







参考 https://cloud.tencent.com/developer/article/1863351
在我们的日常业务开发中经常会涉及到使用正则表达式对数据进行处理,比如String的Split()方法,它根据方法中传入的正则表达式对字符串做分割处理。
但是我们是否真的了解正则表达式,它是如何匹配的?不同的匹配方式会带来怎样的效率差别?怎样才能做到效率最优?
本篇就对“如何优化正则表达式的匹配效率?”做深入探讨。
匹配的三种方式
看下面这个例子,我们给定了一个字符串以及三个功能相同但写法略有区别的正则表达式:
String testStr = "effg";
String regular_1 = "ef{1,3}g";
String regular_2 = "ef{1,3}?g";
String regular_3 = "ef{1,3}+g";
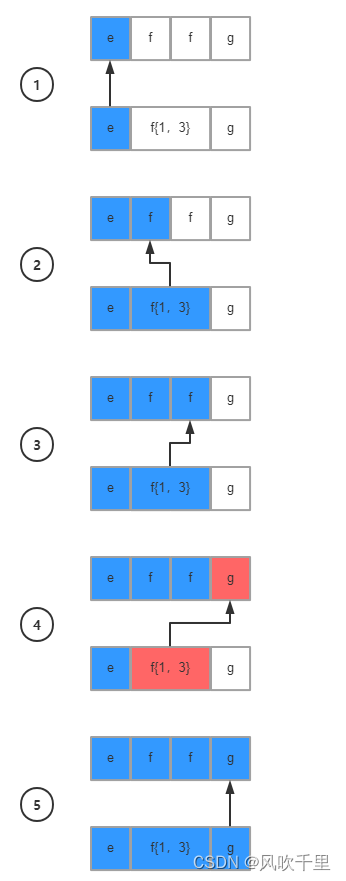
1、贪婪模式(Greedy): ef{1,3}g
贪婪模式是正则表达式的默认匹配方式,在该模式下,对于涉及数量的表达式,正则表达式会尽量匹配更多的内容,我用模型图来演示一下匹配逻辑
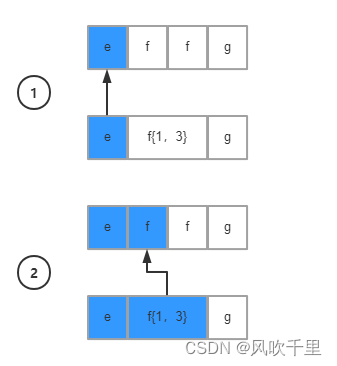
到第二步的时候其实已经满足第二个条件f{1,3},但我们说过贪婪模式会尽量匹配更多的内容,所以依然停在第二个条件继续遍历字符串
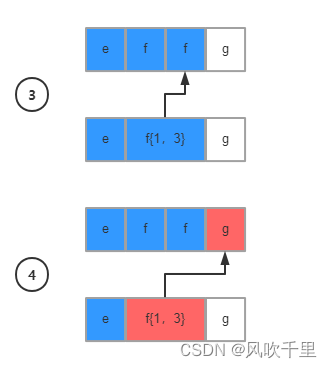
注意看第四步,字符g不满足匹配条件f{1,3},这个时候会触发回溯机制:指针重新回到第三个字符f处
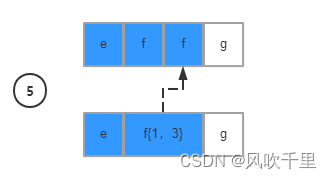
关于回溯机制
回溯是造成正则表达式效率问题的根本原因,每次匹配失败,都需要将之前比对过的数据复位且指针调回到数据的上一位置,想要优化正则表达式的匹配效率,减少回溯是关键。
回溯之后,继续从下一个条件以及下一个字符继续匹配,直到结束
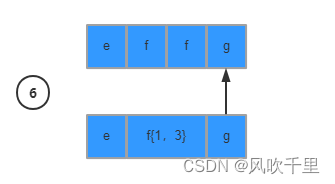
2、懒惰模式(Reluctant): ef{1,3}?g
与贪婪模式相反,懒惰模式则会尽量匹配更少的内容:
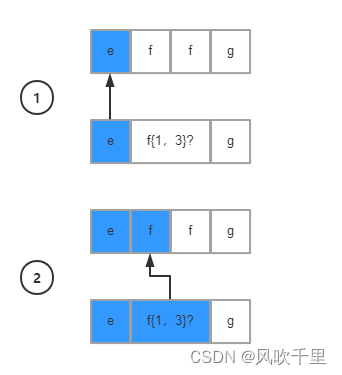
到第二步的时候,懒惰模式会认为已经满足条件f{1,3},所以会直接判断下一条件
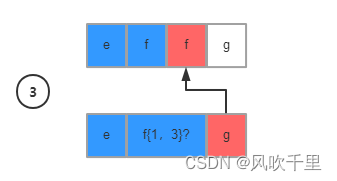
注意,到这步因为不满足匹配条件,所以触发回溯机制,将判断条件回调到上一个
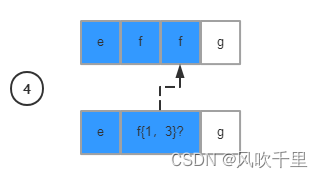
回溯之后,继续从下一个条件以及下一个字符继续匹配,直到结束
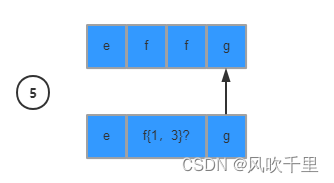
3、独占模式(Possessive): ef{1,3}+g
独占模式应该算是贪婪模式的一种变种,它同样会尽量匹配更多的内容,区别在于在匹配失败的情况下不会触发回溯机制,而是继续向后判断,所以该模式效率最佳














 788
788











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









