







# -*- coding: utf-8 -*-
import urllib2
import urllib
import re
import os
import easygui as g
def open_url(url):
req = urllib2.Request(url)
req.add_header("User-Agent","Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.99 Safari/537.36")
page = urllib2.urlopen(req)
html = page.read().decode("utf-8")
return html
def get_img(html):
p = r'http://.*?\.jpg|http://.*?\.png|http://.*?\.gif|https://.*?\.jpg|https://.*?\.png|https://.*?\.gif'
imglist = re.findall(p,html)
for each in imglist:
filename = (each.split("/")[-1])
img_url = "http" + each.split("http")[-1]
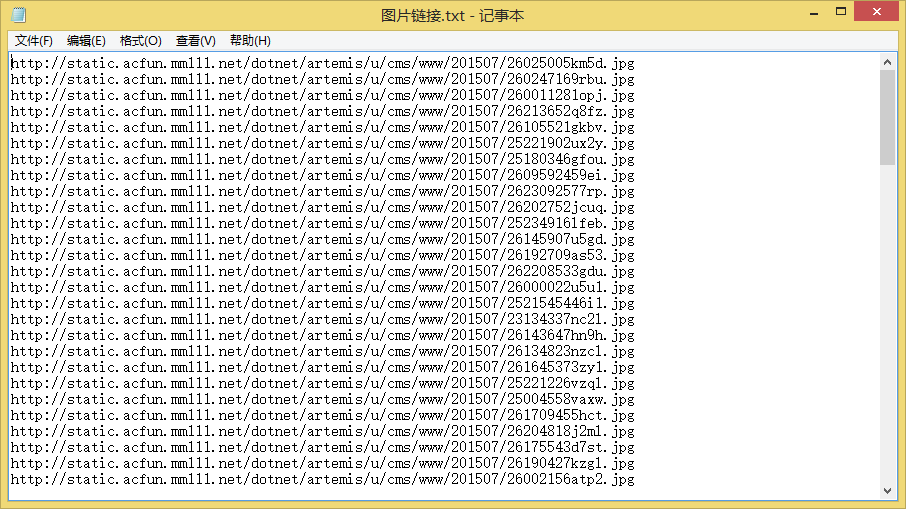
with open(u"图片链接.txt","a") as t:
t.write(img_url+"\n")
try:
urllib.urlretrieve(img_url,filename)
except:
pass
if __name__ == '__main__':
try:
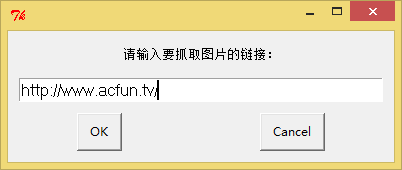
url = g.enterbox(msg=u"请输入要抓取图片的链接:")
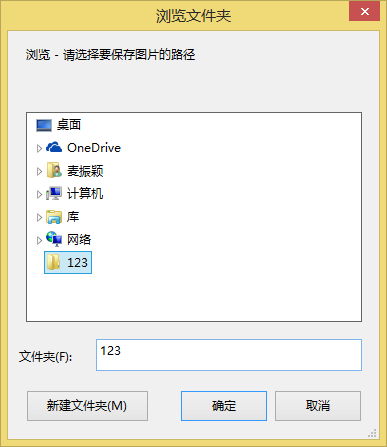
path_download = g.diropenbox(msg=u"请选择要保存图片的路径",title=u"浏览",default=os.getcwd())
except:
exceptionbox()
os.chdir(path_download)
get_img(open_url(url))
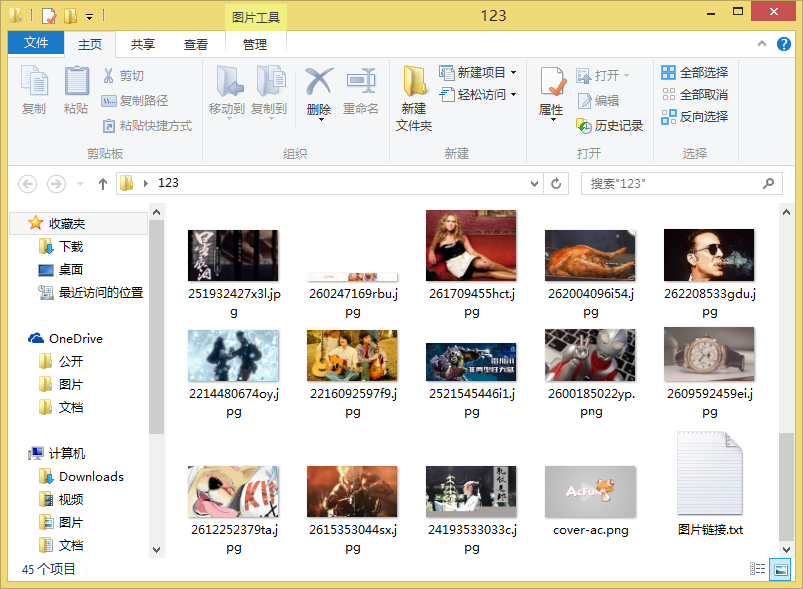
g.msgbox(u"图片抓取完毕!")
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









