







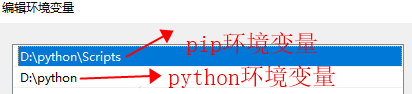
一、 Windows下载安装python3.9.6,配置环境变量
二、安装scrapy
cmd命令
pip install scrapy
三、创建运行项目
创建项目:
scrapy startproject pytest
注意:新建项目需要将settings.py配置文件的 ROBOTSTXT_OBEY = True 改为 False
示例:爬取百度首页
创建爬虫文件:scrapy genspider baidu-spider www.baidu.com
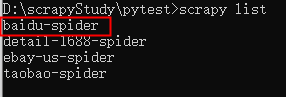
查看爬虫列表:scrapy list
爬虫文件代码示例:
import scrapy
class BaiduSpiderSpider(scrapy.Spider):
name = 'baidu-spider'
allowed_domains = ['www.baidu.com']
start_urls = ['http://www.baidu.com/']
def parse(self, response):
print(response.text)
pass
运行爬虫:scrapy crawl baidu-spider

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









