







参考资料:农作物品种试验数据管理与分析
1、PC1和PC2代表什么?
双标图的x轴代表行(如基因型)和列(如环境)在第1主成分(PC1)上的得分,y轴代表行和列在第2主成分(PC2)上的得分。
PC1是一个虚拟变量,是对所有变量的最佳线性概括,可以最大限度地解释所有变量变异,但由不完全代表其中的任何变量。
PC2同样也是一个虚拟变量,它是对PC1拟合后数据中的剩余变量的最佳线性概括,解释它与观察变量的关系更困难也更不确定。
双标图分析主要目的是理解图示的变量间的关系和模式,而不是解释坐标轴的意义。联想到双标图其实是可以自由旋转的,也就是可以理解“坐标轴代表什么”的问题确实没有什么意义。
2、PC1和PC2的单位是什么?
PC1和PC2的单位决定于双标图构建时的数据定标和加权方法,以及奇异值分配方法。假如数据是未定标的,两向表分解后(不是坐标轴)仍然是其原来性状的单位。假如数据是SD定标的,那么两向表的单位就是SD;同样,如果数据是SE定标的,那么两向表的单位就是SE。
双标图坐标轴的单位更加复杂,而且基因型和环境得分的单位可能并不相同,这决定于奇异值分配的方法。假设用于分析的两向表是SD,使用基因型聚焦的分配方法(f=1),那么基因型坐标的单位就是SD,而环境则无计量单位;相反,如果采用聚焦环境的分配方法(f=0),则环境单位是SD,而基因型无计量单位。总之,坐标轴的单位并不重要,重要的是双标图必须按照相同的刻度绘制,即x轴和y轴的物理单位相同。
3、双标图分析前需要做什么准备?
双标图分析是意向对两向数据表进行可视化分析的技术,它有助于揭示数据中存在的模式,但不创造模式。因此,用于双标图分析的数据本身必须是有实际意义的。
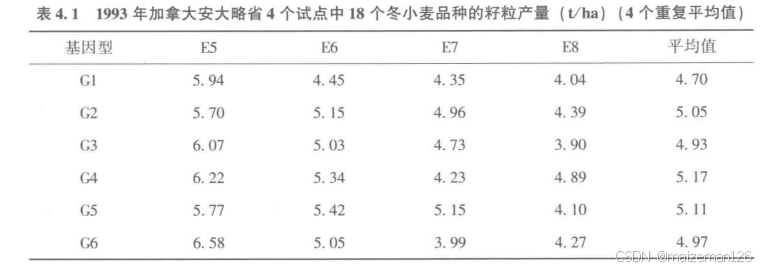
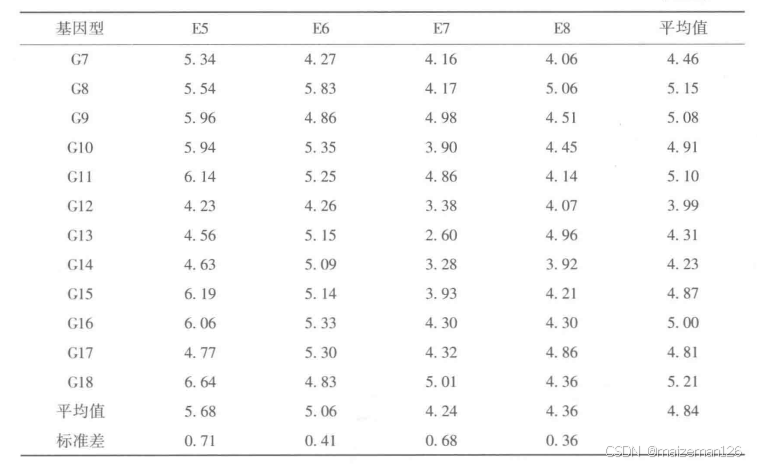
什么数据才是有意义的呢?以下面的数据表为例,它是一个18×4的两向表,其中每个数据都是4次重复的平均值。为了保证数据“有意义”,4个试验中至少有一个实验在基因型间存在统计学上的显著差异(在研究人员认为有意义的显著水平下)。那些基因型间差异不显著的试验不含真实信息,所以也不应当包含在双标图分析中。如果所有试验中都不存在显著的差异,那么双标图分析就没有必要进行了。
 4、双标图可以充分展示两向表中的模式吗?
4、双标图可以充分展示两向表中的模式吗?
双标图分析都是先假设双标图可以完全地或充分地近似待分析的两向数据表,但是对存在复杂交互作用的大型数据集来说,这可能很难。所以在进行GGE双标图分析时,都需要注意其主成分分析信息,如下: 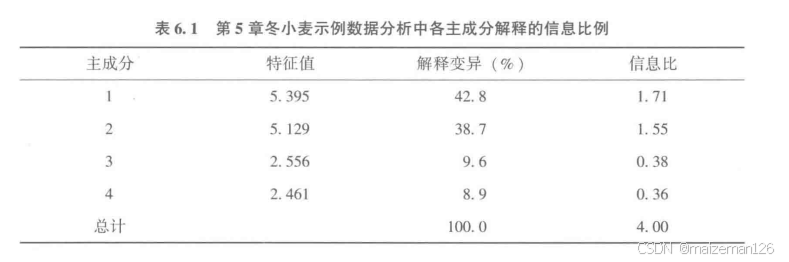
此表中列有主成分的相关信息,如主成分的奇异值信息、解释的平方和(SS)百分比,信息比(IR)。其中第1和第2主成分分别解释了G+GE总平方和的42.8%和38.7%,因此,双标图共解释了81.5%的G+GE总平方和,对数据集合度是比较“高”的。
但是需要一个量化的标准来衡量拟合度多高算是高。表中“IR”提供了这样的信息,IR大于1.0的主成分包含了数据的有用信息,而小于1.0的主成分并不包含有用的信息,因而也是没有意义的。
各主成分的信息比IR的计算过程如下:一个18×4两向表的最大维数是4,如果这4维是完全相互独立的,都应当平均地解释1/4或25%的总平方和。一个主成分的信息比IR就是该主成分解释的平方和除以平均百分比。本例中,PC1的信息比IR=42.8/25=1.712,而PC3的IR=9.6/25=0.384。IR大于1表示该主成分代表的数据信息多于1个变量的均值,因此可以展示数据的模型(或相关性);IR小于1表示该主成分中的有用信息已经被前面的主成分提取了,而剩余的变异可作为噪音处理。通过降维的方法将噪音从模式中分离出去是主成分分析的一个重要作用。
5、如果只有第一个主成分的IR值大于1该如何?
如果只有第一个主成分的IR>1,就表明只需要第一个主成分就可以表达数据中的信息。在这种情况下,除非研究目的只关注第一主成分,否则仍然可以用GGE双标图展示数据,因为双标图可以同时图示行变量和列变量间的差异,比算术平均值含有更多的信息量。同时,即使只有第一个主成分的信息比大于1,也不表示不存在变量间的交互作用,如当行变量和列变量的PC得分都有正值和负值时,就表明存在互作效应。
6、如果双标图未充分展示数据怎么办?
如果有3个以上主成分的IR>0,就表示两维双标图(PC1和PC2)没有充分展示数据的模式。在这种情况下,两维双标图仍然可以解释数据中最终的模式,因而双标图仍然是可以用的。下面用实例说明:
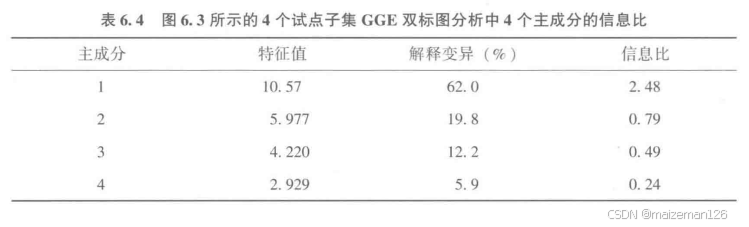
2012年加拿大魁北克省春燕麦品种试验产量数据的双标图如下图,其中,含38个春燕麦基因型(图示中列出了5个基因型的全称,其余用“+”表示)和加拿大魁北克省春燕麦产区的9个试点(用大写字母表示)。9个试验点代表了魁北克省的三大作物产区,以各试点名称后的数字表示其所在产区。如STRO1是第1作物区的试点而LAPO3是第3作物区的试点。各主成分解释的信息比表明,前3个主成分的IR>1.0,所以只含PC1和PC2的双标图可能并没有充分展示数据中的模式。
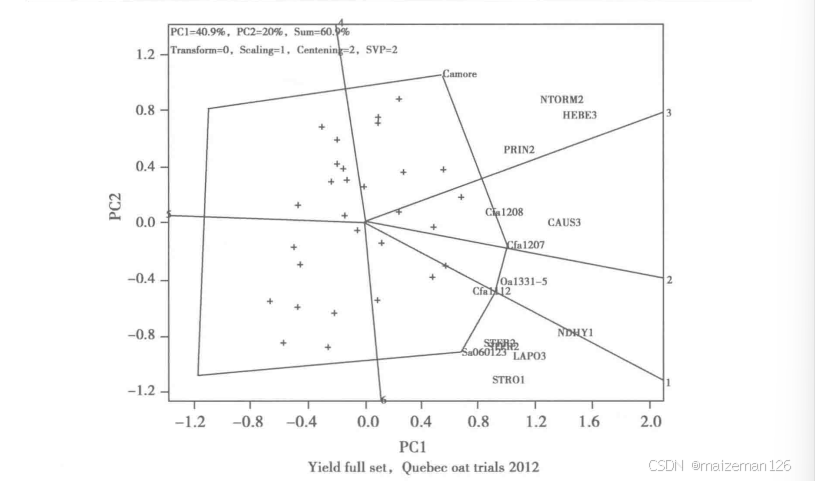
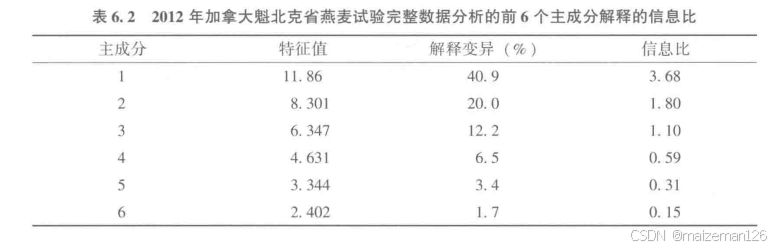
双标图表明,9个试点中有8个试点明显地分为两个组,其中,试点NORM3HEBE3、PRIN2和STAU2落在右上角扇区中,并以Canmore为该扇区共同的胜出品种:而试点STRO1、STFR2、HDHY1和LAPO3落在右下角扇区中,以SA060123为共同的胜出品种。试点CAUS3落在这两个扇区中间的一个扇区中,以CFA1207为胜出品种。
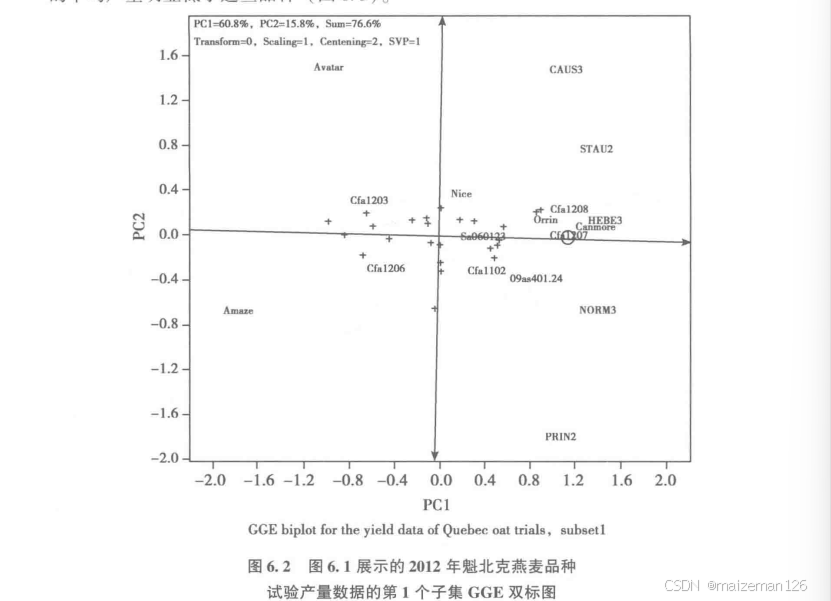
为了验证基于图6.1中的双标图得出的结论的可靠性,采用数据的子集制作了2个双标图。第一组试点数据子集的双标图,在5个可能的主成分中只有第1主成分的IR>1.0,所以,这个CGE双标图在展示该子集数据模式上是很充分的。这个双标图是GCE双标图的“平均值-稳定性”功能图。图中的小圆圈代表5个试验点的“平均环境”,通过平均环境和双标图原点的直线称为平均环境轴(AEA),轴上的箭头所指的方向代表基因型的高产方向。该试点组合中最高产的品种是Canmore,其次是CFA1207CFA1208和0min等,而SA060123的产量显然低于这些基因型。
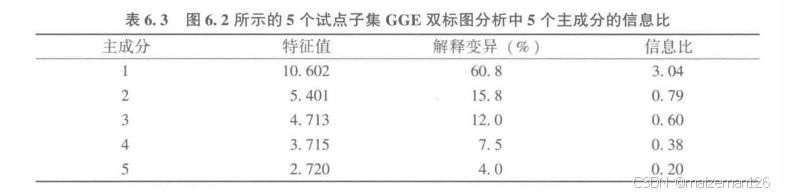
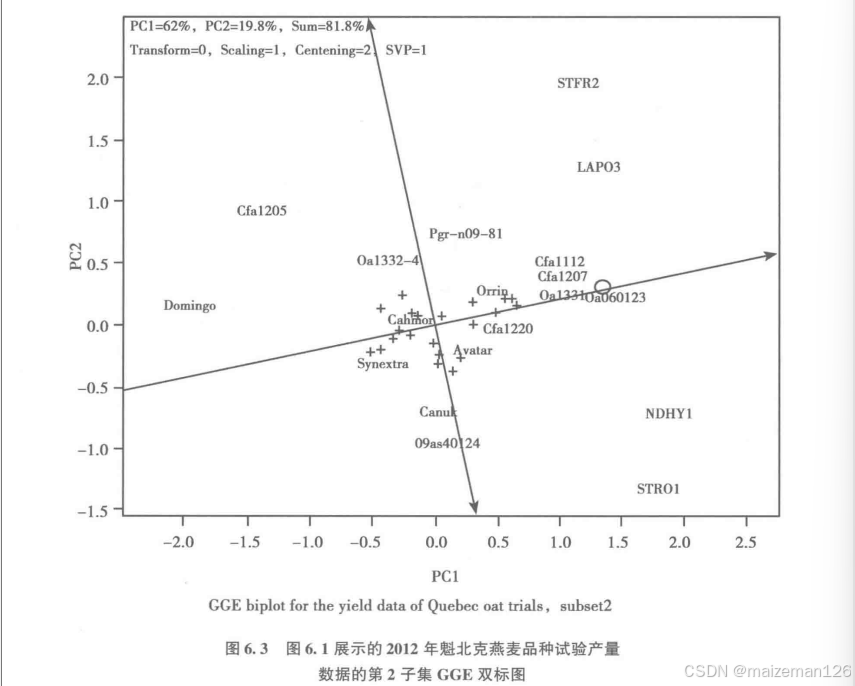
第2个试点组合数据子集分析的4个可能的主成分只有第1个主成分的IR>1.0,说明的GGE双标图也很充分地展示了该子集的数据模式。由该子集双标图的“平均值-稳定性”功能图可见,这个试点组合中最高产的基因型是SA060123,其次是CFA1112、CFA1207和OA1331-5,而Canmore的平均产量明显低于这些品种。
7、如果数据集中有缺失值怎么办?
双标图分析的基本数据技术是奇异值分解(SVD),而奇异值分解必须使用完整的两向表。如果数据表不完整,那就需要在奇异值分解上先将缺值填上某种数值将两向表填充完整。单年品种试验的基因型与试点两向表通常是完整或基本完整的,通常不存在缺值问题。但是,多年品种试验中由于年际间基因型和试点的变化,基因型-环境基因型-环境数据通常是不完整的,从而限制了双标图分析方法的应用。一般而言,对于不完整两向表,大致有3种处理方法。
(1)用环境平均值代替缺失值
(2)提取完整的数据子集:通过删除有缺失值的基因型(行)或环境(列)来提取完整子集
(3)用估计值替换缺失值
8、双标图中两个基因型间的差异在统计学上显著吗?
在聚焦于基因型奇异值分配的GGE双标图中,两个基因型间的距离近似于其欧式距离。因此,基因型间的相对差异可以在双标图中体现。两个基因型间的距离越远,差异就越大。但是,双标图本身并没有显著性检测指标,所以不能指出图中的差异是否达到统计学的显著水平,仍需借助于传统的统计量来检验差异显著性。
9、两个环境间的相关性在统计学上显著吗?
在聚焦于环境奇异值分配的GGE双标图中,两个环境间夹角的余弦值近似于其皮尔逊相关系数,而二者近似的程度与双标图的拟合度有关。但相关系数的显著性问题,双标图也没有显著性检测的不确定度指标。可以用环境间的相关系数矩阵及其统计显著性来补充分析。
10、双标图中的互作模式在统计学上显著吗?
尽管双标图没有不确定度的测量指标,但在双标图中表现明显地差异通常也在统计上差异显著,而且这种现象具有一定的普遍性。当然,这种差异和模式只存在于所分析的数据集中,如果需要把从前数据集得出的结论推广应用,需要进一步分析多年品种试验数据。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









