






#coding:utf-8
import urllib2
import re
import time
import datetime
print time.strftime('当前时间是:%Y年%m月%d日 %H:%M:%S',time.localtime(time.time())).decode('utf-8')
t = datetime.datetime.now()
month = t.month
day = t.day
url_home = 'http://www.fenxs.com/'
patt = 'www\.fenxs\.com\/\d+\.html" \S+ ' + str(month) + '\S\S\S' + str(day) + '\S\S\S'
# www.fenxs.com/1540.html" title="分享社 7月15日
try:
html_home = urllib2.urlopen(url_home,timeout=10).read()
except urllib2.URLError,e:
print(e.reason)
search_url = re.search(patt,html_home)
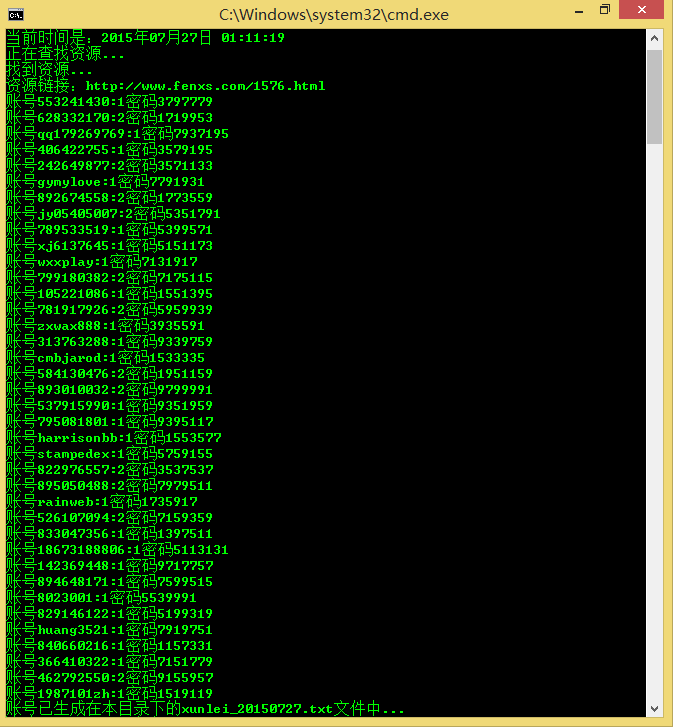
print(u'正在查找资源...')
if search_url:
print(u'找到资源...')
else:
print(u'没有找到资源...')
resource_url = 'http://' + str( re.match(('www\.fenxs\.com\/\d+\.html'),search_url.group()).group() )
print(u'资源链接:%s' % resource_url)
try:
html_resource = urllib2.urlopen(resource_url,timeout=10).read()
except urllib2.URLError,e:
print(e.reason)
patt_resource = '[\\x80-\\xff]+\w{6,}:[12][\\x80-\\xff]+\w+<'
search_account_resource = re.findall(patt_resource,html_resource)
if t.month<10:
_time = str(t.year)+'0'+str(t.month)
else:
_time = str(t.year)+str(t.month)
if t.day<10:
_time = _time+'0'+str(t.day)
else:
_time = _time+str(t.day)
file_name = 'xunlei_'+_time+'.txt'
account_resource = open(file_name,'w')
for i in search_account_resource:
print(i[:-1].decode('utf-8'))
account_resource.write(i[:-1]+'\n')
account_resource.close()
print(u'账号已生成在本目录下的%s文件中...' % file_name)获取分享社最新一期的迅雷分享账号
最新推荐文章于 2024-10-17 09:49:32 发布

















 3139
3139

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









