期相同阶段的群组之间的差异,揭示总体衡量指标所掩盖的问题。
- 通过分析每个同期群的行为差异,来制定有针对性的营销方案。
2. 案例
2.1 案例背景
数据集为线上某店铺的2019.09 - 2020.02的销售订单,每月进行不同的促销策略,分析其每月新用户的留存状况。
数据来源:点击链接
2.2 数据清洗
import pandas as pd
import numpy as np
# 数据加载
data = pd.read_excel('同期群订单数据.xlsx')
data.head()
查看数据
查看数据信息
data.info()
- 付款时间存在缺失值
删除缺失值
# 删除缺失值
data.dropna(inplace=True)
# 查看订单状态
data['订单状态'].value_counts()

- 没有交易失败的订单
提取年与月,用于时间分组
data['date'] = pd.to_datetime(data['付款时间'].tolist(), utc=True).strftime("%Y-%m")
数据清洗完毕
2.3 分析
查看用户数量复购同期分布,以2019年9月为基准。
df = pd.DataFrame()
month_list = data['date'].unique() # 月份数
total_user_list = [] # 总用户列表
for i,j in enumerate(month_list):
month_user_list = data.query("date == @j")['客户昵称'].unique().tolist() # 该月的用户
month_new_user_list = list(set(month_user_list).difference(set(total_user_list))) # 该月的新用户
current_new_user_list = [] # 用来存放该月之后每月的新增用户
for k in month_list[i:]:
current_user_list = data.query("date == @k")['客户昵称'].unique() # 该月之后的第k个月的用户
current_new_user_num = len(set(month_new_user_list).intersection(set(current_user_list))) # 该月之后的第k个月的新增用户数
current_new_user_list.append(current_new_user_num) # 添加到列表
df = df.append(pd.DataFrame(current_new_user_list).T) # 添加到df
total_user_list += month_user_list # 将该月的用户添加到总用户列表
df.columns = ['本月新增'] + [ '+'+str(i)+'个月' for i in range(1,6)]
df.index = month_list
df.fillna(' ', inplace=True)
df

数字不够直观,所以转换成百分比进行对比
df1 = df.replace(' ', np.nan)
def func(x, y):
res = ['%.2f%%'%i for i in round((x/y)*100, 2)]
return res
df1.iloc[:,1:] = df1.apply(func, args=(df['本月新增'], )).iloc[:,1:].round(2).replace('nan%',' ')
df1
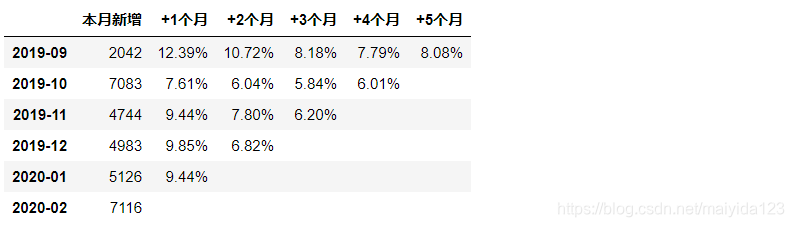
观察上表:
- 横向对比,顾客留存率随时间逐渐下降,19年9月份留存率最高,稳定在8%左右;19年10月最低,仅为6%左右。
- 纵向对比,19年9月新增客户最少,但人群相对精准,留存率表现优于其他月份。19年10月的新增客户较多,但人群精准度较低,留存率不高。
我们可以看看留存用户的客单价同期分布
# 客单
df2 = pd.DataFrame()
month_list = data['date'].unique() # 月份数
total_user_list = [] # 总用户列表
for i,j in enumerate(month_list):
month_user_list = data.query("date == @j")['客户昵称'].unique().tolist() # 该月的用户
month_new_user_list = list(set(month_user_list).difference(set(total_user_list))) # 该月的新用户
current_new_user__ATV_list = [] # 用来存放该月之后每月的新增用户的客单价
for k in month_list[i:]:
current_user_list = data.query("date == @k")['客户昵称'].unique() # 该月之后的第k个月的用户
current_new_user = set(month_new_user_list).intersection(set(current_user_list)) # 该月之后的第k个月的新增用户
current_new_user_payment = data.query("date == @k & 客户昵称 in @current_new_user")['支付金额'].sum() # 该月之后的第k个月的新增用户总消费
current_new_user_ATV = current_new_user_payment / len(current_new_user) # 客单价
current_new_user__ATV_list.append(current_new_user_ATV ) # 添加到列表
df2 = df2.append(pd.DataFrame(current_new_user__ATV_list).T) # 添加到df2
total_user_list += month_user_list # 将该月的用户添加到总用户列表
df2.columns = ['本月新增客单价'] + [ '+'+str(i)+'个月' for i in range(1,6)]
df2.index = month_list
df2 = df2.round()
df2['本月新增客单价'] = df2['本月新增客单价'].astype("int")
df2.fillna(' ', inplace=True)
df2
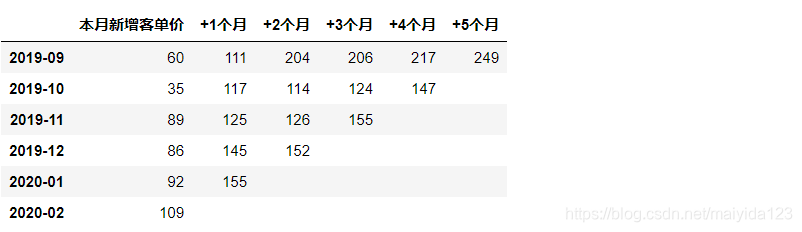
观察上表,可以看到:
- 20年2月的新增用户首月客单最高,达到109;
- 次月留存用户的客单价均比首月新增的高出不少;
- 单月客单最高的为19年9月的新增用户在20年2月的客单价,达到249;
- 2020年2月的营销效果对于新、老客户都比较有吸引力
- …
此外,通过简单修改客单价同期群的代码,我们还可以得到购买次数、消费金额等的同期群分布,这里就不重复造轮子了,有兴趣的可以自己尝试。
2.4 结论
通过对比以上,我们可以发现
- 19年10月的低价营销活动引入了大量不精准、低消费力的客户,造成流失率高、留存消费力弱的现状。
- 19年9月的营销活动则吸引较为优质的客户,其留存率较高,消费能力强。
- 新用户在2-3个月后留存率达到稳定,在6%-8%之间。
- 根据营销活动的获客成本和应用场景不同,需要更多的信息和时间判断营销活动的优劣。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









