







 WHYPER是一款采用自然语言处理技术分析移动应用描述,以确定其权限需求是否符合用户期望的工具。通过对应用描述进行深入的语义分析,WHYPER能够识别出与特定权限相关的句子,从而辅助评估应用是否遵循最小权限原则。在READ_CONTACTS、READ_CALENDAR和RECORD_AUDIO等权限上,WHYPER取得了83%的准确率。
WHYPER是一款采用自然语言处理技术分析移动应用描述,以确定其权限需求是否符合用户期望的工具。通过对应用描述进行深入的语义分析,WHYPER能够识别出与特定权限相关的句子,从而辅助评估应用是否遵循最小权限原则。在READ_CONTACTS、READ_CALENDAR和RECORD_AUDIO等权限上,WHYPER取得了83%的准确率。
又到了昊哥读论文时间. 今天搞的是一篇思路比较新颖的CCS 13’ paper. 作者来自于北卡州立(现在在UIUC)的谢涛组, 还算有点远房关系呢.
之前一提到软件安全就离不开什么static /dynamic analysis, 不是model checking就是symbolic execution, 虽然每篇paper都用了很多吓人的terminology且都说自己有多么新颖, 站在外面看一看其实都大同小异.
今天的WHYPER就不大一样了, 它另辟蹊径, 从一个新的角度看待和解决问题. 好了, 不扯犊子了, 详细说下WHYPER.
从题目能看出来, 它强调了”自动化” 和对手机app的风险评估. 我们有各种各样的静态分析和动态分析工具查软件的code和run-time behavior, 但是却忽略了很重要的一点: 软件描述. Apple的app store靠公司雇员审核app描述和行为是否违规, Google把这任务交给了用户, 让用户自己去读描述并把它和app要的permission做对应. 那干嘛不利用现在正火的自然语言处理(NLP)技术做描述到permission的映射, 从而自动检查app 是否遵循了least-privilege原则?
Abstract
what do users expect? 对于给定的app, 检查它的描述是否有迹象表明它需要什么权限. 使用的技术为NLP. 对三个特定的权限达到了83%的准确率. 说自己是第一篇考虑用户期望是否和程序功能匹配问题的paper.
Introduction
说无论是苹果还是狗狗目前都还是人工的检查app的权限是否合适. 他们写的动机是”bridging the semantic gap between what the user expects an app to do what it actually does.”
提到了有些权限如通讯录, 日历和麦克风在描述中大致会体现, 但一些底层的权限如网络和控制震动描述就不大可能能反映出来了.
用NLP技术来决定app**为什么需要某权限(名字来历). 以app描述作为输入, 找出哪些句子**对权限做了暗示. 用官方API做训练集直接生成某些权限的semantic.
评估时使用了581个流行app, 大致10000句话.
iOS的动态权限管理方式能让用户很烦, 而Andoird静态权限大部分用户根本不读. 所以他们的方法可操作性很强.
Whyper Overview
WHYPER是基于句子做分析的, 避免了以keyword为基础的高false positive. 具体来说基于keyword作分析有两大缺陷: 1. 混淆意思: 同样的词在不同的语境下有不同的意义, 映射到不同的权限 2. 隐含语义: 有些权限是通过整句的意思隐含的, keywords找不到.
PS: 因为没有类似的work可以比, 于是找了种naive实现方法做比较.
NLP背景
Parts of Speech Tagging
将句子中各组成成分标出来, 如名词和动词
Phrase or Noun Phrase
和Tagging所做的事类似, 只是换成了短语: 名词短语或者动词短语.
Typed Dependency
根据句子中各部分的语义依赖关系把句子分成层.
Named Entity Recognition
把单词分到之前设定的类.
Use Case and Threat Model
可能用途包括1. 提升用户安装app时的体验(如app store高亮敏感语句) 2. store 管理者拿来规范开发者 3. 与静/动态分析结合 4. 与crowd-sourcing结合来评估用户所期待的功能.
本文考虑的为提醒用户描述中没有体现出来的权限.
WHYPER Design
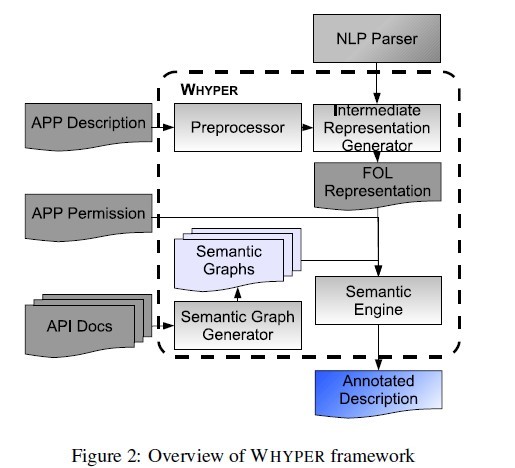
Preprocessor
找句子界限; 减少词法token
1. 句子终结符处理
包括句号, 分号, 省略号.
用正则表达式和wordnet.
2. 句子界限
考虑了更多符号作为分界
3. 特殊名处理
找到如”Google Maps”这样的特殊名并标记出来.
4. 简写
用正则表达式处理简写.
NLP Parser
用Stanford parser对分好了的句子做标记.
1. 特殊名识别
奇怪这个功能怎么又跑到这块来了是吧? 其实是个反馈. Parser识别出特殊名并把它存到一张表(lookup table)里, 然后predecessor 用这张表识别之后需要处理句子中的特殊名.
2. Stanford-Typed Dependencies
用Stanford-Typed Dependencies描述出句子中各组成在语法上的依赖关系. 拿 “Also you can share the yoga exercise to your friends via Email and SMS.” 这句话举例, 依赖关系如下图:

红色表示依赖名, 绿色的是POS tag.
Intermediate-Representation Generator
用树形的一阶逻辑(FOL)表达式表现标记后的语句内的关系.
Semantic-Graph Generator
花开两朵, 各表一枝. 前面说的都是怎么处理描述, 那怎么和权限联系上呢? 靠的是对API 文档建立语义图. 作者说了, 每个权限具体表现内容API文档说的很清楚嘛. 三步走, 先用现有的work把API文档中对特定权限的描述抽出来. 再通过API 类名判断权限对应的资源. 比如通过”ContactsContract.Contacts” 类得出”Address book”和”Contacts”资源对应着”READ_CONTACT”权限. 最后通过类的成员变量和成员识别子资源和对应操作.
因此通过API 文档中的公开的函数可以得到名词短语和动词短语, 分别对应着资源和操作.
Semantic Engine
作者设计了个算法来对权限的semantic-graph 和描述的FOL做比对. 算法对每一个输入的FOL通过给定的semantic graph判断其是否需要相应权限.
Evaluation (P8 - P12)
管描述语句叫做permission semantics. 用Whyper和(对句子的)手工标记做对比. 回答两个问题
1. 精确度 (false positive), recall(false-negative)和F-score在识别有关权限的句子时分别是多少?
2. 和keywords-based相比怎么样?
目标权限
只考虑三个权限: READ_CONTACTS, READ_CALENDAR和 RECORD_AUDIO, 一共六百个app, 每个权限随机选二百.
Evaluation Setup
三个人独立的对六百个app描述做标记, 保证每个句子至少被两个人标记过. 最后再把三个人意见汇总达成一致, 三个人中有两个人同意就代表有相关权限.
用人检测的结果作为ground truth, 再测whyper的表现, 分别测: TP, FP, TN 和FN.
精确度定义为 =
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2981
2981

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









