







参考资料:R语言实战【第2版】
探索性因子分析(EFA)的目标是通过发掘隐藏在数据下的一组较少的,更为基本的无法观测的变量,来解释一组可观测变量的相关性。这些虚拟的、无法观测的变量被称作因子。(每个因子被认为可解释多个观测变量间共有的方差,因此准确来说,它们应该称作公共因子)
模型的形式是:
其中,Xi是第i个可观测变量(i=1,2,...,k),Fj是公共因子(j=1,2,...,p),并且p<k。Ui是Xi变量独有的部分(无法被公共因子解释)。ai可认为是每个因子对复合而成的可观测变量的贡献值。
虽然PCA和EFA存在差异,但它们的许多分析步骤都是相似的。为阐述EFA的分析过程,我们用它来对六个心理学测验间的相关性进行分析。 112个人参与了六个测验,包括非语言的普通智力测验( general)、画图测验( picture)、积木图案测验( blocks)、迷宫测验( maze)、阅读测验( reading)和词汇测验( vocab)。我们如何用一组较少的、潜在的心理学因素来解释参与者的测验得分呢?
数据集ability.cov提供了变量的协方差矩阵,我们可以用cov2cor()函数将其转化为相关系数矩阵。数据集没有缺失值。
# 设置小数显示位数
options(digits=2)
# 数据处理
covariances<-ability.cov$cov
correlations<-cov2cor(covariances)
# 查看数据
correlations
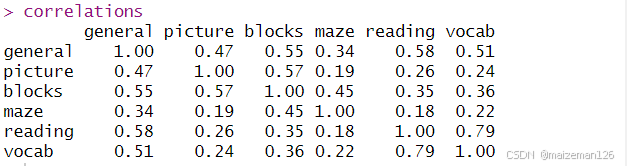
因为要寻求用来解释数据的潜在结构,可使用EFA方法。与使用PCA相同,下一步工作为判断需要提取几个因子。
1、判断需提取的公共因子数
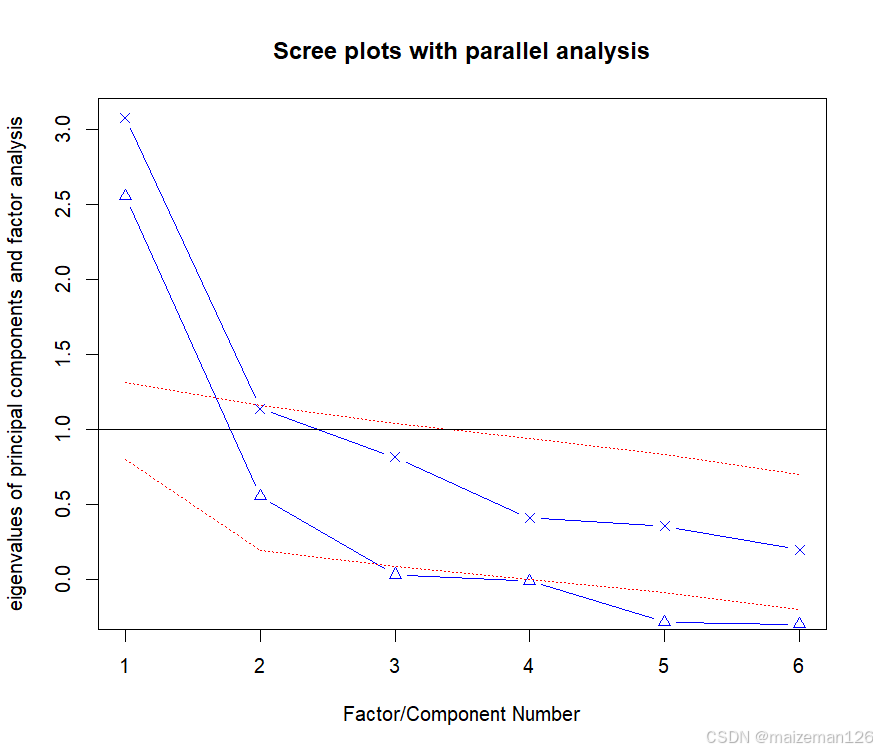
×代表PCA分析,△代表EFA分析。上图中,如果使用PCA方法,我们可能会选择一个成分(碎石检验和平行分析)或者两个成分(特征值大于1)。当摇摆不定时,高估因子数通常比低估因子数的结果好,因为高估因子数一般较少曲解“真实”情况。
观察EFA的结果,显然要提取两个因子。碎石检验的前两个特征值都在拐角处之上,并且大于基于100次模拟数据矩阵的特征均值。对于EFA,Kaiser-Harris准则的特征值数大于0,而不是1。(大部分人都没有意识到这一点。)
2、提取公共因子
现在我们决定提取两个因子,可以使用fa()函数获得相应的结果。fa()函数的格式如下:
fa(r, nfactors=, n.obs=, rotate=, scores=, fm=)
其中,r是相关系数矩阵或原始数据矩阵;
nfactors用于指定提取因子的数目(默认为1)
n.obs是观测数(相关系数矩阵时需要填写)
rotate用于指定旋转方法(默认互变异数最小法)
scores用于指定是否计算因子得分(默认不计算)
fm用于设定因子化方法(默认极小残差法)
与PCA不同,提取公共因子的方法很多,包括最大似然法(ml)、主轴迭代法(pa)、加权最小二乘法(wls)、广义加权最小二乘法(gls)和最小残差法( minres)。统计学家青睐使用最大似然法,因为它有良好的统计性质。不过有时候最大似然法不会收敛,此时使用主轴迭代法效果会很好。
# 为旋转的主轴迭代因子法
fa<-fa(correlations,nfactors=2,
rotate="none",fm="pa")
# 查看结果
fa
由上面结果可知,两个因子解释了6个心理学测验60%的方差。不过因子载荷矩阵的意义并不太好解释,此时需要进行因子旋转。
3、因子旋转
我们可以使用正交旋转或斜交旋转来旋转两个因子,现在我们同时尝试两种方法,看看它们的异同。
# 正交旋转提取因子
fa.varimax<-fa(correlations,nfactors=2,
rotate="varimax",fm="pa")
fa.varimax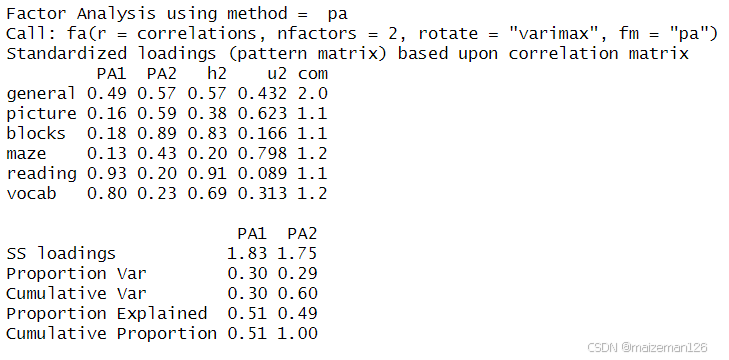
正交旋转的分析结果显示:阅读和词汇在第一因子上载荷较大,画图、积木图案和迷宫在第二因子上载荷较大,非语言的普通智力测量在两个因子上载荷较为平均,这表明存在一个语言智力因子和一个非语言智力因子。
使用正交旋转将人为地强制两个因子不相关。如果想允许两个因子相关可以使用斜交转轴法,比如promax。
# 用斜交旋转提取因子
fa.promax<-fa(correlations,nfactors=2,
rotate="promax",fm="pa")
fa.promax
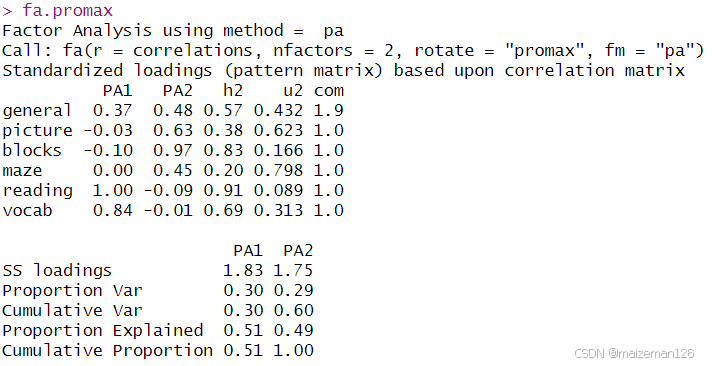
由上面的结果可知正交旋转和斜交旋转的不同之处:对于正交旋转,因子分析的重点在于因子结构矩阵(变量与因子的相关系数),而对于斜交旋转,因子分析会考虑三个矩阵:因子结构矩阵、因子模式矩阵和因子关联矩阵。
因子模式矩阵即标准化的回归系数矩阵。它列出了因子预测变量的权重。
因子关联矩阵即因子相关系数矩阵。
PA1和PA2列中的值组成了因子模式矩阵。它们是标准化的回归系数,而不是相关系数。注意,矩阵的列仍用来对因子进行命名
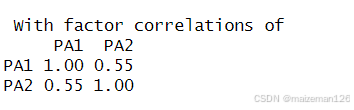
因子关联矩阵显示两个因子的相关系数为0.55,相关性很大。如果因子间的关联性很低,我们可能需要重新使用正交旋转来简化问题。
因子结构矩阵(或称因子载荷矩阵)没有列出来,但我们可以使用公式F=P×Phi得到它,其中F是因子载荷矩阵,P为因子模式矩阵,Phi为因子关联矩阵。
# 建立因子结构矩阵计算函数
fsm<-function(oblique){
if(class(oblique)[2]=="fa" & is.null(oblique$Phi)){
warning("Object doesn't look like oblique EFA")
}else{
P<-unclass(oblique$loading)
F<-P %*% oblique$Phi
colnames(F)<-c("PA1","PA2")
return(F)
}
}
fsm(fa.promax)
现在我们可以看到变量与因子间的相关系数。将它们与正交旋转所得因子载荷相比,我们会发现该载荷阵列的噪音比较大,这是因为之前我们允许潜在的因子相关。虽然斜交方法更为复杂,但模型更复合真实数据。
使用factor.plot()或fa.diagram()函数,我们可以绘制正交或斜交结果的图形。
factor.plot(fa.promax,labels=rownames(fa.promax$loadings))
fa.diagram(fa.promax,simple=FALSE)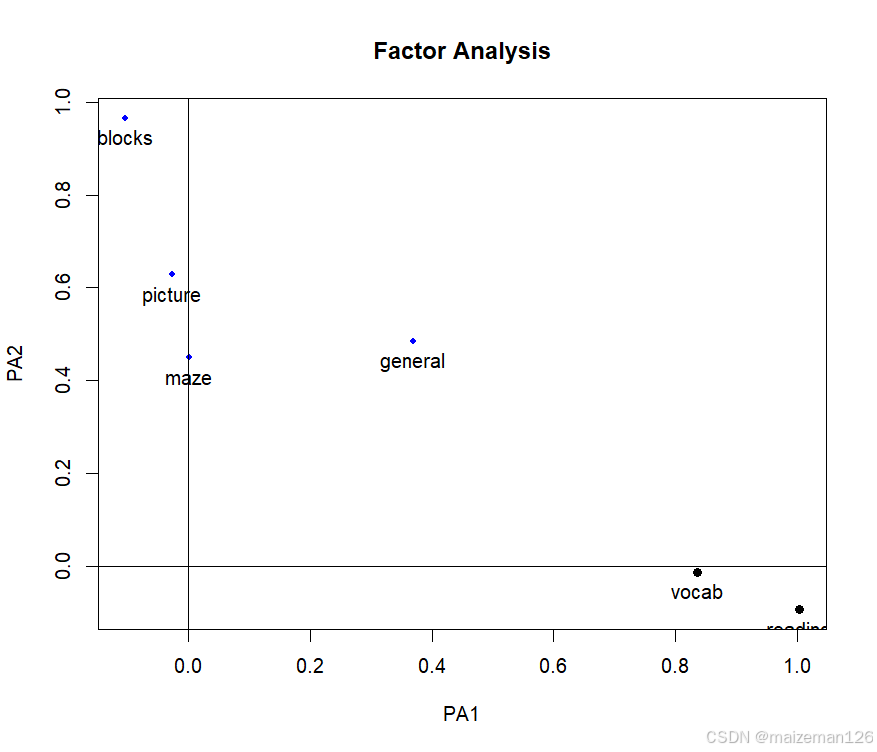
由上图可知:词汇和阅读在第一个因子( PA1)上载荷较大,而积木图案、画图和迷宫在第二个因子( PA2)上载荷较大。普通智力测验在两个因子上较为平均。
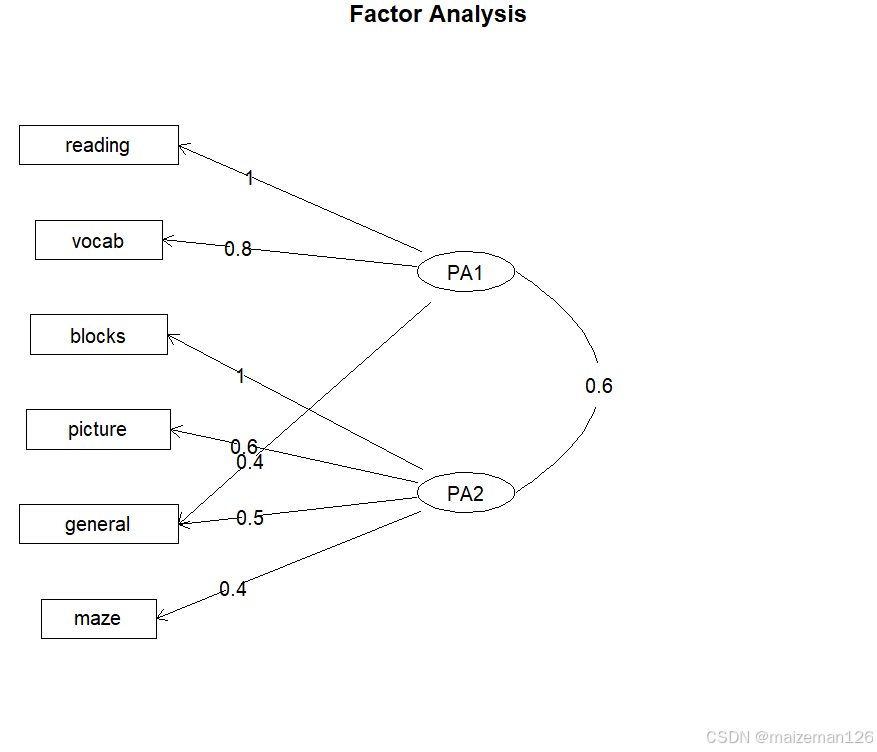
上图由fa.diagram()函数生成,如果将simple=TRUE,那么将仅显示每个因子下最大的载荷以及因子间的而相关系数。
4、因子得分
相比PCA, EFA并不那么关注计算因子得分。在fa()函数中添加score = TRUE选项(原始数据可得时)便可很轻松地获得因子得分。另外还可以得到得分系数(标准化的回归权重),它在返回对象的weights元素中。
对于ability.cov数据集,通过二因子斜交旋转法便可获得用来计算因子得分的权重:

与可精确计算的主成分得分不同,因子得分只是估计得到的。它的估计方法有多种, fa()函数使用的是回归方法。
5、验证性因子分析
在EFA中,你可以用数据来判断需要提取的因子数以及它们的含义。但是你也可以先从一些先验知识开始,比如变量背后有几个因子、变量在因子上的载荷是怎样的、因子间的相关性如何,然后通过收集数据检验这些先验知识。这种方法称作验证性因子分析( CFA)。
CFA是结构方程模型( SEM)中的一种方法。 SEM不仅可以假定潜在因子的数目以及组成,
还能假定因子间的影响方式。你可以将SEM看做是验证性因子分析(对变量)和回归分析(对因
子)的组合,它的结果输出包含统计检验和拟合度的指标。 R中有几个可做CFA和SEM的非常优
秀的软件包,如sem、 openMx和lavaan。
ltm包可以用来拟合测验和问卷中各项目的潜变量模型。该方法常用来创建大规模标准化测试,比如学术能力测验( SAT)和美国研究生入学考试( GRE)。

















 2068
2068

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









